浅谈spark
spark
spark是一个开源分布式计算框架,在于让计算更加快速,通常使用资源调度器yarn和spark自带的资源调度器standalond进行调度,spark相对于Hadoop更加快速,基于它是内存进行迭代,每次通过计算逻辑得到的中间结果值都会存放在内存中,而且最后结果也是从内存到磁盘,而Hadoop则是每次的中间结果都会写到磁盘,读的时候还要从磁盘中读取,最终结果写入的时候也是从磁盘到内存再到磁盘。spark比Hadoop快也是因为spark有个任务调度器:DAG
spark是一个主从架构框架,driver端进行任务调度和收集结果,它会将整个job程序拆分成多个task并通过最优计算位置发放给对应的worker,worker计算完成后再返回给dirver,因此如果最后的结果过大driver端会报OOM
spark常用运行模式:local多线程本机模拟集群、standalone(client客户端模式,cluster集群模式)、yarn(client客户端模式,cluster集群模式),client模式的driver在提交任务的客户端上,cluster模式driver在集群中某一台worker上,因此client模式适合测试,因为如果job任务过多,driver所在的节点负载太大,网卡流量过大,其他程序容易卡死,而cluster则不会,该模式每次执行任务会在集群中随机选一台当作driver,所以多任务的时候,任务分配比较均衡
worker中会有许多executor(进程),每个进程下有个线程池,可以运行线程,一个partition对应一个线程,所以每个线程处理一个partition数据,每运行一个线程处理的数据量就是一个partition的数据量,worker中默认启动一个executor,一个executor默认使用一个core
粗细粒度
mr和spark两个计算框架来说,mr是细粒度,它在分发任务的时候mapTask或reduceTask会先去申请资源,它是一个动态申请;而spark则是粗粒度,在触发action算子之前就已经将资源全部申请好了,如果申请的资源不够就会一直等待
粗粒度
优点:在于资源可以复用,比如:spark的application中可以有多个job,每个job都会被分成多个stage,每个stage里面会有多个task,在并行度为1的时候每个task运行在一个executor中,task执行完,executor资源不需要销毁,下一个stage的task的执行可以复用这个executor资源,这样task的执行效率比较高,stage执行快,job执行快,因此整个application的运行就快
缺点:如果有一个task比较慢没有执行完,那么资源就不会释放,会造成资源浪费
细粒度
优点:不会造成资源浪费,执行完一个task就会释放
缺点:执行效率慢,每个task的执行都会取申请资源
sparkCore
Rdd弹性分布式数据集,里面有多个partition组成,也是通过partition分区来实现分布式,spark的计算就i是Rdd之间的转换
Rdd五大特性
1.由一系列的partition组成的
spark没有实现读hdfs文件的方法,采用的是mr的textFile()方法实现的,将block切分成多个split,而spark会将每一个split加载到Rdd中的每一个partition中
2.方法作用在每一个split上计算
或者是partition(split与partition一一对应)
3.Rdd之间有一系列的依赖关系
每一条partition操作线叫做task,task中会有依赖关系,因此即使Rdd丢失了,也会根据它的父Rdd重新计算得到
4.partition里面是key-value类型的数据
5.对每一个分片有一些计算的最优位置
在读hdfs中数据的时候已经获取到了每个block的地址,因此spark会将对应的task放到对应的地址中
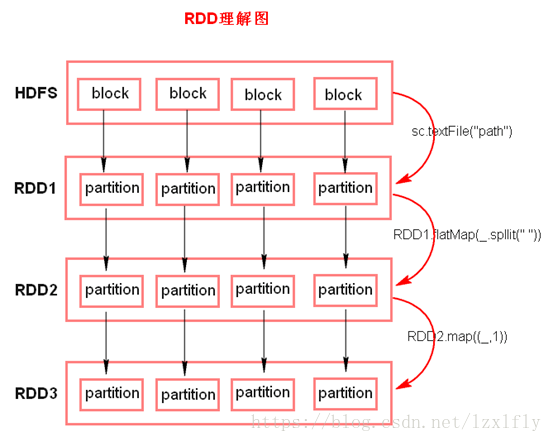
写代码流程:加载数据集形成rdd,再通过一系列transformations转换算子(懒执行)对rdd进行操作,最后执行action算子(触发整个job执行),spark接收的数据可以来源于hdfs,cassandra,hbase,s3
常用transformations算子
map传入一条数据输出一条数据,通过map里面的计算逻辑进行计算
filter传入一条数据返回bool类型,如果是ture则不做修改直接输出,false则过滤掉
flatMap传入一条数据返回一个序列集合,它先经过map,然后对map的结果进行扁平化(将数据从对象中释放出到partition中)
sample抽样算子,如果rdd中有很多数据量,要抽样看是否数据倾斜
groupByKey按照key进行分组,会产生shuffle,分区器作用在(key,value)类型
reduceByKey先分组然后对value进行计算
union将两个rdd变成一个新的rdd,但是两个rdd之间还是独立的
join将(key,value)将相同key的value进行组合
cogroup将(key,value)将相同key的value序列进行组合,也就是将最后相同的key进行了groupByKey
mapValues只对value处理,不对key处理
sort排序
partitionBy里面传一个分区器,将rdd变成另外一个rdd,值不变只是重新分区
常用action算子
count将rdd中的结果条数返回出来
collect将rdd中的数据形成一个集合返回
reduce返回rdd中的一个类型
lookup传进一个key值,返回所有value出来,返回的是一个集合
save将结果放到hdfs中
持久化
目的:对于重复使用的rdd可以进行持久化,减少计算时间
持久化的单元是partition
持久化操作也是懒执行需要action算子触发才能进行,并且必须赋值给一个变量,在持久化后不能直接接action算子
1.通过persist(StorageLevel.)来操作
NONE不写内存不写磁盘
DISK_ONLY只写磁盘,序列化
DISK_ONLY_2只写磁盘,序列化,2个副本
MEMORY_ONLY只写内存,不序列化(cache()方法就是调用MEMORY_ONLY)
MEMORY_ONLY_2只写内存,不序列化,2个副本
MEMORY_ONLY_SER只写内存,序列化
MEMORY_ONLY_SER_2只写内存,序列化,2个副本
MEMORY_AND_DISK使用内存,使用磁盘不序列化,但是先往内存中放,剩下存放磁盘,剩下的partition再往磁盘中放,比如rdd中一共50个partition,而内存只能存下40个,那么剩下的10个由磁盘进行存储
MEMORY_AND_DISK_2使用内存,使用磁盘不序列化,但是先往内存中放,剩下存放磁盘,这个动作会发生两次在不同的节点
MEMORY_AND_DISK_SER上面的基础上使用序列化
MEMORY_AND_DISK_SER_2上面的基础上使用序列化,2个副本
spark默认采用的序列化就是Java的序列化方式压缩比不是很高,不过还有个kyro序列化器,压缩比比较高
运行内存的优先级比存储内存的优先级要高,如果运行内存不足会将存储内存清空一部分给运行内存
2.通过checkpoint()将数据持久化到hdfs中
为了数据更高的安全性可持久化到hdfs中,需要事先在sparkcontext中设置sc.setCheckpointDir("hdfs路径")。当action算子触发checkpoint懒执行的时候,程序会通过task的依赖关系向上查找哪个rdd需要进行checkpoint,然后做标记,最后会重新启动一个job将rdd数据持久化到hdfs中,因为会重新启动一个job去执行,因此可以在做checkpoint之前可以先做一个persist(StorageLevel.),进行完成checkpoint之后会将所有的父rdd标记成parentRdd,因为如果业务逻辑比较复杂的话,那么依赖关系会很长,这样如果中途有哪个rdd挂了,回溯会比较麻烦
如果数据安全性比较高,业务逻辑的链条比较长可以选择checkpoint
广播变量和累加器
广播变量:当算子逻辑中需要使用外部变量的时候,会向drive端的blockManagerMaster中获取,然后drive端的blockManagerMaster会将变量封装成task发送给executor中task,可executor中如果有多个task线程,那么driver端需要网络传输多次,这样导致效率很低,而且如果变量很大,每个task都会存储一份或多个变量,也会占用executor大量运行内存,这样容易导致gc垃圾回收,严重会报OOM。因此在executor中需要一个广播变量,在executor中有个blockManager,如果task线程需要外部变量,task会向blockManager获取,如果第一次blockManager中没有,会向driver的blockManagerMaster中获取,driver端的blockManagerMaster会将含有变量的task发送给blockManager,这时executor中的task获取到变量后会保存在本executor的blockManager中,之后如果其他的task线程也需要这个变量,只需要从blockManager中获取即可
