OptaPlanner 发展方向与问题
最近一段时间,因为忙于【易排(EasyPlan)规划平台】的设计与开发工作,平台的一些功能设计,需要对OptaPlanner的各种特性作更深入的研究与应用。慢慢发现,OptaPlanner进入8.X版本之后,变化还是挺大的。对于我个人的项目、平台及咨询工作,这些变化中,大部分还是帮助很大的,但也发现一些不太合理的地方。这两天终于完成了平台的“规划评分分析功能”,就挤点时间出来,记录一下OptaPlanner 8.X的这些变化吧。
以下是我应用OptaPlanner过程中归纳的一些关于该软件的发展方向,及此过程中遇到的一些问题。
实时规划接口优化
实时规划是OptaPlanner的一重大特有特性,目前在其它求解器还没发现类似的功能。就是考虑到当求解一个问题的时间过长时(例如数据量大、约束复杂)有可能在求解的过程中,数据已经发生变化,此时,实时规划就可以在未完成整份数据的完全求解,即可通过实时规划的API对数据进行更新,OptaPlanner会在已完成了部分求解的基础上,将变更纳入考虑,而无需停止整个规划过程,重新跑一次规划。实时规划的另一个经典应用场景,就是在VRP(车辆路径规划)过程中的实进车辆调度功能,即车辆按原计划的路线行驶,当遇到路况不佳时,司机可以将路况反馈回服务端,以OptaPlanner为作引擎的服务端会马上作出反馈,重新规划一条新的路线给司机,并对后续的访问节点进行适当调配。其实这一过程同样适用于车间的调度工作,我们的平台将会添加这一功能 - 车间实时工作调度模块。
那么实时规划功能,在OptaPlanner的8.X版本中有哪些改善呢?其实,我们在8.X以前一直都已经有实时规划功能,但那些版本我们需要实现实时规划,OptaPlanner提供的接口,还是相对比较零碎且繁复的。例如,当我需要增加一个数据时,需要先判断添加这个数据是一个Planning Entity,还是一个普通的Problem Fact,不同的情况需要使用不同的API。添加与删除两种操作也使用不同的API区分。因此,要实现实时规划,需要考虑:你是需要从规划空间中增加对象,还是删除对象;你增加/删除的是什么类型的对象;从而采用不同API,编写不同的处理逻辑。
而到了8.X之后,将上述情况都整合成一个接口 - ProblemChange. 即无论你的操作是增加还是删除对象,无论你操作的对象无论是Planning Entity还是Problem Fact;对于整个规划问题来说,都是对规划问题的修改,因此,这些操作都抽象成一个接口 - ProblemChange。只要我们新建一个类实现ProblemChanged这个接口即可。当然,具体在这个接口的实现类中,需要如何实现新增、删除逻辑,还是需要我们自己去编写的,因为这属于业务逻辑的范畴;但也仅仅涉及这些对象被增删后,规划空间中剩余对象的一些业务性要求而已。而评分之类由引擎自行处理的逻辑则不需我们来处理。例如,在VRP场景中,如果有一个节点临时取消了,那么我们可以通过实时规划把这个节点从一条车辆行驶路线中删除。但是,因为一条路线是由各个节点首尾相接构成的,因此,如果你删掉这条路线上的一个节点,这条路线就被截断了。为了保持路线的完整性,你需要把被删除节点的前后两个节点连接起来,从而保证路线的完整(这也是OptaPlanner中Chain的一个原则性要求)。这就是删除一个节点需要处理的唯一一个需要人工处理的业务逻辑。当然各种场景需要处理的逻辑不同,例如添加一个节点,则不需要任何处理,因为一个新的对象出现,对OptaPlanner来说,相当于有一个对象还未被规划处理而已,它会自动把这个新的对象纳入考虑。
