Python基础之【第一篇】
| Python简介: |
python的创始人为吉多·范罗苏姆(Guido van Rossum)。1989年的圣诞节期间,吉多·范罗苏姆为了在阿姆斯特丹打发时间,决心开发一个新的脚本解释程序,作为ABC语言的一种继承。
Python可以应用于众多领域,如:数据分析、组件集成、网络服务、图像处理、数值计算和科学计算等众多领域。目前业内几乎所有大中型互联网企业都在使
用Python,如:Youtube、Dropbox、BT、Quora(中国知乎)、豆瓣、知乎、Google、Yahoo!、Facebook、
NASA、百度、腾讯、汽车之家、美团等。
互联网公司广泛使用Python来做的事一般有:自动化运维、自动化测试、大数据分析、爬虫、Web 等。
python和其他语言的区别:
其他语言: 代码编译得到
字节码 ,虚拟机执行字节码并转换成机器码再后在处理器上执行
C 和 Python、Java、C#等 C语言: 代码编译得到
机器码 ,机器码在处理器上直接执行,每一条指令控制CPU工作
Python 和 C
Python这门语言是由C开发而来
对于使用:Python的类库齐全并且使用简洁,如果要实现同样的功能,Python
10行代码可以解决,C可能就需要100行甚至更多.
对于速度:Python的运行速度相较与C,绝逼是慢了
Python 和 Java、C#等
对于使用:Linux原装Python,其他语言没有;以上几门语言都有非常丰富的类库支持
对于速度:Python在速度上可能稍显逊色
所以,Python和其他语言没有什么本质区别,其他区别在于:擅长某领域、人才丰富、先入为主。
Python的种类:
Cpython
Python的官方版本,使用C语言实现,使用最为广泛,CPython实现会将源文件(py文件)转换成字节码文件(pyc文件),然后运行在Python虚拟机上。
Jyhton
Python的Java实现,Jython会将Python代码动态编译成Java字节码,然后在JVM上运行。
IronPython
Python的C#实现,IronPython将Python代码编译成C#字节码,然后在CLR上运行。(与Jython类似)
PyPy(特殊)
Python实现的Python,将Python的字节码字节码再编译成机器码。
Python环境:
安装Python
windows:
1、下载安装包
https://www.python.org/downloads/
2、安装
默认安装路径:C:\python27
3、配置环境变量
【右键计算机】--》【属性】--》【高级系统设置】--》【高级】--》【环境变量】--》【在第二个内容框中找到 变量名为Path
的一行,双击】 --> 【Python安装目录追加到变值值中,用 ; 分割】
如:原来的值;C:\python27,切记前面有分号
linux:
无需安装,原装Python环境,如果自带2.6,请更新至2.7
更新Python
windows: 卸载重装即可
linux:
Linux的yum依赖自带Python,为防止错误,此处更新其实就是再安装一个Python
查看默认Python版本
python -V
1、安装gcc,用于编译Python源码
yum install
gcc
2、下载源码包,https://www.python.org/ftp/python/
3、解压并进入源码文件
4、编译安装
./configure
make
all
make
install
5、查看版本
/usr/local/bin/python2.7 -V
6、修改默认Python版本
mv
/usr/bin/python /usr/bin/python2.6
ln -s
/usr/local/bin/python2.7 /usr/bin/python
7、防止yum执行异常,修改yum使用的Python版本
vi
/usr/bin/yum
将头部
#!/usr/bin/python 修改为 #!/usr/bin/python2.6
Python入门
一、第一句Python代码
创建 hello.py 文件,内容如下:
print "hello,world"
执行 hello.py 文件,即:
python hello.py
python内部执行过程如下:
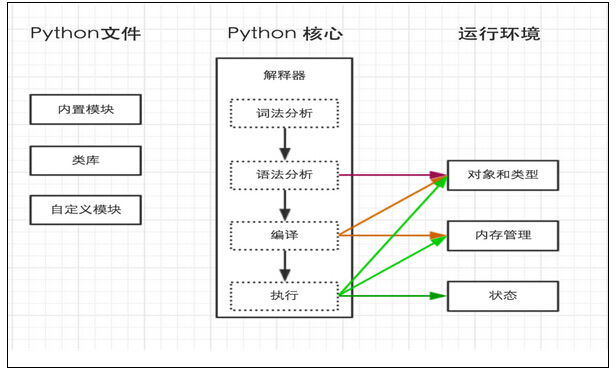
二、解释器
上一步中执行 python hello.py 时,明确的指出 hello.py 脚本由 python 解释器来执行。
如果想要类似于执行shell脚本一样执行python脚本,例:./hello.py ,那么就需要在 hello.py
