KingbaseES 查询计划剖析
概述:了解KingbaseES查询计划对于开发人员和数据库管理员来说都是一项关键技能。这可能是优化SQL查询的第一件事,也是验证优化的SQL查询是否确实实现期望结果的方式。
1、KingbaseES数据库中的查询生命周期
每个查询都会经历不同的阶段,了解下面周期的每个阶段,对理解数据库是很重要的。
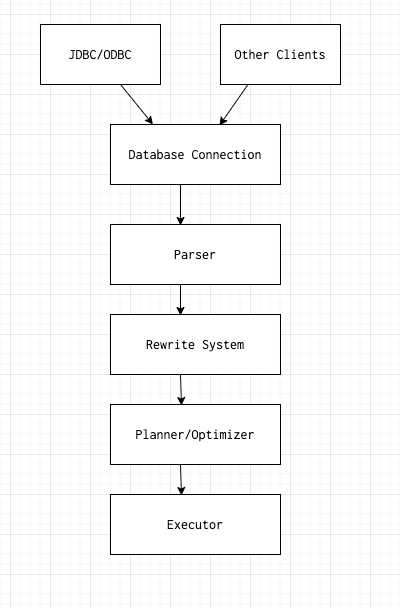
第一阶段是通过JDBC/ODBC或通过其他方式如KSQL(客户端工具)连接到数据库。
第二阶段是将查询转换为解析树的格式,就像 SQL 查询的编译形式。
第三阶段是重写系统/规则系统。它采用从第二阶段生成的解析树,并以规划器/优化器可以开始在其中工作的方式重写它。
第四阶段是最重要数据库的核心。规划器使得知执行器知道如何执行查询、使用什么索引、是否扫描较小的表以消除更多不必要的记录等问题。
第五个也是最后一个阶段是执行器,它执行实际执行并返回结果。
下面将描述第四阶段的工作内容。
2、数据设置
首先建立一些表来运行本文的实验。
CREATE TABLE TEST_TABLE AS select id, lpad(id,10,'0') code, md5(random()) name from generate_series(1, 1000000) id;
该表现在包含1000000行记录。
下面的大多数示例将基于上表。有意保持简单,专注于过程而不是表/数据的复杂性。
3、KingbaseES解释一个查询
explain select * from test_table limit 10;
test=# explain select * from test_table limit 10;
QUERY PLAN
--------------------------------------------------------------------------
Limit (cost=0.00..0.22 rows=10 width=68)
-> Seq Scan on test_table (cost=0.00..17196.64 rows=785064 width=68)
(2 rows)
通过使用EXPLAIN,可以在数据库实际执行查询计划之前查看它们。将在下面的部分中了解每一个的部分,先看看另一个扩展版本的EXPLAIN调用EXPLAIN ANALYZE。
explain analyze select * from test_table limit 10;
test=# explain analyze select * from test_table limit 10;
QUERY PLAN
---------------------------------------------------------------------------------------------------------------------
Limit (cost=0.00..0.22 rows=10 width=68) (actual time=0.062..0.063 rows=10 loops=1)
-> Seq Scan on test_table (cost=0.00..17196.64 rows=785064 width=68) (actual time=0.060..0.061 rows=10 loops=1)
Planning Time: 0.064 ms
Execution Time: 0.073 ms
(4 rows)
与 不同EXPLAIN,EXPLAIN ANALYSE实际上在数据库中运行查询。这个选项对于了解计划者是否没有正确发挥其作用非常有帮助;即,从EXPLAIN和生成的计划是否存在巨大差异EXPLAIN ANALYZE。
4、什么是数据库中的缓冲区和缓存?