广播变量还有个特点叫做多点传输,如果零一个executor中的task也需要外部变量,那么它会就近找一个blockManager来获取,而非到drive端中获取
使用方法:
val broadcast=sparkContext.broadcast(需要广播出去的变量或集合)//将需要广播的变量或集合添加到广播变量中
在算子中使用
broadcast.getValue()
广播变量在driver端定义,在executor端只能读取,不能操作
累加器
使用方法:
accumulator=sparkContext.accumulator(0)//定义累加器的初始值
在算子中往累加器中添加数字
accumulator.add(number)
累加器在driver端定义,在executor端只能操作,不能读取
广播变量和累加器都是懒执行,需要才会取获取
宽窄依赖
窄依赖:父rdd的partition分区与子rdd的partition分区数据的传输是一对一或多对一的关系
宽依赖:父rdd的partition分区与子rdd的partition分区数据的传输是一对多的关系
为什么会有宽窄依赖?
每个job会根据宽窄依赖划分为多个stage,在每个stage中父rdd与子rdd之间的关系叫做血统,在血统这条线中父rdd与子rdd中的partition之间叫做管道,管道用于每个task的计算,而血统用来rdd之间的容错
宽依赖中ShuffleWrite端如果结果不进行cache或者persist,则会将结果写道磁盘
shuffle
为了解决存放在不同partition上的数据聚合问题。shuffle可分为shuffle_write和shuffle_read。shuffle常用的种类可分为HashShuffle和SortShuffle,
shuffle_write端每一个stage的MapTask都会将自己处理的当前分区中key相同的数据写到一个分区文件中,每个stage中会有多个MapTask,因此也会又多个分区文件,
shuffle_read端ReduceTask会从shuffle_write端的stage上所有的task所在节点上寻找到属于自己分区文件并拉取到ReduceTask对应的文件缓冲区中,保证每个相同key的数据都汇聚到同一个节点上进行处理
HashShuffle
每个MapTask端executor中的task处理完后会将结果写到磁盘中,写入磁盘的过程中会根据ReduceTask端的task个数进行分桶,将key相同的数据分到同一个buffer(默认32k)内存缓冲中,当buffer中写满的时候会溢写到BlockFile分区小文件中,下次写另一个buffer
HashShuffle中shuffle_write端每个task所创建的分区小文件个数和shuffle_read端中task的个数相同
shuffle_write端产生磁盘小文件的总数=shuffle_read端task的总数 X shuffle_write端每个executor中task的个数 X executor的个数
缺点:
1.小文件过多会导致占用内存过大
2.ReduceTask来从BlockFile小文件拉取数据的时候,每次都会打开一个文件句柄,如果小文件过多,创建的对象也会增多,打开文件的时间会增长,并且每次拉取数据都需要和MapTask端建立通讯,小文件过多时间也会增长
consolication机制
shuffle_write端每个executor中只有一个core每次同时只能运行一个task,executor中运行第二个task的时候会复用之前的BlockFile分区小文件,core为1的情况下每个executor中的BlockFile分区小文件叫做ShuffleFileGroup,如果core为2则ShuffleFileGroup有两个,ShuffleFileGroup里面的小文件个数和shuffle_read端中task的个数相同
shuffle_write端产生磁盘小文件的总数=shuffle_read端task的总数 X shuffle_write端executor的个数 X shuffle_write端executor中core的个数
stage与stage之间是不会复用ShuffleFileGroup,因为它们所对应的ReduceTask端task的个数和并行度可能都不同
SortShuffle
shuffle_write端executor中每个task把结果写到内存数据结构中(map或array,根据shuffle算子决定,),该内存数据结构中的数据结构没有固定大小,每插入32次数据之后都会检查内存数据结构的大小,
如果超过5M(默认起始值5M),会将但前的内存数据结构大小乘以2再减去5,剩下的就是需要向executor申请的内存空间,如果executor中没有这么多内存了,那么该内存数据结构就会写到内存缓冲(32k)中,
写的过程中会有个排序的过程,写1万条数据到内存缓冲中,如果内存缓冲写满了,会触发溢写到磁盘上,最后将多个小文件合并成一个文件,并形成一个索引文件,shuffle_read端task来拉取数据的时候只需要从
索引文件中读到相应的偏移量即可获取数据。shuffle_read端task每次以48m的大小拉数据,然后放到shuffle_read端的HashMap(大小是executor内存量的20%,超过了溢写磁盘)中进行合并
shuffle_write端产生磁盘小文件的总数=shuffle_write端executor的core(线程数)X 2
bypass机制
在SortShuffle的基础上去掉排序,排序会消耗性能
触发条件:当shuffle_read端的task数量小于spark.shuffle.sort.bypassMergeThreshold参数的值,并且使用的还是SortShuffle就会触发
任务调度与资源调度
standalone-client模式
1.用户在driver所在节点执行spark-submit脚本,接到请求之后,driver端创建SparkConf、SparkContext、DAGScheduler、TaskScheduler,然后TaskScheduler会将application注册到master的缓存中
2.master接收到请求之后会进行资源调度,向worker发送消息启动executor(worker在启动spark就已经将worker信息注册到了master缓存中,worker向master发送心跳的时候只是发送了一个workerid,并没有发送资源情况,因为在spark-submit的时候已经提交了需要多少资源,master直接做减法。master拥有集群所有的资源情况)
3.worker启动好executor后会反向注册给TaskScheduler,通知driver端资源已分配好,driver收到通知就执行spark代码,执行到某个action算子就触发一个job
4.DAGScheduler会将这个job根据宽窄依赖划分成多个stage,每个stage中都是一个管道计算(一组并行计算的task),其实就是一组并行计算的task,最后以taskSet的形式发送给TaskScheduler。如果stage失败,DAGScheduler会重试提交4次,如果失败表示job失败
5.TaskScheduler接收到taskSet后,会遍历taskSet从里面将task取出来,然后将task发送到executor里面的线程池中的线程执行,如果线程池中的线程失败,executor会向taskSet汇报,TaskScheduler会重新提交一份task,默认重试3次。(task在shuffle过程丢失,则DAGScheduler就会重新提交stage)
6.如果task执行时间过长则会重新提交一个task来执行,但是原来的不会被kill掉,哪个先执行完就以哪个为准,如果连接数据库使用推测执行可能会有重复数据,因此推测执行默认关闭,如果必须开启,可以设置其主键
standalone-cluster模式
1.用户在节点上执行spark-submit脚本,该节点会向master缓存中注册driver信息
2.master接收到请求后会随机找一台节点worker,通知启动executor运行driver
3.driver启动后会将application注册到master缓存中并在drive中创建SparkConf、SparkContext、DAGScheduler、TaskScheduler
4.master接收到请求之后会进行资源调度,向worker发送消息启动executor(worker在启动spark就已经将worker信息注册到了master缓存中)
