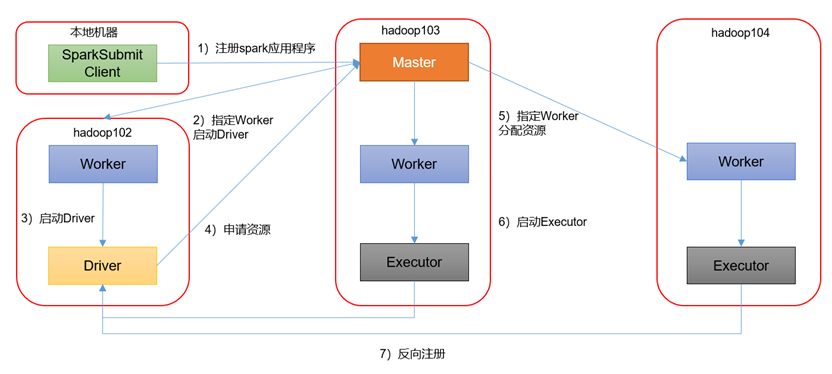
Spark详解(03) - Spark3.0.0运行环境安装
Spark详解(03) - Spark3.0.0运行环境安装
Spark运行模式
Spark常见部署模式:
Local模式:在本地部署单个Spark服务
所谓的Local模式,就是不需要其他任何节点资源就可以在本地执行Spark代码的环境,一般用于教学,调试,演示等。
在IDEA中运行代码的环境称之为开发环境,和Local模式还是有区别的。
Standalone模式:Spark自带的任务调度模式。(国内常用)
YARN模式:Spark使用Hadoop的YARN组件进行资源与任务调度。(国内常用)
Windows模式:为了方便在学习测试spark程序,Spark提供了可以在windows系统下启动本地集群的方式,这样,在不使用虚拟机或服务器的情况下,也能满足Spark的基本使用。
Mesos & K8S模式:(了解)。
Mesos是Apache下的开源分布式资源管理框架,它被称为是分布式系统的内核,在Twitter得到广泛使用,管理着Twitter超过30,0000台服务器上的应用部署,但是在国内,依然使用着传统的Hadoop大数据框架,所以国内使用Mesos框架的并不多,但是原理都差不多。
容器化部署是目前业界很流行的一项技术,基于Docker镜像运行能够让用户更加方便地对应用进行管理和运维。容器管理工具中最为流行的就是Kubernetes(k8s),而Spark也在最近的版本中支持了k8s部署模式。详情参考官网地址:https://spark.apache.org/docs/latest/running-on-kubernetes.html
Spark安装地址
文档查看地址:https://spark.apache.org/docs/3.0.0/
官网下载地址:https://spark.apache.org/downloads.html
镜像历史版本下载地址:https://archive.apache.org/dist/spark/
本文使用的版本下载地址:https://archive.apache.org/dist/spark/spark-3.0.0/spark-3.0.0-bin-hadoop3.2.tgz
Local模式安装(测试环境)
Local模式就是运行在一台计算机上的模式,通常就是用于测试环境。
安装
Local模式的安装非常简单,直接将安装包上传到服务器并解压即可使用,具体操作步骤如下
上传安装包park-3.0.0-bin-hadoop3.2.tgz到服务器
[root@hadoop102 software]# tar -zxvf spark-3.0.0-bin-hadoop3.2.tgz -C /opt/module/
[root@hadoop102 software]# cd /opt/module/
[root@hadoop102 module]# mv spark-3.0.0-bin-hadoop3.2/ spark-local
使用
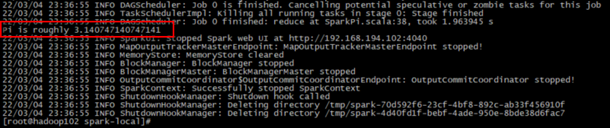
(1)local: 没有指定线程数,则所有计算都运行在一个线程当中,没有任何并行计算
(2)local[K]:指定使用K个Core来运行计算,比如local[2]就是运行2个Core来执行
(3)local[*]:默认模式。自动按照CPU最多核来设置线程数。比如CPU有8核,Spark自动设置8个线程计算。
spark-examples_2.12-3.0.0.jar:要运行的程序jar包名称;
10:要运行程序的输入参数(这里表示计算圆周率π的次数,计算次数越多,准确率越高);
[root@hadoop102 spark-local]# bin/spark-submit
官方WordCount案例
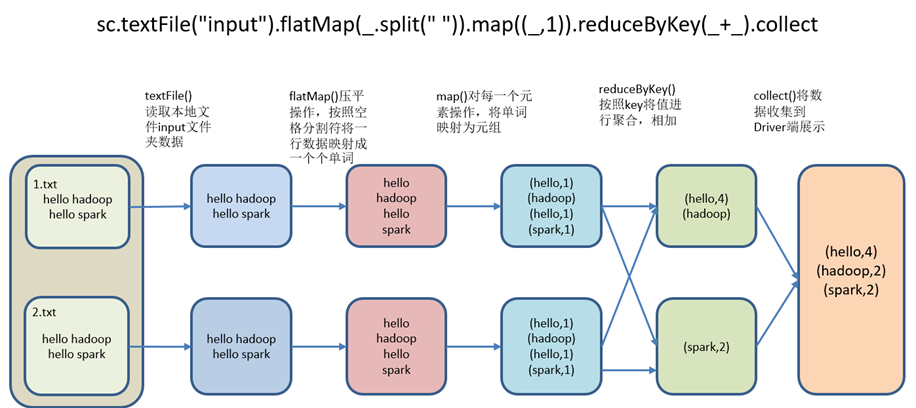
在input下创建2个文件1.txt和2.txt,并输入内容
(2)使用bin/spark-shell命令启动spark-shell
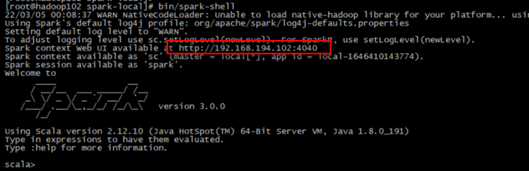
注意:sc是SparkCore程序的入口;spark是SparkSQL程序入口;master = local[*]表示本地模式运行。
Spark context Web UI available at http://192.168.194.102:4040
Spark context available as 'sc' (master = local[*], app id = local-1646410143774).
