第三方模块:requests模块和openpyxl模块
1.第三方模块的下载应由
第三方模块:别人写的模块 一般情况下功能都特别强大
我们如果想使用第三方模块 第一次必须先下载后面才可以反复使用(等同于内置模块)
下载第三方模块的方式
1.pip工具
注意每个解释器都有pip工具 如果我们的电脑上有多个版本的解释器那么我们在使用pip的时候一定要注意到底用的是哪一个 否则极其任意出现使用的是A版本解释器然后用B版本的pip下载模块
为了避免pip冲突 我们在使用的时候可以添加对应的版本号
python27 pip2.7
python36 pip3.6
python38 pip3.8
下载第三方模块的句式
pip install 模块名
下载第三方模块临时切换仓库
pip install 模块名 -i 仓库地址
下载第三方模块指定版本(不指定默认是最新版)
pip install 模块名==版本号 -i 仓库地址
2.pycharm提供快捷方式
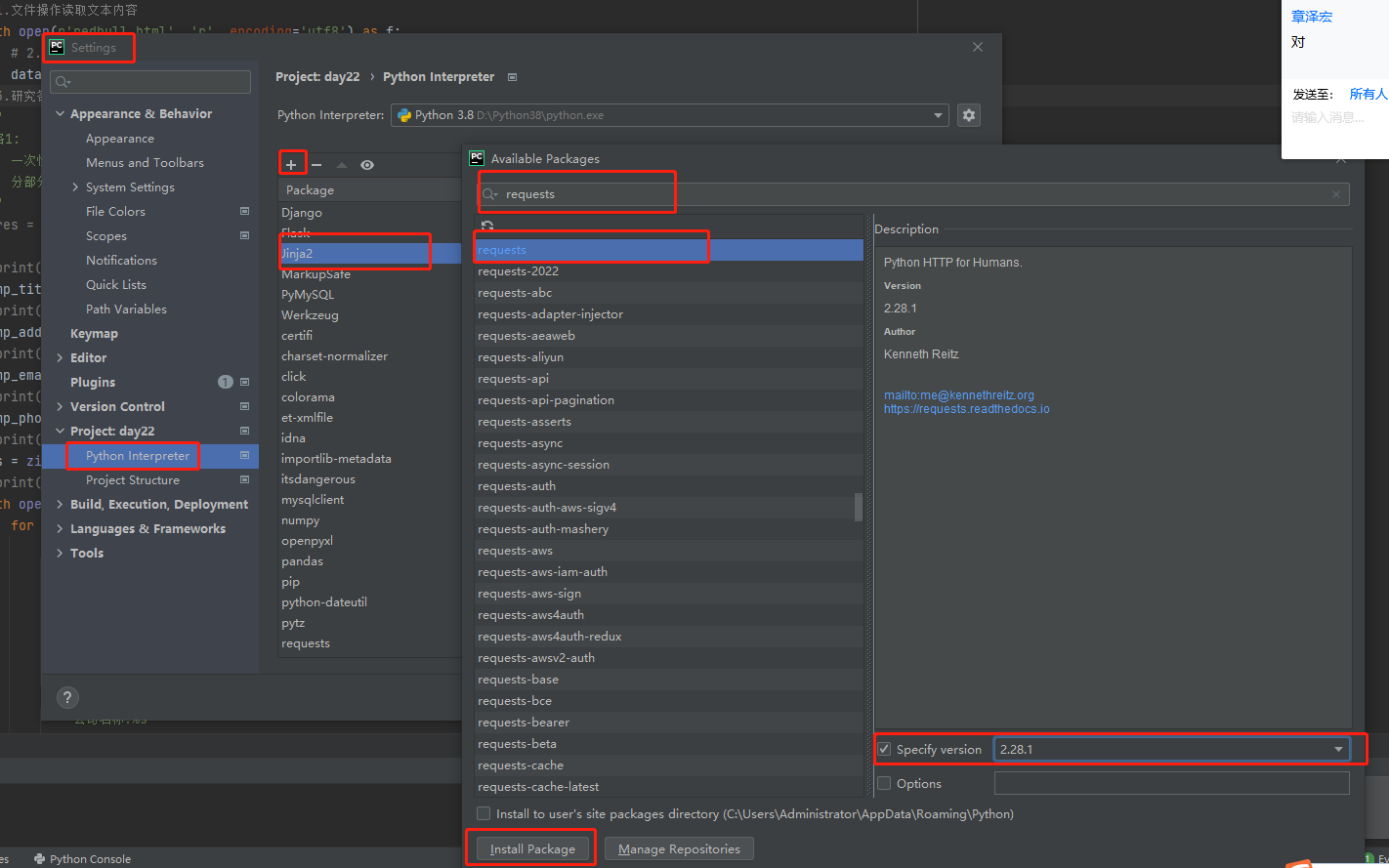
"""
下载第三方模块可能会出现的问题
1.报错并有警告信息
WARNING: You are using pip version 20.2.1;
原因在于pip版本过低 只需要拷贝后面的命令执行更新操作即可
d:\python38\python.exe -m pip install --upgrade pip
更新完成后再次执行下载第三方模块的命令即可
2.报错并含有Timeout关键字
说明当前计算机网络不稳定 只需要换网或者重新执行几次即可
3.报错并没有关键字
面向百度搜索
pip下载XXX报错:拷贝错误信息
通常都是需要用户提前准备好一些环境才可以顺利下载
4.下载速度很慢
pip默认下载的仓库地址是国外的 python.org
我们可以切换下载的地址
pip install 模块名 -i 仓库地址
pip的仓库地址有很多 百度查询即可
清华大学 :https://pypi.tuna.tsinghua.edu.cn/simple/