5.worker启动好executor后会反向注册给TaskScheduler,通知driver端资源已分配好,driver收到通知就执行spark代码,执行到某个action算子就触发一个job
6.DAGScheduler会将这个job根据宽窄依赖划分成多个stage,每个stage中都是一个管道计算(一组并行计算的task),其实就是一组并行计算的task,最后以taskSet的形式发送给TaskScheduler。如果stage失败,DAGScheduler会重试提交4次,如果失败表示job失败
7.TaskScheduler接收到taskSet后,会遍历taskSet从里面将task取出来,然后将task发送到executor里面的线程池中的线程执行,如果线程池中的线程失败,executor会向taskSet汇报,TaskScheduler会重新提交一份task,默认重试3次。(task在shuffle过程丢失,则DAGScheduler就会重新提交stage)
8.如果task执行时间过长则会重新提交一个task来执行,但是原来的不会被kill掉,哪个先执行完就以哪个为准,如果连接数据库使用推测执行可能会有重复数据,因此推测执行默认关闭,如果必须开启,可以设置其主键
yarn-client模式
1.用户提交spark-submit脚本,driver所在节点会创建SparkConf、SparkContext、DAGScheduler、TaskScheduler并发送请求到ResourceManager让其启动ApplicationMaster,ResourceManager会启动Container并随机找一台NodeManager也启动Container
2.启动完成Container后运行ApplicationMaster,这个ApplicationMaster只有启动executor的作用,没有作业调度功能只有资源调度功能。ApplicationMaster向ResourceManager申请一批NodeManager并启动Container
3.ApplicationMaster通知NodeManager在Container中启动executor,Container会将executor方向注册到driver中的TaskScheduler中,driver收到通知就执行spark代码,执行到某个action算子就触发一个job
4.DAGScheduler会将这个job根据宽窄依赖划分成多个stage,最后以taskSet的形式发送给TaskScheduler
5.TaskScheduler接收到taskSet后,会遍历taskSet从里面将task取出来,然后将task发送到executor里面的线程池中的线程执行
yarn-cluster模式
1.用户在节点上执行spark-submit,该节点会向ResourceManager发送请求启动ApplicationMaster,ResourceManager收到请求后启动Container,由Container随机找一台NodeManager启动ApplicationMaster,ApplicationMaster也同时会创建SparkConf、SparkContext、DAGScheduler、TaskScheduler
2.在cluster模式下ApplicationMaster相当于driver的作用。ApplicationMaster会向ResourceManager请求一批NodeManager
3.NodeManager启动Container后ApplicationMaster会通知启动executor,executor启动后会反向注册到ApplicationMaster的TaskScheduler中,driver收到通知就执行spark代码,执行到某个action算子就触发一个job
4.DAGScheduler会将这个job根据宽窄依赖划分成多个stage,最后以taskSet的形式发送给TaskScheduler
5.TaskScheduler接收到taskSet后,会遍历taskSet从里面将task取出来,然后将task发送到executor里面的线程池中的线程执行
SparkSql
主要对结构化数据进行计算,不同于rdd对非结构化数据进行计算。在SparkCore和SparkSql相互转换相互调用。SparkSql可以访问hive,avro,parquet,orc,json,jdbc,hdfs,s3,h2(hbase需要手动整合)。
SparkSql采用的数据结构是dataFrame(底层基于Rdd封装),可以看作分布式表结构,其效率要高于rdd操作,原因在于rdd中partition里面的每条数据都是对象,如果需要对对象中某个属性进行操作则需要加载整个对象到内存中,这样容易产生数据冗余;不同于rdd,dataFrame的表结构可以将每个字段的所有数据看作一个字段,因此只对某字段加载到内存操作即可
底层架构:用户提交交互式sql,经过解析器确认sql语句正确后解析成逻辑计划,传给分析器进行分析传给优化器,优化器里面有一批规则来对逻辑计划进行优化,然后传给sparkPlanner,里面有一批策略,将逻辑计划上变成数据集合,然后运行模型来分析真实物理计划的耗时选择最优的策略,最后准备计划转变成rdd执行
使用方式:
val sqlContext = new SQLContext(sparkContext)
读数据
数据类型可以是非嵌套json,parquet(保存数据默认的类型,它的压缩比高于json,列式文件格式),jdbc
如果是parquet数据源还可以自动推断分区,比如hdfs的存储目录为/users/country=China和/users/country=English,里面都有个users.parquet文件,加载数据.parquet(/users),那么dataframe会自动根据目录结构推断键值
val dataFrame = sqlContext.read.format("json").load("url") # 等价于sqlContext.read.json("url"),直接使用.json()出来传入数据地址外还可以传入json类型Rdd
val fieldFrame = dataFrame.select("field").show() # 查询某字段并打印,show()在SparkSql中是个action操作
dataFrame.printSchema() #打印dataFrame表格式,也是个action操作
dataFrame.select(dataFrame("name"), dataFrame("age").plus(10)).show() # dataFrame.col("字段名")和dataFrame("字段名")的含义是一样的,表示dataFrame中的当前行所对应的字段值,plus加法操作
dataFrame.filter(dataFrame("age").gt(20)).show() # 过滤age大于20的数据
dataFrame.groupBy("age").count().show() # 按照age字段进行分组然后统计每组的个数,age相同的作为一组
dataFrame.groupBy("date").agg(max('sale_amount)) # 按照date字段进行分组,然后计算出最大的,max中必须为"'",而且max是import org.apache.spark.sql.functions._中
dataFrame.registerTempTable("table") # 将dataframe注册成临时的表,这个表只是逻辑上的表,不会落地,只有在需要写sql语句的时候才需要
sqlContext.sql("select * from table").show() #通过sql语句对表查询
读关系型数据库
方式1
var options = new HashMap[String, String]()
options.put("url", "jdbc:mysql://ip:3306/库")
options.put("user", "用户")
options.put("password", "密码")
options.put("dbtable", "表")
var studentInfosDF = sqlContext.read.format("jdbc").options(options).load()
如果需要更换表
options.put("dbtable", "表")
var studentScoresDF = sqlContext.read.format("jdbc").options(options).load()
方式2
DataFrameReader reader = sqlContext.read().format("jdbc")
reader.option("url", "jdbc:mysql://ip:3306/库")