上述描述的实现业务过程,也都在ProblemChange这个接口内实现即可。而且整个接口需要实现的方法也只有doChangeg一个方法,构造好一个ProblemChange对象,直接将这个对象传送给SovlerManager对象的addProblemChange方法即可。相对于之前版本的接口简单明了。
评分方式,以ConstraintStream取代Drools
8.X之后,由该团队成员 Lukáš Petrovický 主导的ConstraintStream功能得到长足发展。事实上ConstraintStream早在7.X版本就已出现,但当时提供的API还是比较少,未能覆盖最常用的Drools表达的所有功能。到了8.X之后,相长的时间与版本里,都在完善ConstraintStream功能。ConstraintStream我们通常称之为“约束流”,熟悉Java8以上版stream特性的小伙伴应该知道,通过stream功能,可以实现类似SQL脚本一样的复杂查询。规划约束的本质也是对数据集的过滤、条件判断和评分设定(这就是所谓运筹优化算法的核心之一)。
目前OptaPlanner关于分数计算(也即评分)有以下方法:
- Easy Java score calculation - 相对较容易实现但因为没有增量评分,性能稍差
- Drools score calculation- 基于Drools引擎,直接使用Drools脚本编写约束,性能一般表达方法丰富,但需要学习Drools,在8.X版本已被标识为“弃用”,即不再更新,预计在9.X将会取消该种计分方法。
- Constraint streams score calculation- 新的约束流评分,实现起来较精简,但需要熟悉掌握各个函数式编程API,后台还是基于Drools引擎)
- Incremental Java score calculation- 性能最强、灵活性最高,但官方不推荐,原因是实现难度较大)
Drools评分是目前最为成熟易用的一种评分方法,规划模型里的第一个约束,对应于Drools脚本中的每一个规则(脚本里称为Rule),一个规则体由LHS和RHS构成,其中LHS根据约束的要求实现规则逻辑,当LHS的所有条件都满足了,就会执行RHS中的内容,因此,RHS主要是实现评分功能,即具体是要求引擎对哪个类型、哪个层次作出多少分值的惩罚或奖励。这种方法具有非常丰富的逻辑表达方式,丰富的Drools脚本表达能力也可以充分利用,当然,要掌握Drools脚本也需要有一定的学习过程。
