python学习-Day7
作业讲解
'''
习题题目:
编写一个用户登录程序
要求最多尝试失误三次 过期自动提示并可重置尝试次数
用户登录成功之后进入内部循环 用户输入什么就打印什么 并给用户提供一个结束程序的特殊指令
获取用户输入的用户名和密码,可以处理首尾空格
用户的用户名和密码使用变量存储 通过程序获取用户名和密码比对
data = 'jason|123'
'''
# 用户登录功能 获取用户输入 比对用户数据
# 1.定义类似于数据库的数据 (单用户模式)
source_data = 'jason|123'
# 1.1 多用户模式登录
# source_data = ['jason|123', 'tony|123', 'kevin|321', 'jerry|222']
# 8.添加一个计数器
count = 1
# 5.添加循环
while True:
# 9.判断当前尝试的次数
if count == 4:
choice = input('您已经尝试三次了 是否继续(y/n)>>>:').strip()
if choice == 'y':
count = 1
else:
print('欢迎下次使用')
break
# 2.获取用户输入的用户名和密码
username = input('username>>>:').strip()
# TODO:自己可以结合自己的需求添加更多的校验
if len(username) == 0:
print('用户名不能为空')
continue
password = input('password>>>:').strip()
if len(password) == 0:
print('密码不能为空')
continue
# 3.切割原始数据得到用户名和密码再比对
real_name, real_pwd = source_data.split('|') # real_name, real_pwd=['jason','123'] 解压赋值
# 4.校验用户名和密码
if username == real_name and password == real_pwd:
print("登录成功")
# 6.添加内层循环
while True:
cmd = input('请输入您的指令>>>:').strip()
# 7.添加一个结束条件
if cmd == 'q':
break
print('正在执行您的命令:%s' % cmd)
else:
print('用户名或密码')
# 10.没错一次 计数器加一
count += 1

数据类型内置方法2
字符串(str)
这里我整理了比较完整的字符串的数据类型转换及内置方法,详情去我的番外篇博客看吧~
列表(list)
类型转换
但凡能被for循环遍历的数据类型都可以传给list()转换成列表类型,list()会跟for循环一样遍历出数据类型中包含的每一个元素然后放到列表中
# int
print(list(11)) # 不行
# float
print(list(11.11)) # 不行
#str
print(list('wdad')) # 结果:['w', 'd', 'a', 'd']
# dict
print(list({"name":"jason","age":18})) #结果:['name', 'age']
# tuple
print(list((1,2,3))) # 结果:[1, 2, 3]
# set
print(list({1,2,3,4})) # 结果:[1, 2, 3, 4]
# bool
print(list(True)) # 不行
内置方法
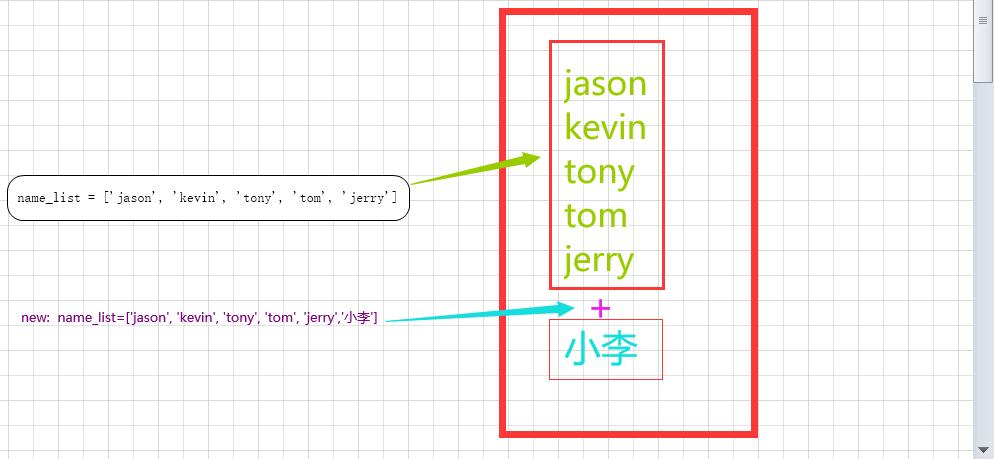