reader.option("driver", "com.mysql.jdbc.Driver")
reader.option("user", "用户")
reader.option("password", "密码")
reader.option("dbtable", "表")
DataFrame studentInfosDF = reader.load()
写数据
dataFrame.write.mode(SaveMode.Overwrite).format("json").save("url")和dataFrame.write.mode(SaveMode.Overwrite).json("url")如果不写格式,默认保存格式parquet
.write()拿到写的句柄(对象)
.mode(SaveMode.Overwrite)重写
Append 追加
ErrorIfExists如果文件存在报错
Ignore 如果文件存在不写
RDD和DataFrame的转换
1.反射方式
Rdd转DataFrame(Java版本中字段的顺序会按照字典排序的顺序进行排序,Scala版本不会排序)
1)需要一个对象类并实现Serializable序列化接口,并且因为用到了反射所以该对象类必须为public
2)通过map算子将rdd中的数据疯转到对象类中
3)通过sqlContext.createDataFrame(Rdd,对象类.class)底层会通过反射的方式得到DataFrame
DataFrame转Rdd
dataFrame.rdd即可转成rdd,里面类型是Row类型,可以通过row.get(下标)来拿数据,如果确定了row里面数据的类型还可以直接用getInt,getString等准确获取
2.动态转换
Rdd转DataFrame
1)构造RowRdd,比如:rdd.map(x=>Row(x(0),x(1)))
2)构造StructField,创建Schema,比如:StructType.apply(Array(StructField("name",StringType,true),StructField("age",IntegerType,true))),StructField参数字段名,类型,是否可为null默认true
另一种写法
var structFields = new util.ArrayList[StructField]()
structFields.add(DataTypes.createStructField("name", DataTypes.StringType, true))
structFields.add(DataTypes.createStructField("age", DataTypes.IntegerType, true))
var schema = DataTypes.createStructType(structFields)
如果字段数很多可以通过以下方式进行构建
val schemaString = "name:String age:Integer"
StructType(schemaString.split(" ").map(fieldName => StructField(fieldName.split(":")(0), if (fieldName.split(":")(1).equals("String")) StringType else IntegerType, true)))
3)构建DataFrame,比如:sqlContext.createDataFrame(RowRdd,schema)
DataFrame转Rdd
dataFrame.rdd
3.隐式转换
Rdd转DataFrame
1)导入import sqlContext.implicits._
2)rdd.toDF() # 这种方式的表都会在一个字段中
DataFrame转Rdd
dataFrame.rdd
SparkSql整合hive
配置
在spark的master节点spark的conf目录下添加hive-site.xml,配置hive的元数据,高可用中另一个master上也需要配置
<configuration>
<property>
<name>hive.metastore</name>
<vlaue>thrift://hiveIp:9083</vlaue>
</property>
</configuration>
hive节点启动hive的metastore服务,该服务提供元数据供其他客户端访问,执行hive --service metastore
使用
sqlcontext是hivecontext的父类,sparksql和hive整合完后就可以使用hivecontext
import org.apache.spark.sql.hive.HiveContext
val hiveContext=new HiveContext(sparkContext)
hiveContext.sql("show databases")
hiveContext.sql("show databases").show() # 查看所有的数据库
hiveContext.sql("use default") # 使用默认的数据库,不加默认使用default库
hiveContext.sql("show tables") # 查看库中的表
hiveContext.sql("drop table 表名") # 删除表
hiveContext.sql("CREATE TABLE IF NOT EXISTS student_infos (name STRING, age INT) row format delimited fields terminated by '\t'") # 创建表结构,字段之间的分隔符\t,行之间\n
hiveContext.sql("LOAD DATA LOCAL INPATH '/root/resource/student_infos' INTO TABLE student_infos") # 加载本地数据到hive的表中如果加载hdfs上数据去掉local
dataFrame.saveAsTable("表名") # 保存表到hive中
UDF
sqlContext.udf.register("strLen", (str: String) => str.length()) 注册一个用户自定义函数,strLen名字,匿名函数(str: String) => str.length()
sqlContext.sql("select name,strLen(name) from names") # 使用strLen函数
UDAF
需要另写一个类,继承UserDefinedAggregateFunction并实现如下方法
inputSchema # 输入数据的类型
bufferSchema # 聚合操作时,所处理的数据的类型
dataType # 最终函数返回值的类型
deterministic # 设置成true和false都可以,是一个确定性设置
initialize # 为每个分组的数据执行初始化值
update # 每个分组,有新的值进来的时候,如何进行分组对应的聚合值的计算,这个update相当于shuffle中在map进行combiner
merge # 最后merger的时候,在各个节点上的聚合值,要进行merge,也就是合并,相当于shuffle中reduce端拉去过来后进行最后聚合
evaluate # 最后返回一个最终的聚合值,要和dataType的类型一一对应
sqlContext.udf.register("strCount", new StringCount) # 注册udaf函数
sqlContext.sql("select name,strCount(name) from names group by name") # 使用udaf函数
开窗函数
row_number()开窗函数的作用:按照每一个分组数据的顺序,打上一个分组内的行号,比如id=a [111,112,113]应用开窗函数后id=a [111 1,112 2,113 3]
例如:
SELECT product,category,revenue FROM (SELECT product,category,revenue,row_number() OVER (PARTITION BY category ORDER BY revenue DESC) rank FROM sales ) tmp_sales WHERE rank<=3")获取每组前三条数据
其中"row_number() OVER (PARTITION BY category ORDER BY revenue DESC) rank",over后面表示对谁开窗,先对category分组,然后按照revenue进行降序排序,取别名为rank,开创函数会对组内的数据进行标注序号,1,2,3...
