使用加强堆结构解决topK问题
作者:Grey
原文地址: 使用加强堆结构解决topK问题
题目描述
LintCode 550 · Top K Frequent Words II
思路
由于要统计每个字符串的次数,以及字典序,所以,我们需要把用户每次add的字符串封装成一个对象,这个对象中包括了这个字符串和这个字符串出现的次数。
假设我们封装的对象如下:
public class Word {
public String value; // 对应的字符串
public int times; // 对应的字符串出现的次数
public Word(String v, int t) {
value = v;
times = t;
}
}
topk的要求是: 出现次数多的排前面,如果次数一样,字典序小的排前面
很容易想到用有序表+比较器来做。
比较器的规则定义成和topk的要求一样,然后把元素元素加入使用比较器的有序表中,如果要返回topk,直接从这个有序表弹出返回给用户即可。比较器的定义如下:
public class TopKComparator implements Comparator<Word> {
@Override
public int compare(Word o1, Word o2) {
// 次数大的排前面,次数一样字典序在小的排前面
return o1.times == o2.times ? o1.value.compareTo(o2.value) : (o2.times - o1.times);
}
}
有序表配置这个比较器即可
TreeSet<Word> topK = new TreeSet<>(new TopKComparator());
所以topk()方法很简单,只需要从有序表里面把元素拿出来返回给用户即可
public List<String> topk() {
List<String> result = new ArrayList<>();
for (Word word : topK) {
result.add(word.value);
}
return result;
}
时间复杂度 O(K)
以上步骤不复杂,接下来是add的逻辑,add的每次操作都有可能对前面我们设置的topK有序表造成影响,
所以在每次add操作的时候需要有一个机制可以告诉topK这个有序表,需要淘汰什么元素,需要新加哪个元素,让topK这个有序表时时刻刻只存topk个元素,
这样就可以确保topK()方法比较单纯,时间复杂度保持在O(K)
所以接下来的问题是:如何告诉topK这个有序表,需要淘汰什么元素,需要新加哪个元素?
我们可以通过堆来维持一个门槛,堆顶元素表示最先要淘汰的元素,所以堆中的比较策略定为:
次数从小到大,字典序从大到小,这样,堆顶元素永远是:次数相对更少或者字典序相对更大的那个元素。所以如果某个时刻要淘汰一个元素,从堆顶拿出来,然后再到topK这个有序表中查询是否有这个元素,有的话就从topK这个有序表中删除这个元素即可。
private class ThresholdComparator implements Comparator<Word> {
@Override
public int compare(Word o1, Word o2) {
// 设置堆门槛,堆顶元素最先被淘汰
return o1.times == o2.times ? o2.value.compareTo(o2.value) : (o1.times - o2.times);
}
}
如果使用Java自带的PriorityQueue做这个堆,无法实现动态调整堆的功能,因为我们需要把次数增加的字符串(Word)在堆上动态调整,自带的PriorityQueue无法实现这个功能,PriorityQueue只能支持每次新增或者删除一个节点的时候,动态调整堆(
O(logN),但是如果堆中的节点变化了,PriorityQueue无法自动调整成堆结构,所以我们需要实现一个增强堆,用于节点变化的时候可以动态调整堆结构(保持O(logN)复杂度)。
加强堆的核心是增加了一个哈希表,
private Map<Word, Integer> indexMap;
用于存放每个节点所在堆上的位置,在节点变化的时候,可以通过哈希表查出这个节点所在的位置,然后从所在位置进行heapify/heapInsert操作,且这两个操作只会走一个,
这样就动态调整好了这个堆结构,以下resign方法就是完成这个工作
public void resign(Word word) {
int i = indexMap.get(word);
heapify(i);
heapInsert(i);
}
除了这个resign方法,自定义堆中的其他方法和常规的堆没有区别,在每次进行heapify和heapInsert操作的时候,如果涉及到交换两个元素,需要将indexMap中的两个元素的位置也互换
private void swap(int i, int j) {
if (i != j) {
indexMap.put(words[i], j);
indexMap.put(words[j], i);
Word tmp = words[i];
words[i] = words[j];
words[j] = tmp;
}
}
由于自定义堆和有序表topk只存top k个数据,所以TopK结构中还需要一个哈希表来记录所有的字符串出现与否:
private Map<String, Word> map;
自此,TopK结构中的add方法需要的前置条件已经具备,整个add方法的流程如下:
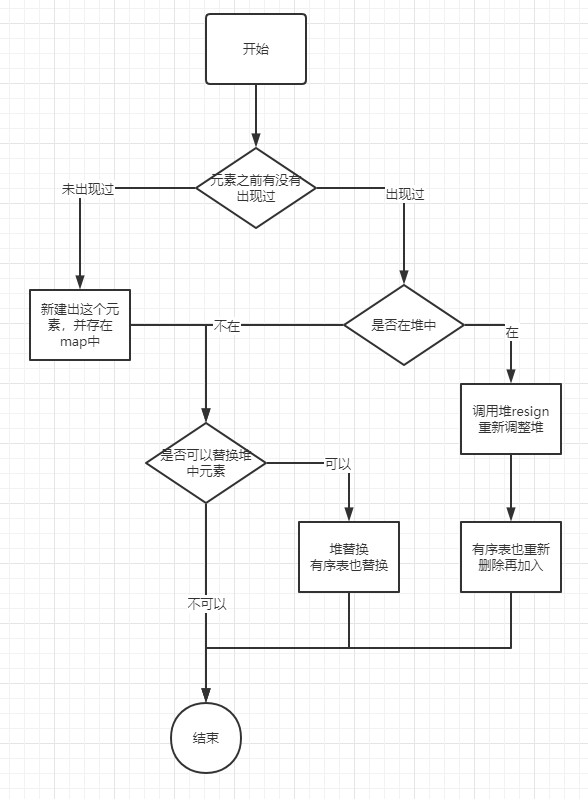
关于复杂度,add方法,时间复杂度O(log K), topk方法,时间复杂度O(K)。
完整代码
class TopK {
private TreeSet<Word> topK;
private Heap heap;
private Map<String, Word> map;
private int k;
public TopK(int k) {
this.k = k;
topK = new TreeSet<>(new TopKComparator());
heap = new Heap(k, new ThresholdComparator());
map = new HashMap<>();
}
public void add(String str) {
if (k == 0) {
return;
}
Word word = map.get(str);
if (word == null) {
// 新增元素
word = new Word(str, 1);
// 是否到达门槛可以替换堆中元素
if (heap.isReachThreshold(word)) {
if (heap.isFull()) {
Word toBeRemoved = heap.poll();
topK.remove(toBeRemoved);
}
heap.add(word);
topK.add(word);
