ETL工具 (二)sqoop 数据同步工具
Sqoop简介
将关系数据库(oracle、mysql、postgresql等)数据与hadoop数据进行转换的工具、
官网: http://sqoop.apache.org/
版本:(两个版本完全不兼容,sqoop1使用最多)
sqoop1:1.4.x
sqoop2:1.99.x

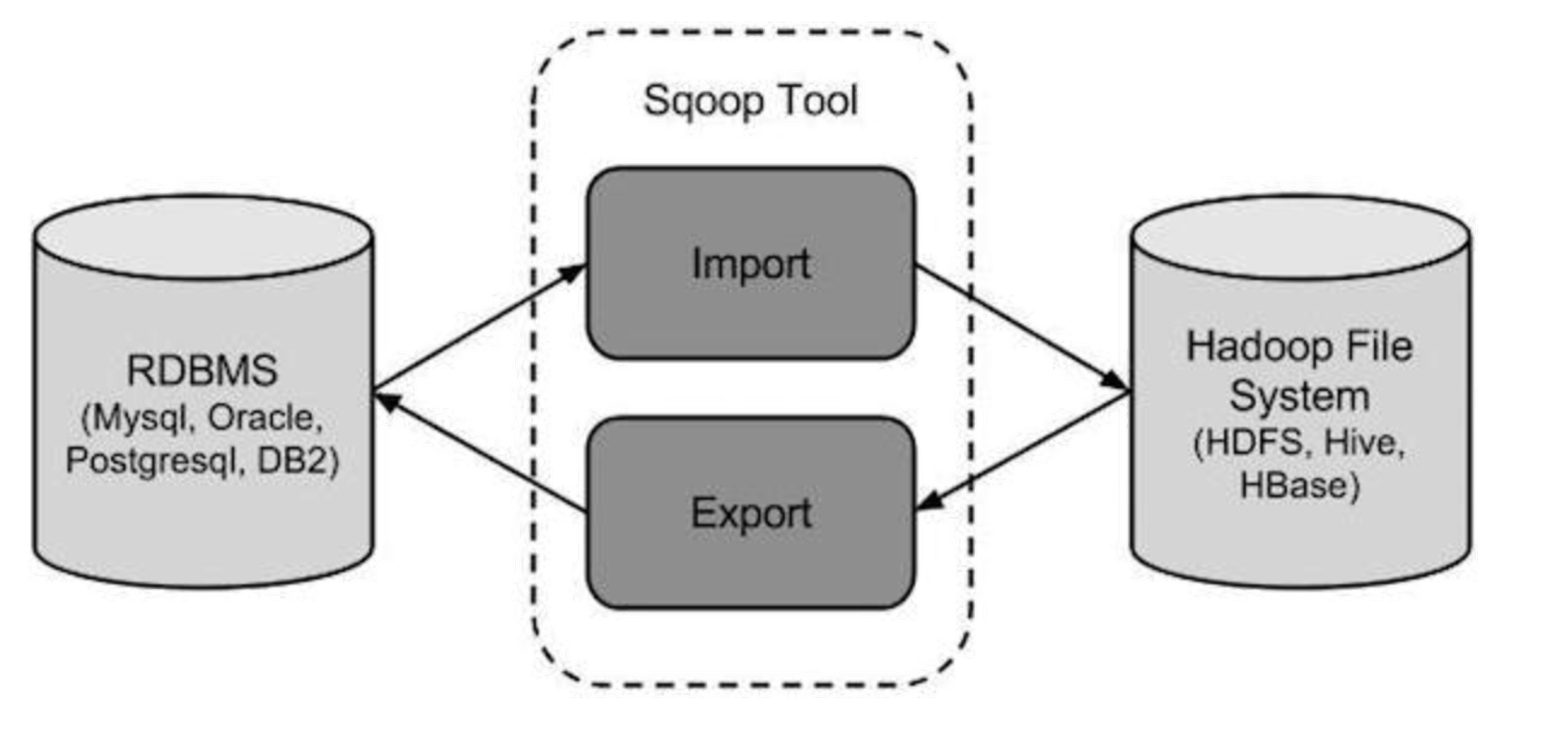
sqoop架构非常简单,是hadoop生态系统的架构最简单的框架。
sqoop1由client端直接接入hadoop,任务通过解析生成对应的maprecue执行
同类产品 DataX:阿里顶级数据交换工具
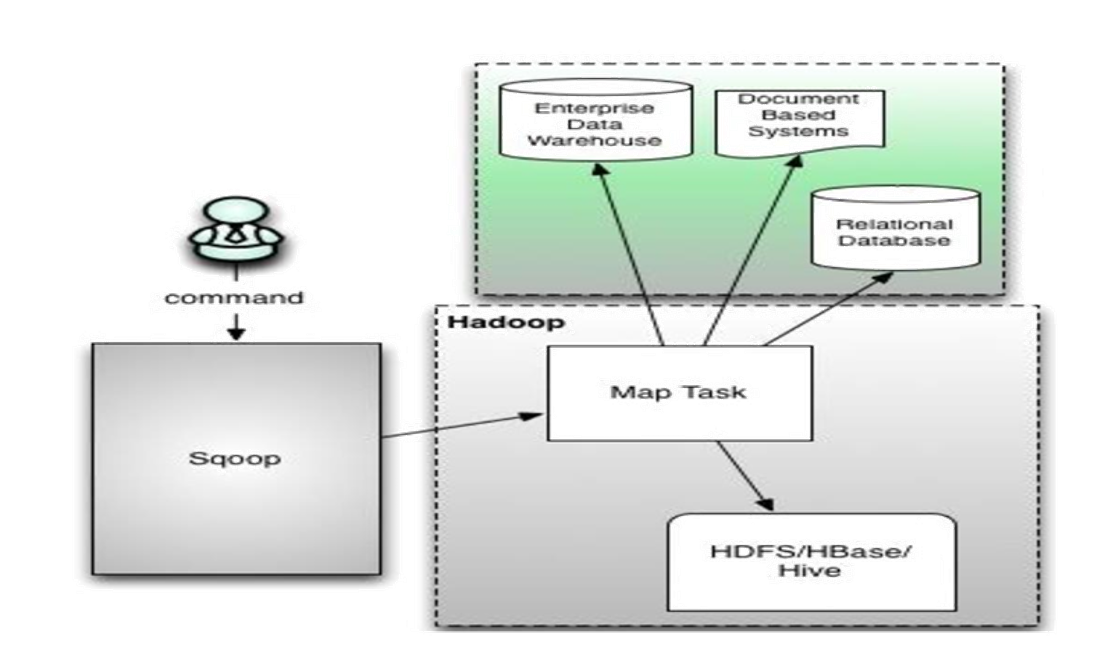
导入数据到hdfs
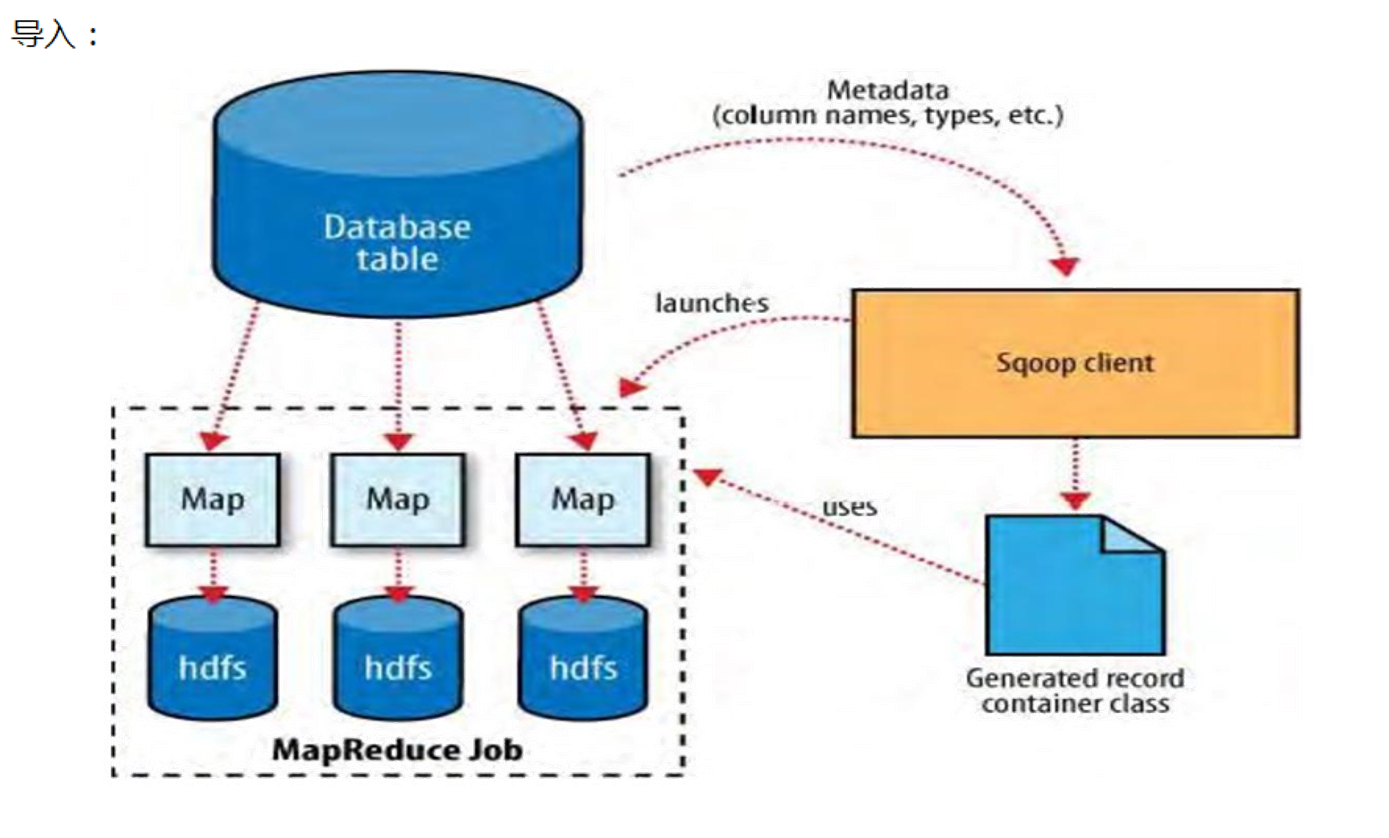
导出hdfs数据
安装步骤
1、解压
2、配置环境变量 export SQOOP_HOME=/XX/sqoop.xx source /etc/profile
3、添加数据库驱动包 cp mysql-connector-java-5.1.10.jar /sqoop-install-path/lib
4、重命名配置文件 mv sqoop-env-template.sh sqoop-env.sh
5、修改配置../bin/configure-sqoop 去掉未安装服务相关内容;例如(HBase、HCatalog、Accumulo): #if [ ! -d "${HBASE_HOME}" ]; then # echo "Error: $HBASE_HOME does not exist!" # echo 'Please set $HBASE_HOME to the root of your HBase installation.' # exit 1
6、测试 sqoop version sqoop list-databases -connect jdbc:mysql://node3:3306/ -username root -password 123456
详细步骤
SQOOP安装
1、上传并解压
tar -zxvf sqoop-1.4.6.bin__hadoop-2.0.4-alpha.tar.gz -C /usr/local/soft/
2、修改文件夹名字
mv sqoop-1.4.6.bin__hadoop-2.0.4-alpha/ sqoop-1.4.6
3、修改配置文件
# 切换到sqoop配置文件目录
cd /usr/local/soft/sqoop-1.4.6/conf
# 复制配置文件并重命名
cp sqoop-env-template.sh sqoop-env.sh
# vim sqoop-env.sh 编辑配置文件,并加入以下内容
export HADOOP_COMMON_HOME=/usr/local/soft/hadoop-2.7.6
export HADOOP_MAPRED_HOME=/usr/local/soft/hadoop-2.7.6/share/hadoop/mapreduce