阿里云:http://mirrors.aliyun.com/pypi/simple/
中国科学技术大学 :http://pypi.mirrors.ustc.edu.cn/simple/
华中科技大学:http://pypi.hustunique.com/
豆瓣源:http://pypi.douban.com/simple/
腾讯源:http://mirrors.cloud.tencent.com/pypi/simple
华为镜像源:https://repo.huaweicloud.com/repository/pypi/simple/
"""
2.网络爬虫模块之requests模块
requests模块能够模拟浏览器发送网络请求,相当于获取网页源码
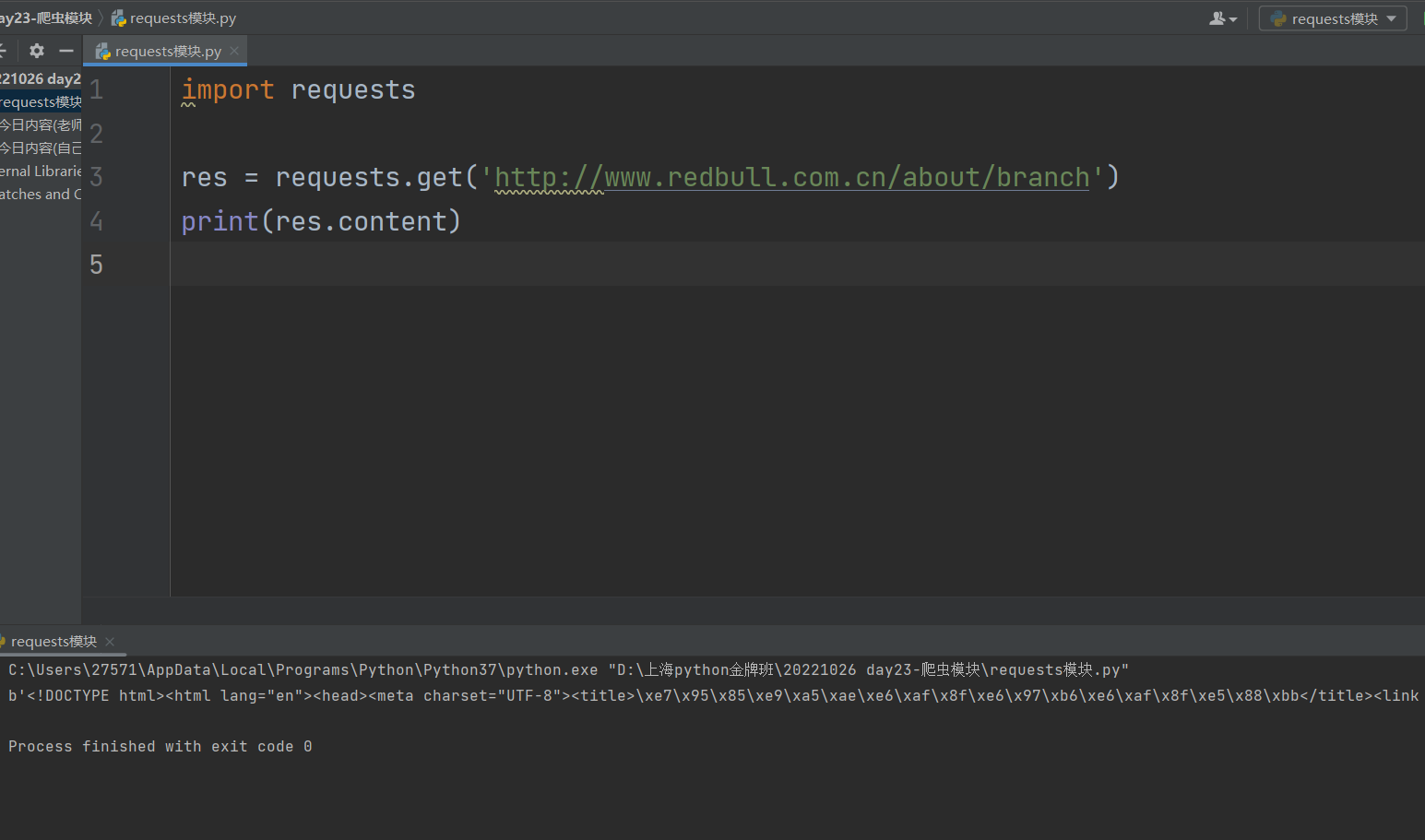
1.朝指定网址发送请求获取页面(等价于:浏览器地址栏输入网址回车访问),获取到的网页数据是二进制类型
import requests
res = requests.get('http://www.redbull.com.cn/about/branch')
print(res.content)
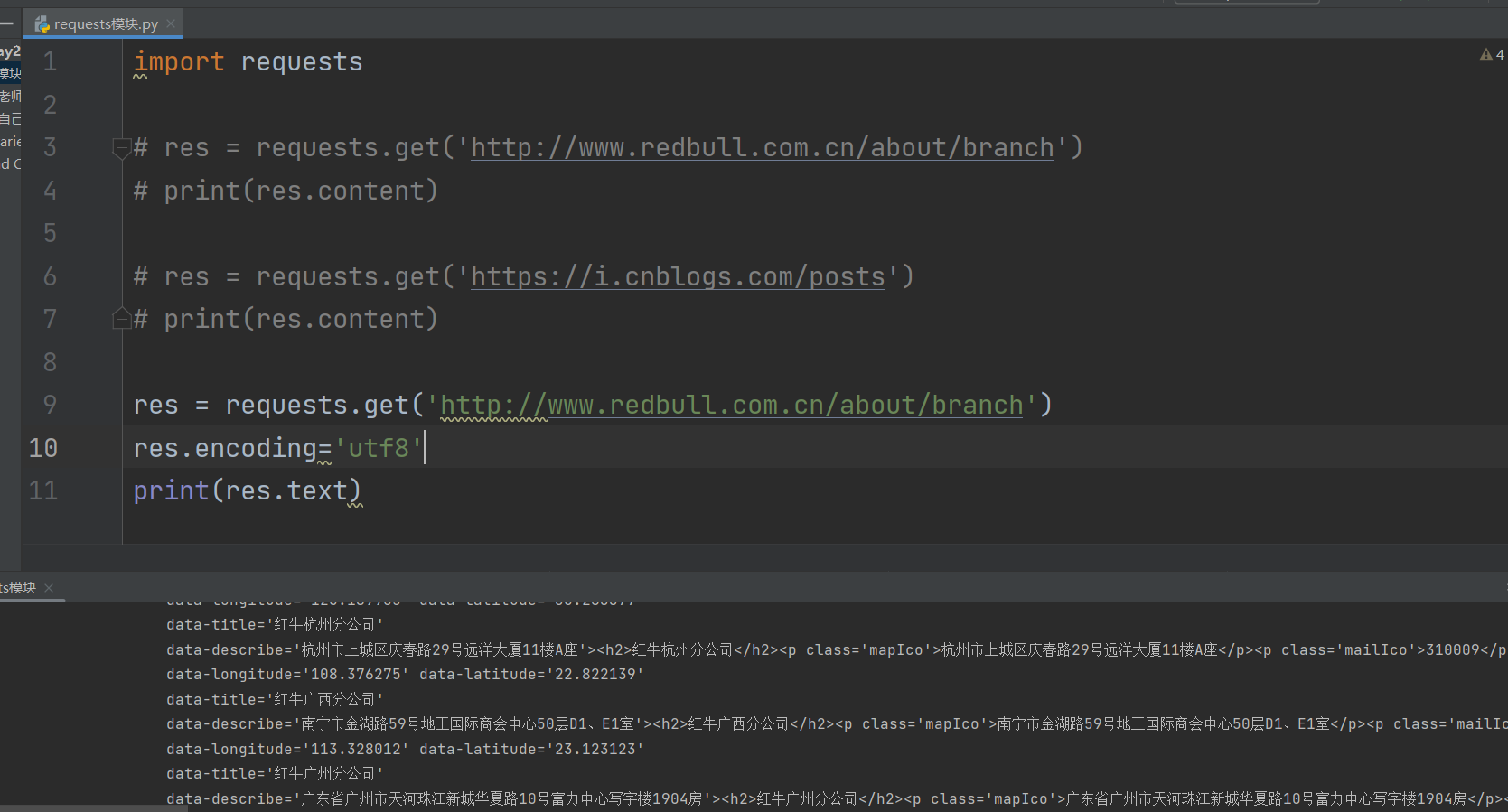
2.可以指定编码,按照utf8来解码,就可以看到正常的网页源码
res.encoding = 'utf8'
print(res.text)
3.网络爬虫实战之爬取链家二手房数据
用requests模块之后可以直接获取到网页的源码,不需要上网页复制
import requests
import re
res = requests.get('https://sh.lianjia.com/ershoufang/pudong/')
data = res.text
# print(data)
tittle_list = re.findall('data-is_focus="" data-sl="">(.*?)</a>', data) # 标题集合