根据OptaPlanner官方发布的计划,Drools评分方式将会在下一个主版本(通常认为是9.X版)将会取消相关接口,届时将无法使用Drools脚本实现评分约束。取而代之的是ConstraintStream评分方式。而在我决定开发易排(EasyPlan)通用规划平台的时候,考虑到以后的兼容性及性能要求,我目前使用的是Incremental Java Score calculation的方式实现相关约束。这种方法虽然实现起来难度最高,但其性能与灵活性也是最好的。考验的是开发人员对约束的实现能力,同时需要实现方案的分数分析,若使用Drools或ConstraintStream这两个主分方式,完成规划后,一个方案的分布也已经自动生成的,而使用Incremental Java Score calculation则需要实现额外的接口,才能得到主分的分布信息。但我认为若作为一个定制项目,这些额外的付出需要根据实际情况考虑,而我们实现的是一个性能、灵活性要求都更高的产品,因此,花更多的时间精力来实现Incremental Java Score calculation是完全有必要的。
关于ConstraintStream的底层实现基础,在一篇OptaPlanner官方发布,建议人们将Drools约束移植到ConstraintStream方式的文章(见以下链接)里提到,ConstraintStream其底层也是基于Drools引擎的,只是提供一套对Java开发人员更为熟悉的函数式编程的ConstraintStream API,以方便开发人员编写约束。见以下截图:

截图出处: OptaPlanner deprecates score DRL
部分未成熟的功能
SolverManager的Problem ID(即规划数据集的ID)问题仍有Bug
在我们的【易排(EasyPlan)通用智能规划平台】的开发过程中, 我们使用了SolverManager来实现多个数据集并行规划,平台的API调用后可即时返回。其中就用到SolverManager的Problem ID来识别规划空间中不同数据集,从而查询各个数据集的状态和规划结果。但在开发过程中,我们发现,当一个数据集规划运算异常时,我们重新把这个数据集再次提交到引擎,且使用的数据集ID(Problem ID)与前一个数据集ID一样,会出现一个异常,提示该ID的数据集已经处理。很明显这是一个错误,因此我已在他们社区的JIRA里创建了一个issue。希望能早日修复此问题。
也正因为这个问题,我在我们的平台关于规划ID的机制作出相应的变更,以避开OptaPlanner这个问题。若看过平台最早一个版本的说明文件的小伙伴应该有印象,每个数据集的规划ID是由我们在生成数据集(即那个json)时,自己去维护其中的id字段的,这也能很好地让调用方较容易地控制各个数据集的ID,但若过程中出现这个异常,当我们重新提交一个数据集给平台重新跑规划运算时,若使用了与这前出现异常的数据集一样的ID,就会返回一个异常,提示:该问题(id为1)已在处理。因此,那个版本我们提供了一个接口,用于查询一个ID是否已经存在规划数据集,还有一个接口用于生一个新的ID。但这种设计其实相对大家的前端调用程序的设计是比较繁复的,因此,但我们必须在OptaPlanner官方修复该问题前,避免该问题出现,同时也提高调用端的易用程度。因此,我们将接口修改为,提交数据集到平台做规划运算时,数据集的ID并不作准,而是平台自己根据当前的规划空间情况,生成一个新的ID,以该ID为准,用于后续操作使用。
