HDFS文件读写过程
参考自《Hadoop权威指南》 [http://www.cnblogs.com/swanspouse/p/5137308.html]
HDFS读文件过程:
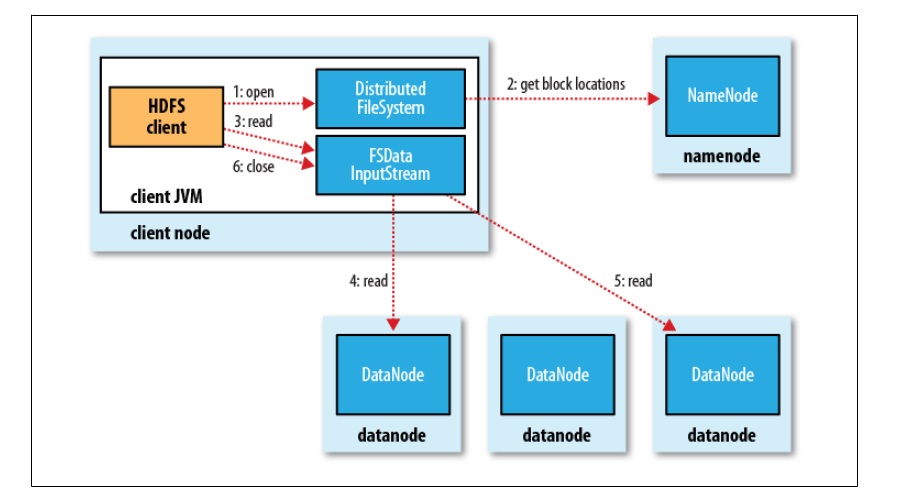
- 客户端通过调用FileSystem对象的open()来读取希望打开的文件。对于HDFS来说,这个对象是分布式文件系统的一个实例。
- DistributedFileSystem通过RPC来调用namenode,以确定文件的开头部分的块位置。对于每一块,namenode返回具有该块副本的datanode地址。此外,这些datanode根据他们与client的距离来排序(根据网络集群的拓扑)。如果该client本身就是一个datanode,便从本地datanode中读取。DistributedFileSystem 返回一个FSDataInputStream对象给client读取数据,FSDataInputStream转而包装了一个DFSInputStream对象。
- 接着client对这个输入流调用read()。存储着文件开头部分块的数据节点地址的DFSInputStream随即与这些块最近的datanode相连接。
- 通过在数据流中反复调用read(),数据会从datanode返回client。
- 到达块的末端时,DFSInputStream会关闭与datanode间的联系,然后为下一个块找到最佳的datanode。client端只需要读取一个连续的流,这些对于client来说都是透明的。
- 在读取的时候,如果client与datanode通信时遇到一个错误,那么它就会去尝试对这个块来说下一个最近的块。它也会记住那个故障节点的datanode,以保证不会再对之后的块进行徒劳无益的尝试。client也会确认datanode发来的数据的校验和。如果发现一个损坏的块,它就会在client试图从别的datanode中读取一个块的副本之前报告给namenode。
- 这个设计的一个重点是,client直接联系datanode去检索数据,并被namenode指引到块中最好的datanode。因为数据流在此集群中是在所有datanode分散进行的。所以这种设计能使HDFS可扩展到最大的并发client数量。同时,namenode只不过提供块的位置请求(存储在内存中,十分高效),不是提供数据。否则如果客户端数量增长,namenode就会快速成为一个“瓶颈”。
HDFS写文件过程

- 客户端通过在DistributedFileSystem中调用create()来创建文件。
- DistributedFileSystem 使用RPC去调用namenode,在文件系统的命名空间创一个新的文件,没有块与之相联系。namenode执行各种不同的检查以确保这个文件不会已经存在,并且在client有可以创建文件的适当的许可。如果检查通过,namenode就会生成一个新的文件记录;否则,文件创建失败并向client抛出一个IOException异常。分布式文件系统返回一个文件系统数据输出流,让client开始写入数据。就像读取事件一样,文件系统数据输出流控制一个DFSOutputStream,负责处理datanode和namenode之间的通信。
- 在client写入数据时,DFSOutputStream将它分成一个个的包,写入内部队列,称为数据队列。数据流处理数据队列,数据流的责任是根据适合的datanode的列表要求namenode分配适合的新块来存储数据副本。这一组datanode列表形成一个管线————假设副本数是3,所以有3个节点在管线中。