export HBASE_HOME=/usr/local/soft/hbase-1.4.6
export HIVE_HOME=/usr/local/soft/hive-1.2.1
export ZOOCFGDIR=/usr/local/soft/zookeeper-3.4.6/conf
export ZOOKEEPER_HOME=/usr/local/soft/zookeeper-3.4.6
# 切换到bin目录
cd /usr/local/soft/sqoop-1.4.6/bin
# vim configure-sqoop 修改配置文件,注释掉没用的内容(就是为了去掉警告信息)

4、修改环境变量
vim /etc/profile
# 将sqoop的目录加入环境变量
5、添加MySQL连接驱动
# 从HIVE中复制MySQL连接驱动到$SQOOP_HOME/lib
cp /usr/local/soft/hive-1.2.1/lib/mysql-connector-java-5.1.49.jar /usr/local/soft/sqoop-1.4.6/lib/
6、测试
# 打印sqoop版本
sqoop version

# 测试MySQL连通性
sqoop list-databases -connect jdbc:mysql://master:3306/ -username root -password 123456
准备MySQL数据
登录MySQL数据库
mysql -u root -p123456;
创建student数据库
create database student;
切换数据库并导入数据
# mysql shell中执行
use student;
source /usr/local/soft/bigdata17/scrips/student.sql;
source /usr/local/soft/bigdata17/scrips/score.sql;
另外一种导入数据的方式
# linux shell中执行
mysql -u root -p123456 student</usr/local/soft/bigdata17/scrips/student.sql
mysql -u root -p123456 student</usr/local/soft/bigdata17/scrips/score.sql
使用Navicat运行SQL文件
也可以通过Navicat导入
导出MySQL数据库
mysqldump -u root -p123456 数据库名>任意一个文件名.sql
import
从传统的关系型数据库导入HDFS、HIVE、HBASE......
MySQLToHDFS
编写脚本,保存为MySQLToHDFS.conf
sqoop执行脚本有两种方式:第一种方式:直接在命令行窗口中直接输入脚本;第二种方式是将命令封装成一个脚本文件,然后使用另一个命令执行
第一种方式:
sqoop import \
--append \
--connect jdbc:mysql://master:3306/student \
--username root \
--password 123456 \
--table student \
--m 4 \
--split-by age \