name_list = ['jason', 'kevin', 'tony', 'tom', 'jerry']
索引取值
# 正向取(从左往右)
print(name_list[0])
# 反向取(负号表示从右往左)
print(name_list[-1])
# 对于list来说,既可以按照索引取值,又可以按照索引修改指定位置的值,但如果索引不存在则报错
name_list[1] = 'martthow'
print(name_list)
# ['jason', 'martthow', 'tony', 'tom', 'jerry']
切片操作
# 顾头不顾尾:取出索引为1到3的元素
print(name_list[1:4]) # ['kevin', 'tony', 'tom']
print(name_list[-4:-1]) # ['kevin', 'tony', 'tom']
print(name_list[-1:-4:-1]) # ['jerry', 'tom', 'tony']
步长
# 第三个参数1代表步长,会从0开始,每次累加一个1即可,所以会取出索引0、1、2、3的元素
print(name_list[0:4:1]) # ['jason', 'kevin', 'tony', 'tom']
# 第三个参数2代表步长,会从0开始,每次累加一个2即可,所以会取出索引0、2的元素
print(name_list[0:4:2]) # ['jason', 'tony']
print(name_list[-1:-4:-1]) # ['jerry', 'tom', 'tony']
统计列表中元素的个数
print(len(name_list)) # 5
成员运算 (in和not in)
# 最小判断单位是元素不是元素里面的单个字符
print('j' in name_list) # False
print('jason' in name_list) # True
列表添加元素的方式*

# append()列表尾部追加'单个'元素
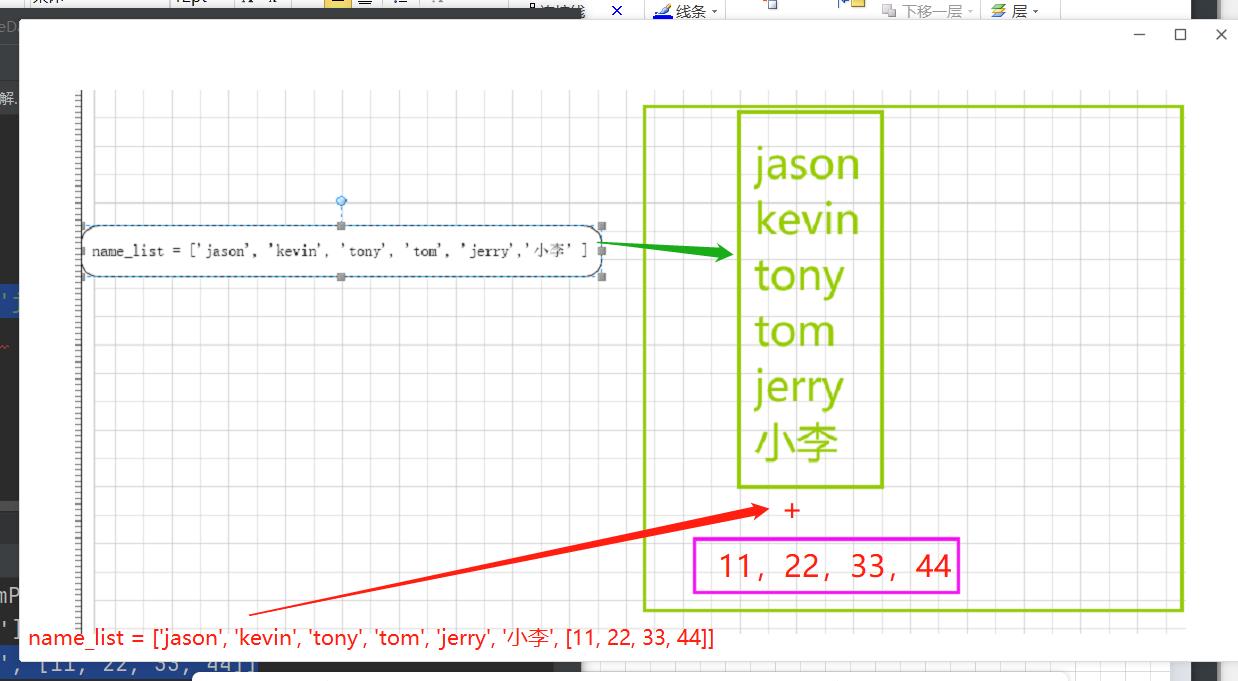
name_list.append('小李')
print(name_list)
name_list.append([11, 22, 33, 44])
print(name_list)
# insert()指定位置插入'单个'元素
name_list.insert(0, 123)
name_list.insert(2, '可不可以插个队')
name_list.insert(1, [11, 22, 33])
print(name_list)
# extend()合并列表
name_list.extend([11, 22, 33, 44, 55])
print(name_list)
'''extend其实可以看成是for循环+append'''
for i in [11, 22, 33, 44, 55]:
name_list.append(i)
print(name_list)
name_list += [11, 22, 33, 44, 55]
print(name_list) # 加号的效率不高
删除元素
# 通用的删除方式(del)
del name_list[0]
print(name_list)
# 就地删除(remove)
# remove()括号内指名道姓的直接删除某个元素,没有返回值
print(name_list.remove('jerry')) # None
print(name_list) # ['jason', 'kevin', 'tony', 'tom']
