道长的算法笔记:KMP算法及其各种变体
(一)如何优化暴力算法
Waiting...
(二)KMP模板
KMP 算法的精髓在于 \(next\) 数组,\(next[i]=j\) 代表 \(p[1,j]=p[i-j+1,i]\),\(next[i]\) 数值意义代表 \(p[1,i]\) 所有前缀与后缀的最长公共部分,我们约定本文提到的前缀与后缀均为不包含原字符串 \(p\) 本身。
这个过程动手计算并不困难,但想理解代码为何如此实现倒并不简单。个人建议,自行动手画图计算 \(next\) 数组,以此体会这个过程,否则永远不可能理解哪怕一行代码。由于 \(next\) 可能会有命名与内置命名冲突的风险,因而我们的代码实现中写为 \(nxt\) 而非 \(next\),下文我们都将使用 \(nxt\),同时为使代码实现起来更加简洁,我们所有字符串的索引均从 \(1\) 开始计算。

说完约定之后,接着来看模式串 \(p\) 的最长前缀与后缀公共长度的计算过程,前缀字符最大可取到的范围是在 \(s[1,n-2]\),后缀最大可取到的范围是在 \(s[2,n-1]\),例如 \(abcd\) 前缀包括\(\{a、ab、abc\}\),后缀包括了\(\{d、cd、bcd\}\),值得注意,后缀的字符出场顺序与原字符串 \(p\) 是一样的,都是从左往右。回忆一下 \(nxt[i] = j\),其含义是指 \(p[1,j]=p[i-j+1,i]\),注意,此处使用方括号与逗号分隔的表示法是指左闭右闭区间,使用方括号与冒号分隔的切片表示法才是左闭右开区间。我们计算 \(nxt\) 数组的过程其实就是字符串 \(p\) 对其自身的匹配过程,我们错开一位再进行比较即可比对所有前缀与所有后缀之间,最大公共长度部分了。
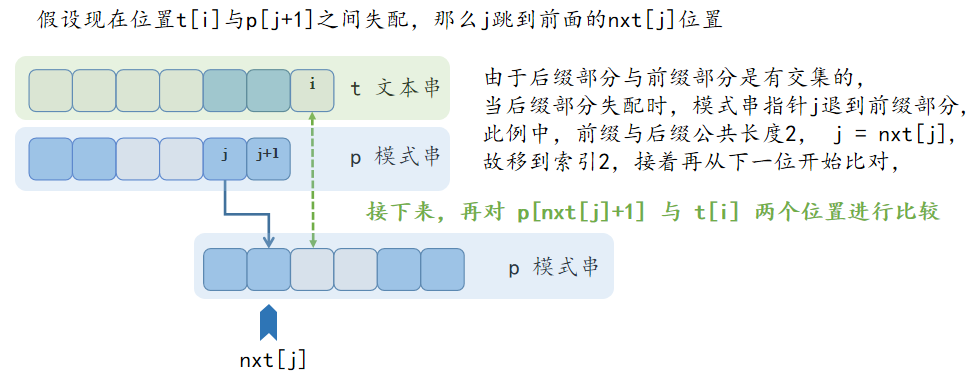
再看上图的匹配过程,如果失配,指向模式串的指针 \(p\) 往左退,除非已经到达了退无可退的状态,方才跳出。在完成了向左移动退步的操作之后,再对当前文本串 \(t[i]\) 位置与模式串进行对比,指针 \(i\) 从始至终都只向右移动。下列模板来自 ACwing831 ,若条件允许,强烈建议购买 ACwing 算法课程,其它模板题亦有 LeetCode28、洛谷3375等等。
#include<bits/stdc++.h>
using namespace std;
#define MAXN 1000010
char txt[MAXN], pat[MAXN];
int nxt[MAXN];
int main(){
int n, m;
scanf("%d %s", &n, pat + 1);
scanf("%d %s", &m, txt + 1);
// 显然i = 1不符合条件,此时即既没有非平凡前缀又没有非平凡后缀
for(int i = 2, j = 0; i <= n; i++){
while(j && pat[i] != pat[j + 1])
j = nxt[j];
if(pat[i] == pat[j + 1]) j++;
nxt[i] = j;
}
for(int i = 1, j = 0; i <= m; i++){
while(j && txt[i] != pat[j + 1])