--target-dir /shujia/bigdata17/student1/ \
--fields-terminated-by '\t'
第二种方式:
import
--append
--connect
jdbc:mysql://master:3306/student
--username
root
--password
123456
--table
student
--m
4
--split-by
age
--target-dir
/shujia/bigdata17/student21/
--fields-terminated-by
','
执行脚本
sqoop --options-file MySQLToHDFS.conf
注意事项:
1、--m 表示指定生成多少个Map任务,不是越多越好,因为MySQL Server的承载能力有限
2、当指定的Map任务数>1,那么需要结合--split-by参数,指定分割键,以确定每个map任务到底读取哪一部分数据,最好指定数值型的列,最好指定主键(或者分布均匀的列=>避免每个map任务处理的数据量差别过大)
3、如果指定的分割键数据分布不均,可能导致数据倾斜问题
4、分割的键最好指定数值型的,而且字段的类型为int、bigint这样的数值型
5、编写脚本的时候,注意:例如:--username参数,参数值不能和参数名同一行
--username root // 错误的
// 应该分成两行
--username
root
6、运行的时候会报错InterruptedException,hadoop2.7.6自带的问题,忽略即可
21/01/25 14:32:32 WARN hdfs.DFSClient: Caught exception
java.lang.InterruptedException
at java.lang.Object.wait(Native Method)
at java.lang.Thread.join(Thread.java:1252)
at java.lang.Thread.join(Thread.java:1326)
at org.apache.hadoop.hdfs.DFSOutputStream$DataStreamer.closeResponder(DFSOutputStream.java:716)
at org.apache.hadoop.hdfs.DFSOutputStream$DataStreamer.endBlock(DFSOutputStream.java:476)
at org.apache.hadoop.hdfs.DFSOutputStream$DataStreamer.run(DFSOutputStream.java:652)
7、实际上sqoop在读取mysql数据的时候,用的是JDBC的方式,所以当数据量大的时候,效率不是很高
8、sqoop底层通过MapReduce完成数据导入导出,只需要Map任务,不许需要Reduce任务 part-m-00000
9、每个Map任务会生成一个文件
MySQLToHive
先会将MySQL的数据导出来并在HDFS上找个目录临时存放,默认为:/user/用户名/表名