SparkStreaming
spark中实时计算框架,根据SparkStreaming中的定时器每个一段时间会将这段时间所收集的数据收集到rdd中进而封装成DStream进行这批数据的处理,因此SparkStreaming是一个微批处理,非准实时计算框架,开始执行任务之后就不可以再调整其的并行度,SparkStreaming在处理的时候线程数需要大于等于2,因为一个线程用来接收数据,一个线程用来处理业务逻辑
sparkStreaming中每个batch每200ms切成一个block,每个block由一个线程来执行
SparkStreaming通过StreamingContext来使用,StreamingContext的创建的方式有两种,一种传入sparkConf,另一种传入sparkContext
例如:new StreamingContext(sparkConf,Seconds(1))和new StreamingContext(sparkContext,Seconds(1))后面的Seconds(1)表示定时器的时间设定,每1秒会处理这1秒所收集的数据,这个时间需要根据集群资源情况(ganglia监控)进行设置
简单示例代码:统计1s内单词个数,可以结合nc -lk命令测试使用
val sparkconf = new SparkConf().setAppName("application").setMaster("local[2]")
val streamingContext = new StreamingContext(sparkconf,Seconds(1))
streamingContext.socketTextStream("ip",端口).flatMap(x=>(x.split(" "))).map((_,1)).reduceByKey(_+_).print()
streamingContext.start()
streamingContext.awaitTermination()
streamingContext.stop()
整个执行逻辑最后必须有action算子,所有的代码都会受SparkStreaming框架控制,只有触发定时器并且代码中有action算子,job才会执行
start()运行逻辑代码;awaitTermination()等待或终止可通过ctrl+c或web页面终止;
stop()停止,默认参数true,SparkContext和StreamingContext都会杀掉,因此停止之后是不能再调用start(),如果需要可以设置false,这样StreamingContext和SparkContext就不会被杀掉了可以继续执行其他的逻辑
利用checkpoint存储driver
sparkStreaming也有个chkpoint,它保存的是driver中的信息(sparkconf,对Dstream的操作逻辑,哪些batch已经处理,哪些没有处理,batch中有多个job,所以还包括哪些job被执行,哪些没有被执行),下次driver重启之后直接用这些元信息就可以恢复
内容
SparkStreaming利用UpdateStateByKey算子做数据增量更新操作,UpdateStateByKey算子第一个参数表示相同key所对应的计数值的集合,第二个参数表示状态值,状态值可以是任意类型,SparkStreaming会在使用updateStateByKey的时候为已经存在的key进行state的状态自动更新,对于每个新出现的key也会执行state的更新函数操作,如果通过更新函数对state更新后返回noe的话,此时该key对应的state会被删除掉,如果要不断的更新每个key的state,就会涉及到了状态的保存和容错,这个时候就需要开启checkpoint机制和功能,UpdateStateByKey算子会自动调用checkpoint方法
UpdateStateByKey算子每处理一个DStream就会向内存中写一份状态数据,如果batch的时间小于10s,那么每10s会由内存向hdfs中保存一份,如果大于10s那么每个batch向内存中写数据后,内存马上会写磁盘一份
根据该功能实现了wordcount持续累加的功能,代码如下:
val sparkconf = new SparkConf().setAppName("application").setMaster("local[2]")
val streamingContext = new StreamingContext(sparkconf,Seconds(5))
streamingContext.checkpoint("hdfs://hadoop1:9000/目录")
streamingContext.socketTextStream("ip",9999).flatMap(_.split(" ")).map((_,1)).updateStateByKey((x:Seq[Int],y:Option[Int])=>(Some(x.sum+y.getOrElse(0)))).print()
streamingContext.start()
streamingContext.awaitTermination()
streamingContext.stop()
窗口操作和窗口滑动
如果一个DStream的定时器为2,而窗口时间为4,窗口滑动时间为2,那么一个窗口内会有两个batch,这两个batch在执行的时候会合并为一个DStream进行操作,滑动时间一般设置小于窗口时间,因此会有一些重复值
窗口操作可用来查看最近一段时间内最新的消息的情况,所以即使在滑动的时候有重复值也没关系
窗口大小必须是定时器设定的整数倍,否则会将一个batch数据切开,而在SparkStreaming中这样的数据会被丢弃并且窗口滑动时间也必须是定时器设定时间的整数倍不然会报错
示例:通过reducebykeyandwindows算子实现滑动窗口的热点搜索词实时统计,代码如下
val sparkconf = new SparkConf().setAppName("application").setMaster("local[2]")
val streamingContext = new StreamingContext(sparkconf,Seconds(10))
streamingContext.checkpoint("hdfs://hadoop1:9000/sscheckpoint")
val dataDStrem: DStream[(String, Int)] = streamingContext.socketTextStream("hadoop1", 9999).map(x=>((x.split("\t")(1),1)))
//dataDStrem.reduceByKeyAndWindow((x:Int,y:Int)=>(x+y),Seconds(60),Seconds(20))窗口大小60s,滑动窗口时间20s,每隔20s计数最近60s内的数据,优化后如下
dataDStrem.reduceByKeyAndWindow(_+_,_-_,Seconds(60),Seconds(20)).transform(rdd=>{
rdd.collect().foreach(println(_))//这行是在Driver端执行,如果现在从dstream中抽取rdd执行action操作,那么会在生成job的时候触发任务,所以在这里面可以动态改变广播变量进行做预警,因为是driver端执行
val sortedSearchWordCountsRDD= rdd.map(x=>(x._2,x._1)).sortByKey(false).map(x=>(x._2,x._1))
sortedSearchWordCountsRDD.take(3).foreach(x=>(println(x._1+":"+x._2)))
sortedSearchWordCountsRDD
}).print()
streamingContext.start()
streamingContext.awaitTermination()
streamingContext.stop()
reducebykeyandwindows算子的优化:比如上个窗口内有个3个batch,batch1、batch2、batch3,现在经过窗口滑动后新窗口内的batch为batch2、batch3、batch4,而它的操作是上一个窗口加上batch4再减去batch1得到的
使用reducebykeyandwindows算子必须设置checkpoint目录来维护每个key,reduceByKeyAndWindow是针对窗口操作而不是针对DStream操作
使用transform算子可以对DStream中每个rdd进行操作,但是需要返回一个rdd
SparkStreaming整合Kafka(官网->Advanced Sources->Kafka Integration Guide添加jar包)
SparkStreaming通常会和kafka搭配,kafka起到缓冲的作用,因为流式处理是无法估算什么时间有多少数据,kafka和流式计算框架整合可以起到解耦的作用,SparkStreaming不会关心数据源来自哪里,处理完的数据也不关心最终会保存到什么地方
两种方式
1.kafka推数据到sparkStreaming
SparkStreaming中有个receiver,它是永久启动用来接收数据使用,它是一个job默认情况下只有一个task在一个executor中执行,它的数据存储级别是memory_and_disk_ser_2,有备份且有序列化,所以接过来的数据会在两个或多个executor中