# 从左往右查找第一个 括号内需要删除的元素
# 延迟删除(pop)
print(name_list.pop()) # 默认是尾部弹出 jerry
print(name_list)
print(name_list.pop(2)) # 还可以指定索引值 tony
print(name_list)
修改列表元素(id)
print(id(name_list[0])) # 2614038082368
name_list[0] = 'jasonDSB'
print(id(name_list[0])) # 2614038926320
print(name_list)
排序(sort)
# sort()给列表内所有元素排序
# 排序时列表元素之间必须是相同数据类型,不可混搭,否则报错
ss = [44, 77, 99, 11, 22, 33, 88, 66]
ss.sort() # 默认是升序
print(ss) # [11, 22, 33, 44, 66, 77, 88, 99]
ss.sort(reverse=True) # 可以修改尾降序
# reverse用来指定是否跌倒排序,默认为False
print(ss) # [99, 88, 77, 66, 44, 33, 22, 11]
翻转
ss = [44, 77, 99, 11, 22, 33, 88, 66]
ss.reverse() # 前后颠倒
print(ss)
比较运算
s1 = [11, 22, 33]
s2 = [1, 2, 3, 4, 5, 6, 7, 8]
print(s1 > s2) # True
"""列表在做比较的时候 其实比的是对应索引位置上的元素,如果分出大小,则无需比较下一个元素"""
s1 = ['A', 'B', 'C'] # A>>>65
s2 = ['a'] # a>>>97
print(s1 > s2) # False
ss = [44, 77, 99, 11, 22, 33, 88, 66]
print(ss.index(99))
统计列表中某个元素出现的次数
l1 = [11, 22, 33, 44, 33, 22, 11, 22, 11, 22, 33, 22, 33, 44, 55, 44, 33]
print(l1.count(11)) # 统计元素11出现的次数
l1.clear() # 清空列表
print(l1) # []

可变类型与不可变类型
可变数据类型:值发生改变时,内存地址不变,即id不变,证明在改变原值
不可变类型:值发生改变时,内存地址也发生改变,即id也变,证明是没有在改变原值,是产生了新的值
'''
可变类型与不可变类型
可变类型 如:列表
值改变 内存地址不变 修改的是本身
不可变类型 如:字符串
值改变 内存地址肯定遍 修改过程产生了新的值
'''
数字类型( int \ float ):
>>> x = 10
>>> id(x)
1953464720
>>>
>>> x = 20
>>> id(x)
1953465040
# 内存地址改变了,说明整型是不可变数据类型,浮点型也一样
字符串:
>>> x = "qiao"
>>> id(x)
1853141915384
>>> x = "qiaoyu"
>>> id(x)
1853141915496
# 内存地址改变了,说明字符串是不可变数据类型
列表:
>>> list1 = ['tom','jack','egon']
>>> id(list1)
486316639176
>>> list1[2] = 'kevin'
>>> id(list1)
486316639176
>>> list1.append('lili')
>>> id(list1)
486316639176
