3、数组、集合、Lambda、Stream与Optional类
一、数组:
数组保存在JVM堆内存中
1、数组的创建:
(1)、一维数组创建方式一:
//一维数组方式一
Integer[] array01 = {1,2,3};
System.out.println("一维数组创建方式一");
System.out.println("数组长度:"+array01.length);
for (int i: array01) {
System.out.println("Array01["+(i-1)+"]="+array01[i-1]);
}
(2)、一维数组创建方式二:
//一维数组方式二
Integer[] array02 = new Integer[2];
array02[0] = 1;
array02[1] = 2;
System.out.println("一维数组创建方式二");
System.out.println("数组长度:"+array02.length);
for (int i: array02) {
System.out.println("Array02["+(i-1)+"]="+array02[i-1]);
}
(3)、一维数组创建方式三:
//一维数组方式三
Integer[] array03 = new Integer[]{1,2,3};
System.out.println("一维数组创建方式三");
System.out.println("数组长度:"+array03.length);
for (int i: array03) {
System.out.println("Array03["+(i-1)+"]="+array03[i-1]);
}
(4)、二维数组同理:
//二维数组同理
Integer[][] array04 = {{1,2},{3,4}};
System.out.println("二维数组创建方式同理");
System.out.println("二维数组长度:"+array04.length);
for (int i = 0; i < array04.length; i++) {
for (int j = 0; j < array04[i].length; j++) {
System.out.println("Array04["+(i)+"]"+"["+(j)+"]="+array04[i][j]);
}
} Integer[][] array05 = new Integer[][]{{1,2},{3,4}};
for (int i = 0; i < array05.length; i++) {
for (int j = 0; j < array05[i].length; j++) {
System.out.println("Array05["+(i)+"]"+"["+(j)+"]="+array05[i][j]);
}
} Integer[][] array06 = new Integer[2][2];
array06[0][0] = 1;
array06[0][1] = 2;
array06[1][0] = 3;
array06[1][1] = 4;
for (int i = 0; i < array06.length; i++) {
for (int j = 0; j < array06[i].length; j++) {
System.out.println("Array06["+(i)+"]"+"["+(j)+"]="+array06[i][j]);
}
}
2、java.util.Arrays工具类详解:
(1)、Arrays.equals():判断两个数组是否相等
/**
* 1、boolean equals(int[] a,int[] b):判断两个数组是否相等。
* @Return false
* */
int[] arr1 = new int[]{1,2,3,4};
int[] arr2 = new int[]{1,3,2,4};
boolean isEquals = Arrays.equals(arr1, arr2);
System.out.println(isEquals);
(2)、Arrays.toString():输出数组信息
/**
* 2.String toString(int[] a):输出数组信息。
* @Return [1, 2, 3, 4]
* */
int[] arr1 = new int[]{1,2,3,4};
System.out.println(Arrays.toString(arr1));
(3)、Arrays.fill():将指定值填充到数组中
/**
* 3、
* void fill(int[] a,int val):将指定值填充到数组中的每一个元素。
* void fill(int[] a,fromIndex,toIndex,int val):将指定值填充的数组中从fromIndex(包含)到toIndex(不包含)范围内的每一个元素。
* */
int[] arr1 = new int[]{1,2,3,4};
Arrays.fill(arr1,10);
//toPrint->[10, 10, 10, 10]
System.out.println(Arrays.toString(arr1));
Arrays.fill(arr1,1,3,0);
//toPrint->[10, 0, 0, 10]
System.out.println(Arrays.toString(arr1));
(4)、Arrays.sort():对数组进行升序排序
/**
* 4、
* void sort(int[] a):对数组进行升序排序。
* void sort(int[] a,fromIndex,toIndex):对数组从fromIndex(包含)到toIndex(不包含)范围内进行部分排序。