- 数据流将包分流给管线中第一个的datanode,这个节点会存储包并且发送给管线中的第二个datanode。同样地,第二个datanode存储包并且传给管线中的第三个数据节点。
- DFSOutputStream也有一个内部的数据包队列来等待datanode收到确认,称为确认队列。一个包只有在被管线中所有的节点确认后才会被移除出确认队列。如果在有数据写入期间,datanode发生故障, 则会执行下面的操作,当然这对写入数据的client而言是透明的。首先管线被关闭,确认队列中的任何包都会被添加回数据队列的前面,以确保故障节点下游的datanode不会漏掉任意一个包。为存储在另一正常datanode的当前数据块制定一个新的标识,并将该标识传给namenode,以便故障节点datanode在恢复后可以删除存储的部分数据块。从管线中删除故障数据节点并且把余下的数据块写入管线中的两个正常的datanode。namenode注意到块复本量不足时,会在另一个节点上创建一个新的复本。后续的数据块继续正常接收处理。只要dfs.replication.min的副本(默认是1)被写入,写操作就是成功的,并且这个块会在集群中被异步复制,直到其满足目标副本数(dfs.replication 默认值为3)。
- client完成数据的写入后,就会在流中调用close()。
- 在向namenode节点发送完消息之前,此方法会将余下的所有包放入datanode管线并等待确认。namenode节点已经知道文件由哪些块组成(通过Data streamer 询问块分配),所以它只需在返回成功前等待块进行最小量的复制。
- 复本的布局:需要对可靠性、写入带宽和读取带宽进行权衡。Hadoop的默认布局策略是在运行客户端的节点上放第1个复本(如果客户端运行在集群之外,就随机选择一个节点,不过系统会避免挑选那些存储太满或太忙的节点。)第2个复本放在与第1个复本不同且随机另外选择的机架的节点上(离架)。第3个复本与第2个复本放在相同的机架,且随机选择另一个节点。其他复本放在集群中随机的节点上,不过系统会尽量避免相同的机架放太多复本。
- 总的来说,这一方法不仅提供了很好的稳定性(数据块存储在两个机架中)并实现很好的负载均衡,包括写入带宽(写入操作只需要遍历一个交换机)、读取性能(可以从两个机架中选择读取)和集群中块的均匀分布(客户端只在本地机架上写入一个块)。
HDFS文件读写过程的更多相关文章
- HDFS 文件读写过程
HDFS 文件读写过程 HDFS 文件读取剖析 客户端通过调用FileSystem对象的open()来读取希望打开的文件.对于HDFS来说,这个对象是分布式文件系统的一个实例. Distributed ...
- Hadoop之HDFS文件读写过程
一.HDFS读过程 1.1 HDFS API 读文件 Configuration conf = new Configuration(); FileSystem fs = FileSystem.get( ...
- 【Hadoop】二、HDFS文件读写流程
(二)HDFS数据流 作为一个文件系统,文件的读和写是最基本的需求,这一部分我们来了解客户端是如何与HDFS进行交互的,也就是客户端与HDFS,以及构成HDFS的两类节点(namenode和dat ...
- f2fs源码分析之文件读写过程
本篇包括三个部分:1)f2fs 文件表示方法: 2)NAT详细介绍:3)f2fs文件读写过程:4) 下面详细阐述f2fs读写的过程. 管理数据位置关键的数据结构是node,node包括三种:inode ...
