如何用Google Drive下载超大型文件
本文将对「如何下载Google Drive中的超大型文件?」这一问题展开探索和解决。
太长不读:直接看这里
情景与问题
在AI、系统安全等研究领域,一项研究成果的产生需要大量的数据样本进行训练和分析,而很多国外作者会倾向于在Google Drive上分享自己的数据集。但是,Google Drive只会为每个下载链接保留一小时的有效期,即你会在Google Drive上的下载链接中会发现一个token字段,而这个字段的有效期是1小时。这一机制使得你必须在1小时内下载好你的文件,否则时机一到,token刷新,当前下载会话就会失效。如果无法有效实现断点续传的话,你就得从头下载了。
那么,在国内的网络环境下,是否有方案可以帮助我们有效实现从Google Drive上下载几十GB乃至更大的文件呢?
候选解决方案
解决上述问题的核心点在于:要么具有下载带宽足够的网络服务,要么可以实现对Google Drive的有效断点续传。因此,可以有以下候选的解决方案:
- 浏览器直接下载
- Google Drive Desktop 客户端下载
- 第三方下载软件(如IDM、CyberDuck等)
- 用国外服务器下载后作为中转,设法下载到国内本地
以上候选解决方案我都试了一遍,在面对70GB大文件时,只有最后一个方法是奏效的。而在介绍这种方法之前,首先介绍前三种方法在目前Google Drive下载机制及国内网络环境下失败的原因。
浏览器直接下载
直接用Chrome下载(开启硬件加速、多线程),如下图所示。
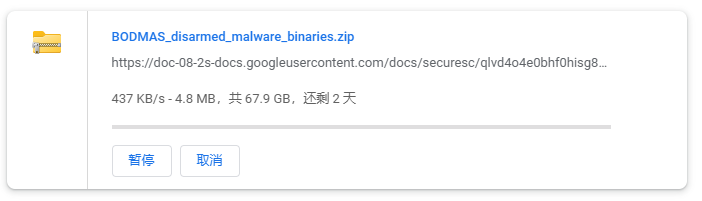
此时,下载速度将主要取决于你的代理服务器带宽、Chrome下载策略等i因素,而我这个速度对于下载70GB的大文件而言是远远不够的。
因此,一个小时后,下载失败了。
Google Drive Desktop 客户端
在我寻找其他解决方法时,发现有人提到使用 Back up & Sync 这款软件可以实现Google Drive下载的断点续传。而在2021年这款软件已经正式成为了Google Drive Desktop。下载并安装完后,这款Google Drive的客户端似乎是一个半成品,在本地你甚至无法直接浏览云端存储的内容,如下图所示。
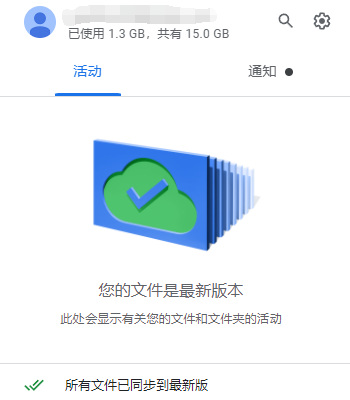
整个软件只有一个空荡荡的下载状态(所谓的同步状态),你想下载Drive中的某个文件时,只能使用搜索功能查找你想要的文件。这甚至都不如国内的一些云盘客户端的体验。总之,在搜索到我想“同步”到本地的大文件后,点击文件名自动开始下载。
令人惊喜的是,客户端的下载速度平均可以达到8MB/s(虽然有些不稳定)。然而,一个小时后,下载再一次的失效了,此时我本以为重新点击文件就能实现断点续传,可惜客户端还是从头给我下载。翻阅了产品文档和他人经验后,我依然没能找到断点续传的功能,不知这是我自己的原因,还是这个软件从Back up & Sync 改进而来后,居然不支持自家Drive的断点续传了?