再开启一个hadoop102远程连接窗口,使用jps查看SparkSubmit进程
spark-submit,是将jar上传到集群,执行Spark任务;
spark-shell,相当于命令行工具,本身也是一个Application。
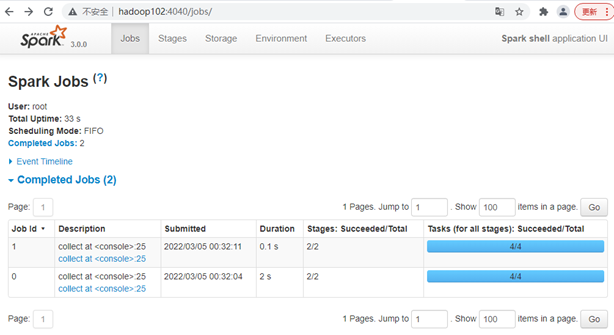
(3)登录hadoop102:4040,查看程序运行情况(注意:spark-shell窗口关闭掉,则hadoop102:4040页面关闭)
res0: Array[(String, Int)] = Array((hello,4), (spark,2), (hadoop,2))
Standalone(独立)模式
Standalone模式(也称独立模式)是Spark自带的资源调动引擎,构建一个由Master + Slave构成的Spark集群,Spark运行在集群中。
这个要和Hadoop中的Standalone区别开来。这里的Standalone是指只用Spark来搭建一个集群,不需要借助Hadoop的Yarn和Mesos等其他框架。
安装
[root@hadoop102 module]# tar -zxvf spark-3.0.0-bin-hadoop3.2.tgz -C /opt/module/
[root@hadoop102 module]# cd /opt/module/
[root@hadoop102 module]# mv spark-3.0.0-bin-hadoop3.2/ spark-standlone
[root@hadoop102 module]# cd spark-standlone/conf/
[root@hadoop102 conf]# mv slaves.template slaves
[root@hadoop102 conf]# vi slaves
[root@hadoop102 conf]# mv spark-env.sh.template spark-env.sh
[root@hadoop102 conf]# vi spark-env.sh
[root@hadoop102 spark-standlone]# cd ../
[root@hadoop102 spark-standlone]# vi /opt/module/spark-standlone/sbin/spark-config.sh
export JAVA_HOME=export JAVA_HOME=/usr/local/jdk1.8.0_191
如果不配置JAVA_HOME环境变量,在执行sbin/start-all.sh命令启动spark集群的时候可能会出现JAVA_HOME is not set 异常
[root@hadoop102 conf]# cd /opt/module/
[root@hadoop102 module]# scp -r spark-standlone/ hadoop103:/opt/module/spark-standlone
[root@hadoop102 module]# scp -r spark-standlone/ hadoop104:/opt/module/spark-standlone