然后再将数据加载到Hive中,加载完成后,会将临时存放的目录删除
编写脚本,并保存为MySQLToHive.conf文件
import
--connect
jdbc:mysql://master:3306/student
--username
root
--password
123456
--table
score
--m
3
--split-by
student_id
--fields-terminated-by
'\t'
--hive-import
--hive-overwrite
--create-hive-table
--hive-database
sqooptest
--hive-table
mysqltoscore
--direct
执行脚本
sqoop --options-file MySQLToHive.conf
--direct
加上这个参数,可以在导出MySQL数据的时候,使用MySQL提供的导出工具mysqldump,加快导出速度,提高效率
需要将master上的/usr/bin/mysqldump分发至 node1、node2的/usr/bin目录下
scp /usr/bin/mysqldump node1:/usr/bin/
scp /usr/bin/mysqldump node2:/usr/bin/
--e参数的使用
sqoop在导入数据时,可以使用--e搭配sql来指定查询条件,并且还需在sql中添加$CONDITIONS,来实现并行运行mr的功能。
只要有--e+sql,就需要加$CONDITIONS,哪怕只有一个maptask。
sqoop通过继承hadoop的并行性来执行高效的数据传输。 为了帮助sqoop将查询拆分为多个可以并行传输的块,需要在查询的where子句中包含$conditions占位符。 sqoop将自动用生成的条件替换这个占位符,这些条件指定每个任务应该传输哪个数据片。
import
--connect
jdbc:mysql://master:3306/student
--username
root
--password
123456
--m
2
--split-by
student_id
--e
"select * from score where student_id=1500100001 and $CONDITIONS"
--target-dir
/testE
--fields-terminated-by
'\t'
--hive-import
--hive-overwrite
--create-hive-table
--hive-database
sqooptest
--hive-table
mysqltoscore3
--direct
MySQLToHBase
编写脚本,并保存为MySQLToHBase.conf
sqoop1.4.6 只支持 HBase1.0.1 之前的版本的自动创建 HBase 表的功能
import
--connect
jdbc:mysql://master:3306/student
--username
root
--password
123456
--table
student
--hbase-table
studentsq
--column-family
cf1