总之,Google Drive Desktop给我一种软件工业半成品的感觉,用户体验真的非常糟糕。
第三方下载软件
在很多多线程下载器、SFTP下载器等第三方下载软件中,我尝试了著名的IDM。当IDM接管Google Drive的下载链接时,也只能达到2-4MB/s的下载速度,如下图所示;不过没关系,选用IDM的原因之一就是据说它可以实现Google Drive的断点续传。

当下载一个小时后,IDM虽然同样会告诉用户当前下载链接已失效,但是当你尝试让IDM进行链接重定向时,它会要求你再在Drive中手动下载一下,如下图所示。这样一来,它就又可以接管新的下载链接了。而且惊喜的是,IDM的确可以实现对新下载链接的断点续传。
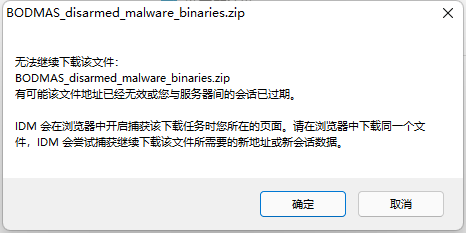
但是在我测试IDM之时, 我已多次尝试下载该文件了。Google Drive以 此文件已超出下载限制的原因 拒绝让我重新下载。因此,尽管IDM在断点续传时能重定向链接并以一个不错的速度接管,但此时的我们不得不寻找一个新的方法。
有效的解决方案
最终,我们只能寄希望于寻找具有足够带宽的国外主机,使用其下载大文件后,设法转移到国内本地。这种做法虽然有些繁琐,但只要文件能成功下载到我们能控制的主机中,想再对其进行各种操作就不会有限制了。
申请Vultr主机
Vultr主机的一大优势在于它的主机带宽据说非常不错,同时它支持支付宝缴费,而且扣费方式是按照小时收费的。因此,从你创建一个主机的docker实例,到结束任务销毁这个实例的过程中,通常只花费不到1$的价格就足够了,这便于我们在上面进行一些临时性的任务和实验。
进入Vultr官网,登录后在Deploy中依次选择购买的主机地点、系统、存储空间等配置。此处要记得根据目标文件的大小选择一个空间充足的方案,这里我选择了150GB存储的配置,如下图所示。
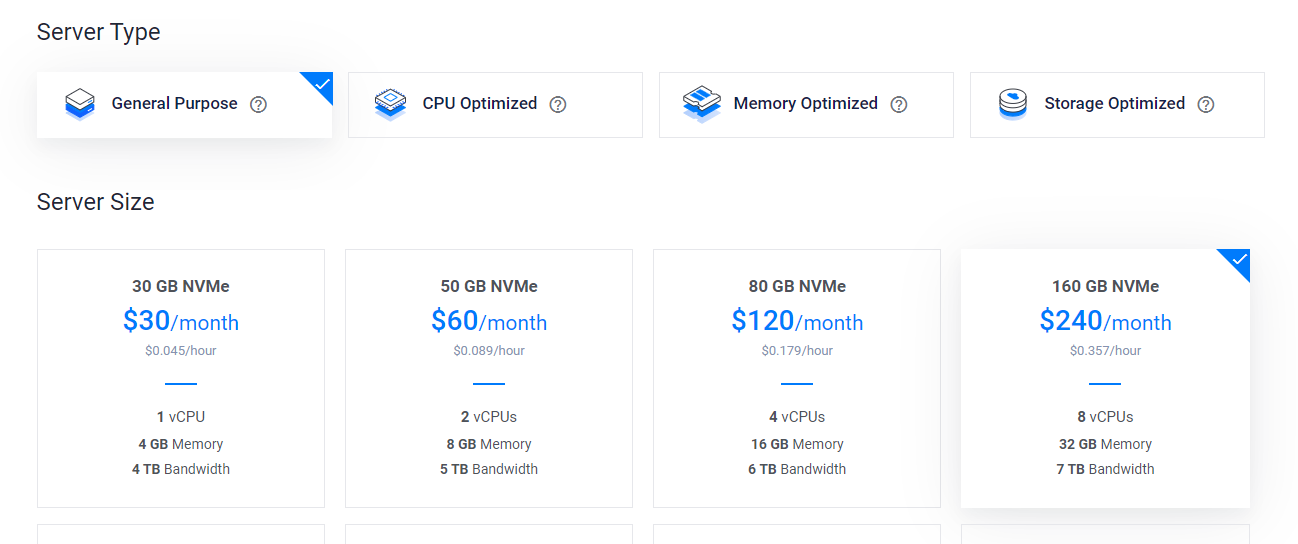