street_list = re.findall('<a href=".*?" target="_blank">(.*?)</a> </div></div><div class="address">', data) # 街道
name_list = re.findall('data-log_index=".*?" data-el="region">(.*?) </a>', data) # 小区名
attention_list = re.findall('<div class="followInfo"><span class="starIcon"></span>(.*?) / .*?</div>', data) # 关注人数列表
total_list = re.findall('<div class="totalPrice totalPrice2"><i> </i><span class="">(.*?)</span><i>万</i>', data) # 总价
unit_list = re.findall('</div><div class="unitPrice" data-hid=".*?" data-rid=".*?" data-price=".*?"><span>(.*?)元/平</span></div></div></div><div class="listButtonContainer">', data) # 单价
res = zip(tittle_list, street_list, name_list, attention_list, total_list, unit_list)
# print(list(res))
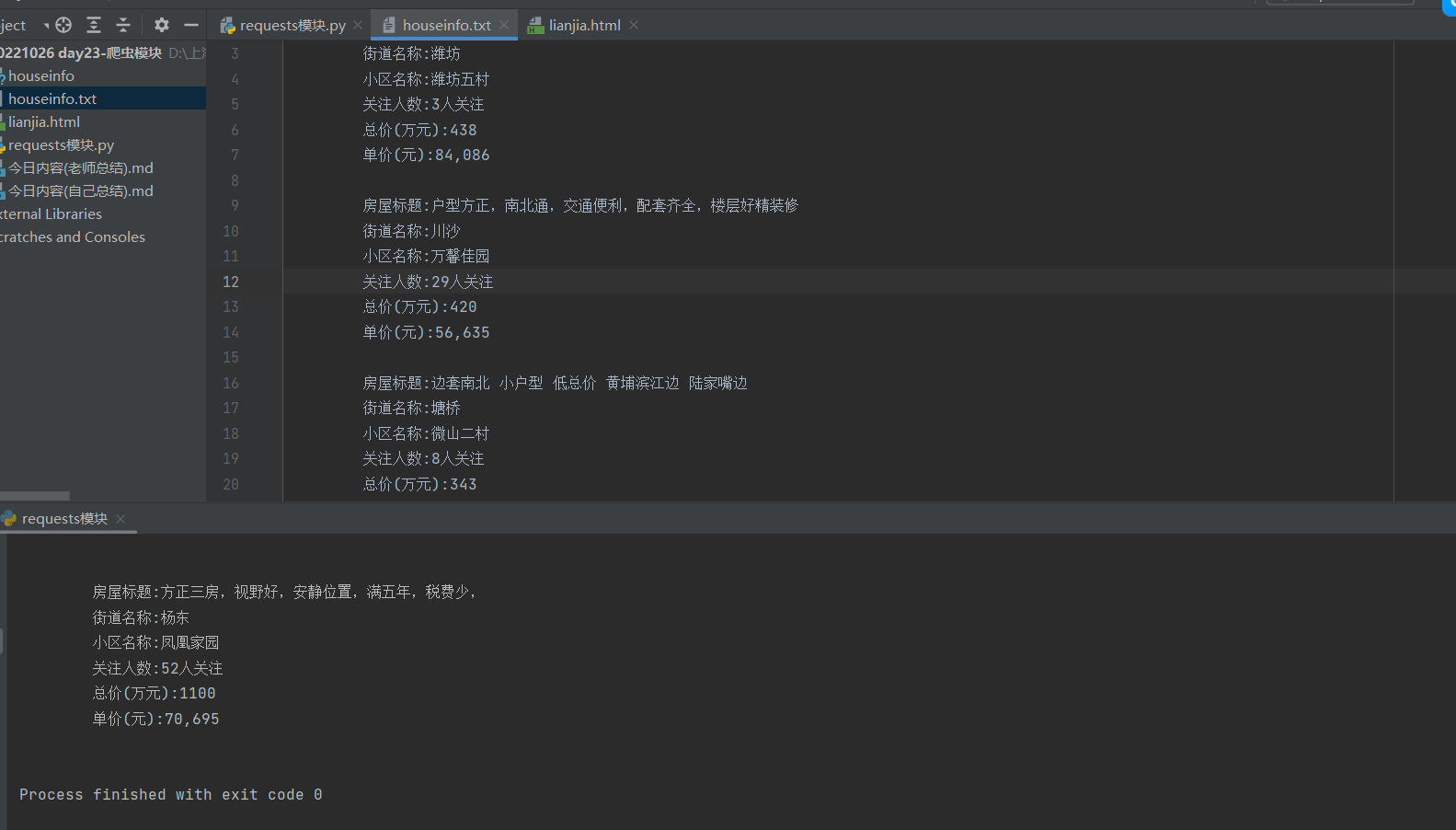
with open('houseinfo.txt', 'w', encoding='utf8') as f:
for data in res:
print("""
房屋标题:%s
街道名称:%s
小区名称:%s
关注人数:%s
总价(万元):%s