# 对列表的值进行操作时,值改变但内存地址不变,所以列表是可变数据类型
元组:
>>> t1 = ("tom","jack",[1,2])
>>> t1[0]='TOM' # 报错:TypeError
>>> t1.append('lili') # 报错:TypeError
# 元组内的元素无法修改,指的是元组内索引指向的内存地址不能被修改
>>> t1 = ("tom","jack",[1,2])
>>> id(t1[0]),id(t1[1]),id(t1[2])
(4327403152, 4327403072, 4327422472)
>>> t1[2][0]=111 # 如果元组中存在可变类型,是可以修改,但是修改后的内存地址不变
>>> t1
('tom', 'jack', [111, 2])
>>> id(t1[0]),id(t1[1]),id(t1[2]) # 查看id仍然不变
(4327403152, 4327403072, 4327422472)
字典:
>>> dic = {'name':'egon','sex':'male','age':18}
>>>
>>> id(dic)
4327423112
>>> dic['age']=19
>>> dic
{'age': 19, 'sex': 'male', 'name': 'egon'}
>>> id(dic)
4327423112
# 对字典进行操作时,值改变的情况下,字典的id也是不变,即字典也是可变数据类型

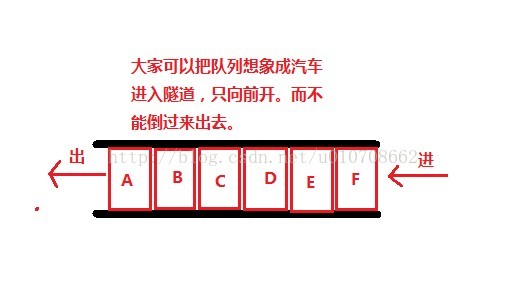
队列与堆栈
这里我们先使用列表模拟出队列与堆栈的特征
队列(先进先出)
new_list = []
# 先进
new_list.append(111)
new_list.append(222)
new_list.append(333)
# 先出
for i in new_list:
print(i)
print(new_list.pop(0))
print(new_list.pop(0))
print(new_list.pop(0))
堆栈(先进后出)
new_list = []
# 先进
new_list.append(111)
new_list.append(222)
new_list.append(333)
# 后出
print(new_list.pop())
print(new_list.pop())
print(new_list.pop())

今天的学习内容结束啦!!!
python学习-Day7的更多相关文章
- python学习Day7 数据类型的转换,字符编码演变历程
一.数据类型的转换 1.1.1.字符转列表:lst1 = str.split(默认空格,也可依据指定字符分界),若无分界字符,就没法拆分,这时可以直接放进list转成列表 ----> s1 = ...
- Python学习-day7 类 部分socket
这周还是继续关于类的学习,在面向对象的学习过程中又学习了网络编程,并且提交了编写FTP的作业. 复习一下类的相关概念和定义 类 属性 实例变量:内存中 ...
- python学习day7
目录 一.反射 二.socket 三.socketserver 一.反射 python中的反射功能是由以下四个内置函数提供:hasattr.getattr.setattr.delattr,改四个函数分 ...
- python学习day7 数据类型及内置方法补充
http://www.cnblogs.com/linhaifeng/articles/7133357.html#_label4 1.列表类型 用途:记录多个值(一般存放同属性的值) 定义方法 在[]内 ...