[root@hadoop102 module]# cd /opt/module/spark-standlone/
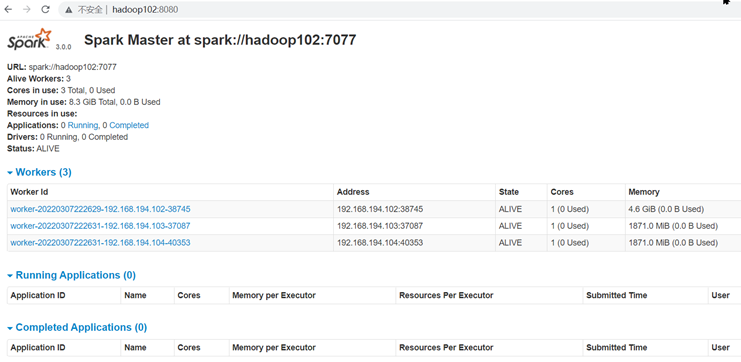
[root@hadoop102 spark-standlone]# sbin/start-all.sh
[root@hadoop102 spark-standlone]# jps
Spark集群测试案例
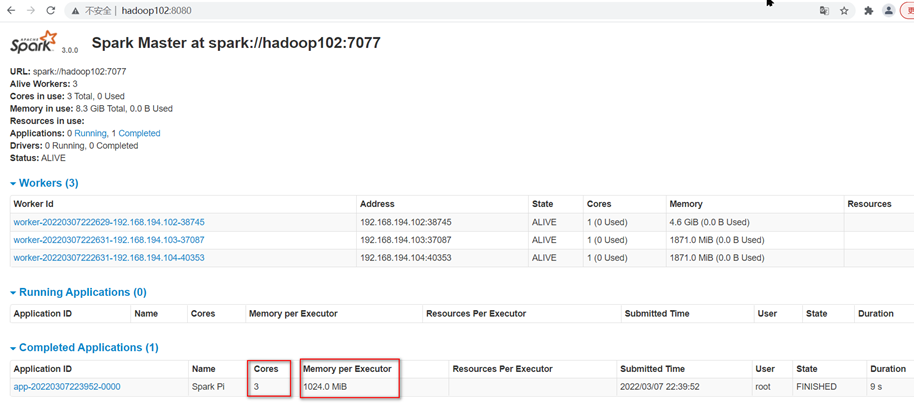
页面查看http://hadoop102:8080/,发现执行本次任务,默认采用三台服务器节点的总核数3核,每个节点内存1024M。
--class org.apache.spark.examples.SparkPi \
--master spark://hadoop102:7077 \
./examples/jars/spark-examples_2.12-3.0.0.jar \
|
参数 |
解释 |
可选值举例 |
|
--class |
Spark程序中包含主函数的类 |
|
|
--master |
Spark程序运行的模式 |
本地模式:local[*]、spark://hadoop102:7077、 Yarn |
|
--executor-memory 1G |
指定每个executor可用内存为1G |
符合集群内存配置即可,具体情况具体分析。 |
|
--total-executor-cores 2 |
指定所有executor使用的cpu核数为2个 |
|
|
application-jar |
打包好的应用jar,包含依赖。这个URL在集群中全局可见。 |
|
|
application-arguments |
传给main()方法的参数 |
配置历史服务
由于spark-shell停止掉后,hadoop102:4040页面就看不到历史任务的运行情况,所以开发时都配置历史服务器记录任务运行情况。
1)修改spark-default.conf.template名称
mv spark-defaults.conf.template spark-defaults.conf
2)修改spark-default.conf文件,配置日志存储路径(写),并同步到其他服务器上
spark.eventLog.dir hdfs://hadoop102:8020/directory
-Dspark.history.fs.logDirectory=hdfs://hadoop102:8020/directory
-Dspark.history.retainedApplications=30"
# 参数1 Dspark.history.ui.port:WEBUI访问的端口号为18080
# 参数2 Dspark.history.fs.logDirectory:指定历史服务器日志存储路径(读)
启动Hadoop集群,并在HDFS上创建/directory目录。
--class org.apache.spark.examples.SparkPi \