* 注:
* sort() 方法使用快速排序适用于少量数据的排序,parallelSort() 方法使用并行排序适用于大量数据的升序排序
* */
int[] arr1 = new int[]{1,3,2,4};
Arrays.sort(arr1);
//toPrint->[1, 2, 3, 4]
System.out.println(Arrays.toString(arr1));
int[] arr2 = new int[]{1,3,2,7,4};
Arrays.sort(arr2,1,3);
//toPrint->[1, 2, 3, 7, 4]
System.out.println(Arrays.toString(arr2));
(5)、Arrays.binarySearch():二分查找搜索数组中指定值的位置
/**
* 5.int binarySearch(int[] a,int key):使用二分查找搜索指定的值,找到了则返回该值在数组中的下标,没找到则返回一个负数
* @Return 8
* */
int[] arr3 = new int[]{-98,-34,2,34,54,66,79,105,210,333};
int index = Arrays.binarySearch(arr3, 210);
if(index >= 0){
System.out.println(index);
}else{
System.out.println("未找到");
}
(6)、Arrays.asList():将数组转化成List集合的方法
注: 参考自
1)、该方法适用于对象型数据的数组(String、Integer...),不建议使用于基本数据类型的数组(byte,short,int,long,float,double,boolean);
2)、该方法将数组与List列表链接起来:当更新其一个时,另一个自动更新;
3)、该方法得到的List的长度是不可改变的,添加或删除一个元素时(add()、remove()、clear()等方法)程序就会抛出异常;
总结:
如果你的List只是用来遍历,就用Arrays.asList()。如果你的List还要添加或删除元素,还是乖乖地new一个java.util.ArrayList,然后一个一个的添加元素。
/**
* 6.List<T> asList(T... a):将数组转化成List集合的方法,此方法得到的List的长度是不可改变的,添加或删除一个元素时程序就会抛出异常
* */
String[] arr4 = {"a","b","c","d","e","f","g"};
List<String> list = Arrays.asList(arr4);
//list.add("k"); //抛出异常:java.lang.UnsupportedOperationException
for (String i: list ) {
System.out.println(i);
}
3、八大排序算法之一:冒泡排序法
/**
* 冒泡排序:
* 八大排序算法之一
* 1、比较数组中两个相邻的元素,如果第一个数比第二个数大,就交换位置(从小到排)
* 2、每次比较,都会产生一个最大,或最小的数
* 3、下一轮则可以少一次排序
* 4、依次循环,直至结束
* */
public static void BubbleSort(int[] array){
for (int i = 0; i < array.length-1; i++){
//每个数字需要循环比较n-1次,随着数据被排序,未匹配数字越来越少,与外层循环形成反比 公式为:length-i-1,没匹配到一个数,减少一次循环
for (int j = 0; j < array.length-i-1; j++){
//每次将数据进行比较,将最大值或最小值放入到比较数中
//如果第一个数大于第二个数,将交换位置,比较数永远是最大数
if (array [j] > array [j+1]){
//将前一个元素,放入到临时位置
int temp = array [j];
//将后一个元素,赋值给前一个元素,进行替换
array [j] = array[j+1];
//在将前一个元素的值,替换到后一个元素中,形成交换
array [j+1] = temp;
}
}
}
System.out.println("排序后数组为:"+ Arrays.toString(array));
}
二、集合:
1、集合详解:
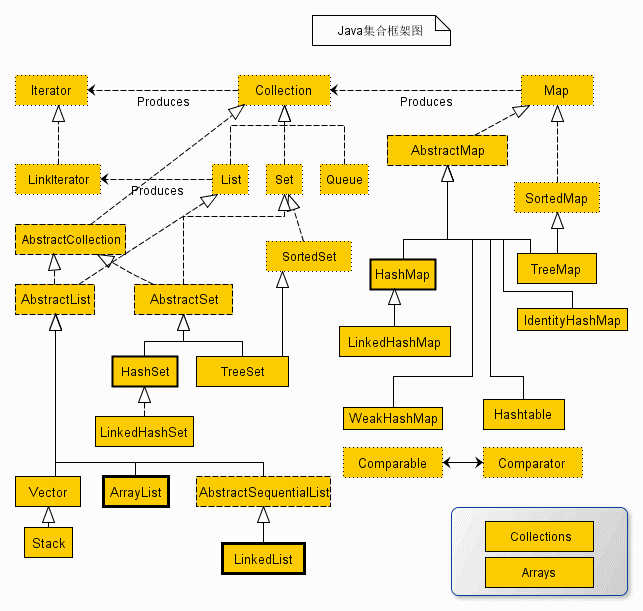
(1)、Collection父接口:
|----Collection接口:单列集合,以单个方式存储元素对象
增:add(Object obj)
删:remove(int index) / remove(Object obj)
改:set(int index, Object ele)
查:get(int index)
* |----List接口:存储有序可重复的数据。
* |----ArrayList类:底层数组,初始化容量10,默认扩容到原容量的1.5倍,线程不安全的,检索效率高、增删效率低;
* |----LinkedList类:底层是双向链表,检索效率低、增删效率高;
* |---- Vector类:底层数组,作为List接口的古老实现类;线程安全的,效率低;底层都创建了长度为10的数组。在扩容方面,默认扩容为原来的数组长度的2倍。
*
* |----Set接口:存储无序不可重复的数据(主要参考map)
* |----HashSet类:线程不安全的;可以存储null值