receiver接收kafka的数据,是kafka的消费者,数据的偏移量由receiver自己管理,它会将偏移量放在zookeepper中,每接收一条数据就会向zookeeper汇报,下次读数据的偏移量就是当前的加1,如果在接收数据的过程中receiver挂掉了,而且接收的数据还没有及时计算和备份,这样会造成数据丢失,因此出现了wal机制(预写日志)kafka每发送一条数据向receiver也会向hdfs发送一份,但是这样性能贵降低
receiver中还有个反压机制,一个DStream会触发一个job,反压机制会根据上一个DStream的处理情况对当前DStream接收数据进行限流,当然也可手动限流
示例代码如下
val sparkconf = new SparkConf().setAppName("application").setMaster("local[2]")
.set("spark.streaming.receiver.writeAheadLog.enable","true")//开启receiver机制
val streamingContext = new StreamingContext(sparkconf,Seconds(5))
streamingContext.checkpoint("hdfs://hadoop1:9000/checkpoint")
val topicConsumerConcurrency = Map("Hello_Kafka"->1)
//参数一StreamingContext,参数二ZooKeeper集群信息,接受Kafka数据的时候会从Zookeeper中获得Offset等元数据信息
//参数三组,参数四消费的Topic以及并发读取Topic中Partition的线程数
//如果用5个参数的createStream(),可以设置receiver的存储级别
//如果有多个receiver,可以如下操作
//val numStreams = 5
// val kafkaStreams = (1 to numStreams).map { i => KafkaUtils.createStream(...)}
//val unifiedStream = streamingContext.union(kafkaStreams)
KafkaUtils.createStream(streamingContext,"hadoop1:2181,hadoop2:2181,hadoop3:2181","Group",topicConsumerConcurrency)
.map(x=>(x._2.split(" "),1)).reduceByKey(_+_).print()
streamingContext.start()
streamingContext.awaitTermination()
streamingContext.stop()
2.sparkStreaming直接到kafka中取数据
executor中的task会直接从Kafka中拿数据,消息偏移量由sparkStreaming自己管理,偏移量信息放到hdfs中(由task自己放),如果task执行失败了,sparkStreaming自己会知道失败了,那么偏移量不会增加,只有成功才会增加
这种机制也会有问题,比如task处理一批数据的过程中失败了,由于task自己放偏移量信息到hdfs,如果过程中失败了,那么就会出问题,但是没有备份性能要比wal机制要高
示例代码如下
val sparkconf = new SparkConf().setAppName("application").setMaster("local[2]")
val streamingContext = new StreamingContext(sparkconf,Seconds(5))
streamingContext.checkpoint("hdfs://hadoop1:9000/checkpoint")
//broker的url,不是zookeeper管理偏移量,所以直接从broker中拿
val kafkaParameters = Map("metadata.broker.list"->"hadoop1:9092,hadoop2:9092,hadoop3:9092")
val topics = Set("Hello_Kafka")
//StringDecoder是kafka.serializer.StringDecoder中
KafkaUtils.createDirectStream[String,String,StringDecoder,StringDecoder](streamingContext,kafkaParameters,topics)
.map(x=>(x._2.split(" "),1)).reduceByKey(_+_).print()
streamingContext.start()
streamingContext.awaitTermination()
streamingContext.stop()
SparkStreaming与Stream的选型
Stream是一个准实时计算框架,Storm对事务机制的支持比较好,可以实现来一条数据即处理一条数据,可以支持动态调整并行度,当数据量比较大的时候则会自动将并行度增大,合理运行任务
SparkStreaming微批处理比stream吞吐量高,Spark生态比较好
因此,如果数据来自股票、银行、等金融数据要求事务机制比较高或者集群的资源比较紧张的情况下可以使用Storm,如果事务机制要求没有这么高并且集群资源比较宽松可以采用SparkStreaming
spark搭建
需要先安装jdk,修改/etc/hosts文件
免密钥操作
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
spark官网下载:http://spark.apache.org/downloads.html
旧版本下载:https://archive.apache.org/dist/spark/
笔者采用的是spark-2.3.3-bin-hadoop2.7.tgz版本
对解压后conf中slaves.template和spark-env.sh.template文件进行复制为slaves和spark-env.sh文件并修改
slaves文件添加从节点的主机名或ip
spark-env.sh文件中添加
export SPARK_MASTER_IP=master # 主节点ip
export SPARK_MASTER_PORT=7077 # 提交程序使用的端口
export SPARK_WORKER_CORES=1 # worker里面的资源个数
export SPARK_WORKER_INSTANCES=1 # 一台节点中可以启动1个worker,默认1个
export SPARK_WORKER_MEMORY=512m # worker内存
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop # 如果采用的是yarn资源调度器需要加上
节点同步spark目录
sbin下启动start-all.sh(start-all只是启动了master和worker,也就是spark的standalone的资源调度器而已)如果是yarn模式则不需要启动
例如:执行命令
./bin/spark-submit --class org.apache.spark.examples.SparkPi --master spark://master:7077 --executor-memory 512m --total-executor-cores 1 ./examples/jars/spark-examples_2.11-2.3.3.jar 100
该命令表示为standalone资源调度器下client模式,执行./examples/jars/spark-examples_2.11-2.3.3.jar包中org.apache.spark.examples.SparkPi类,主节点为spark://master:7077,executor内存使用512M,这个集群的core只有1个,因为--total-executor-cores表示集群的core数,最后100表示100个线程数,也是agrs[0]
./bin/spark-submit --class org.apache.spark.examples.SparkPi --master spark://centos:7077 --deploy-mode cluster --supervise --executor-memory 512M --total-executor-cores 1 ./examples/jars/spark-examples_2.11-2.3.3.jar 100
该命令表示为standalone资源调度器下cluster模式,执行./examples/jars/spark-examples_2.11-2.3.3.jar包中org.apache.spark.examples.SparkPi类,主节点为spark://master:7077,当集群中driver挂了那么supervise会重新启动driver,executor内存使用512M,这个集群的core只有1个,因为--total-executor-cores表示集群的core数,最后100表示100个线程数
cluster中driver默认需要的内存是1G,指定driver内存--driver-memory 512m