--master spark://hadoop102:7077 \
./examples/jars/spark-examples_2.12-3.0.0.jar \
7)查看Spark历史服务地址:hadoop102:18080
配置高可用(HA)
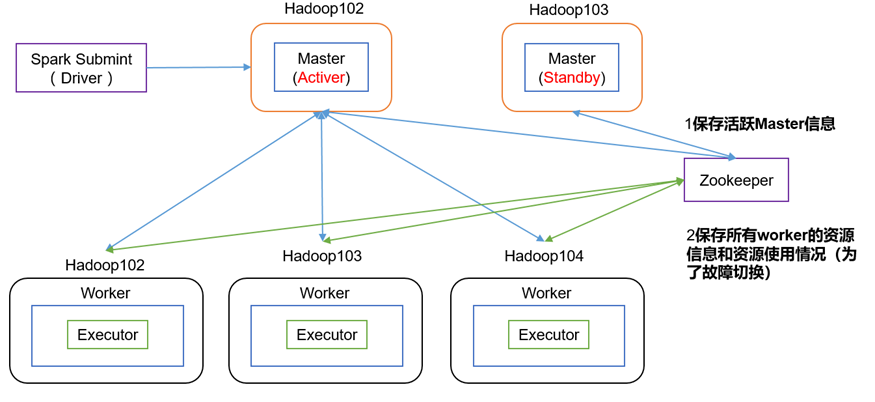
安装Zookeeper集群并启动:《Zookeeper详解(02) - zookeeper安装部署-单机模式-集群模式》
export SPARK_DAEMON_JAVA_OPTS="
-Dspark.deploy.recoveryMode=ZOOKEEPER
-Dspark.deploy.zookeeper.url=hadoop102,hadoop103,hadoop104
-Dspark.deploy.zookeeper.dir=/spark"
#Zookeeper3.5的AdminServer默认端口是8080,和Spark的WebUI冲突
export SPARK_MASTER_WEBUI_PORT=8989
在Zookeeper节点中自动创建/spark目录,用于管理:
再启动一个hadoop102窗口,将/opt/module/spark-local/input中的测试数据上传到hadoop集群的/input目录
hadoop fs -put /opt/module/spark-local/input/ /input
--master spark://hadoop102:7077,hadoop103:7077 \
参数:--master spark://hadoop102:7077指定要连接的集群的master
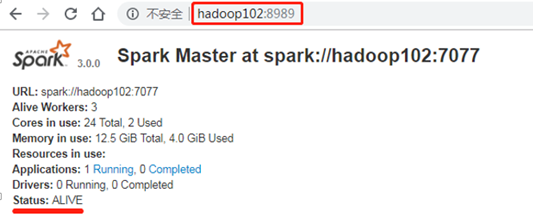
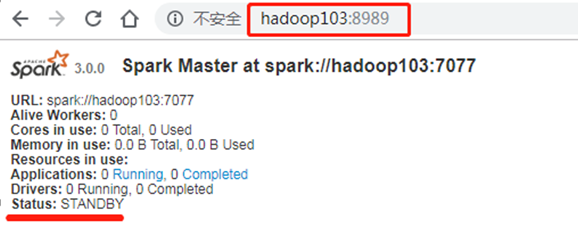
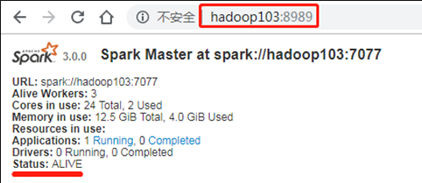
5831 CoarseGrainedExecutorBackend
Kill掉hadoop102的master进程,页面中观察http://hadoop103:8080/的状态是否切换为active。
运行模式
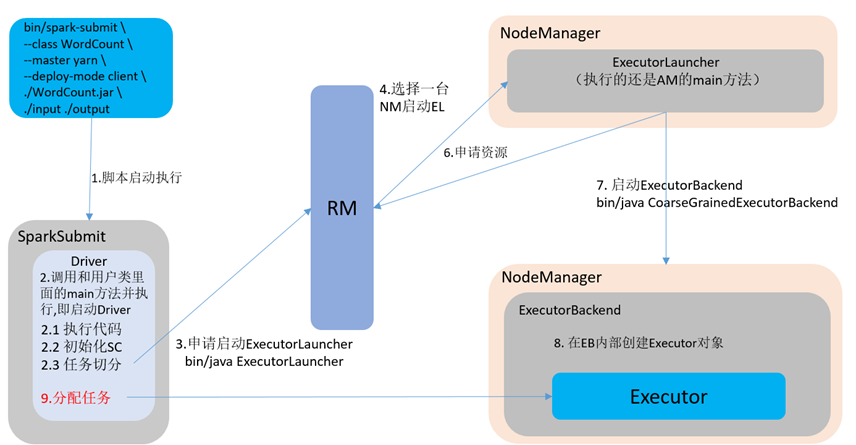
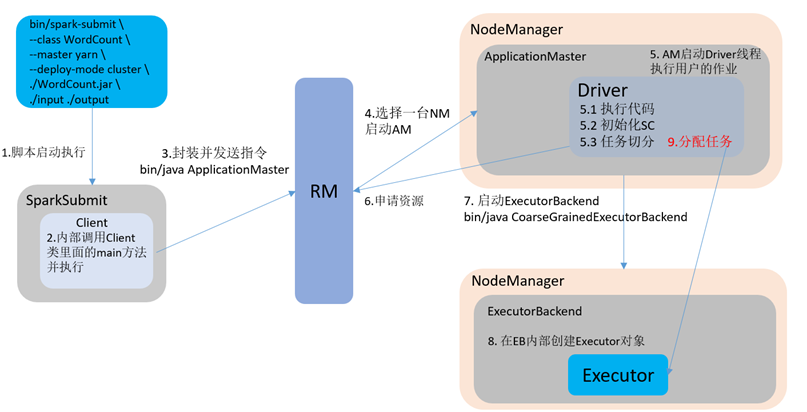
Spark有standalone-client(客户端模式)和standalone-cluster(集群模式)两种模式,主要区别在于:Driver程序的运行节点。
--class org.apache.spark.examples.SparkPi \
--master spark://hadoop102:7077 \
./examples/jars/spark-examples_2.12-3.0.0.jar \
--deploy-mode client,表示Driver程序运行在本地客户端
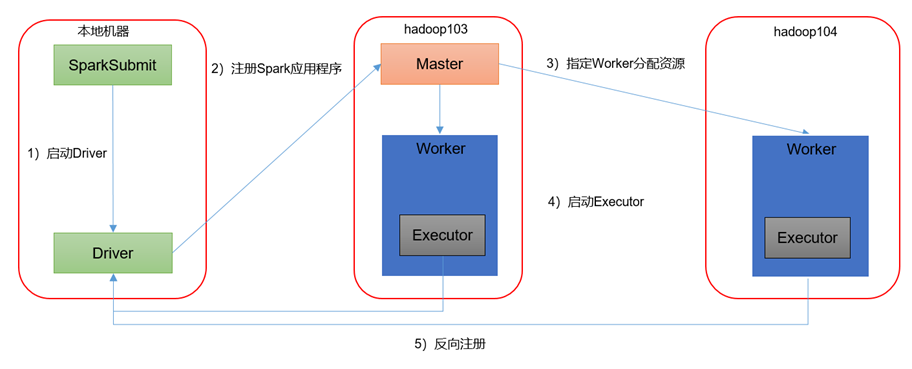
--class org.apache.spark.examples.SparkPi \