在充值(无需充太多,$10即可)并启动之后,我们需要在当前这个主机实例中通过命令行的方式下载Google Drive中的文件。
获取Oauth API Key
Google作为一个API狂魔,自然也提供了Google Drive文件下载的Oauth API。可通过如下步骤实现Drive API的申请,并在命令行中进行文件的下载。
在Oauth 2.0中,选择Drive API v3下的 https://www.googleapis.com/auth/drive.readonly,如下图所示。

选择 Authorize API,并选择 Exchange authorization code for tokens 就可以申请到一个新的Drive API 下载用 Access Token,这一token的有效期同样为1小时。
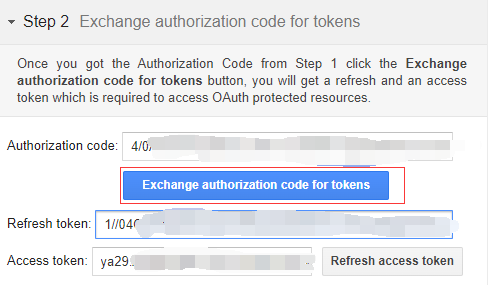 记得将该 Access Token 复制保存出来,以便下一步使用。
记得将该 Access Token 复制保存出来,以便下一步使用。
下载至Vultr主机
下面我们使用curl在命令行中下载Drive中的文件。
curl -H "Authorization: Bearer YOUR_ACCESS_TOKEN" https://www.googleapis.com/drive/v3/files/YOUR_FILE?alt=media -o OUTPUT_FILE
其中有三个需要自己填写字段:
- YOUR_ACCESS_TOKEN: 填写我们刚申请的token即可
- YOUR_FILE: 在Drive右击要下载的文件, 选择 获取链接, 将链接的后半部分填入即可, 如下图所示.
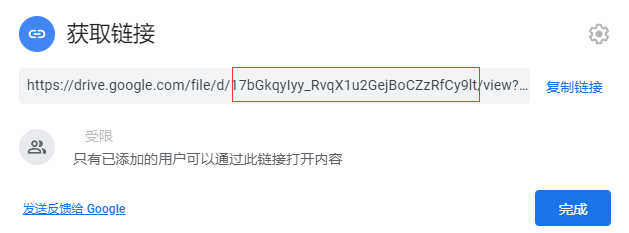
- OUTPUT_FILE: 下载要输出的文件名, 随意填写即可; 如果是断点下载, 记得保持文件名一致.