j = nxt[j];
if(txt[i] == pat[j + 1]) j++;
if(j == n){
printf("%d ", i - n);
j = nxt[j];
}
}
printf("\n");
return 0;
}
KMP 算法的本质是利用字符串本身蕴含的冗余信息,通俗来说就是利用自身的相同部分来减少比对的次数,很直观的,当出现失配的时候,对于已经比过的、相同的部分,我们显然不需要重新再比对一次。
当一个字符串是由某个循环节,循环若干次构成的时候,此时字符串蕴含的冗余信息几乎是最理想的状态,KMP 认为所有的字符串均是通过某个循环节,进行若干次循环之后,再截取子串获得的,例如字符串 \(cabcabca\) 其实就是通过 \(abc\) 循环四次之后所得的 文本串\(txt\) 截取 \(txt[3,10]\) 部分得到的。下文“KMP理解加深”章节中,我们会继续讨论这一点。
(三)KMP理解加深
(3.1)重复的子字符串问题
给定一个非空的字符串 \(s\) ,检查 \(s\) 是否可以通过由其一个子串重复多次构成,假如 \(s\) 包含若干子串 \(x\),不妨记 \(s=kx\),其中 \(k>=2\),那么 \(s+s=2kx\),掐头去尾丢弃两个字符,也就是相当于破坏了头尾部分两个 \(x\) 子串,此番操作之后,剩余 \(2(k-1)x\),由于 \(k>=2\),代入可知 \(s\) 至少会在 \(2(k-1)x\) 出现一次,因而只要对于切片 \(2s[1:-1]\) 检查是否包含 \(s\) 即可知道 \(s\) 是否可以通过由其一个子串重复多次构成。
class Solution {
public:
bool repeatedSubstringPattern(string s) {
string cp = "#" + s;
string txt = "#" + s.substr(1) + s; txt.pop_back();
vector<int> nxt(cp.size() + 1, 0);
for(int i = 2, j = 0; i < cp.size(); i++){
while(j && cp[i] != cp[j + 1])
j = nxt[j];
if(cp[i] == cp[j + 1]) j++;
nxt[i] = j;
}
for(int i = 1, j = 0; i < txt.size(); i++){
while(j && txt[i] != cp[j + 1])
j = nxt[j];
if(txt[i] == cp[j + 1]) j++;
if(j == cp.size() - 1){
return true;
}
}
return false;
}
};
这道题是比较简单的面试题,检查字符串是否可由多个重复的子串构成,本题放在此处主要是为了下一题分析字符串子串循环节长度、循环次数做铺垫。
为了便于形式化表达,我们不妨使用记号 \(nxt^2[j]\) 代表 \(nxt[nxt[j]]\),以此类推,我们可以写出 \(nxt^k[j]\), 其中 \(k\)是整数,且不大于 \(n-1\),这种形式化的表达会在下文帮助我们理解 KMP 算法的本质。
(3.2)串周期