--master spark://hadoop102:7077 \
./examples/jars/spark-examples_2.12-3.0.0.jar \
--deploy-mode cluster,表示Driver程序运行在集群
client用于测试,因为该模式的Driver运行在本地客户端,会与yarn集群产生较大的网络通信,从而导致网卡流量激增;它的好处在于直接执行时,在本地可以查看到所有的log,方便调试;
由于cluster模式,客户端的终端显示的仅是简单运行状况,无法像client模式将所有的日志信息都显示到客户端的终端上,若要查看cluster模式下的运行日志信息,只能够通过如下方式进行查看
在http://192.168.194.102:8080/页面点击Completed Drivers里面的Worker
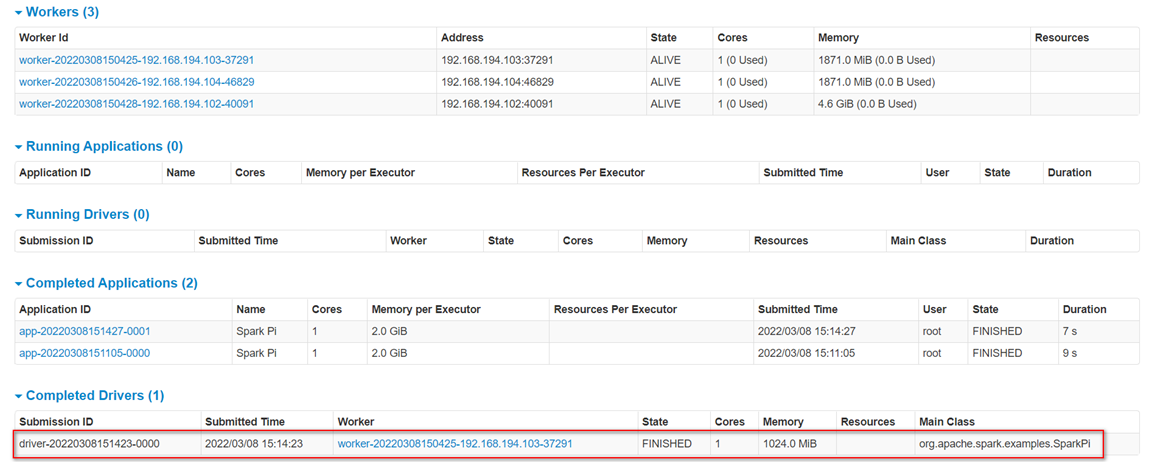
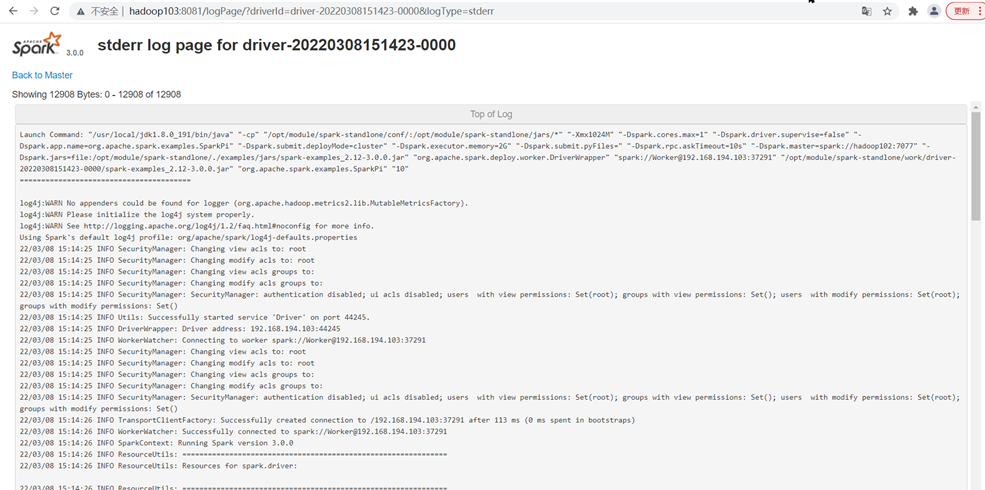
跳转到Spark Worker页面,点击Finished Drivers中Logs下面的stdout

Spark ON Yarn模式(重点)
Spark客户端直接连接Yarn,不需要额外构建Spark集群。
安装
[hadoop@hadoop102 software]$ tar -zxvf spark-3.0.0-bin-hadoop3.2.tgz -C /opt/module/
[hadoop@hadoop102 software]$ cd /opt/module/
[hadoop@hadoop102 module]$ mv spark-3.0.0-bin-hadoop3.2/ spark-yarn
如果使用的环境是虚拟机且内存较少,为防止执行过程进行被意外杀死,做如下配置
<!--是否启动一个线程检查每个任务正使用的物理内存量,如果任务超出分配值,则直接将其杀掉,默认是true -->
<name>yarn.nodemanager.pmem-check-enabled</name>
<!--是否启动一个线程检查每个任务正使用的虚拟内存量,如果任务超出分配值,则直接将其杀掉,默认是true -->
<name>yarn.nodemanager.vmem-check-enabled</name>
xsync /opt/module/hadoop-3.1.3/etc/hadoop/yarn-site.xml
[hadoop@hadoop102 conf]$ mv spark-env.sh.template spark-env.sh
[hadoop@hadoop102 conf]$ vi spark-env.sh
在文件末尾添加YARN_CONF_DIR配置,保证后续运行任务的路径都变成集群路径
YARN_CONF_DIR=/opt/module/hadoop-3.1.3/etc/hadoop
参数:--master yarn,表示Yarn方式运行;--deploy-mod表示客户端方式运行程序