单价(元):%s
""" % data)
f.write("""
房屋标题:%s
街道名称:%s
小区名称:%s
关注人数:%s
总价(万元):%s
单价(元):%s
""" % data)
4.自动化办公领域至openpyxl模块
1.excel文件的后缀名问题
03版本之前
.xls
03版本之后
.xlsx
2.操作excel表格的第三方模块
xlwt往表格中写入数据、wlrd从表格中读取数据
兼容所有版本的excel文件
openpyxl最近几年比较火热的操作excel表格的模块
03版本之前的兼容性较差
ps:还有很多操作excel表格的模块 甚至涵盖了上述的模块>>>:pandas
3.openpyxl操作
1.导入模块
from openpyxl import Workbook
2.创建一个excel文件
wb = Workbook
3.创建多个工作簿()
wb1 = wb.create_sheet('帅哥名单')
wb2 = wb.create_sheet('靓女名单')
4.保存文件(保存文件一定要在所有操作最下面,如果保存文件下面还有操作则执行不了)
wb.save(r'111.xlsx')
5.改工作簿位置:想要把某个创立的工作簿放在最前面,只需要再工作簿第二个参数写上0
wb1 = wb.create_sheet('帅哥名单', 0)
6.如果文件栏多出一个文件,并且该文件前面有~说明该文件一打开
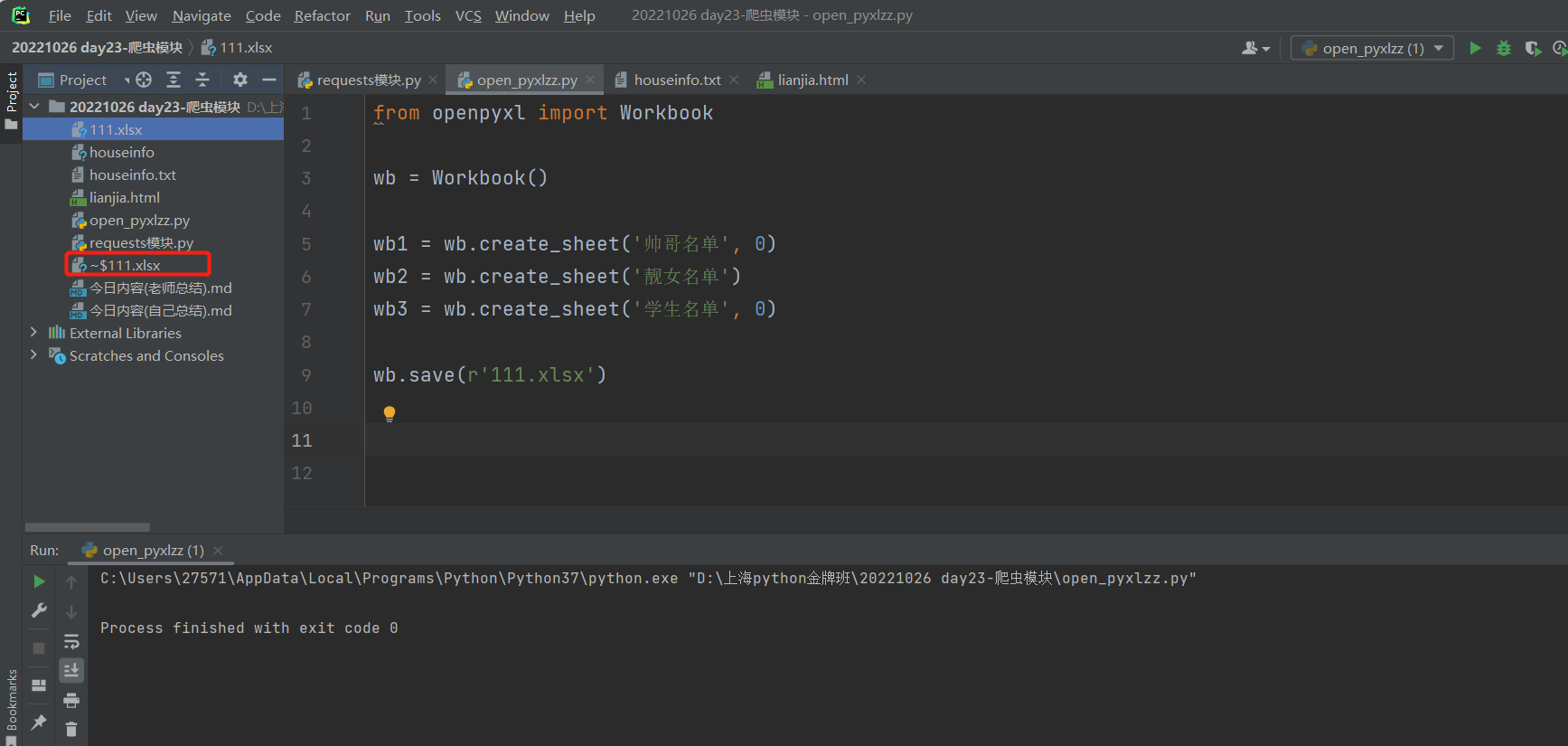
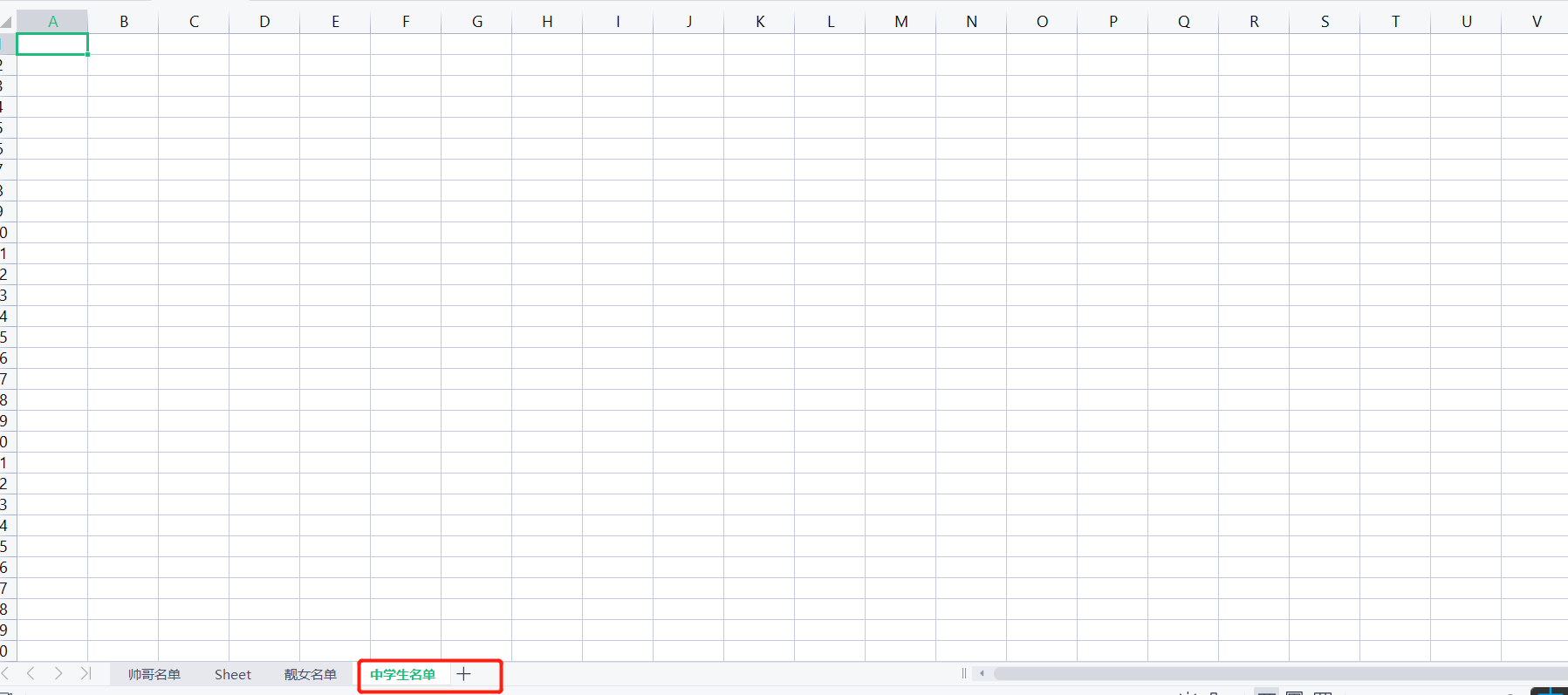
7.可以修改工作簿名称
wb3.title = '中学生名单'
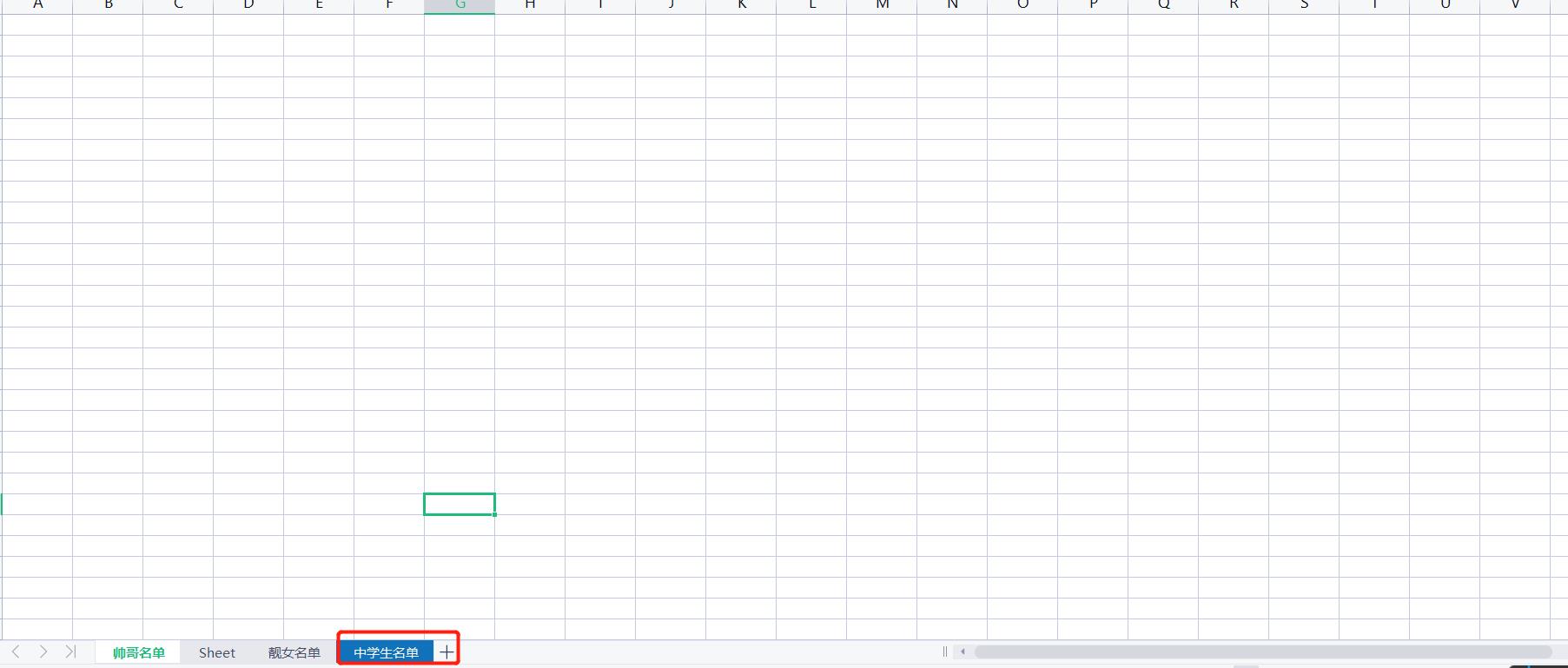
8.还可以改工作簿图标颜色
wb3.sheet_properties.tabColor = '1072BA'
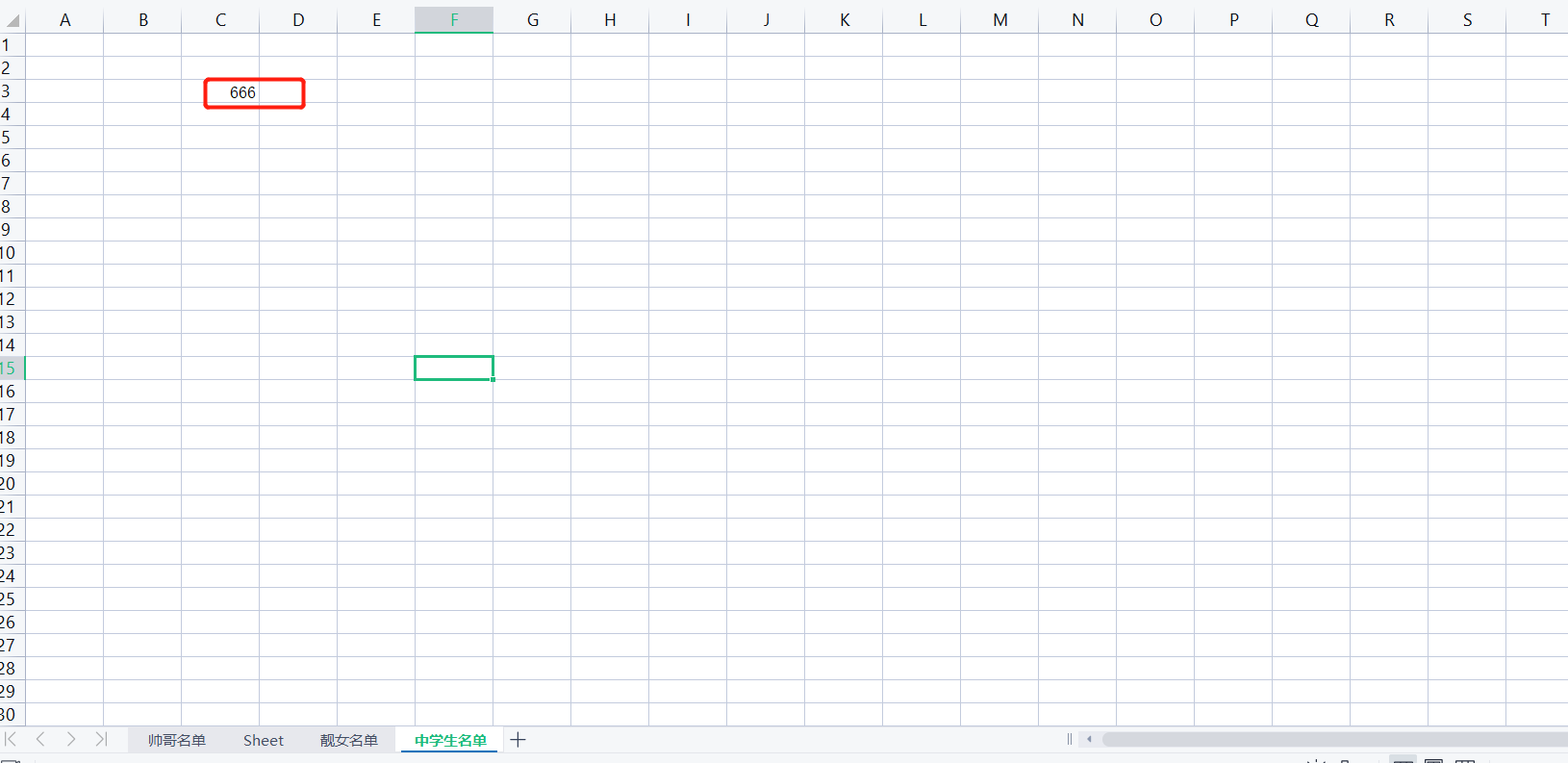
9.写入表格方式1:
wb3['C3'] = 666
10.写入表格方式2:row是行,column是列,value是插入的内容
wb3.cell(row=3, column=1, value='max')
11.写入数据方式3:
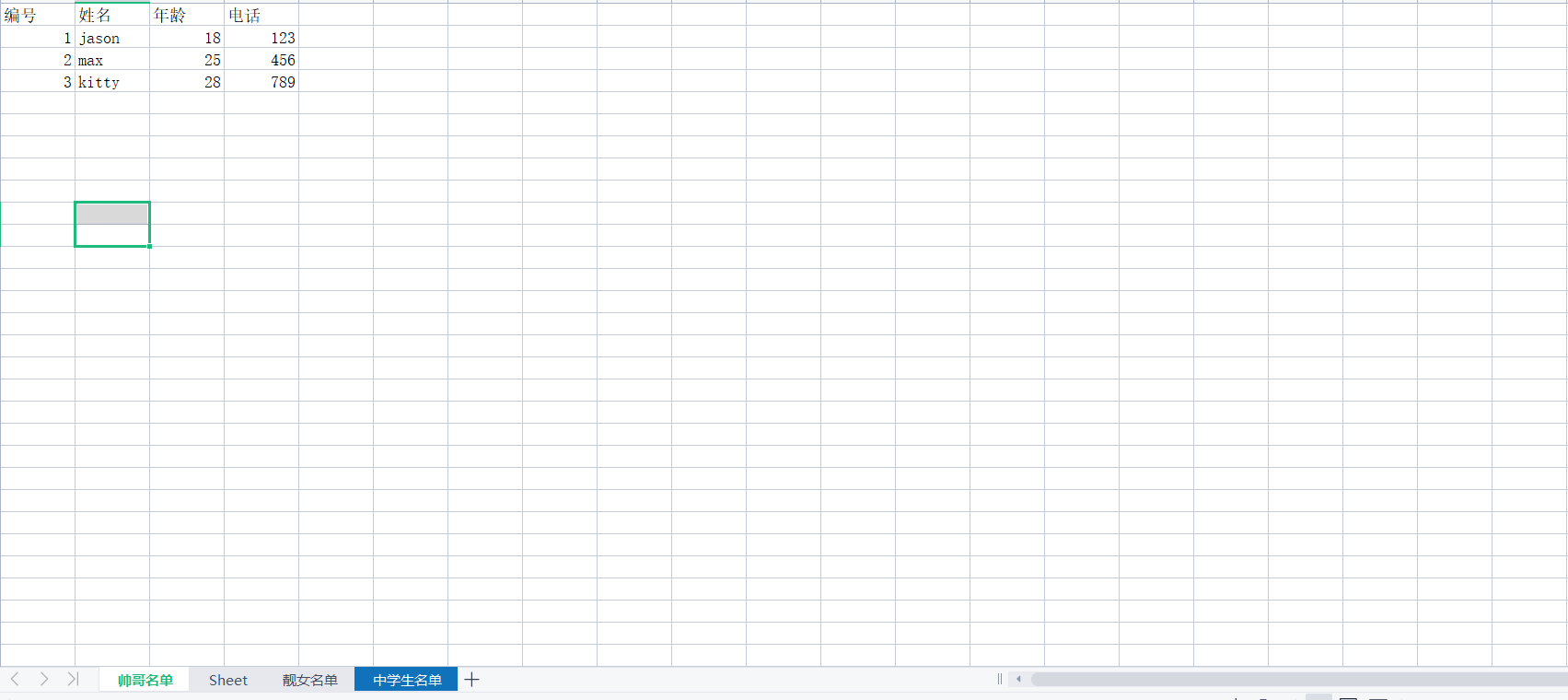
wb1.append(['编号', '姓名', '年龄', '电话'])
wb1.append([1, 'jason', 18, 123])
wb1.append([2, 'max', 25, 456])
wb1.append([3, 'kitty', 28, 789])
"""
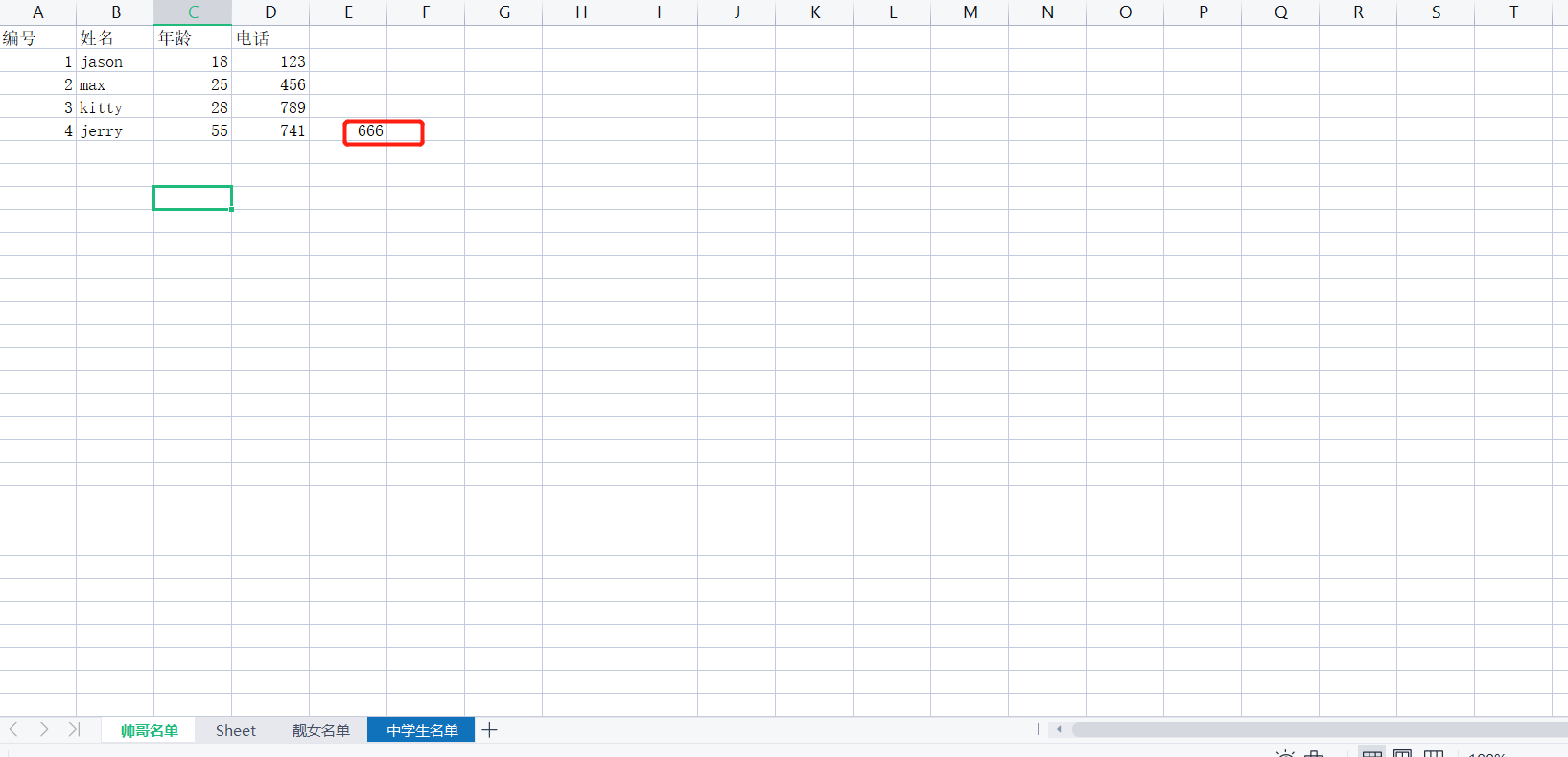
如果写入的数据列数和第一行不一样,有的信息未填写,那么直接按照顺序传入
"""
wb1.append([4, 'jerry', 55, 741, 666])
12.填写数学公式
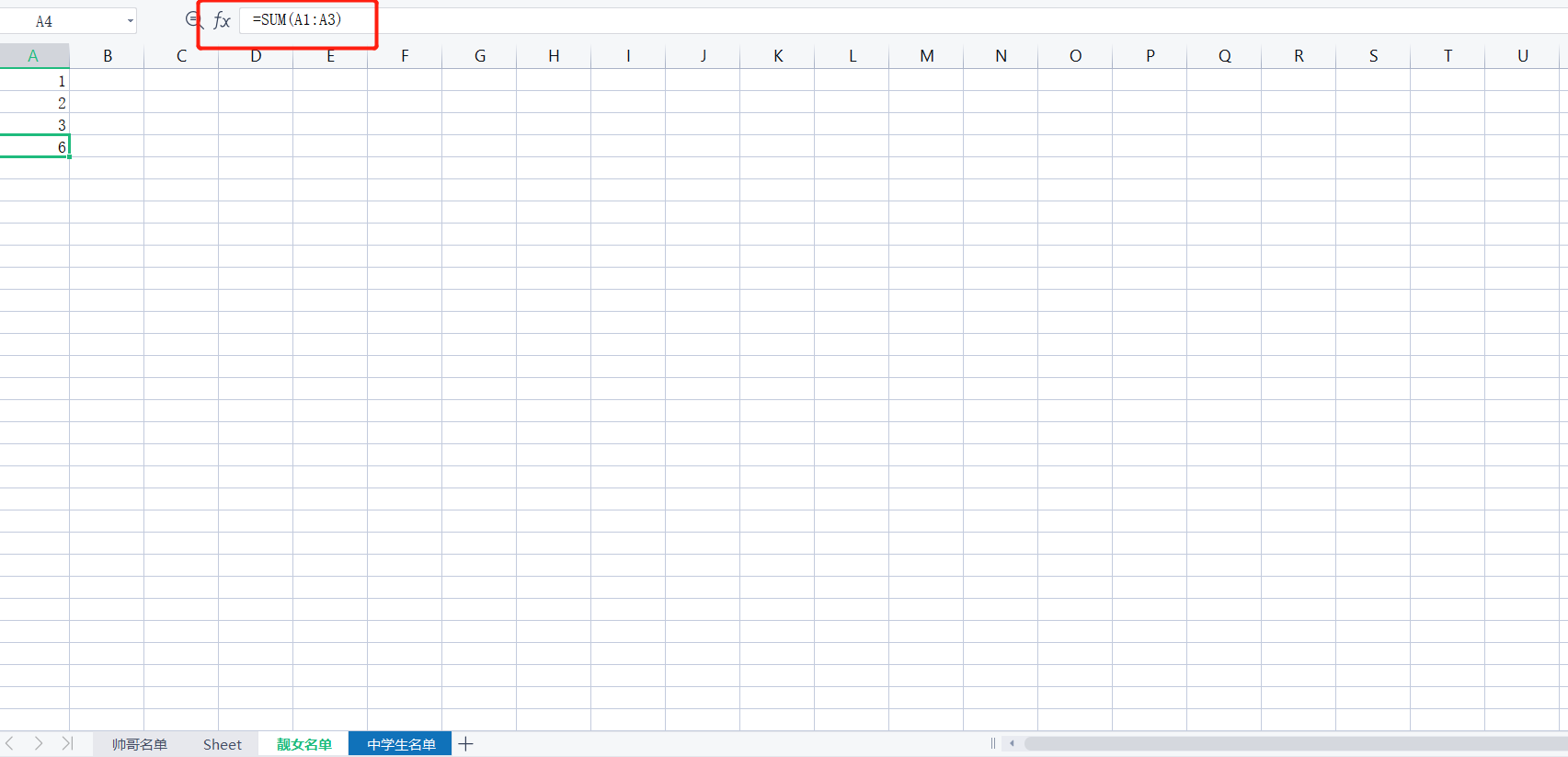
wb2.cell(row=1, column=1, value=1)
wb2.cell(row=2, column=1, value=2)
wb2.cell(row=3, column=1, value=3)
wb2['A4'] = '=sum(A1:A3)'
wb2.cell(row=5, column=1, value= '=sum(a1:a4)')
5.openpyxl模块实战
"""
整理链家网前十页房产信息,并且放在表格当中
"""
import requests
import re
from openpyxl import Workbook
wb = Workbook()
wb1 = wb.create_sheet('房产信息', 0)
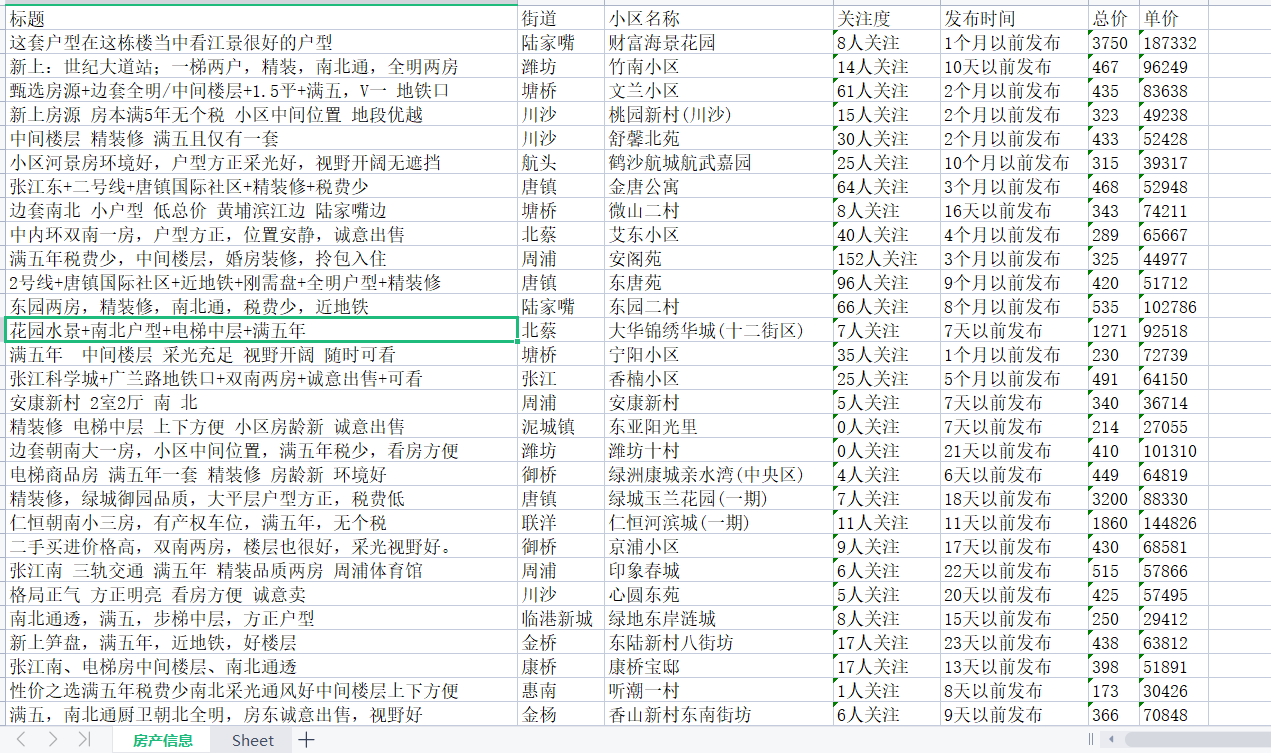
wb1.append(['标题', '街道', '小区名称', '关注度', '发布时间', '总价', '单价'])