例如:一个数据集在客户端(例如你们自己的MES系统)生成时,其ID是1,但通过接口提交到平台时,平台可能返回的是2(调用反馈json中的PID字段值),那么,此次规划的ID是2,后续需要查询状态、获取结果,以及以后需要实时规划时,更新一个规划数据集,使用的ID都需要使用2,而不是使用你们自己生成的1. 希望官方能早日修复些问题。
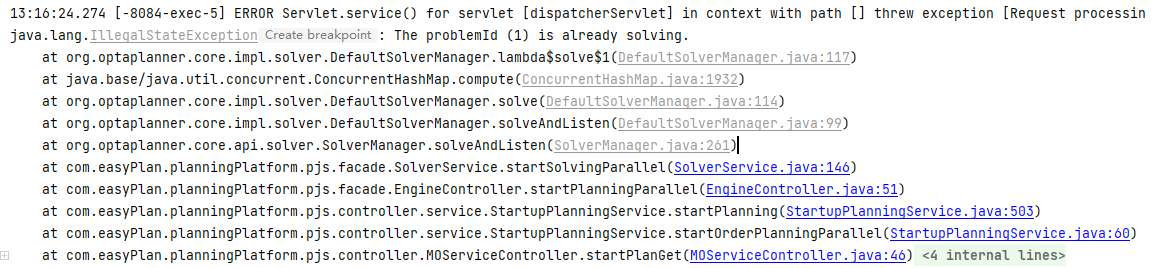
前一个数据集出现异常时,后续再使用相同的ID,就会出现这样的异常
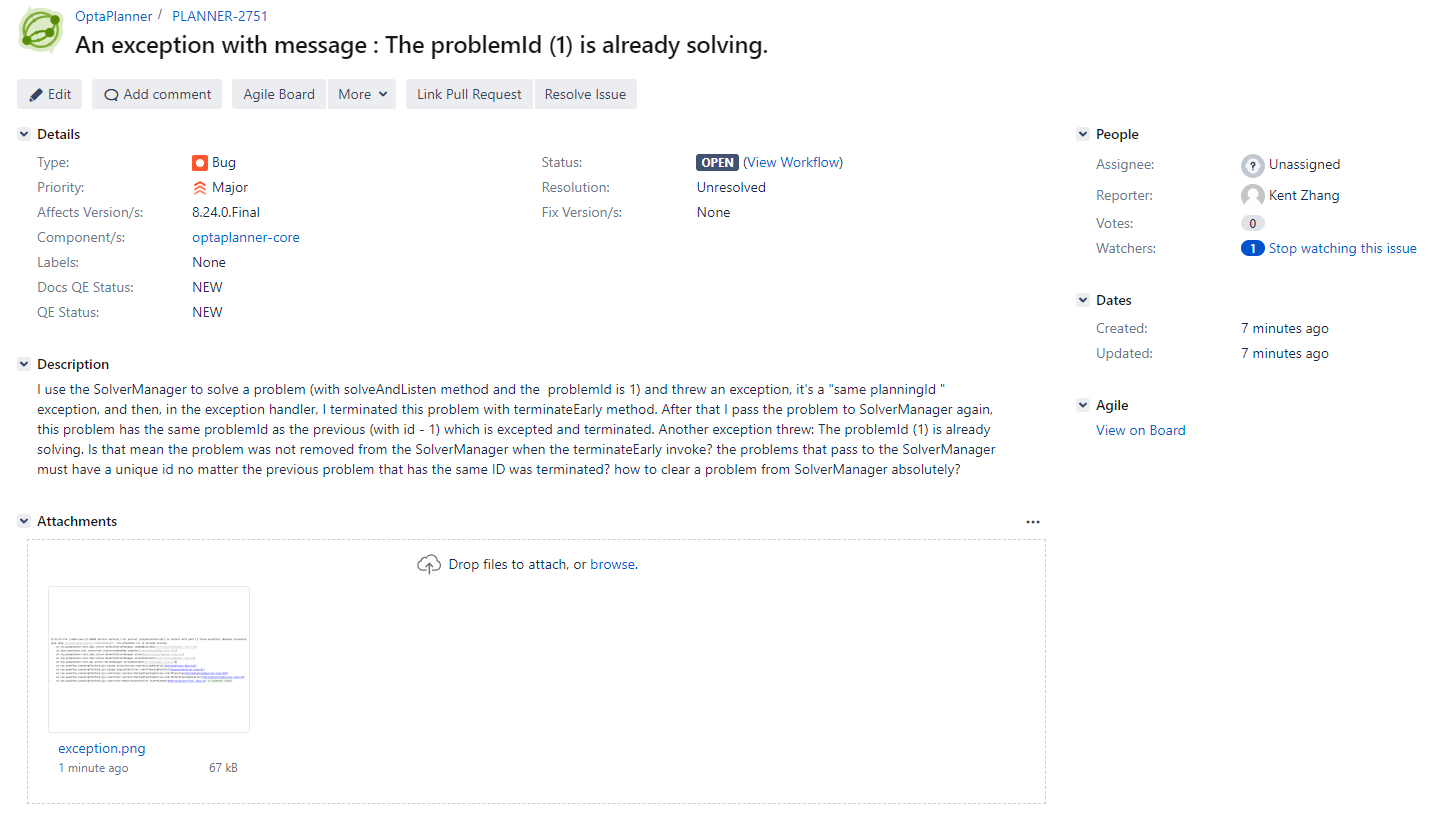
Geoffrey De Smet建议本人创建的issue
新的链状态设计仍有部分特性未实现
另外一个问题是,在8.x的其中一个版本(具体哪个版本没细查了),我们之前常用的时间链(Chained Through Time)模式,提供了一种新的方式来实现,并引入了 @IndexShadowVariable 和 @PlanningListVariable 两个新的标注, 其目标是简化时间链模式,令链实现起来更直观。使用过时间链模型的小伙伴应该还记得,该模式需要定义通过继承父类或实现接口的方式,来定义一条链上的锚和节点的关系,实现起来比较绕,可只要我们一旦掌握了要领,实现起来还是比较灵活的。 OptaPlanner为了简单此模式,引入了列表规划变理(即一个规划变更可以是一个列表)。但事实上这个功能尚未完全成熟,还是有一特列情况无法实现的,而在官方的示例中,我们可以看到,一些功能未能实现而需要做些取舍。
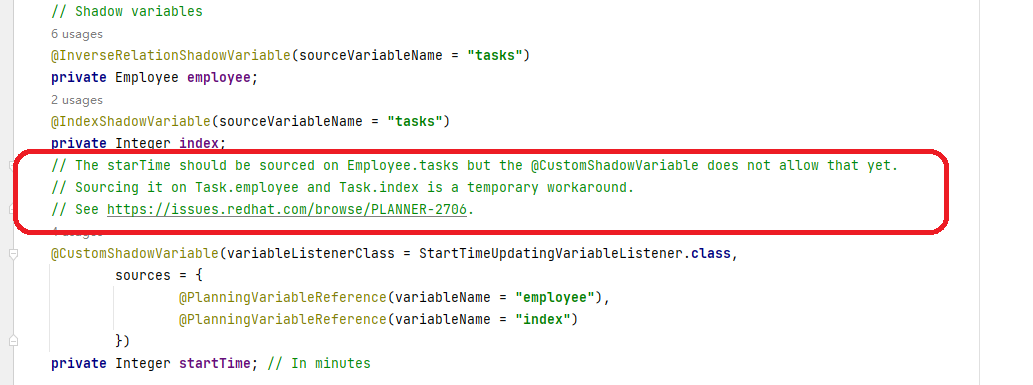
综上,大家在使用最新版本OptaPlanner的时候,有些功能还需要根据具体情况使用相应的方法,有一些新加上去的功能,看上去实现起来会更简洁,但其实它不一定成熟的。需要看情况使用。例如,因为上述新的链状功能的实现还没成熟,TaskAssigning示例的Consume功能在新的版本中被屏蔽,还没办法演示员工对任务完成情况的案例。如下图。

以上是本人对于OptaPlanner新版本总结出来的一些问题,分享给大家,希望大家在使用时能尽可能避坑。
同时也邀请大家使用我们的【易排(EasyPlan)通用智能规划平台】,它基于OptaPlanner对APS的一些常用规划逻辑进行封装,大家只需要管理、维护好自己系统(使用MES、MOM、ERP中的计划模块)中的工单数据,即可快速地实现一个APS模块。后续我们还会添加【VRP - 车辆路径规划】和【在线调度】模块,敬请期待。可以通过以下链接查看更多该平台的使用方法。
与平台相关疑问,可以添加本人微信(13631823503)探讨,或关注我们的公众号【让APS成为可能】及时接收相关消息。
OptaPlanner 发展方向与问题的更多相关文章
- [.net 面向对象程序设计深入](4)MVC 6 —— 谈谈MVC的版本变迁及新版本6.0发展方向
[.net 面向对象程序设计深入](4)MVC 6 ——谈谈MVC的版本变迁及新版本6.0发展方向 1.关于MVC 在本篇中不再详细介绍MVC的基础概念,这些东西百度要比我写的全面多了,MVC从1.0 ...