如果运行的时候,抛出如下异常ClassNotFoundException:com.sun.jersey.api.client.config.ClientConfig
-原因分析:Spark2中jersey版本是2.22,但是yarn中还需要依赖1.9,版本不兼容
<name>yarn.timeline-service.enabled</name>
9)查看http://192.168.194.102:8088/页面,点击History,查看历史页面

spark-shell --master yarn --deploy-mode client
配置历史服务
为了查看spark程序的历史运行情况,需要配置一下历史服务器。
[hadoop@hadoop102 conf]$ mv spark-defaults.conf.template spark-defaults.conf
[hadoop@hadoop102 conf]$ vi spark-defaults.conf
spark.eventLog.dir hdfs://hadoop102:9820/directory
[hadoop@hadoop102 conf]$ vi spark-env.sh
-Dspark.history.fs.logDirectory=hdfs://hadoop102:9820/directory
-Dspark.history.retainedApplications=30"
# 参数3含义:指定保存Application历史记录的个数,如果超过这个值,旧的应用程序信息将被删除,这个是内存中的应用数,而不是页面上显示的应用数。
hadoop@hadoop102 conf]$ vi spark-defaults.conf
spark.yarn.historyServer.address=hadoop102:18080
[hadoop@hadoop102 conf]$ hadoop fs -mkdir /directory
[hadoop@hadoop102 spark-yarn]$ sbin/start-history-server.sh
停止命令:sbin/stop-history-server.sh
--class org.apache.spark.examples.SparkPi \
./examples/jars/spark-examples_2.12-3.0.0.jar \
Web页面查看日志:http://hadoop102:8088/cluster

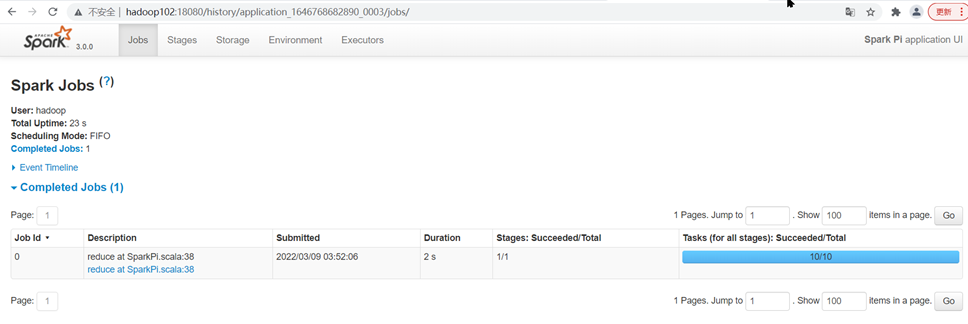
待spark任务执行成功后点击"history"跳转到http://hadoop102:18080/
Spark ON Yarn运行模式
Spark有yarn-client(客户端模式)和yarn-cluster(集群模式)两种模式,主要区别在于:Driver程序的运行节点。
yarn-client:Driver程序运行在客户端,适用于交互、调试,希望立即看到spark程序的输出结果。
yarn-cluster:Driver程序运行在由ResourceManager启动的APPMaster适用于生产环境。