* |----LinkedHashSet类:作为HashSet的子类;遍历其内部数据时,可以按照添加的顺序遍历,但是并不是说LinkedHashSet是有序的在添加数据的同时,每个数据还维护了两个引用,记录此数据前一个数据和后一个数据。对于频繁的遍历操作,LinkedHashSet效率高于HashSet。
* |----TreeSet类:可以照添加对象的指定属性,进行排序。
(2)、Map父接口:
|----Map接口:双列数据,以键值对key-value方式存储元素对象(无序不可重复)
添加:put(Object key,Object value)
删除:remove(Object key)
修改:put(Object key,Object value)
查询:get(Object key)
* |----HashMap类:底层jdk7及之前是数组与单向链表的结合体,jdk8是数组、单向链表与红黑树的结合体,插入与删除的原理是底层调用hashcode()得到哈希值,在经过哈希算法将其转换成数组下标;HashMap初始化容量16,默认加载因子是0.75,当达到75%开始扩容,扩容为原容量的2倍数。HashMap线程不安全的,效率高;允许存储null的key和value;
* |----LinkedHashMap类:保证在遍历map元素时,可以照添加的顺序实现遍历。原因:在原的HashMap底层结构基础上,添加了一对指针,指向前一个和后一个元素。对于频繁的遍历操作,此类执行效率高于HashMap。
* |----TreeMap类:底层使用红黑树,保证照添加的key-value对进行排序,实现排序遍历。此时考虑key的自然排序或定制排序
* |----Hashtable:线程安全的,效率低;不能存储null的key和value
2、java.util.Collections工具类详解:
Collections类是Java中针对集合类的一个工具类,其中提供一系列静态方法。
常用静态方法:
(1)、sort():对List集合中的元素默认进行升序排序
/**
* 1、sort():对List集合中的元素默认进行升序排序
* 注:
* 集合指定的泛型T必须实现Comparable<? super T>接口
* */
public static void sortDemo(){
List<Integer> list = new ArrayList<>();
list.add(1);
list.add(5);
list.add(2);
list.add(4);
list.add(3);
//默认升序排序
Collections.sort(list);
System.out.println(list); //toPrint->[1, 2, 3, 4, 5]
//降序排序,Collections.reverseOrder():反向比较器
Collections.sort(list,Collections.reverseOrder());
System.out.println(list); //toPrint->[5, 4, 3, 2, 1]
}
(2)、reverse():反转List集合中的元素
/**
* 2、reverse():反转List集合中的元素
* */
public static void reverseDemo(){
List<Integer> list = new ArrayList<>();
list.add(1);
list.add(5);
list.add(2);
list.add(4);
list.add(3);
//默认升序排序
Collections.sort(list);
System.out.println(list); //toPrint->[1, 2, 3, 4, 5]
//反转List集合元素
Collections.reverse(list);
System.out.println(list); //toPrint->[5, 4, 3, 2, 1]
}
(3)、shuffle():随机打乱List集合中元素的位置
/**
* 3、shuffle():随机打乱List集合中元素的位置
* */
public static void shuffleDemo(){
List<Integer> list = new ArrayList<>();
list.add(1);
list.add(5);
list.add(2);
list.add(4);
list.add(3);
//默认升序排序
Collections.sort(list);
System.out.println(list); //toPrint->[1, 2, 3, 4, 5]
//随机打乱位置
Collections.shuffle(list);
System.out.println(list); //toPrint->[2, 4, 3, 1, 5](随机)
}
(4)、copy():复制并覆盖相应List集合中索引的元素
/**
* 4、copy():复制并覆盖相应List集合中索引的元素
* 注:
* (1)、第一个参数是目的集合,第二个参数是源集合
* (2)、目的集合必须声明集合大小,即目的集合要等于或者大于源集合的元素的个数。否则报下标界的异常(java.lang.IndexOutOfBoundsException)。
* */
public static void copyDemo(){
List<Integer> list = new ArrayList<>();
list.add(1);
list.add(5);
list.add(2);
list.add(4);
list.add(3);
System.out.println(list); //toPrint->[1, 2, 3, 4, 5]
//copy():复制并覆盖相应List集合中索引的元素,必须指定目的集合大小
//方式一、初始化指定List的大小