./bin/spark-submit --class org.apache.spark.examples.SparkPi --master yarn-client --executor-memory 512m --num-executors 1 ./examples/jars/spark-examples_2.11-2.3.3.jar 100
该命令表示为yarn资源调度器下client模式,执行./examples/jars/spark-examples_2.11-2.3.3.jar包中org.apache.spark.examples.SparkPi类,executor内存使用512M,有1个executor来执行,最后100表示100个线程数
./bin/spark-submit --class org.apache.spark.examples.SparkPi --master yarn-cluster --executor-memory 512m --num-executors 1 ./examples/jars/spark-examples_2.11-2.3.3.jar 100
该命令表示为yarn资源调度器下cluster模式,执行./examples/jars/spark-examples_2.11-2.3.3.jar包中org.apache.spark.examples.SparkPi类,executor内存使用512M,有1个executor来执行,最后100表示100个线程数
spark集群高可用
对master节点使用zookeeper做高可用,master中的信息只有driver、worker、application的注册信息,所以只需要将这三个注册信息同步到zookeeper中即可,而且如果application正在运行,恢复master是不受影响的,因为application在运行之前已经将所有需要的资源全部申请到了,因此即使正在触发action算子执行application也是没有关系的,但是如果正在恢复的过程中执行application则会报错
搭建方法:
修改spark-env.sh文件,在spark集群的配置基础上添加
export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=node1:2181,node2:2181,node3:2181 -Dspark.deploy.zookeeper.dir=/spark_2019411"
其中spark.deploy.recoveryMode # 值为zookeeper,表示用zookeeper模式做高可用
spark.deploy.zookeeper.url # zookeeper的url
spark.deploy.zookeeper.dir # spark在znode中的目录(znode就是zookeeper节点)
然后选择准备standby状态的master节点,修改其spark-env.sh文件spark_master_ip需要修改成standby状态的master节点的ip,启动./sbin/spark-master.sh
可运行./bin/spark-shell --master spark://node1:7077,node2:7077 --executor-memory 512m命令来尝试
查漏补缺
1.用户应用程序application可分为driver端运行程序和worker中executor运行的程序,driver端运行的则为main函数,executor运行算子逻辑,executor运行action算子所得到的数据集会返回给driver端程序,并对结果可以进行操作,driver端除了运行main方法和接收action算子运算的结果外,还创建SparkContext作为spark程序的入口,SparkContext被创建的时候还会创建两个调度器DAGScheduler和taskScheduler,DAGScheduler是高层调度器负责对job划分成stage,taskScheduler是底层调度器负责将task调度到集群中运行
2.clusterManager在集群上获取资源的外部服务,比如standalone和yarn
3.worker可以运行spark应用的节点
4.executor在worker中为spark应用启动task进程,task进程负责运行任务如果有需要还负责将结果存储在内存或者磁盘中,每个应用都会有各自的executor
5.运行spark-submit命令时,如果不做任何配置的情况下,一个应用程序在一个worker上只启动1个executor
6.task是被送到executor上的工作单元,运行在executor中每个task进程中
7.application会被划分为多个job,job根据shuffle又会被划分成多个stage,stage由task组成
8.集群模式下worker中有executor,executor中有线程池,线程池中的线程会执行task
9.每个job可以看成触发了一次action算子
10.core并行的线程数
11.其实并没有将hdfs中block数据加载到partition当中,而是在partition中指定了对应哪一个block,相当于namenode里面的索引(元数据)
12.spark的并行度和cpu的并行度不是一个概念,cpu的并行度是不计算时间的切换同时执行多少任务,spark的并行度表示stage有多少task,但是可能不是同时执行,比如worker中可以同时执行100个(也是cpu并行度),而spark的并行度是10000的话它会分成100批来执行
13.一般来说并行度设置为core的2-3倍,可以充分利用core,比如服务器中core的个数有10个,那么可以同时并行执行10个task,
14.DAGscheduler是在触发action算子的时候进行切分job
15.DAGscheduler会记录哪个rdd或stage被持久化
16.TaskScheduler为每个taskSet的维护都有一个taskSetManager(追踪每个task的执行情况)
17.DAGscheduler基于stage构建DAG有向无环图,根据block分区位置来决定每个任务的最佳位置,每个task处理hdfs上的block
18.partition也是通过mr的split()方法一条一条读hdfs中block数据,每一条数据经过管道上的算子操作,中间的数据集并没有落地,相当于1+1+1+1=4而非1+1=2;2+1=3;3+1=4,如果进行持久化(cache和persist),数据会留到内存或磁盘中相当于备份,所以spark如果不进行cache和persist,它占用内存也是很少的,可如果不进行cache和persist,spark程序又不是很快
19.集群中同时有多少个并行的task,就会有多少条数据正在运行,如果集群中同时运行一万条task而且在没有持久化的情况下,就用一条数据的大小乘以一万就是占用的内存数
20.Scala提供的方法是单机进行的,spark提供的是集群中进行的,使用起来没有区别,运行起来会不一样
21.application只有注册到master内存中,master才会给其分配资源
22.给application分配资源的最小单位是一个executor
23.给executor分配的默认最小core个数为1,可以自行配置
24.spark-shell也是一个application,里面调用了spark-submit,只是内部实现的是repl模式,比如使用:./spark-shell --master spark://node:7077 --executor-memory 512m 默认client模式,提交的主节点,每一个executor的内存
25.每一个partition是由一个task线程来执行
26.join有可能是窄依赖,也可能是宽依赖,如果两个父rdd使用分区器进行重分区,然后shuffle时子rdd使用了相同的分区器进行分区就是窄依赖,否则就是是宽依赖
27.在使用join算子的时候可以通过广播变量不产生shuffle,比如rdd1.join(rdd2),可以先将rdd2结果的值转成map形式,再广播出去,这样就不会产生shuffle
28.dataFrame的collect()方法,action操作,返回Array[row]数组
29.spark-shell中会自动创建sparkcontext和sqlContext,可直接使用
30.sparkSql中下推过滤器,比如:两表中数据通过filter过滤然后再join比两表先join然后再过滤的效率高
31.jdbc连接数据库
Class.forName("com.mysql.jdbc.Driver");
Connection conn = null;
Statement stmt = null;
try {
conn = DriverManager.getConnection("jdbc:mysql://IP:3306/库","用户名","密码");
stmt = conn.createStatement();
stmt.executeUpdate(sql);
} catch (Exception e) {
e.printStackTrace();
} finally {
if (stmt != null) {
stmt.close();
}
if (conn != null) {
conn.close();
}
}
浅谈spark的更多相关文章
- 浅谈Spark应用程序的性能调优
浅谈Spark应用程序的性能调优 :http://geek.csdn.net/news/detail/51819 下面列出的这些API会导致Shuffle操作,是数据倾斜可能发生的关键点所在 1. g ...