--hbase-row-key
id
--m
1
在HBase中创建student表
create 'studentsq','cf1'
执行脚本
sqoop --options-file MySQLToHBase.conf
export
HDFSToMySQL
编写脚本,并保存为HDFSToMySQL.conf
在往关系型数据库中导出的时候我们要先在关系型数据库中创建好库以及表,这些sqoop不会帮我们完成。
export
--connect
jdbc:mysql://master:3306/student?useUnicode=true&characterEncoding=UTF-8
--username
root
--password
123456
--table
student
--m
1
--columns
id,name,age,gender,clazz
--export-dir
/shujia/bigdata17/sqoopinput/
--fields-terminated-by
','
先清空MySQL student表中的数据,不然会造成主键冲突
执行脚本
sqoop --options-file HDFSToMySQL.conf
查看sqoop help
sqoop help
21/04/26 15:50:36 INFO sqoop.Sqoop: Running Sqoop version: 1.4.6
usage: sqoop COMMAND [ARGS]
Available commands:
codegen Generate code to interact with database records
create-hive-table Import a table definition into Hive
eval Evaluate a SQL statement and display the results
export Export an HDFS directory to a database table
help List available commands
import Import a table from a database to HDFS
import-all-tables Import tables from a database to HDFS
import-mainframe Import datasets from a mainframe server to HDFS
job Work with saved jobs
list-databases List available databases on a server
list-tables List available tables in a database
merge Merge results of incremental imports
metastore Run a standalone Sqoop metastore
version Display version information
See 'sqoop help COMMAND' for information on a specific command.