给定一个字符串,其前缀是从第一个字符开始的连续若干个字符,在本例中,我们规定前缀包括字符串本身,例如 \(abaab\) 共有前缀 \(\{a,ab,aba,abaa,abaab\}\),我们希望对每个前缀\(s[1,i],(i>1)\)判断是否具有循环节,如果存在循环节,其长度是多少,循环次数是多少。
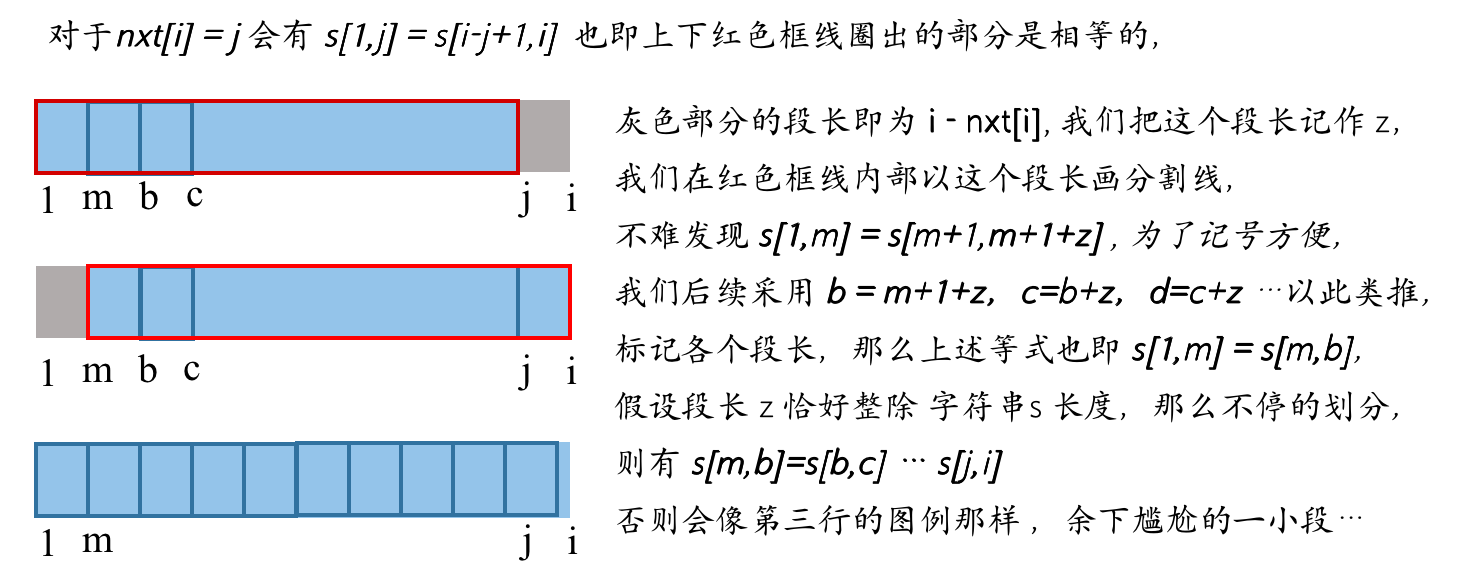
对于某一个字符串\(s[1,i]\),在其众多的 \(nxt[1...i]\) 候选项中,如果存在于一个\(nxt[x],x\in[1...i]\)使得 \(i\%i - nxt[x] = 0\), 那么\(s[1,i-nxt[x]]\), 也即第二行图例中的灰色部分,即为 \(s[1,i]\) 循环元,其循环次数 \(K=i/(i-nxt[x])\)。
其实,只要 \(s[1,i]\) 是由若干循环节构成的,那么我们要找的 \(nxt[x]\) 其实就是 \(nxt[i]\),因为 \(nxt[i]\) 代表着 “失配时指针向左移动最少的位置”,如果存在其它 \(nxt[x],x \neq i\) 同样满足 \(i\%i - nxt[x] = 0\),则其需要移动的位置一定多于 \(nxt[i]\),也就是说,此时的 \(i-nxt[x]\) 并非最小单元长度。
举个例子,比如字符串 \(abababab\),最小的循环节应为 \(ab\),长度\(2\),满足\(8\%2=0\),但是 \(abab\) 长度\(4\),也能构成一个循环节,同样满足 \(8\%4=0\),但它并非最小循环节。
#include <bits/stdc++.h>
#include <algorithm>
using namespace std;
char str[1000010];
int nxt[1000010];
int n;
int kase;
int main(){
while(scanf("%d", &n) != EOF){
if(n == 0) break;
scanf("%s", str + 1);
for(int i = 2, j =0; i <= n; i++){
while(j && str[i] != str[j + 1])
j = nxt[j];
if(str[i] == str[j + 1]){
j++;
}
nxt[i] = j;
}
printf("Test case #%d\n", ++kase);
for(int i = 2; i <= n; i++){
if(i % (i - nxt[i]) == 0 && nxt[i]){
printf("%d %d\n", i, i/(i - nxt[i]));
}
}
printf("\n");
}
return 0;
}
本题能够延伸得到一些其它结论,详见下列条目,其中 \(x\) 代表的含义与上文相同:
- 如果\(i-nxt[i]\) 能够整除 \(i\),那么\(s[1,i]\)具有最小循环节,长度 \(i-nxt[i]\)
- 如果\(i-nxt[x]\),(\(x>0\) 且 \(x \neq i)\) 能够整除 \(i\),那么\(s[1,i]\) 具有循环元,长度 \(i-nxt[x]\)
- 其余候选项 \(nxt[x]\) 均满足 \(x > 0, x = nxt^k[i]\),其中 \(k=1,2,3,4...n-1\)