运行命令开始下载。可以看到,海外Vultr主机的直连Drive的带宽非常可观,平均速度居然可以达到100MB/s左右。这一速度下载70GB的文件也只需要十几分钟。

因此,使用国外主机是完全可以有效下载Google Drive中的大文件的,1小时的极限可以下载400GB左右的文件,而且可以使用curl -C实现断点续传,由此理论上能实现任意大文件的有效下载。
下载至国内主机
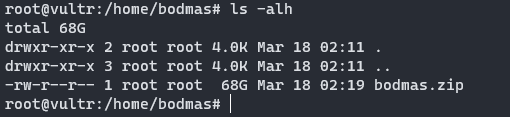
此时文件已成功下载至我们能控制的一个主机了,我们可设法将其二次下载至国内的本地服务器。而Vultr的主机带宽已经充分证明了它网络服务的可靠性。因此,可以在Vultr主机上架设nginx,并直接将该大文件使用http服务发布在公网上,通过nginx + http的文件下载服务,在国内本地主机上使用IDM等第三方软件加速下载。
在Vultr上直接 apt install nginx 安装nginx,安装记得在Vultr主机上使用如下命令关闭防火墙。启动服务如下所示。
sudo ufw app list
sudo ufw allow 'Nginx Full'

在设置之后,可以直接将我们的bodmas.zip这一大文件移动到Debian的nginx Web根目录(/var/www/html)下。之后,本地直接访问 http://my_vultr_ip/bodmas.zip ,让IDM接管下载,即可看到此时的下载速度基本也能达到70MB/s,而且不会有下载时间限制。
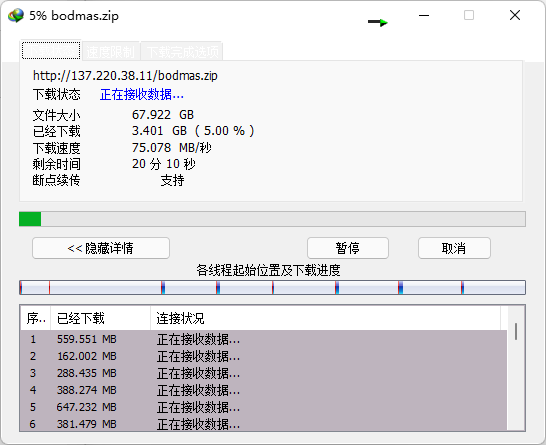
最终,这一70GB的数据集文件,几经转折终于抵达了我们自己的电脑中。而我们Vultr主机也可以直接destroy掉,此时只花了1$不到,余额可以先放着以备他用。
遗留问题
Google Drive Desktop的使用:这个软件的用户体验实在是太差了,但它毕竟是Google Drive的官方客户端,因此上文中我的失败经验有没有可能只是我的打开方式不对,但软件本身其实是支持断点续传的?
CyberDuck的断点续传:CyberDuck也是一款非常出名的第三方下载软件,它可以连接许多产品的文件下载服务。但由于在没有license的条件下,是无法连接至Google Drive的。因此CyberDuck是否能做到比IDM更强大、更高效的断点续传?这一结果可能需要他人来进一步测试了。
总结
以上成功的方案可以基本总结成下面的5步:
- 申请一个带宽可靠、存储足够的海外主机(推荐Vultr);
- 申请Google Drive的Oauth API Key (获得 Access Token);
- 使用curl -C 下载目标文件至海外主机;
- 在海外主机上架设nginx,设置防火墙,并将目标文件移动至根目录;
- 本地使用IDM等多线程下载工具,在海外主机的Web服务中接管目标文件的下载。
诚然,直接使用IDM接管并断点续传这一方案在特定条件下也是可以成功的,但终究没有直接使用最后一种方法的下载速度快而且省心。在经过简单的配置之后,我们基本可以下载Google Drive中任意的超大型文件了。
最后,感谢你的阅读,欢迎给出建议或者其他更高效的方法。以一句歌词作为结束:
如何用Google Drive下载超大型文件的更多相关文章
- Google Drive网盘文件直链获取一键脚本
说明:本脚本可以将Google Drive网盘的文件分享链接或者文件ID变成直链,方便我们在很多情况下调用.只支持文件分享,不支持文件夹.文件分享ID为26到48位. 使用 1.需求 wget.g ...
- 谷歌推出备份新工具:Google Drive将同步计算机文件
Google 正在将云端硬盘 Drive 转变成更强大的文件备份工具.很快,Google Drive 将能监测并备份你电脑上的(几乎)所有文件,只要是你勾选的文档,Drive 就能同步至云端. 具体来 ...
- Google Drive 和 Dropbox 同步同一个文件夹目录
Dropbox 也是非常棒的同步工具,例如先进的增量上传或者更开放的 API 等.可是为什么不曾想过把 Google Drive 和 Dropbox 同时使用呢,我是说,让这两者同时云同步同一个文件 ...
- Google Drive 里的文件下载的方法
Google Drive 里并不提供创建直接下载链接的选项,但是可以通过小小的更改链接形式就能把分享的内容保存到本地.例如,一份通过 Google Drive 分享的文件链接形式为: https:// ...