- 浅谈Spark Kryo serialization
原创文章,转载请注明: 转载自http://www.cnblogs.com/tovin/p/3833985.html 最近在使用spark开发过程中发现当数据量很大时,如果cache数据将消耗很多的内 ...
- 浅谈Spark(1) - Overview
Spark是UC Berkeley AMP lab所开源的类Hadoop MapReduce的通用并行框架,Spark,拥有Hadoop MapReduce所具有的优点:但不同于MapReduce的是 ...
- 浅谈压缩感知(二十):OMP与压缩感知
主要内容: OMP在稀疏分解与压缩感知中的异同 压缩感知通过OMP重构信号的唯一性 一.OMP在稀疏分解与压缩感知中的异同 .稀疏分解要解决的问题是在冗余字典(超完备字典)A中选出k列,用这k列的线性 ...
- 浅谈 Fragment 生命周期
版权声明:本文为博主原创文章,未经博主允许不得转载. 微博:厉圣杰 源码:AndroidDemo/Fragment 文中如有纰漏,欢迎大家留言指出. Fragment 是在 Android 3.0 中 ...
- 浅谈 LayoutInflater
浅谈 LayoutInflater 版权声明:本文为博主原创文章,未经博主允许不得转载. 微博:厉圣杰 源码:AndroidDemo/View 文中如有纰漏,欢迎大家留言指出. 在 Android 的 ...
- 浅谈Java的throw与throws
转载:http://blog.csdn.net/luoweifu/article/details/10721543 我进行了一些加工,不是本人原创但比原博主要更完善~ 浅谈Java异常 以前虽然知道一 ...
- 浅谈SQL注入风险 - 一个Login拿下Server
前两天,带着学生们学习了简单的ASP.NET MVC,通过ADO.NET方式连接数据库,实现增删改查. 可能有一部分学生提前预习过,在我写登录SQL的时候,他们鄙视我说:“老师你这SQL有注入,随便都 ...
- 浅谈WebService的版本兼容性设计
在现在大型的项目或者软件开发中,一般都会有很多种终端, PC端比如Winform.WebForm,移动端,比如各种Native客户端(iOS, Android, WP),Html5等,我们要满足以上所 ...
- 浅谈angular2+ionic2
浅谈angular2+ionic2 前言: 不要用angular的语法去写angular2,有人说二者就像Java和JavaScript的区别. 1. 项目所用:angular2+ionic2 ...
随机推荐
- 通过Google Cloud Storage(GCS)管理Terraform的状态State
管理Terraform状态文件的最佳方式是通过云端的统一的存储,如谷歌云就用GCS. 首先要创建一个Bucket: $ gsutil mb -p pkslow -l us-west1 -b on gs ...
- 02-Tcl输出、赋值与替换
2 Tcl输出.赋值与替换 2.1 puts Tcl的输出命令是puts,将字符串标准输出channelled.语法中两个问号之间的参数为可选参数. # 例1 puts hello # 输出 hell ...
- C#动态创建对象过程
创建对象环境 获取当前应用程序集引用的类库详细信息,动态类也将调用此类库 obj类为项目动态编译时用到的模版类,主要提取其using信息用于动态生成的类使用 1 AssemblyName[]r ...
- Grafana 系列文章(二):使用 Grafana Agent 和 Grafana Tempo 进行 Tracing
️URL: https://grafana.com/blog/2020/11/17/tracing-with-the-grafana-cloud-agent-and-grafana-tempo/ ✍A ...
- Node.js 应用全链路追踪技术——全链路信息存储
作者:vivo 互联网前端团队- Yang Kun 本文是上篇文章<Node.js 应用全链路追踪技术--全链路信息获取>的后续.阅读完,再来看本文,效果会更佳哦. 本文主要介绍在Node ...
- 论文翻译:2022_Time-Shift Modeling-Based Hear-Through System for In-Ear Headphones
论文地址:基于时移建模的入耳式耳机透听系统 引用格式: 摘要 透传(hear-through,HT)技术是通过增强耳机佩戴者对环境声音的感知来主动补偿被动隔离的.耳机中的材料会减少声音 500Hz以上 ...
- 【模板】倍增求LCA
题目链接 一. 时间戳法(本质上是dfs序) #include<cstdio> using namespace std; const int NN = 5e5+8; int n,m,s; ...
- 强大的word插件,让工作更高效:不坑盒子 2023版
不坑盒子简介 很多朋友在工作过程中需要对Word文档进行编辑处理,如果想让Word排版更有效率可以试试小编带来的这款不坑盒子软件,这是一个非常好用的插件工具,专门应用在Word文档中,支持Office ...
- ASP.NET Core - 请求管道与中间件
1. 请求管道 请求管道是什么?请求管道描述的是一个请求进到我们的后端应用,后端应用如何处理的过程,从接收到请求,之后请求怎么流转,经过哪些处理,最后怎么返回响应.请求管道就是一次请求在后端应用的生命 ...
- Mybatis Plus 框架项目落地实践总结
在使用了Mybatis Plus框架进行项目重构之后,关于如何更好的利用Mybatis plus.在此做一些总结供大家参考. 主要总结了以下这几个方面的实践. 基础设计 BaseEntity 逻辑删除 ...