这里讨论一个有意义的指标BUFFERS。它解释了有多少数据来自缓存,以及有多少必须从磁盘中获取。
explain (analyze,buffers) select * from test_table limit 10 offset 20;
test=# explain (analyze,buffers) select * from test_table limit 10 offset 20;
QUERY PLAN
----------------------------------------------------------------------------------------------------------------------
Limit (cost=0.39..0.58 rows=10 width=48) (actual time=0.008..0.009 rows=10 loops=1)
Buffers: shared hit=1
-> Seq Scan on test_table (cost=0.00..19346.00 rows=1000000 width=48) (actual time=0.005..0.007 rows=30 loops=1)
Buffers: shared hit=1
Planning Time: 0.100 ms
Execution Time: 0.019 ms
Buffers : shared hit=1意味着从 KingbaseES缓存本身获取了1个页面。
explain (analyze,buffers) select * from test_table limit 100 offset 500;
test=# explain (analyze,buffers) select * from test_table limit 100 offset 500;
QUERY PLAN
-----------------------------------------------------------------------------------------------------------------------
Limit (cost=9.67..11.61 rows=100 width=48) (actual time=0.140..0.157 rows=100 loops=1)
Buffers: shared hit=1 read=5
-> Seq Scan on test_table (cost=0.00..19346.00 rows=1000000 width=48) (actual time=0.008..0.134 rows=600 loops=1)
Buffers: shared hit=1 read=5
Planning Time: 0.039 ms
Execution Time: 0.171 ms
Buffers: shared hit=1 read=5,显示5个页面来自磁盘。该read部分是显示有多少页面来自磁盘的变量,hit表示来自缓存。如果我们再次执行相同的查询(记住ANALYSE运行查询),那么所有数据现在都来自缓存。
test=# explain (analyze,buffers) select * from test_table limit 100 offset 500;
QUERY PLAN
-----------------------------------------------------------------------------------------------------------------------
Limit (cost=9.67..11.61 rows=100 width=48) (actual time=0.058..0.070 rows=100 loops=1)
Buffers: shared hit=6
-> Seq Scan on test_table (cost=0.00..19346.00 rows=1000000 width=48) (actual time=0.009..0.047 rows=600 loops=1)
Buffers: shared hit=6
Planning Time: 0.040 ms
Execution Time: 0.084 ms
(6 rows)
KingbaseES使用一种称为 LRU(最近最少使用)缓存的机制将经常使用的数据存储在内存中。了解到 KingbaseES 的缓存机制,可以使用EXPLAIN (ANALYSE, BUFFERS)命令查看它是如何工作的。
5、VERBOSE 命令参数
Verbose 是另一个提供额外信息的命令参数。
explain (analyze,buffers,verbose) select * from test_table limit 100 offset 500;
test=# explain (analyze,buffers,verbose) select * from test_table limit 100 offset 500;
QUERY PLAN
------------------------------------------------------------------------------------------------------------------------------
Limit (cost=9.67..11.61 rows=100 width=48) (actual time=0.101..0.115 rows=100 loops=1)
Output: id, code, name
Buffers: shared hit=6
-> Seq Scan on public.test_table (cost=0.00..19346.00 rows=1000000 width=48) (actual time=0.008..0.091 rows=600 loops=1)
Output: id, code, name
Buffers: shared hit=6
Planning Time: 0.034 ms
Execution Time: 0.129 ms
注意,Output: id, code, name是附加的。在复杂的查询计划中,将打印大量其他信息。默认情况下,COSTS and TIMING选项TRUE作为设置,除非您想将它们设置为FALSE。
6、KingbaseES中的 FORMAT 解释
KingbaseES能够以多种格式提供查询计划,例如JSON,这些计划可以用某种语言进行解析。
explain (analyze,buffers,verbose,format json) select * from test_table limit 100 offset 5000;
test=# explain (analyze,buffers,verbose,format json) select * from test_table limit 100 offset 5000;
QUERY PLAN
---------------------------------------------
[ +
{ +
"Plan": { +