- 任意一个循环元的长度必然是最小循环元的整数倍
- 如果 \(i-nxt[i]\) 无法整除 \(i\),那么任意 \(i-nxt[x]\) 均不可能作为 \(s[1,i]\) 循环元
- 无论 \(m=i-nxt[i]\) 可否整除 \(i\),\(i-nxt[x]\) 都等于若干倍 \(m\),也即 \(i-nxt[x]=bm\)
对于最后一条可能的会使得感到抽象,我们举个例子。使用的 \(abc\) 作为循环节反复拼接四次构成新字符串 \(abcabcabcabc\),然后截取其中一个片段 \(cabcabca\) 作为我们接下来分析的文本串\(txt\),我们先算这个片段 \(nxt\) 数组。

显然文本串 \(txt\) 没有循环节,但是 \(8-nxt[8]=3\),所得的数值 \(3\) 竟然就是我们最初用于构造的 \(txt\) 循环节的长度,\(8-nxt^2[8]=6\),所得数值恰好是循环节的两倍,符合我们上面所说的规律,这是巧合吗?我们接着往下迭代,由于 \(nxt^3[8]=0\) 已经不在候选项中了,我们不再往下分析。其实,上述的过程其实并非巧合,相反其恰恰道出了 KMP 算法的本质,也即所有字符串均可通过循环节进行若干次循环之后截取子串得到。通常 \(i-nxt[i]\) 即可推算得出用于构造 \(s[1,i]\) 文本串的循环节长度。理解了这点,也就不难做出 AC4188连接字符串 、UVA10298这几道题了。
(3.3)匹配统计
Waiting...
(3.4)处理字符矩阵
Waiting...
(四)KMP算法变体
(4.1)构造Z函数求解LCP
Waiting...
(4.2)自动机模型
Waiting...
支持作者

道长的算法笔记:KMP算法及其各种变体的更多相关文章
- 算法笔记--KMP算法 && EXKMP算法
1.KMP算法 这个博客写的不错:http://www.cnblogs.com/SYCstudio/p/7194315.html 模板: next数组的求解,那个循环本质就是如果相同前后缀不能加上该位 ...
- 算法:KMP算法
算法:KMP排序 算法分析 KMP算法是一种快速的模式匹配算法.KMP是三位大师:D.E.Knuth.J.H.Morris和V.R.Pratt同时发现的,所以取首字母组成KMP. 少部分图片来自孤~影 ...
- 算法 | 串匹配算法之KMP算法及其优化
主串 s:A B D A B C A B C 子串 t: A B C A B 问题:在主串 s 中是否存在一段 t 的子串呢? 形如上述问题,就是串匹配类问题.[串匹配--百度百科] 串匹配问题是一 ...
- BF算法与KMP算法
BF(Brute Force)算法是普通的模式匹配算法,BF算法的思想就是将目标串S的第一个字符与模式串T的第一个字符进行匹配,若相等,则继续比较S的第二个字符和 T的第二个字符:若不相等,则比较S的 ...
- 数据结构之BF算法,kmp算法,三元组,十字链表总结
在这一章中,老师教了我们四种数据结构:BF算法,kmp算法,三元组和十字链表:还给我们讲了2019年团体天体赛中T1-8的AI题 1.对于BF和kmp算法,老师除了在课堂上讲解算法的主要核心思想外,还 ...