# 查看import的详细帮助
sqoop import --help
1、并行度不能太高,就是 -m
2、如果没有主键的时候,-m 不是1的时候就要指定分割字段,不然会报错,如果有主键的时候,-m 不是1 可以不去指定分割字段,默认是主键,不指定 -m 的时候,Sqoop会默认是分4个map任务。
Sqoop 在从HDFS中导出到关系型数据库时的一些问题
问题一:
在上传过程中遇到这种问题:
ERROR tool.ExportTool: Encountered IOException running export job: java.io.IOException: No columns to generate for ClassWriter
驱动版本的过低导致的,其实在尝试这个方法的时候我们可以先进行这样:加一行命令,--driver com.mysql.jdbc.Driver \ 然后问题解决!!!
如果添加命令之后还没有解决就把jar包换成高点版本的。
问题二:
依旧是导出的时候,会报错,但是我们很神奇的发现,也有部分数据导入了。这也就是下一个问题。
Caused by: java.lang.NumberFormatException: For input string: "null"
解决方式:因为数据有存在null值得导致的
在命令中加入一行(方式一中的修改方式,方式二也就是转换一下格式):--input-null-string '\\N' \
--input-null-string
'\\N'
问题三:**
java.lang.RuntimeException: Can't parse input data: '1998/5/11'
出现像这样的问题,大多是因为HDFS上的数据与关系型数据库创建表的字段类型不匹配导致的。仔细对比修改后,就不会有这个报错啦!!
增量同步数据
我们之前导入的都是全量导入,一次性全部导入,但是实际开发并不是这样,例如web端进行用户注册,mysql就增加了一条数据,但是HDFS中的数据并没有进行更新,但是又再全部导入一次又完全没有必要。
所以,sqoop提供了增量导入的方法。
1、数据准备:
2、将其先用全量导入到HDFS(hive)中去
import
--connect
jdbc:mysql://master:3306/student
--username
root
--password
123456
--table
student
--hive-import
--hive-overwrite
--create-hive-table
--hive-database
testsqoop
--hive-table
from_mysql_student
--fields-terminated-by
'\t'
3、先在mysql中添加一条数据,在使用命令进行追加
4、根据时间进行大量追加(不去重)
#前面的案例中,hive本身的数据也是存储在HDFS上的,所以我今后要做增量操作的时候,需要指定HDFS上的路径
import
--connect
jdbc:mysql://master:3306/student
--username
root
--password
123456
--table
student
--target-dir
/user/hive/warehouse/sqooptest.db/from_mysql_student
--fields-terminated-by
'\t'
--incremental
append
--check-column
id
--last-value
3
结果:但是我们发现有两个重复的字段

5、往往开发中需要进行去重操作:sqoop提供了一个方法进行去重,内部是先开一个map任务将数据导入进来,然后再开一个map任务根据指定的字段进行合并去重
结果:

之前有重复的也进行合并去重操作,最后生成一个结果。
总结:
–check-column
用来指定一些列,这些列在增量导入时用来检查这些数据是否作为增量数据进行导入,和关系型数据库中的自增字段及时间戳类似.