"Node Type": "Limit", +
"Parallel Aware": false, +
"Startup Cost": 96.73, +
"Total Cost": 98.66, +
"Plan Rows": 100, +
"Plan Width": 48, +
"Actual Startup Time": 0.802, +
"Actual Total Time": 0.821, +
"Actual Rows": 100, +
"Actual Loops": 1, +
"Output": ["id", "code", "name"], +
"Shared Hit Blocks": 6, +
"Shared Read Blocks": 42, +
"Shared Dirtied Blocks": 0, +
"Shared Written Blocks": 0, +
"Local Hit Blocks": 0, +
"Local Read Blocks": 0, +
"Local Dirtied Blocks": 0, +
"Local Written Blocks": 0, +
"Temp Read Blocks": 0, +
"Temp Written Blocks": 0, +
"Plans": [ +
{ +
"Node Type": "Seq Scan", +
"Parent Relationship": "Outer", +
"Parallel Aware": false, +
"Relation Name": "test_table", +
"Schema": "public", +
"Alias": "test_table", +
"Startup Cost": 0.00, +
"Total Cost": 19346.00, +
"Plan Rows": 1000000, +
"Plan Width": 48, +
"Actual Startup Time": 0.006, +
"Actual Total Time": 0.646, +
"Actual Rows": 5100, +
"Actual Loops": 1, +
"Output": ["id", "code", "name"],+
"Shared Hit Blocks": 6, +
"Shared Read Blocks": 42, +
"Shared Dirtied Blocks": 0, +
"Shared Written Blocks": 0, +
"Local Hit Blocks": 0, +
"Local Read Blocks": 0, +
"Local Dirtied Blocks": 0, +
"Local Written Blocks": 0, +
"Temp Read Blocks": 0, +
"Temp Written Blocks": 0 +
} +
] +
}, +
"Planning Time": 0.058, +
"Triggers": [ +
], +
"Execution Time": 0.835 +
} +
]
(1 row)
同时还支持其他格式:TEXT(默认)、JSON、XML、YAML
7、总结EXPLAIN使用方式
EXPLAIN 通常会开始使用的计划类型,主要用于生产系统。
EXPLAIN ANALYSE用于运行查询以及获取查询计划。这是获得计划中的计划时间和执行时间细分以及与执行查询的成本和实际时间的比较。
EXPLAIN (ANALYSE, BUFFERS) 在分析之上使用以获取来自缓存和磁盘的行/页数以及缓存的行为方式。
EXPLAIN (ANALYSE, BUFFERS, VERBOSE) 获取有关查询的详细信息和附加信息。
EXPLAIN(ANALYSE,BUFFERS,VERBOSE,FORMAT JSON)是以特定格式导出的方式;在这种情况下,JSON。
8、执行计划查看
查询计划的元素
无论复杂性如何,任何查询计划都有一些基本结构。在本节中,将重点关注这些结构,这将有助于以抽象的方式理解查询计划。
查询的节点
查询计划由节点组成:

一个节点可以被认为是数据库执行的一个阶段。节点大多是嵌套的,如上图所示;在Seq Scan它之前和之上完成,然后应用该Limit子句。可以添加一个Where子句来理解多层次的嵌套。
explain select * from test_table where code = '0002222' limit 10 offset 500;

l 筛选ID > 10000 的行。
l 使用过滤器进行顺序扫描。
l 在顶部应用LIMIT条件。
如您所见,数据库识别出只需要 10 行,并且一旦达到所需的 10 行就不会再进行扫描。当前,已关闭查询并行,SET max_parallel_workers_per_gather =0; ,以便计划更简单。
查询规划器中的成本
成本是数据库查询计划的关键部分,由于它们的表示方式,这些成本很容易被误解。

需要注意的几个重要事项是:
l LIMIT条款的启动成本不为零。这是因为启动成本汇总到顶部,看到的是其下方节点的成本。
l 总成本是一个衡量标准,与规划者的相关性比与用户的相关性更高。
l 通常,顺序扫描在估计方面很模糊,因为数据库不知道如何优化它们。索引可以极大地加速带有WHERE子句的查询。
l Width很重要,因为一行越宽,需要从磁盘获取的数据就越多。
如果我们实际运行查询,那么成本会更有意义。
数据库规划和执行
计划和执行时间是仅使用EXPLAIN ANALYSE选项获得的指标。

Planner(Planning Time)根据各种参数决定查询应该如何运行,Executor(执行时间)运行查询。上面指出的这些参数是抽象的,适用于任何类型的查询。运行时间以毫秒表示。极少的场景,会出现Plan程序可能需要更多时间来计划查询,而执行程序需要更少时间。它们不一定需要彼此匹配,但如果它们差距很多,那么就要检查其原因了。
在典型代表在线事务处理的 OLTP 系统中,任何计划和执行的总和应该小于 50 毫秒,除非它是分析查询/大量写入/已知异常。在典型的业务中,交易通常从数千到数百万不等。应始终非常仔细地观察这些执行时间,因为这些较小的成本较高的查询可能汇总起来并增加巨大的开销。
优化查询从这里出发
已经涵盖了从查询生命周期到规划器如何做出决策的步骤,本文省略了像节点类型(扫描、排序、连接)这样的主题,因为它们交为复杂,另需文档说明。本文的目的是泛泛了解查询规划器的工作原理、影响其决策的因素以及KingbaseES 提供的工具以更好地理解规划器。
KingbaseES 查询计划剖析的更多相关文章
- SQL Server-聚焦查询计划Stream Aggregate VS Hash Match Aggregate(二十)
前言 之前系列中在查询计划中一直出现Stream Aggregate,当时也只是做了基本了解,对于查询计划中出现的操作,我们都需要去详细研究下,只有这样才能对查询计划执行的每一步操作都了如指掌,所以才 ...
- MySQL的查询计划中ken_len的值计算
本文首先介绍了MySQL的查询计划中ken_len的含义:然后介绍了key_len的计算方法:最后通过一个伪造的例子,来说明如何通过key_len来查看联合索引有多少列被使用. key_len的含义 ...