for i in range(1, 11): # 以获取10页数据为例,每遍历一页地址就会改变一次
res = requests.get(f'https://sh.lianjia.com/ershoufang/pudong/') # 观察网页数据,页数变化体现在pg后面的数字,用for循环挨个获取
data = res.text
# 获取标题
title_list = re.findall(
'data-log_index=".*?" data-el="ershoufang" data-housecode=".*?" data-is_focus="" data-sl="">(.*?)</a>', data)
# 获取街道
street_list = re.findall(
'target="_blank">(.*?)</a> </div></div><div class="address"><div class="houseInfo"><span class="houseIcon">',
data)
# 获取小区名称
name_list = re.findall('target="_blank" data-log_index=".*?" data-el="region">(.*?) </a>', data)
# 获取关注度
attention_list = re.findall('</div></div><div class="followInfo"><span class="starIcon"></span>(.*?)/', data)
# 获取发布时间
time_list = re.findall('</div></div><div class="followInfo"><span class="starIcon"></span>.*? / (.*?)</div><div',
data)
# 获取总价
price_list = re.findall('<div class="totalPrice totalPrice2"><i> </i><span class="">(.*?)</span>', data)
# 获取单价
unit_price = re.findall('data-hid=".*?" data-rid=".*?" data-price="(.*?)"><span>', data)
group = zip(title_list, street_list, name_list, attention_list, time_list, price_list, unit_price)
# group是每页小区的信息集合的列表,用for循环遍历,i就是每个小区的信息
for i in group:
wb1.append(i)
wb.save(r'房产信息前十页.xlsx')
6.pandas模块
"""
openpyxl主要用于数据的写入 至于后续的表单操作它并不是很擅长 如果想做需要更高级的模块pandas
import pandas
data_dict = {
"公司名称": comp_title_list,
"公司地址": comp_address_list,
"公司邮编": comp_email_list,
"公司电话": comp_phone_list
}
# 将字典转换成pandas里面的DataFrame数据结构
df = pandas.DataFrame(data_dict)
# 直接保存成excel文件
df.to_excel(r'pd_comp_info.xlsx')
excel软件正常可以打开操作的数据集在10万左右 一旦数据集过大 软件操作几乎无效
需要使用代码操作>>>:pandas模块
"""
第三方模块:requests模块和openpyxl模块的更多相关文章
- Python基础之模块:5、 第三方模块 requests模块 openpyxl模块
目录 一.第三方模块的下载与使用 1.什么是第三方模块 2.如何安装第三方模块 方式一:pip工具 方式二:pycharm中下载 3.注意事项 1.报错并有警告信息 2.报错,提示关键字 3.报错,无 ...