List<Integer> list1 = new ArrayList<>(Arrays.asList(new Integer[list.size()]));
Collections.copy(list1 , list);
System.out.println(list1); //toPrint->[1, 2, 3, 4, 5]
//方式二、Collections.addAll()方法将所有指定的元素添加到指定的集合中,从而指定List的大小
List<Integer> list2 = new ArrayList<>();
Collections.addAll(list2,new Integer[list.size()]);
Collections.copy(list2 , list);
System.out.println(list2); //toPrint->[1, 2, 3, 4, 5]
}
(5)、max()/min():返回集合中最大/小的元素
/**
* 5、max()/min():返回集合中最大/小的元素
* */
public static void sizeDemo(){
List<Integer> list = new ArrayList<>();
list.add(1);
list.add(5);
list.add(2);
list.add(4);
list.add(3);
System.out.println(list); //toPrint->[1, 2, 3, 4, 5]
System.out.println("集合中最大元素:"+Collections.max(list)); //toPrint->集合中最大元素:5
System.out.println("集合中最小元素:"+Collections.min(list)); //toPrint->集合中最小元素:1
}
三、Java函数式操作:
1、Lambda、方法引用、stream与Optional详解:
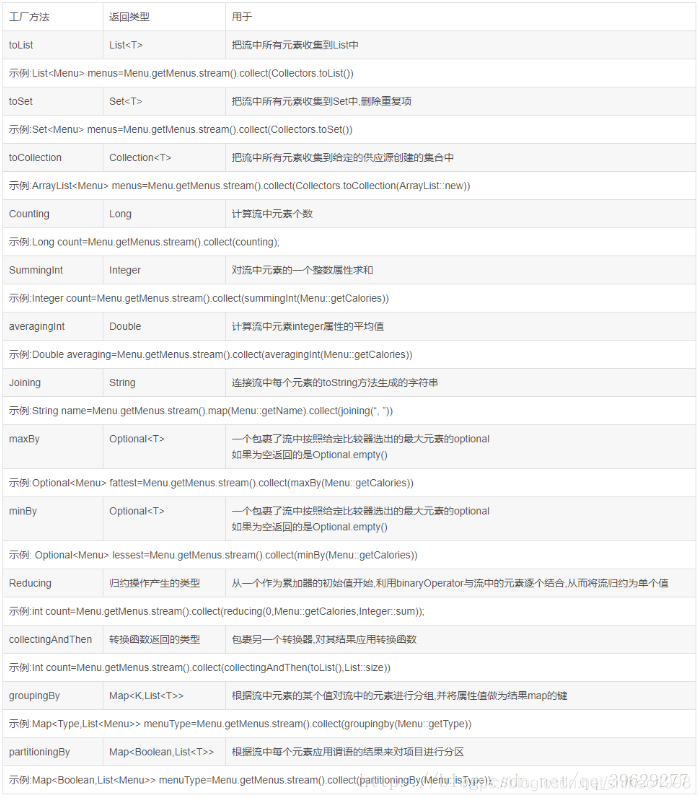
2、java.util.stream.Collectors相关详解:
3、匿名内部类与Lambda表达式的区别:
/**
* 比较匿名内部类与lambda表达式的区别:
* */
public static void compareToBoth(){
//匿名内部类形式创建线程
new Thread(new Runnable() {
@Override
public void run() {
System.out.println(Thread.currentThread().getName());
}
}).start(); //lambda表达式创建线程
new Thread(
() -> System.out.println(Thread.currentThread().getName())
).start();
}
4、接口与函数式接口:
(1)、接口详解:
1)、JDK8前--->接口中只有常量与抽象方法
2)、JDK8--->接口中除了常量与抽象方法外,还有默认方法(default)和静态方法(static)
3)、JDK9--->接口中除了常量、抽象方法、默认方法(default)和静态方法(static)外,还有私有方法(private)
(2)、函数式接口详解:
1)、定义:有且仅有一个抽象方法,但是可以有多个非抽象方法的接口
2)、函数式接口可以被隐式转换为 lambda 表达式
3)、函数式接口一般会加上@FunctionalInterface:主要用于编译级错误检查,当接口不符合函数式接口定义的时候,编译器会报错
/**
* 函数式接口(Functional Interface)就是一个有且仅有一个抽象方法,但是可以有多个非抽象方法的接口
* @FunctionalInterface:主要用于编译级错误检查,加上该注解,当接口不符合函数式接口定义的时候,编译器会报错
*/
@FunctionalInterface
interface LamTest {
void demo01(String t); static void demo02() {
System.out.println("接口说明:\n" +
" 1、JDK8前--->接口中只有常量与抽象方法\n" +
" 2、JDK8--->接口中除了常量与抽象方法外,还有默认方法(default)和静态方法(static)\n" +
" 3、JDK9--->接口中除了常量、抽象方法、默认方法(default)和静态方法(static)外,还有私有方法(private)\n");
}
} class LamTestImp implements LamTest {
@Override
public void demo01(String t){
System.out.println(t);
} }
5、Consumer、Supplier、Predicate与Function函数式接口的区别:
Consumer(消费型),Supplier(供给型)、Predicate(判断型)与Function(转换型)几个函数式接口都处于java.util.function包下
(1)、Consumer(消费型):
1)、源码:
@FunctionalInterface
public interface Consumer<T> { void accept(T t); default Consumer<T> andThen(Consumer<? super T> after) {
Objects.requireNonNull(after);
return (T t) -> { accept(t); after.accept(t); };
} }
2)、使用:
Consumer对应抽象方法:accpet
Consumer<Integer> consumer=new Consumer<Integer>() {