- Greenplum查询计划分析
这里对查询计划的学习主要是对TPC-H中Query2的分析. 1.Query的查询语句 select s_acctbal, s_name, n_name, p_partkey, p_mfgr, s_a ...
- 看懂SqlServer查询计划【转】
原文链接:http://www.cnblogs.com/fish-li/archive/2011/06/06/2073626.html 开始 SQL Server 查找记录的方法 SQL Server ...
- [译]SQL Server 之 查询计划的简单参数化
SQL Server能把一些常量自动转化为参数,以重用这些部分的查询计划. SELECT FirstName, LastName, Title FROM Employees WHERE Employe ...
- [译]SQL Server 之 查询计划缓存和重编译
查询优化是一个复杂而且耗时的操作,所以SQL Server需要重用现有的查询计划.查询计划的缓存和重用在多数情况下是有益的的,但是在某些特殊的情况下,重编译一个查询计划可能能够改善性能. SELECT ...
- 查询计划Hash和查询Hash
查询计划hash和查询hash 在SQL Server 2008中引入的围绕执行计划和缓冲的新功能被称为查询计划hash和查询hash.这是使用针对查询或查询计划的算法来生成二进制hash值的二进制对 ...
- 【转载】看懂SqlServer查询计划
看懂SqlServer查询计划 阅读目录 开始 SQL Server 查找记录的方法 SQL Server Join 方式 更具体执行过程 索引统计信息:查询计划的选择依据 优化视图查询 推荐阅读-M ...
- 看懂SqlServer查询计划
看懂SqlServer查询计划 阅读目录 开始 SQL Server 查找记录的方法 SQL Server Join 方式 更具体执行过程 索引统计信息:查询计划的选择依据 优化视图查询 推荐阅读-M ...
随机推荐
- Vue.js与ElementUI搭建无限级联层级表格组件
前言 今天,回老家了.第一件事就是回家把大屏安排上,写作的感觉太爽了,终于可以专心地写文章了.我们今天要做的项目是怎么样搭建一个无限级联层级表格组件,好了,多了不多说,赶快行动起来吧!项目一览 到底是 ...
- 使用C++的ORM框架QxORM
QxORM中,我们用的最多的无非是这两点 官方表述是这样的: 持久性: 支持最常见的数据库,如 SQLite.MySQL.PostgreSQL.Oracle.MS SQL Server.MongoDB ...
- iftop使用
在linux中监控系统资源.进程.内存占用等信息,可以使用top命令. 查看网络状态可以使用netstat工具. 如果想查看实时的网络流量,监控TCP/IP连接等,则可以使用iftop工具. 一.if ...
- 华为Mate14上安装Ubuntu20.04纪要
Ubuntu16.04用了将近五年了,已经好几年没折腾过系统,所以简要记录一下. 1. 关于UEFI分区,之前的笔记本UEFI是可选的(只是默认该模式),Bios里面还有其他选项.一般安装系统之前 ...
- 005_面试题 Java_传递方式
面试题: 问:java是值传递还是引用传递? 答:java只有值传递,基本类型传递的是具体的数,引用类型传递的是具体的地址
- Unity3D学习笔记9——加载纹理
目录 1. 概述 2. 详论 2.1. Resources方式 2.2. API方式 2.3. Web方式 1. 概述 理论上,Unity中加载纹理并没有什么难度,只需要将图片放置在Assets文件夹 ...
- C++ 处理类型名(typedef,auto和decltype)
随着程序越来越复杂,程序中用到的类型也越来越复杂,这种复杂性体现在两个方面.一是一些类型难于"拼写",它们的名字既难记又容易写错,还无法明确体现其真实目的和含义.二是有时候根本搞不 ...
- 模板库 ~ Template library
TOC 建议使用 Ctrl+F 搜索 . 目录 小工具 / C++ Tricks NOI Linux 1.0 快速读入 / 快速输出 简易小工具 无序映射器 简易调试器 文件 IO 位运算 Smart ...
- 1000-ms-HashMap 线程安全安全问题
问题: HashMap是否是线程安全 详解 http://www.importnew.com/21396.html 有源码分析 和代码性能比较 CHM性能最好 HashMap不是线程安全的:Hasht ...
- 项目操作案例丨西门子PLC通过网关连接ACS800变频器
本案例控制对象为炉条机.以及蒸汽的控制以及现场数据参数的显示以及报警. PLC 选用西门子 CPU,通过 ET200 IO 模块控制现场设备并监控数据.变频器采用ABB ACS800变频器,将ABB ...