- 移动开发发展方向-----Hybird混合开发3大方案
移动开发发展方向-----Hybird混合开发3大方案
- 一段时间没上来了,看到有很多网友对OWA感兴趣,因为所在公司发展方向的原因,没有太多时间继续深入研究OWA,敬请见谅
一段时间没上来了,看到有很多网友对OWA感兴趣,因为所在公司发展方向的原因,没有太多时间继续深入研究OWA,敬请见谅
- memcached学习(3)memcached的删除机制和发展方向
memcached是缓存,所以数据不会永久保存在服务器上,这是向系统中引入memcached的前提. 本次介绍memcached的数据删除机制,以及memcached的最新发展方向--二进制协议(Bi ...
- memcached全面剖析–3. memcached的删除机制和发展方向
memcached在数据删除方面有效利用资源 数据不会真正从memcached中消失 上次介绍过, memcached不会释放已分配的内存.记录超时后,客户端就无法再看见该记录(invisible,透 ...
- spark未来的发展方向
spark是採用scala语言开发的基于内存的计算框架,作者Matei Zaharia,在未来的发展方向: 1.spark streaming:提高spark的流处理能力,使得spark更适于通过一套 ...
- 笑谈ArcToolbox (1) ArcToolbox 的发展方向
笑谈ArcToolbox (1) ArcToolbox 的发展方向 by 李远祥 ArcGIS工具箱ArcToolbox具有非常多的工具,相信用过的人都非常惊叹,其功能完备并且强大,种类繁多,总能找到 ...
- seo从业者发展方向
对于很多朋友来说,seo就是一项比较简单的技能,内容+外链,就可以基本囊括seo的基本内容了.可能很多朋友对此不屑一顾,会说seo可是包含万象, 你需要懂网页设计.标签设计,分词优化.企业建站等等方面 ...
- 【转】IT行业岗位以及发展方向
以下转自https://blog.csdn.net/qq_23994787/article/details/79847270 职业生涯规划的意义 1.以既有的成就为基础,确立人生的方向,提供奋斗的策略 ...
随机推荐
- 【HashMap】浅析HashMap的构造方法及put方法(JDK1.7)
目录 引言 代码讲解 属性 HashMap的空参构造方法 HashMap的put方法 put inflateTable initHashSeedAsNeeded putForNullKey hash ...
- 《你不知道的JS》上
- HamsterBear Linux Low Res ADC按键驱动的适配 + LVGL button移植
HamsterBear lradc按键驱动的适配 平台 - F1C200s Linux版本 - 5.17.2 ADC按键 - 4 KEY tablet 驱动程序位于主线内核: drivers/inpu ...
- 使用CSS实现《声生不息》节目Logo
声明:本文涉及图文和模型素材仅用于个人学习.研究和欣赏,请勿二次修改.非法传播.转载.出版.商用.及进行其他获利行为. 背景 <声生不息> 是芒果TV.香港电视广播有限公司和湖南卫视联合推 ...
- spring boot 默认日志替换为 log4j
移除默认日志 <dependency> <groupId>org.springframework.boot</groupId> <artifactId> ...
- ElasticSearch基础学习(SpringBoot集成ES)
一.概述 什么是ElasticSearch? ElasticSearch,简称为ES, ES是一个开源的高扩展的分布式全文搜索引擎. 它可以近乎实时的存储.检索数据:本身扩展性很好,可以扩展到上百台服 ...
- 通过Swagger接口导出模板文件时报错:URL.createObjectURL: Argument 1 is not valid for any of the 1-argument overloads.
问题描述:通过Swagger接口导出Excel模板文件时,报错:URL.createObjectURL: Argument 1 is not valid for any of the 1-argume ...
- 渗透:wesside-ng
WEP自动破解工具wesside-ng wesside-ng是aircrack-ng套件提供的一个概念验证工具.该工具可以自动扫描无线网络,发现WEP加密的AP.然后,尝试关联该AP.关联成功后,它会 ...
- mac安装java环境
1.java安装包获取: 链接:https://www.oracle.com/java/technologies/javase/javase-jdk8-downloads.html 2.验证安装是否成 ...
- vs2022+resharper C++ = 拥有一个不输clion的代码体验
这篇文章详细讲一下resharper C++在vs2022中的配置,让他拥有跟clion一样好用的代码补全功能. 为什么clion写代码体验很好好用为啥还要用vs呢,因为网上很多教程都是基于visua ...