- Appengine直接下载文件并保存到google drive
一直对下载文件比较感兴趣.前些日子无意搜到google 推出一项服务,可以直接将文件下载到google drive中,原型猛戳这里,但有限额限制.一时脑洞大开,可不可以在appengine 上架设服务 ...
- Linux 网站文件和数据库全量备份 一键脚本(支持FTP,Google Drive)
原文连接: https://teddysun.com/469.html 此文为转载,建议查看秋水大神的原文,排版更容易查看,另外,建议查看脚本源码,方便了解脚本运行过程, 脚本已测试,大神的脚本一如既 ...
- 在线打开,浏览PDF文件的各种方式及各种pdf插件------(MS OneDrive/google drive & google doc/ github ?raw=true)
在线打开,浏览PDF文件的各种方式: 1 Google drive&doc (国内不好使,you know GFW=Great Firewall) 1. google drive: 直接分 ...
- 【转】Expire Google Drive Files 让Google Docs云盘共享连接在指定时间后自动失效
最近在清理Google Docs中之前共享过的文件链接,发现Google Docs多人协作共享过的链接会一直存在,在实际操作中较不灵活.正好订阅的RSS推送了Pseric写的这篇文章 - Expire ...
- 教你用 google-drive-ocamlfuse 在 Linux 上挂载 Google Drive
如果你在找一个方便的方式在 Linux 机器上挂载你的 Google Drive 文件夹, Jack Wallen 将教你怎么使用 google-drive-ocamlfuse 来挂载 Google ...
随机推荐
- 关于在 Linux 下多个不相干的进程互斥访问同一片共享内存的问题
转载请注明来源:https://www.cnblogs.com/hookjc/ 这里的"不相干",定义为: 这几个进程没有父子关系,也没有 Server/Client 关系 这一片 ...
- start方式开启服务的特点&bindService 方式开启服务的特点
服务是在后台运行 可以理解成是没有界面的activity 定义四大组件的方式都是一样的 定义一个类继承Service start方式开启服务的特点 特点: (1)服务通 ...
- 用rewrite规则实现将所有到a域名的访问rewrite到b域名
1.临时重定向 1.1使用redirect实现临时重定向 # cat /apps/nginx/conf/nginx.conf ...省略... server { listen 80; server_n ...
- Lesson10——NumPy 迭代数组
NumPy 教程目录 NumPy 迭代数组 NumPy 迭代器对象 numpy.nditer 提供了一种灵活访问一个或者多个数组元素的方式. 迭代器最基本的任务的可以完成对数组元素的访问. Exa ...
- hexo 接入Google站长工具(google search console)提交sitemap
1.点击google search console 2.选择 点击红圈的按钮 新建资源 3.资源类型 选择网址前缀, 输入网站的url 4.输入完成后的点击验证 下载html 放在hexo 项目下的 ...
- 帆软报表(finereport)JS实现点击参数面板按钮显示或隐藏数据
当报表中列出数据太多时,想通过显示按钮隐藏明细数据只显示统计数据.如下图示例,那么该如何实现呢?本文以FineReport为例,来讲述JS如何实现点击参数面板按钮显示或隐藏数据. 打开报表 在参数面板 ...
- IO_FILE——leak 任意读
在堆题没有show函数时,我们可以用 IO_FILE 进行leak,本文就记录一下如何实现这一手法. 拿一个输出函数 puts 来说,它在源码里的表现形式为 _IO_puts . _IO_puts ( ...
- [LeetCode]1470. 重新排列数组
给你一个数组 nums ,数组中有 2n 个元素,按 [x1,x2,...,xn,y1,y2,...,yn] 的格式排列. 请你将数组按 [x1,y1,x2,y2,...,xn,yn] 格式重新排列, ...
- [Java]Java入门笔记(三):类、对象和方法
七.类.对象和方法 类和对象的关系 类定义了对象的本质: 类(class)是对象(object)的模板,而对象(object)是类的一个实例(instance). 使多个对象的指向相同: Studen ...
- demo_2_27
#define _CRT_SECURE_NO_WARNINGS 1#include <stdio.h>#include <string.h> int count_bit_one ...