@Override
public void accept(Integer integer) {
System.out.println(integer);
}
};
consumer.accept(1);
}
3)、Consumer总结:
Consumer接口是一个消费型的接口,只要实现它的accept方法,就能作为消费者来输出信息。
lambda、方法引用都可以是一个Consumer类型,因此他们可以作为forEach的参数,用来协助Stream输出信息。
Consumer还有很多变种,例如IntConsumer、DoubleConsumer与LongConsumer等,归根结底,这些变种其实只是指定了Consumer中的泛型而已,方法上并无变化。
(2)、Supplier(供给型):
1)、源码:
@FunctionalInterface
public interface Supplier<T> { T get();
}
2)、使用:
Supplier对应抽象方法:get
Supplier<Double> supplier=()->new Random().nextDouble();
//当然也可以使用方法引用
Supplier<Double> supplier1= Math::random;
System.out.println(supplier.get());
3)、Supplier总结:
Supplier是一个供给型的接口,其中的get方法用于返回一个值。
Supplier也有很多的变种,例如IntSupplier、LongSupplier与BooleanSupplier等
(3)、Predicate(判断型):
1)、源码:
@FunctionalInterface
public interface Predicate<T> { boolean test(T t); default Predicate<T> and(Predicate<? super T> other) {
Objects.requireNonNull(other);
return (t) -> test(t) && other.test(t);
} default Predicate<T> negate() {
return (t) -> !test(t);
} default Predicate<T> or(Predicate<? super T> other) {
Objects.requireNonNull(other);
return (t) -> test(t) || other.test(t);
} static <T> Predicate<T> isEqual(Object targetRef) {
return (null == targetRef)
? Objects::isNull
: object -> targetRef.equals(object);
}
}
2)、使用:
Predicate对应抽象方法:test
Predicate<Integer> predicate=i->i>5;
System.out.println(predicate.test(1));
3)、Predicate总结:
Predicate是一个判断型的接口,用一个test方法去测试传入的参数。
当然,Predicate也有对应的变种。
(4)、Function(转换型):
1)、源码:
@FunctionalInterface
public interface Function<T, R> { R apply(T t); default <V> Function<V, R> compose(Function<? super V, ? extends T> before) {
Objects.requireNonNull(before);
return (V v) -> apply(before.apply(v));
} default <V> Function<T, V> andThen(Function<? super R, ? extends V> after) {
Objects.requireNonNull(after);
return (T t) -> after.apply(apply(t));
} static <T> Function<T, T> identity() {
return t -> t;
}
}
2)、使用:
Function对应抽象方法:apply
List<Student> list= Arrays.asList(new Student("jack",1),new Student("tom",2));
Function<Student,Integer> function= Student::getId;
list.stream().map(function).forEach(System.out::print);
3)、Function总结:
Function是一个转换型的接口,其中的apply可以将一种类型的数据转化成另外一种类型的数据。
Function的变种就更多了。
四、List集合操作:
1、遍历List集合:
/**
* 1、遍历List集合
* 注:避免空指针异常
* */
public static void demo01(){
UserVO vo = new UserVO(1,"a",null);
List<UserVO> list = new ArrayList<>();
list.add(vo);
//一、过滤集合为空情况,二、过滤group为空的情况
Optional.ofNullable(list).ifPresent(p -> {
p.stream().filter(pi -> !ObjectUtils.isEmpty(pi.getGroup())).forEach(po -> {