}
} else {
if (heap.contains(word)) {
topK.remove(word);
word.times++;
topK.add(word);
heap.resign(word);
} else {
word.times++;
if (heap.isReachThreshold(word)) {
if (heap.isFull()) {
Word toBeRemoved = heap.poll();
topK.remove(toBeRemoved);
}
heap.add(word);
topK.add(word);
}
}
}
map.put(str, word);
}
public List<String> topk() {
if (k == 0) {
return new ArrayList<>();
}
List<String> result = new ArrayList<>();
for (Word word : topK) {
result.add(word.value);
}
return result;
}
private class Word {
public String value;
public int times;
public Word(String v, int t) {
value = v;
times = t;
}
}
private class TopKComparator implements Comparator<Word> {
@Override
public int compare(Word o1, Word o2) {
// 次数大的排前面,次数一样字典序在小的排前面
return o1.times == o2.times ? o1.value.compareTo(o2.value) : (o2.times - o1.times);
}
}
private class ThresholdComparator implements Comparator<Word> {
@Override
public int compare(Word o1, Word o2) {
// 设置堆门槛,堆顶元素最先被淘汰
return o1.times == o2.times ? o2.value.compareTo(o1.value) : (o1.times - o2.times);
}
}
private class Heap {
private Word[] words;
private Comparator<Word> comparator;
private Map<Word, Integer> indexMap;
public Heap(int k, Comparator<Word> comparator) {
words = new Word[k];
indexMap = new HashMap<>();
this.comparator = comparator;
}
public boolean isEmpty() {
return indexMap.isEmpty();
}
public boolean isFull() {
return indexMap.size() == words.length;
}
public boolean isReachThreshold(Word word) {
if (isEmpty() || indexMap.size() < words.length) {
return true;
} else {
if (comparator.compare(words[0], word) < 0) {
return true;
}
return false;
}
}
public void add(Word word) {
int size = indexMap.size();
words[size] = word;
indexMap.put(word, size);
heapInsert(size);
}
private void heapify(int i) {
int size = indexMap.size();
int leftChildIndex = 2 * i + 1;
while (leftChildIndex < size) {
Word weakest = leftChildIndex + 1 < size
? (comparator.compare(words[leftChildIndex], words[leftChildIndex + 1]) < 0
? words[leftChildIndex]
: words[leftChildIndex + 1])
: words[leftChildIndex];
if (comparator.compare(words[i], weakest) < 0) {
break;
}
int weakestIndex = weakest == words[leftChildIndex] ? leftChildIndex : leftChildIndex + 1;
swap(weakestIndex, i);
i = weakestIndex;
leftChildIndex = 2 * i + 1;
}
}
public void resign(Word word) {
int i = indexMap.get(word);
heapify(i);
heapInsert(i);
}
private void heapInsert(int i) {
while (comparator.compare(words[i], words[(i - 1) / 2]) < 0) {
swap(i, (i - 1) / 2);
i = (i - 1) / 2;
}
}
public boolean contains(Word word) {
return indexMap.containsKey(word);
}
public Word poll() {
Word result = words[0];
swap(0, indexMap.size() - 1);
indexMap.remove(result);
heapify(0);
return result;
}
private void swap(int i, int j) {
if (i != j) {
indexMap.put(words[i], j);
indexMap.put(words[j], i);
Word tmp = words[i];
words[i] = words[j];
words[j] = tmp;
}
}
}
}
更多
参考资料
使用加强堆结构解决topK问题的更多相关文章
- 基于PriorityQueue(优先队列)解决TOP-K问题
TOP-K问题是面试高频题目,即在海量数据中找出最大(或最小的前k个数据),隐含条件就是内存不够容纳所有数据,所以把数据一次性读入内存,排序,再取前k条结果是不现实的. 下面我们用简单的Java8代码 ...