- openpyxl模块处理excel文件
python模块之——openpyxl 处理xlsx/ xlsm文件 项目原因需要编辑excel文件,经过查询,最先尝试xlwt .wlrd这个两个模块,但是很快发现这两个模块只能编辑xls文件,然而 ...
- 爬虫 Http请求,urllib2获取数据,第三方库requests获取数据,BeautifulSoup处理数据,使用Chrome浏览器开发者工具显示检查网页源代码,json模块的dumps,loads,dump,load方法介绍
爬虫 Http请求,urllib2获取数据,第三方库requests获取数据,BeautifulSoup处理数据,使用Chrome浏览器开发者工具显示检查网页源代码,json模块的dumps,load ...
- 日志、第三方模块(openpyxl模块)
目录 1.日志模块 2.第三方模块 内容 日志模块 1.日志模块的主要组成部分 1.logger对象:产生日志 无包装的产品 import logging logger = logging.getLo ...
- 第四十节,requests模拟浏览器请求模块初识
requests模拟浏览器请求模块初识 requests模拟浏览器请求模块属于第三方模块 源码下载地址http://docs.python-requests.org/zh_CN/latest/use ...
- python3模块: requests
Python标准库中提供了:urllib等模块以供Http请求,但是,它的 API 太渣了.它是为另一个时代.另一个互联网所创建的.它需要巨量的工作,甚至包括各种方法覆盖,来完成最简单的任务. 发送G ...
- python之openpyxl模块
一 . Python操作EXCEL库的简介 1.1 Python官方库操作excel Python官方库一般使用xlrd库来读取Excel文件,使用xlwt库来生成Excel文件,使用xlutils库 ...
- openpyxl模块
openpyxl模块 可以对Excel表格进行操作的模块 第三方模块需要下载 pip install openpyxl 配置永久第三方源: D:\Python36\Lib\site-packages\ ...
- python基础语法12 内置模块 json,pickle,collections,openpyxl模块
json模块 json模块: 是一个序列化模块. json: 是一个 “第三方” 的特殊数据格式. 可以将python数据类型 ----> json数据格式 ----> 字符串 ----& ...
- python day 8: re模块补充,导入模块,hashlib模块,字符串格式化,模块知识拾遗,requests模块初识
目录 python day 8 1. re模块补充 2. import模块导入 3. os模块 4. hashlib模块 5. 字符串格式:百分号法与format方法 6. 模块知识拾遗 7. req ...
随机推荐
- 配置jmeter环境变量
好记性不如烂笔头. 本文采用jmeter5.4.1版本. 1. Linux系统 1.1 将jmeter上传到安装目录并解压 jmeter5.4.1链接: https://pan.baidu.com/ ...
- 在 Tomcat 10.x 上部署 SpringMVC 5.x
在Tomcat10.x 上部署 SpringMVC 5.x的时候,项目一直无法访问 运行截图 原因 Tomcat10基于Jakarta EE 9,其中api的包名已经从javax更改到jakarat ...
- Go语言核心36讲11
至今为止,我们讲过的集合类的高级数据类型都属于针对单一元素的容器. 它们或用连续存储,或用互存指针的方式收纳元素,这里的每个元素都代表了一个从属某一类型的独立值. 我们今天要讲的字典(map)却不同, ...
- dafny : 微软推出的形式化验证语言
dafny是一种可验证的编程语言,由微软推出,现已经开源. dafny能够自我验证,可以在VS Code中进行开发,在编辑算法时,写好前置条件和后置条件,dafny验证器就能实时验证算法是否正确. 在 ...
- CSP-S 游寄
\(\text{reflection}\) 初赛. 本来以为上午要愉快地周测,但是伟大的虎哥让我们在四楼接着练习 然后就目睹了一个万能头+return 0编译 1min30sec 的奇迹 Win7 打 ...
- 【Java EE】Day03 DQL、约束、数据库设计、范式、备份和还原
〇.总结 1.DQL 聚合函数有空值需要使用ifnull函数 where不能使用聚合函数 分页开始索引的计算,及mysql和oracle的方言 2.约束 删除唯一约束DROP INDEX 列名; 3. ...
- 【JVM调优】Day04:总结前三日内容(GC+算法*4+简单回收器*3三色标记,CMS+G1+ZGC,参数个数+OOM+调优参数)
- base64解析爬取糗百
一.缘由 这是我之前刚开始学习的时候爬取糗百的练习内容,主要练习的是bs64解析.虽然现在用的不是特别的多,但是当初的时候用起来还是非常的顺手的. 二.代码实现 #coding:utf-8 impor ...
- DevSecOps 需要知道的十大 K8s 安全风险及建议
Kubernetes (K8s)是现代云原生世界中的容器管理平台.它实现了灵活.可扩展地开发.部署和管理微服务.K8s 能够与各种云提供商.容器运行时接口.身份验证提供商和可扩展集成点一起工作.然而 ...
- 万字长文解析Scaled YOLOv4模型(YOLO变体模型)
一,Scaled YOLOv4 摘要 1,介绍 2,相关工作 2.1,模型缩放 3,模型缩放原则 3.1,模型缩放的常规原则 3.2,为低端设备缩放的tiny模型 3.3,为高端设备缩放的Large模 ...