System.out.println("a".equals(po.getGroup()));
});
});
//三、List中取出指定字段等于指定值的对象
UserVO userVO = list.stream().filter(pi -> !ObjectUtils.isEmpty(pi.getUuid()))
.filter(pi -> pi.getUuid().equals(1))
.findFirst().orElse(null);
System.out.printf("结果:"+userVO);
}
2、List集合转Map<k,T>集合:
/**
* 2、List集合转Map<k,T>集合
* */
public static void demo02(){
UserVO vo = new UserVO(1,"a",null);
UserVO vo1 = new UserVO(1,"b",null);
UserVO vo2 = new UserVO(1,"c",null);
UserVO vo3 = new UserVO(2,"a",null);
UserVO vo4 = new UserVO(3,"b",null);
List<UserVO> list = new ArrayList<>();
list.add(vo);
list.add(vo1);
list.add(vo2);
list.add(vo3);
list.add(vo4);
//uuid为key,UserVO为value
//(k1,k2)->k1 如果有重复的key,则保留第一个
//(k1,k2)->k2 如果有重复的key,则保留最后一个
Map<Integer , UserVO> map1 = list.stream().collect(Collectors.toMap(UserVO::getUuid, p -> p, (k1,k2) -> k1));
Optional.ofNullable(map1.get(1)).ifPresent(p -> {
System.out.println(p.getName());
});
}
3、List集合转Map<k,List<T>>集合:
/**
* 3、List集合转Map<k,List<T>>集合
* */
public static void demo03(){
UserVO vo = new UserVO(1,"a",null);
UserVO vo1 = new UserVO(1,"b",null);
UserVO vo2 = new UserVO(1,"c",null);
UserVO vo3 = new UserVO(2,"a",null);
UserVO vo4 = new UserVO(3,"b",null);
List<UserVO> list = new ArrayList<>();
list.add(vo);
list.add(vo1);
list.add(vo2);
list.add(vo3);
list.add(vo4);
//groupingBy:分组
Map<Integer , List<UserVO>> map = list.stream().collect(Collectors.groupingBy(UserVO::getUuid));
Optional.ofNullable(map.get(1)).ifPresent(p -> {
p.stream().forEach(po -> {
System.out.println(po.getName());
});
});
}
4、List集合全部/部分复制到另一个List集合:
/**
* 4、List集合全部/部分复制到另一个List集合
* 注:
* (1)、list集合的全部内容复制到list1集合中
* (2)、list集合中部分(uuid与name)字段的全部内容复制到list2集合中
* (3)、list集合的截取部分内容复制到list3集合中
* */
public static void demo04(){
List<UserVO> list = new ArrayList<>();
List<UserVO> list1 = new ArrayList<>();
List<UserVO> list2 = new ArrayList<>();
List<UserVO> list3 = new ArrayList<>();
UserVO vo = new UserVO(1,"a",null);
UserVO vo1 = new UserVO(1,"b",null);
UserVO vo2 = new UserVO(1,"c",null);
UserVO vo3 = new UserVO(2,"a",null);
UserVO vo4 = new UserVO(3,"b",null);
list.add(vo);
list.add(vo1);
list.add(vo2);
list.add(vo3);
list.add(vo4);
//一、list集合的全部内容复制到list1集合中
list1.addAll(list);
//二、list集合中部分(uuid与name)字段的全部内容复制到list2集合中
list2 = list.stream().map(p -> new UserVO(p.getUuid(),p.getName())).collect(Collectors.toList());
System.out.println(list2);
//三、list集合的截取部分内容复制到list3集合中
list3.addAll(list.subList(0 , 2));
System.out.println(list3);
}