- python学习 day7 (3月8日)
read()读出来了之后文件里就从之后开始 光标不知道在哪 编码的进阶: 背景: ASCII:英文字母,数字,特殊符号,------------>二进制的对应关系 str: 一个字符 ---- ...
- python学习day7 深浅拷贝&文件操作
4-4 day07 深浅拷贝&文件操作 .get()用法 返回指定键的值,如果值不在字典中返回默认值. info={'k1':'v1,'K2':'v2'}mes = info.get('k1' ...
- Python学习记录day7
目录 Python学习记录day7 1. 面向过程 VS 面向对象 编程范式 2. 面向对象特性 3. 类的定义.构造函数和公有属性 4. 类的析构函数 5. 类的继承 6. 经典类vs新式类 7. ...
- python笔记 - day7
python笔记 - day7 参考: http://www.cnblogs.com/wupeiqi/articles/5501365.html 面向对象,初级篇: http://www.cnblog ...
- 【目录】Python学习笔记
目录:Python学习笔记 目标:坚持每天学习,每周一篇博文 1. Python学习笔记 - day1 - 概述及安装 2.Python学习笔记 - day2 - PyCharm的基本使用 3.Pyt ...
随机推荐
- vuex组成和原理?
组成: 组件间通信, 通过store实现全局存取 修改: 唯一途径, 通过commit一个mutations(同步)或dispatch一个actions(异步) 简写: 引入mapState.mapG ...
- java中会存在内存泄漏吗,请简单描述?
所谓内存泄露就是指一个不再被程序使用的对象或变量一直被占据在内存中.java中有垃圾回收机制,它可以保证一对象不再被引用的时候,即对象编程了孤儿的时候,对象将自动被垃圾回收器从内存中清除掉.由于Jav ...
- 面试问题之计算机网络:TCP滑动窗口
滑动窗口协议是传输层进行流量控制的一种措施,接收方通过通知发送方自己的窗口大小,从而控制发送方的发送速度,从而达到防止发送方发送速度过快而导致自己被淹没的目的,并且滑动窗口分为接收窗口和发送窗口.TC ...
- synchronize、Lock、ReenTrantLock 的区别
synchronize 和Lock: 1.synchronize 系java 内置关键字:而Lock 是一个类 2.synchronize 可以作用于变量.方法.代码块:而Lock 是显式地指定开始和 ...
- vue中v-model 数据双向绑定
表单输入绑定 v-model 数据双向绑定,只能应用在input /textare /select <div id="app"> <input type=&quo ...
- Goland环境配置——Goland上的第一个Go语言程序
安装好goland后,开始编写一个简单程序测试环境是否可用. 新建项目:按File-new-project进入如图new project界面,在Go一栏内的Location里填写项目路径(D:\GOO ...
- Ueditor上传本地音频MP3
遇到一个项目,客户要求能在编辑框中上传录音文件.用的是Ueditor编辑器,但是却不支持本地MP3上传并使用audio标签播放,只能搜索在线MP3,实在有点不方便.这里说一下怎么修改,主要还是利用原来 ...
- AngularJS的核心对象angular上的方法全面解析(AngularJS全局API)
总结一下AngularJS的核心对象angular上的方法,也帮助自己学习一下平时工作中没怎么用到的方法,看能不能提高开发效率.我当前使用的Angularjs版本是1.5.5也是目前最新的稳定版本,不 ...
- 使用Vue2+webpack+Es6快速开发一个移动端项目,封装属于自己的jsonpAPI和手势响应式组件
导语 最近看到不少使用vue制作的音乐播放器,挺好玩的,本来工作中也经常使用Vue,一起交流学习,好的话点个star哦 本项目特点如下 : 1. 原生js封装自己的跨域请求函数,支持promise调用 ...
- EF框架基础
ORM概述: ORM全称是"对象 - 关系映射" . ORM是将关系数据库中的数据用对象的形式表现出来,并通过面向对象的方式将这些对象组织起来,实现系统业务逻辑的过程. Entit ...