- Java最小堆解决TopK问题
TopK问题是指从大量数据(源数据)中获取最大(或最小)的K个数据. TopK问题是个很常见的问题:例如学校要从全校学生中找到成绩最高的500名学生,再例如某搜索引擎要统计每天的100条搜索次数最多的 ...
- Java解决TopK问题(使用集合和直接实现)
在处理大量数据的时候,有时候往往需要找出Top前几的数据,这时候如果直接对数据进行排序,在处理海量数据的时候往往就是不可行的了,而且在排序最好的时间复杂度为nlogn,当n远大于需要获取到的数据的时候 ...
- 堆结构的优秀实现类----PriorityQueue优先队列
之前的文章中,我们有介绍过动态数组ArrayList,双向队列LinkedList,键值对集合HashMap,树集TreeMap.他们都各自有各自的优点,ArrayList动态扩容,数组实现查询非常快 ...
- 如何解决TOP-K问题
前言:最近在开发一个功能:动态展示的订单数量排名前10的城市,这是一个典型的Top-k问题,其中k=10,也就是说找到一个集合中的前10名.实际生活中Top-K的问题非常广泛,比如:微博热搜的前100 ...
- java实现堆结构
一.前言 之前用java实现堆结构,一直用的优先队列,但是在实际的面试中,可能会要求用数组实现,所以还是用java老老实实的实现一遍堆结构吧. 二.概念 堆,有两种形式,一种是大根堆,另一种是小根堆. ...
- Libheap:一款用于分析Glibc堆结构的GDB调试工具
Libheap是一个用于在Linux平台上分析glibc堆结构的GDB调试脚本,使用Python语言编写. 安装 Glibc安装 尽管Libheap不要求glibc使用GDB调试支持和 ...
- 分治思想--快速排序解决TopK问题
----前言 最近一直研究算法,上个星期刷leetcode遇到从两个数组中找TopK问题,因此写下此篇,在一个数组中如何利用快速排序解决TopK问题. 先理清一个逻辑解决TopK问题→快速排序→递 ...
- 【pwn】学pwn日记(堆结构学习)
[pwn]学pwn日记(堆结构学习) 1.什么是堆? 堆是下图中绿色的部分,而它上面的橙色部分则是堆管理器 我们都知道栈的从高内存向低内存扩展的,而堆是相反的,它是由低内存向高内存扩展的 堆管理器的作 ...
随机推荐
- 再议 MySQL 回表
一:回表概述 关于回表的概念网上已经有很多了,这里不过多赘述.下面我们直接放一张图可能更直观说明什么是回表. 图中 非聚集索引也叫二级索引,二级索引本质上也是 一 个 B+ 树结构,与聚集索引(也叫主 ...
- Linux检查服务器是否被入侵
Linux检查服务器是否被入侵 检查root用户是否被纂改 awk -F: '$3==0{print $1}' /etc/passwd awk -F: '$3==0 {print}' /etc/pas ...
- PowerSploit的使用
Invoke-Mimikatz(依赖管理员) Import-Module .\invoke-mimikatz.ps1 Invoke-Mimikatz –DumpCreds 使用Invoke-Mimik ...
- [WC2018]州区划分(FWT,FST)
[WC2018]州区划分(FWT,FST) Luogu loj 题解时间 经典FST. 在此之前似乎用到FST的题并不多? 首先预处理一个子集是不是欧拉回路很简单,判断是否连通且度数均为偶数即可. 考 ...
- espnet中的transformer和LSTM语言模型对比实验
摘要:本文以aishell为例,通过对比实验为大家介绍transformer和LSTM语言模型. 本文分享自华为云社区<espnet中的transformer和LSTM语言模型对比---以ais ...
- java中遗留的小问题
一.类型转换 short s = 1; s = s + 1; //false,因为1是int类型,会损失精度 short s = 1; s += 1; //true,因为+=有自带强转 二.逻辑运算符 ...
- 请简述下你在哪些场景下会选择 Kafka?
日志收集:一个公司可以用Kafka可以收集各种服务的log,通过kafka以统一接口服务的方式开放给各种consumer,例如hadoop.HBase.Solr等. 消息系统:解耦和生产者和消费者.缓 ...
- JavaScript ajax返回状态
该内容转自CSDN:http://blog.csdn.net/u013381651/article/details/51261956 xmlhttp.readyState的值及解释: 0:请求未初始化 ...
- 什么是 AQS ?
AQS 是 AbustactQueuedSynchronizer 的简称,它是一个 Java 提高的底层同步工具类,用一个 int 类型的变量表示同步状态,并提供了一系列的 CAS 操作来管理这个同步 ...
- zookeeper 的应用
不建议使用(单独)zookeeper 做分布式队列,有几点原因,以下原因摘抄于curator的官网: 1.zookeeper有1MB的传输限制.而在队列中,拥有很多的数据节点,通常包括数千个,如果有较 ...