注意:这些被指定的列的类型不能使任意字符类型,如char、varchar等类型都是不可以的,同时–check-column可以去指定多个列
–incremental
用来指定增量导入的模式,两种模式分别为Append和Lastmodified
–last-value
指定上一次导入中检查列指定字段最大值
总结
RDBMS-->HDFS import
HDFS--->RDBMS export
Mysql--->HDFS(hive)
要知道你要数据的来源和数据的目的地
mysql:
--connect
jdbc:mysql://master:3306/student
--username
root
--password
123456
--table
student
hdfs:
--target-dir
/user/hive/warehouse/sqooptest.db/from_mysql_student
--fields-terminated-by
'\t'
hive:
1)
--hive-import
--hive-overwrite
--create-hive-table (如果表不存在,自动创建,如果存在,报错,就不需要这个参数)
--hive-database
testsqoop
--hive-table
from_mysql_student
--fields-terminated-by
'\t'
2)
--target-dir
/user/hive/warehouse/sqooptest.db/from_mysql_student
--fields-terminated-by
'\t'
# 增量需要添加的参数=================================================
--incremental
append
--check-column
id
--last-value
3
(或者是)------------------------------------------------------------
--fields-terminated-by
'\t'
--check-column (hive的列名)
last_mod
--incremental
lastmodified
--last-value
"2022-06-18 16:40:09"
--m
1
========================================================================
# 如果需要去重,请先搞清楚根据什么去重,否则结果可能不是你想要的
--merge-key
name (这里是根据姓名去重,你可以改成自己的去重列名)
hbase:(因为我们的hbase版本是1.4.6,而sqoop1.4.6不支持hbase1.0.1以后的自动创建表,所以我们在做同步到hbase的时候,需要手动先将表创建好)
--hbase-table
studentsq
--column-family
cf1
--hbase-row-key
id (mysql中的列名)
--m
1
HDFS--->mysql
hdfs:
--columns
id,name,age,gender,clazz
--export-dir
/shujia/bigdata17/sqoopinput/
--fields-terminated-by
','
# 如果数据分割出来的字段值有空值,需要添加以下参数(面试可能会面到)
--null-string
'\\N'
--null-non-string
'\\N'
ETL工具 (二)sqoop 数据同步工具的更多相关文章
- 数据同步工具Sqoop和DataX
在日常大数据生产环境中,经常会有集群数据集和关系型数据库互相转换的需求,在需求选择的初期解决问题的方法----数据同步工具就应运而生了.此次我们选择两款生产环境常用的数据同步工具进行讨论 Sqoop ...
- Linux实战教学笔记21:Rsync数据同步工具
第二十一节 Rsync数据同步工具 标签(空格分隔): Linux实战教学笔记-陈思齐 ---本教学笔记是本人学习和工作生涯中的摘记整理而成,此为初稿(尚有诸多不完善之处),为原创作品,允许转载,转载 ...
- Spark记录-阿里巴巴开源工具DataX数据同步工具使用
1.官网下载 下载地址:https://github.com/alibaba/DataX DataX 是阿里巴巴集团内被广泛使用的离线数据同步工具/平台,实现包括 MySQL.Oracle.SqlSe ...
- rsync数据同步工具的配置
rsync数据同步工具的配置 1. rsync介绍 1.1.什么是rsync rsync是一款开源的快速的,多功能的,可实现全量及增量的本地或远程数据同步备份的优秀工具.Rsync软件适用于 unix ...
- 【基础】:Rsync数据同步工具
第二十一节 Rsync数据同步工具 1.1 Rsync介绍 1.1.1 什么是Rsync? 1.1.2 Rsync简介 1.3 Rsync的特性 1.1.4 Rsync的企业工作场景说明 1.2 Rs ...