文件的头部指定解释器,如下:
#!/usr/bin/env python
print "hello,world"
如此一来,执行: ./hello.py 即可。
ps:执行前需给予 hello.py 执行权限,chmod 755 hello.py
三、内容编码
python解释器在加载 .py 文件中的代码时,会对内容进行编码(默认ASCLL)
ASCII(American Standard Code for Information
Interchange,美国标准信息交换代码)是基于拉丁字母的一套电脑编码系统,主要用于显示现代英语和其他西欧语言,其最多只能用 8
位来表示(一个字节)(一个字节用0和1表示),即:2**8 = 256,所以,ASCII码最多只能表示 256 个符号。
ASCII码无法将世界上的各种文字和符号全部表示,所以,就需要新出一种可以代表所有字符和符号的编码,即:Unicode
Unicode(统一码、万国码、单一码)是一种在计算机上使用的字符编码。Unicode
是为了解决传统的字符编码方案的局限而产生的,
它为每种语言中的每个字符设定了统一并且唯一的二进制编码,规定虽有的字符和符号最少由 16 位来表示(2个字节),即:2 **16 =
65536,
注:此处说的的是最少2个字节,可能更多
UTF-8,是对Unicode编码的压缩和优化,他不再使用最少使用2个字节,而是将所有的字符和符号进行分类:ASCLL码中的内容用1个字节保存、欧洲的字符用2个字节保存,东亚的字符用3个字节保存...
所以,python解释器在加载.py文件中的代码时,会对内容进行编码(默认ASCLL),如果是如下代码的话:
报错:ASCLL码无法表示中文
#!/usr/bin/env python
print "你好,世界"
改正:应该显示的告诉python解释器,用什么编码来执行源代码,即:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
#coding:utf-8
#coding=utf-8
print "你好,世界"
- # -*- coding: utf-8 -*-
- #coding:utf-8
- #coding=utf-8
- 这三种方法是等价的
四、注释
单行注视:# 被注释内容
多行注释:""" 被注释内容 """
五、执行脚本传入参数:
Python有大量的模块,从而使得开发Python程序非常简洁。类库有包括三中:
Python内部提供的模块
业内开源的模块
程序员自己开发的模块
Python内部提供一个 sys 的模块,其中的 sys.argv 用来捕获执行执行python脚本时传入的参数
- #!/usr/bin/env python
- # -*- coding: utf-8 -*-
- import sys
- print sys.argv
六、pyc文件
执行Python代码时,如果导入了其他的.py文件,那么,执行过程中会自动生成一个与其同名的.pyc文件,该文件就是Python解释器编译之后产生的字节码。
ps:代码经过编译可以产生字节码;字节码通过反编译也可以得到代码。
七、变量
1、声明变量
- #!/usr/bin/env python
- #coding:utf-8
- name = "saneri"
上述代码声明了一个变量,变量名为:name,变量name的值为:"saneri"
变量的作用:昵称,其代指内存里某个地址中保存的内容
变量定义的规则:
变量名只能是 字母、数字或下划线的任意组合
变量名的第一个字符不能是数字
以下关键字不能声明为变量名
- ['and', 'as', 'assert', 'break', 'class', 'continue', 'def', 'del', 'elif', 'else', 'except', 'exec', 'finally', 'for', 'from', 'global', 'if', 'import', 'in', 'is', 'lambda', 'not', 'or', 'pass', 'print', 'raise', 'return', 'try', 'while', 'with', 'yield']
2、变量的赋值
- #!/usr/bin/env python
- # -*- coding: utf-8 -*-
- name1 = "saneri"
- name2 = "ABC"
开辟了两块不同的内存空间.
- #!/usr/bin/env python
- # -*- coding: utf-8 -*-
- name1 = "saneri"
- name2 = name1
开辟了一块内存空间,内存指向为同一个地址.