- [一本通学习笔记] KMP算法
KMP算法 对于串s[1..n],我们定义fail[i]表示以串s[1..i]的最长公共真前后缀. 我们首先考虑对于模式串p,如何计算出它的fail数组.定义fail[0]=-1. 根据“真前后缀”的 ...
- 学习笔记-KMP算法
按照学习计划和TimeMachine学长的推荐,学习了一下KMP算法. 昨晚晚自习下课前粗略的看了看,发现根本理解不了高端的next数组啊有木有,不过好在在今天系统的学习了之后感觉是有很大提升的了,起 ...
- 串、串的模式匹配算法(子串查找)BF算法、KMP算法
串的定长顺序存储#define MAXSTRLEN 255,//超出这个长度则超出部分被舍去,称为截断 串的模式匹配: 串的定义:0个或多个字符组成的有限序列S = 'a1a2a3…….an ' n ...
- 【算法】KMP算法
简介 KMP算法由 Knuth-Morris-Pratt 三位科学家提出,可用于在一个 文本串 中寻找某 模式串 存在的位置. 本算法可以有效降低在一个 文本串 中寻找某 模式串 过程的时间复杂度.( ...
- KMP算法及KMP算法的应用(POJ2406)
///KMP算法#include<bits/stdc++.h> using namespace std; ]; void makeNext(const char P[],int next[ ...
随机推荐
- Python编程之多进程(multiprocessing)详解
引言 multiprocessing是一个用于产生多进程的包,与threading模块的API类似.multiprocessing既可以实现本地的多进程,也可以实现远程的多进程.通过使用多个子进程而非 ...
- vite vue3 规范化与Git Hooks
在 <JS 模块化>系列开篇中,曾提到前端技术的发展不断融入很多后端思想,形成前端的"四个现代化":工程化.模块化.规范化.流程化.在该系列文章中已详细介绍了模块化的发 ...
- java.lang.Object类与equals()及toString()的使用
1.Object类是所有Java类的根父类 2.如果在类的声明中未使用extends关键字指明其父类,则默认父类为java.lang.Object类 3.Object类中的功能(属性.方法)就具有通用 ...
- react.js+easyui 做一个简单的商品表
效果图: import React from 'react'; import { Form, FormField, Layout,DataList,LayoutPanel,Panel, Lab ...
- Springboot JSON 转换:Jackson篇
本案例基于 Springboot 2.5.7 单元测试场景下进行 <!-- SpringMVC默认使用Jacson,只需要引用web启动器即可,无序单独引用Jackson --> < ...
- nginx.conf指令注释
nginx.conf指令注释 ######Nginx配置文件nginx.conf中文详解##### #定义Nginx运行的用户和用户组 user www www; #nginx进程数,建议设置为等于C ...
- 【Azure 环境】Azure 云环境对于OpenSSL 3.x 的严重漏洞(CVE-2022-3602 和 CVE-2022-3786)的处理公告
问题描述 引用报告:(OpenSSL3.x曝出严重漏洞 : https://www.ctocio.com/ccnews/37529.html ) 最近OpenSSL 3.x 爆出了严重安全漏洞,分别是 ...
- 源码级深度理解 Java SPI
作者:vivo 互联网服务器团队- Zhang Peng SPI 是一种用于动态加载服务的机制.它的核心思想就是解耦,属于典型的微内核架构模式.SPI 在 Java 世界应用非常广泛,如:Dubbo. ...
- 2022-11-06 Acwing每日一题
本系列所有题目均为Acwing课的内容,发表博客既是为了学习总结,加深自己的印象,同时也是为了以后回过头来看时,不会感叹虚度光阴罢了,因此如果出现错误,欢迎大家能够指出错误,我会认真改正的.同时也希望 ...
- 基于k8s的CI/CD的实现
综述 首先,本篇文章所介绍的内容,已经有完整的实现,可以参考这里. 在微服务.DevOps和云平台流行的当下,使用一个高效的持续集成工具也是一个非常重要的事情.虽然市面上目前已经存在了比较成熟的自动化 ...