- HDFS文件读写流程
一.HDFS HDFS全称是Hadoop Distributed System.HDFS是为以流的方式存取大文件而设计的.适用于几百MB,GB以及TB,并写一次读多次的场合.而对于低延时数据访问.大量 ...
- HBase 文件读写过程描述
HBase 数据读写过程描述 我们熟悉的在 Hadoop 使用的文件格式有许多种,例如: Avro:用于 HDFS 数据序序列化与 Parquet:常见于 Hive 数据文件保存在 HDFS中 HFi ...
- HDFS文件读写流程 (转)
文件读取的过程如下: 使用HDFS提供的客户端开发库Client,向远程的Namenode发起RPC请求: Namenode会视情况返回文件的部分或者全部block列表,对于每个block,Namen ...
- HDFS文件读写操作(基础基础超基础)
环境 OS: Ubuntu 16.04 64-Bit JDK: 1.7.0_80 64-Bit Hadoop: 2.6.5 原理 <权威指南>有两张图,下次po上来好好聊一下 实测 读操作 ...
- hadoop笔记-hdfs文件读写
概念 文件系统 磁盘进行读写的最小单位:数据块,文件系统构建于磁盘之上,文件系统的块大小是磁盘块的整数倍. 文件系统块一般为几千字节,磁盘块一般512字节. hdfs的block.pocket.chu ...
随机推荐
- location.hash的摘抄
location.hash详解 去年9月,twitter改版. 一个显著变化,就是URL加入了"#!"符号.比如,改版前的用户主页网址为 http://twitter.com/us ...
- java 多线程—— 线程等待与唤醒
java 多线程 目录: Java 多线程——基础知识 Java 多线程 —— synchronized关键字 java 多线程——一个定时调度的例子 java 多线程——quartz 定时调度的例子 ...
- cellular neural networks(CNN)原理以及应用
一.CNN的原理 1.CNN的思想: (1)借鉴了hopfield神经网络和CA a.hopfield的非线性动力学(主要是用于优化问题,比如旅行商问题等NP问题),Hopfield的能量函数的概念, ...
- NOIP2014感想
NOIP2014转眼就结束了,让人不由感慨时间之快,仿佛几天前还是暑假,几天后就已经坐在考场里了. 从暑假8月开始写博客,发了一些解题报告什么的,但这篇文章不再会是“题目大意 & 解题过程 & ...
- AngularJS向指令传递数据
我今天要实现的功能是利用AngularJS来完成客户端过滤器. list.html页面主要代码如下: ...... <div class='tj_con_tr_ipt' ng-init=&quo ...
- HBase with MapReduce (SummaryToFile)
上一篇文章是实现统计hbase单元值出现的个数,并将结果存放到hbase的表中,本文是将结果存放到hdfs上.其中的map实现与前文一直,连接:http://www.cnblogs.com/ljy20 ...
- iOS 中捕获程序崩溃日志
iOS 中捕获程序崩溃日志 (2014-04-22 17:35:59) 转载▼ iOS开发中遇到程序崩溃是很正常的事情,如何在程序崩溃时捕获到异常信息并通知开发者,是大多数软件都选择的方法.下 ...
- HDU 1508 DP
题意:规定一个数列 = {这个数的质因子只能包括2,3,5,7},求第n个数字是多少: 思路:暴力打表,然后只粘数据,虽然过了,但是正解其实是DP,每一个数字都是由某一个该数列里的某一个数字乘以2,3 ...
- 监听调试web service的好工具TCPMon
监听调试web service的好工具TCPMonhttp://ws.apache.org/commons/tcpmon/download.cgi TCPMon Tutorial Content In ...
- php之无限极分类
首先建立分类信息表: CREATE TABLE IF NOT EXISTS `category` ( `categoryId` smallint(5) unsigned NOT NULL AUTO_I ...