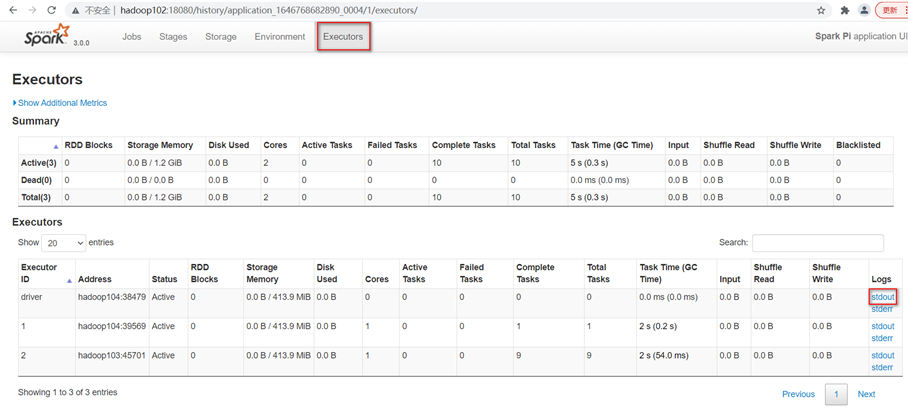
查看http://hadoop103:8088/cluster页面,点击History按钮,跳转到历史详情页面

在http://hadoop102:18080点击Executors->点击driver中的stdout
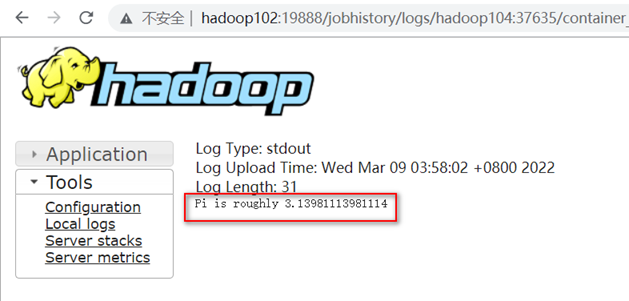
注意:如果在yarn日志端无法查看到具体的日志,则需要配置并启动Yarn历史服务器,具体配置流程请参考文章《Hadoop详解(02)Hadoop集群运行环境搭建》--配置历史服务器(可选)章节
Windows模式(开发环境)
将文件spark-3.0.0-bin-hadoop3.2.tgz解压缩到无中文无空格的任意路径下
双击执行解压缩文件路径下bin目录中的spark-shell.cmd文件,启动Spark本地环境
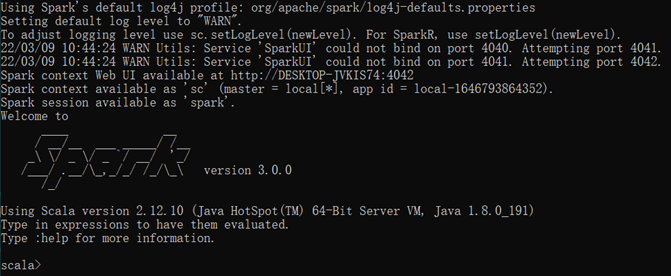
创建D:/input/word.txt文件并在文件中添加内容, 在命令行中输入脚本代码
scala> sc.textFile("D:/input/word.txt").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).collect
res0: Array[(String, Int)] = Array((hello,2), (spark,1), (hadoop,1))
则需要在启动spark-shell.cmd脚本的时候使用以管理员身份运行
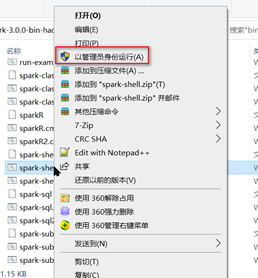
在spark安装目录的bin目录下,按Shift右键空白处,选择 在此处打开Powershell窗口
Mesos & K8S模式(了解)
几种部署模式对比
|
模式 |
Spark安装机器数 |
需启动的进程 |
所属者 |
|
Local |
1 |
无 |
Spark |
|
Standalone |
3 |
Master及Worker |
Spark |
|
Yarn |
1 |
Yarn及HDFS |
Hadoop |
端口号总结
1)Spark查看当前Spark-shell运行任务情况端口号:4040
2)Spark Master内部通信服务端口号:7077 (类比于Hadoop的9820端口)
3)Spark Standalone模式Master Web端口号:8080(类比于Hadoop YARN任务运行情况查看端口号:8088)
4)Spark历史服务器端口号:18080(类比于Hadoop历史服务器端口号:19888)
7077:spark基于standalone的提交任务的端口号
Spark详解(03) - Spark3.0.0运行环境安装的更多相关文章
- RocketMQ详解(三)启动运行原理
专题目录 RocketMQ详解(一)原理概览 RocketMQ详解(二)安装使用详解 RocketMQ详解(三)启动运行原理 RocketMQ详解(四)核心设计原理 RocketMQ详解(五)总结提高 ...