- Rsync数据同步工具
Rsync数据同步工具 什么是Rsync? Rsync是一款开源的.快速的.多功能的,可以实现全量及增量的本地或原程数据同步备份 ...
- Linux系统备份还原工具4(rsync/远程数据同步工具)
rsync即是能备份系统也是数据同步的工具. 在Jenkins上可以使用rsync结合SSH的免密登录做数据同步和分发.这样一来可以达到部署全命令化,不需要依赖任何插件去实现. 命令参考:http:/ ...
- rsync---远程数据同步工具
rsync命令是一个远程数据同步工具,可通过LAN/WAN快速同步多台主机间的文件.rsync使用所谓的“rsync算法”来使本地和远程两个主机之间的文件达到同步,这个算法只传送两个文件的不同部分,而 ...
- kafka2x-Elasticsearch 数据同步工具demo
Bboss is a good elasticsearch Java rest client. It operates and accesses elasticsearch in a way simi ...
随机推荐
- windows下载安装JDK8
一 .下载链接 http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html 根据自己的电脑安 ...
- 一篇文章说清 webpack、vite、vue-cli、create-vue 的区别
webpack.vite.vue-cli.create-vue 这些都是什么?看着有点晕,不要怕,我们一起来分辨一下. 先看这个表格: 脚手架 vue-cli create-vue 构建项目 vite ...
- 斯坦福NLP课程 | 第11讲 - NLP中的卷积神经网络
作者:韩信子@ShowMeAI,路遥@ShowMeAI,奇异果@ShowMeAI 教程地址:http://www.showmeai.tech/tutorials/36 本文地址:http://www. ...
- DEDECMS登录后台,无法连接数据库的原因
在CMS的网页模块中,当迁移网站出现后台无法登录的时候 最可能的情况有下列几种: 1. 数据库服务器宕机.如果是云上的数据库时,需要联系客服进行解决.是有自己的搭建的数据库,需要查看服务是否正常启动 ...
- 九种常见UML图(分类+图解)
九种常见UML图 1.类图 概述 类图(Class Diagram)是面向对象系统建模中最常用和最重要的图,是定义其它图的基础. 类图主要是用来显示系统中的类.接口以及它们之间的静态结构和关系的一种静 ...
- 117_PowerQuery使用ODBC访问带密码的Access
博客:www.jiaopengzi.com 焦棚子的文章目录 请点击下载附件 一. 有朋友在问pq访问带密码的access的时候会报错,导致无法访问(如下图): 1.选择更多 图1 2.选择Acces ...
- 【js奇妙说】如何跟非计算机从业者解释,为什么浮点数计算0.1+0.2不等于0.3?
壹 ❀ 引 0.1+0.2不等于0.3,即便你不知道原理,但也应该听闻过这个问题,包括博主本人也曾在面试中被问到过此问题.很遗憾,当时只知道一句精度丢失,但是什么原因造成的精度丢失却不太清楚.而我在查 ...
- Hadoop安装学习(第三天)
学习任务: 1.解压jdk和hadoop包 2.安装jdk 3.修改hadoop配置文件 4.hadoop格式化 5.hadoop启动 出现的问题:hadoop可以正常启动,但是端口9000丢失,导致 ...
- 04C++核心编程
Day01 笔记 1 C++概述 1.1 C++两大编程思想 1.1.1 面向对象 1.1.2 泛型编程 1.2 移植性和标准 1.2.1 ANSI 在1998制定出C++第一套标准 2 c++初识 ...
- 2022Gartner容器预测:2025年85%的企业将使用容器管理服务
近日,国际知名权威分析机构Gartner发布了最新<全球容器管理预测>.预测中指出:在加速的数字化转型驱动下,到2025年全球容器管理领域市场规模将突破14亿美元,预计年复合增长率将达到2 ...