5、List集合中根据对象某属性进行计算(求和、最大值与最小值):
/**
* 5、List集合中根据对象某属性进行计算(求和、最大值与最小值)
* 注:
* (1)、对list集合UserVO对象中uuid字段求和
* (2)、对list集合UserVO对象中uuid字段求最大值
* (3)、对list集合UserVO对象中uuid字段求最小值
* (4)、整合操作
* Comparator:比较器
* */
public static void demo05(){
List<UserVO> list = new ArrayList<>();
UserVO vo = new UserVO(1,"a",null);
UserVO vo1 = new UserVO(1,"b",null);
UserVO vo2 = new UserVO(1,"c",null);
UserVO vo3 = new UserVO(2,"a",null);
UserVO vo4 = new UserVO(3,"b",null);
list.add(vo);
list.add(vo1);
list.add(vo2);
list.add(vo3);
list.add(vo4);
//一、对list集合UserVO对象中uuid字段求和
Integer sumVO = list.stream().mapToInt(UserVO::getUuid).sum();
System.out.println(sumVO);
//二、对list集合UserVO对象中uuid字段求最大值
Integer maxVO = list.stream().max(Comparator.comparing(UserVO::getUuid)).get().getUuid();
System.out.println(maxVO);
//三、对list集合UserVO对象中uuid字段求最小值
Integer minVO = list.stream().min(Comparator.comparing(UserVO::getUuid)).get().getUuid();
System.out.println(minVO);
//四、List集合中根据对象某属性进行计算
IntSummaryStatistics cal = list.stream().collect(Collectors.summarizingInt(UserVO::getUuid));
System.out.println("总和"+cal.getSum());
System.out.println("最大"+cal.getMax());
System.out.println("最小"+cal.getMin());
System.out.println("平均"+cal.getAverage());
System.out.println("计数"+cal.getCount());
}
6、List集合转Map<k,List<T>>集合再进行遍历:
/**
* 6、List集合转Map<k,List<T>>集合再进行遍历
* */
public static void demo06(){
UserVO vo = new UserVO(1,"a",null);
UserVO vo1 = new UserVO(1,"b",null);
UserVO vo2 = new UserVO(1,"c",null);
UserVO vo3 = new UserVO(2,"a",null);
UserVO vo4 = new UserVO(3,"b",null);
List<UserVO> list = new ArrayList<>();
list.add(vo);
list.add(vo1);
list.add(vo2);
list.add(vo3);
list.add(vo4);
//groupingBy:分组
Map<Integer , List<UserVO>> map = list.stream().collect(Collectors.groupingBy(UserVO::getUuid));
if(!ObjectUtils.isEmpty(map)) {
Set<Map.Entry<Integer , List<UserVO>>> en = map.entrySet();
for (Map.Entry<Integer , List<UserVO>> entry : en) {
//获取KEY值
Integer key = entry.getKey();
//获取VALUE值
List<UserVO> userVOList = entry.getValue(); System.out.println("KEY值:"+key+",VALUE值:"+userVOList);
}
}
}
搜索
复制
3、数组、集合、Lambda、Stream与Optional类的更多相关文章
- Java8 Lambda表达式、Optional类浅析
1.概念 Lambda是一个匿名函数,可以将其理解为一段可以传递的代码(将代码像数据一样进行传递)可以写出更简洁.更灵活的代码.作为一种更紧凑的代码风格,使得java语言的表达能利得到了提升. 2. ...
- java数组集合元素的查找
java数组和集合的元素查找类似,下面以集合为例. 数组集合元素查找分为两类: 基本查找: 二分折半查找: 基本查找: 两种方式都是for循环来判断,一种通过索引值来判断,一种通过数组索引判断. 索引 ...
- 010-jdk1.8版本新特性二-Optional类,Stream流
1.5.Optional类 1.定义 Optional 类是一个可以为null的容器对象.如果值存在则isPresent()方法会返回true,调用get()方法会返回该对象. Optional 是个 ...