- Tsung运行环境安装(转)
转自:http://www.cnblogs.com/tsbc/p/4272974.html#_Toc372013359 tsung Tsung运行环境安装 检查安装一下依赖包,以免在安装的时候报错.( ...
- AppCrawler自动化遍历使用详解(版本2.1.0 )
AppCrawle是自动遍历的app爬虫工具,最大的特点是灵活性,实现:对整个APP的所有可点击元素进行遍历点击. 优点: 1.支持android和iOS, 支持真机和模拟器 2.可通过配置来设定 ...
- AppCrawler自动化遍历使用详解(版本2.1.0 )(转)
AppCrawle是自动遍历的app爬虫工具,最大的特点是灵活性,实现:对整个APP的所有可点击元素进行遍历点击. 优点: 1.支持android和iOS, 支持真机和模拟器 2.可通过配置来设定 ...
- 详解 Vue 2.4.0 带来的 4 个重大变化
在这篇文章中,我将跟大家分享4个有突破性新特性. 服务端渲染异步组件 包裹组件内实现属性继承 异步组件支持webpack3 组件渲染后可保留HTML注释 1.服务端渲染异步组件 在vue2.4.0以前 ...
- Spark详解
原文连接 http://xiguada.org/spark/ Spark概述 当前,MapReduce编程模型已经成为主流的分布式编程模型,它极大地方便了编程人员在不会分布式并行编程的情况下,将自己的 ...
- PayPal 开发详解(七):运行REST API SAMPLE
1.编译成功,修改配置文件 sdk_config.properties ,使用我们申请的测试帐号执行收款测试,clientId 和 clientSecret 参见 PayPal 开发详解(五) 2.将 ...
- rest_framework之频率详解 03
访问频率(节流) 1.某个用户一分钟之内访问的次数不能超过3次,超过3次则不能访问了,需要等待,过段时间才能再访问. 2.自定义访问频率.两个方法都必须写上. 登入页面的视图加上访问频率 3.返回值F ...
- spark——详解rdd常用的转化和行动操作
本文始发于个人公众号:TechFlow,原创不易,求个关注 今天是spark第三篇文章,我们继续来看RDD的一些操作. 我们前文说道在spark当中RDD的操作可以分为两种,一种是转化操作(trans ...
- nexus3.14.0版本linux环境安装、启动、搭建私库
本文介绍的是nexus3.14.0版本在linux环境下安装.启动.搭建私库. nexus3以上的版本太新了,网上很少介绍安装细节的.据了解和2.X版本有所不同了. 1.前提 linux机器上需先安装 ...
随机推荐
- java中list集合怎么判断是否为空
首先看下面代码 @RequestMapping("/getCatlist") public String getCatlist(HttpSession session,HttpSe ...
- Nginx通用优化示例
user nginx; worker_processes auto; #worket_cpu_affinity auto; error_log /var/log/nginx/error.log war ...
- java集合框架复习----(1)
文章目录 1 .集合框架思维导图 一.什么是集合 二.collection接口 1 .集合框架思维导图 一.什么是集合 存放在java.util.*.是一个存放对象的容器. 存放的是对象的引用,不是对 ...
- java简易两数计算器
public class calculator { public static void main(String[] args) { Scanner scanner = new Scanner(Sys ...
- day04-JavaScript01
JavaScript01 官方文档 http://www.w3school.com.cn/js/index.asp 基本说明: JavaScript能改变html内容,能改变html属性,能改变htm ...
- go基础语法50问,来看看你的go基础合格了吗?
目录 1.使用值为 nil 的 slice.map会发生啥 2.访问 map 中的 key,需要注意啥 3.string 类型的值可以修改吗 4.switch 中如何强制执行下一个 case 代码块 ...
- Flutter 构建windows应用
Flutter Windows 桌面端支持进入稳定版 | Flutter 中文文档 | Flutter 中文开发者网站 从2.10之后的版本,flutter已经正式支持构建windows应用.不过距离 ...
- pod(八):pod的调度——将 Pod 指派给节点
目录 一.系统环境 二.前言 三.pod的调度 3.1 pod的调度概述 3.2 pod自动调度 3.2.1 创建3个主机端口为80的pod 3.3 使用nodeName 字段指定pod运行在哪个节点 ...
- java学习之MybBaits
0x00前言 我前面使用的jdbc和jdbc的工具类集成的但是它们在少部分代码的情况下会会简单,但是以后如果项目较大jdbc的固定代码会很难维护,如果使用框架会简单很多,也标志着java学习正式进入到 ...
- 【网络】内网穿透方案&FRP内网穿透实战(基础版)
目录 前言 方案 方案1:公网 方案2:第三方内网穿透软件 花生壳 cpolar 方案3:云服务器做反向代理 FRP简介 FRP资源 FRP原理 FRP配置教程之SSH 前期准备 服务器配置 下载FR ...