- Java8 Lambda/Stream使用说明
一.Stream流1. 流的基本概念 1.1 什么是流?流是Java8引入的全新概念,它用来处理集合中的数据,暂且可以把它理解为一种高级集合.众所周知,集合操作非常麻烦,若要对集合进行筛选.投影,需要 ...
- Java 8 Optional类使用的实践经验
前言 Java中空指针异常(NPE)一直是令开发者头疼的问题.Java 8引入了一个新的Optional类,使用该类可以尽可能地防止出现空指针异常. Optional 类是一个可以为null的容器对象 ...
- 简洁又快速地处理集合——Java8 Stream(下)
上一篇文章我讲解 Stream 流的基本原理,以及它与集合的区别关系,讲了那么多抽象的,本篇文章我们开始实战,讲解流的各个方法以及各种操作 没有看过上篇文章的可以先点击进去学习一下 简洁又快速地处理集 ...
- 超强的Lambda Stream流操作
原文:https://www.cnblogs.com/niumoo/p/11880172.html 在使用 Stream 流操作之前你应该先了解 Lambda 相关知识,如果还不了解,可以参考之前文章 ...
- Java8 新特性 Lambda & Stream API
目录 Lambda & Stream API 1 Lambda表达式 1.1 为什么要使用lambda表达式 1.2 Lambda表达式语法 1.3 函数式接口 1.3.1 什么是函数式接口? ...
- Java8新特性之空指针异常的克星Optional类
Java8新特性系列我们已经介绍了Stream.Lambda表达式.DateTime日期时间处理,最后以"NullPointerException" 的克星Optional类的讲解 ...
随机推荐
- vue3中pinia的使用总结
pinia的简介和优势: Pinia是Vue生态里Vuex的代替者,一个全新Vue的状态管理库.在Vue3成为正式版以后,尤雨溪强势推荐的项目就是Pinia.那先来看看Pinia比Vuex好的地方,也 ...
- python查找相似图片或重复图片
1.查找重复图片 利用文件的MD5值可查找完全一样的重复图片 import os,time,hashlib def getmd5(file): if not os.path.isfile(file): ...
- 题解 P6745 『MdOI R3』Number
前言 不知道是不是正解但是觉得挺好理解. 科学计数法 将一个数表示为\(a\times 10^x\) 的形式.其中\(a\leq10\),\(x\) 为整数. \(\sf Solution\) 其实这 ...
- Nginx四层负载均衡1
1.Nginx负载均衡Redis 服务器 IP地址 作用 系统版本 Nginx代理服务器 10.0.0.38 负载均衡服务器 Rocky8.6 Redis服务器1 10.0.0.18 Redis服务器 ...
- 论文笔记 - An Explanation of In-context Learning as Implicit Bayesian Inference
这位更是重量级.这篇论文对于概率论学的一塌糊涂的我简直是灾难. 由于 prompt 的分布与预训练的分布不匹配(预训练的语料是自然语言,而 prompt 是由人为挑选的几个样本拼接而成,是不自然的自然 ...
- C#在Xp系统执行.exe程序的报错怎么查看原因
我的电脑---->管理---->事件查看器----->应用程序,查看错误来源
- RabbitMq消息手动应答、放回队列重新消费、设置队列消息持久化、分发模式
RabbitMq消息手动应答,放回队列重新消费,设置队列消息持久化 消息应答 概念 消费者完成一个任务可能需要一段时间,如果其中一个消费者处理一个长的任务并仅只完成了部分突然它挂掉了,会发生什么情况. ...
- .NET复习总纲
以下是自己学习遇到比较好的课程和学习网站,如果大家有更好的课程推荐,可以打在评论区或者私聊我,让我也进行学习和补充进文档 一..NET基础 官方文档:https://learn.microsoft.c ...
- Go语言核心36讲51
你好,我是郝林,今天我们继续分享程序性能分析基础的内容. 在上一篇文章中,我们围绕着"怎样让程序对CPU概要信息进行采样"这一问题进行了探讨,今天,我们再来一起看看它的拓展问题. ...
- 【项目案例】配置小型网络WLAN基本业务示例
组网需求 如图1-1所示,AC直接与AP连接.现某企业分支机构为了保证工作人员可以随时随地的访问Internet,需要通过部署WLAN基本业务实现移动办公. 具体要求如下: 1.提供名为"t ...