八、输入
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# 将用户输入的内容赋值给 name 变量
name = raw_input("请输入用户名:")
# 打印输入的内容
print name
输入密码时,如果想要不可见,需要利用getpass 模块中的 getpass方法,即:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import getpass
# 将用户输入的内容赋值给 name 变量
pwd = getpass.getpass("请输入密码:")
# 打印输入的内容
print pwd
九、流程控制和缩进
需求一、用户登陆验证
# 提示输入用户名和密码
# 验证用户名和密码
# 如果错误,则输出用户名或密码错误
# 如果成功,则输出 欢迎,XXX!
- #!/usr/bin/env python
- # -*- coding: encoding -*-
- import getpass
- name = raw_input('请输入用户名:')
- pwd = getpass.getpass('请输入密码:')
- if name == "zhangsan" and pwd == "cmd":
- print "欢迎,zhangsan!"
- else:
- print "用户名和密码错误"
内层变量,无法被外层变量使用
外层变量,可以被内层变量使用
十、初识基本数据类型
1、数字
10是一个整数的例子。
长整数 不过是大一些的整数。
3.14和52.3E-4是浮点数的例子。E标记表示10的幂。在这里,52.3E-4表示52.3 * 10-4。
(-5+4j)和(2.3-4.6j)是复数的例子。
int(整型)
在32位机器上,整数的位数为32位,取值范围为-2**31~2**31-1,即-2147483648~2147483647
在64位系统上,整数的位数为64位,取值范围为-2**63~2**63-1,即-9223372036854775808~9223372036854775807
long(长整型)
跟C语言不同,Python的长整数没有指定位宽,即:Python没有限制长整数数值的大小,但实际上由于机器内存有限,我们使用的长整数数值不可能无限大。
注意,自从Python2.2起,如果整数发生溢出,Python会自动将整数数据转换为长整数,所以如今在长整数数据后面不加字母L也不会导致严重后果了。
float(浮点型)
浮点数用来处理实数,即带有小数的数字。
complex(复数)
复数由实数部分和虚数部分组成,一般形式为x+yj,其中的x是复数的实数部分,y是复数的虚数部分,这里的x和y都是实数。
注:Python中存在小数字池:-5 ~ 257
2、布尔值
真(Ture)或假(Fash) 1 或 0
3、字符串
例如: "hello world"
万恶的字符串拼接:
python中的字符串在C语言中体现为是一个字符数组,每次创建字符串时候需要在内存中开辟一块连续的空,并且一旦需要修改字符串的话,就需要再次开辟空间,万恶的+号每出现一次就会在内存中重新开辟一块空间。
字符串格式化
- name = "saneri"
- print "i am %s " % name
- #输出: i am saneri
PS: 字符串是 %s; 整数 %d; 浮点数%f
字符串常用功能:
移除空白
分割
长度
索引
切片
4、列表
创建列表:
name_list = ['zsan', 'seven', 'eric']
或
name_list = list(['zsan', 'seven', 'eric'])
基本操作:
索引
切片
追加
删除
长度
循环
包含
5、元组
创建元组:
ages = (11, 22, 33, 44, 55)
或
ages = tuple((11, 22, 33, 44, 55))
基本操作:
索引
切片
循环
长度
包含
6、字典(无序)
创建字典:
person = {"name": "saneri", 'age': 18}
或
person = dict({"name": "saneri", 'age': 18})
常用操作:
索引
新增
删除
键、值、键值对
循环
长度
PS:循环,range,continue 和 break
十一、运算
算数运算:
比较运算:
赋值运算:
逻辑运算:
成员运算:
身份运算:
位运算:
运算符优先级:
更多详细信息,点以下链接地址:
http://www.runoob.com/python/python-operators.html#ysf1
十二、文本的基本操作
1.打开文件:
- file_obj = file("文件路径","模式") 推荐使用 open
打开文件时,需要指定文件路径和以何等方式打开文件,打开后,即可获取该文件句柄,此后通过此文件句柄对该文件操作。
打开文件的模式有:
- r,只读模式(默认)。
- w,只写模式。【不可读;不存在则创建;存在则删除内容;】
- a,追加模式。【可读;不存在则创建;存在则只追加内容;】
"+" 表示可以同时读写某个文件
- r+, 可读写文件。【可读;可写;可追加】
- w+,无意义
- a+, 同a
"U"表示在读取时,可以将 \r \n \r\n自动转换成 \n (与 r 或 r+ 模式同使用)
- rU
- r+U
"b"表示处理二进制文件(如:FTP发送上传ISO镜像文件,linux可忽略,windows处理二进制文件时需标注)
- rb
- wb
- ab
读取文件的内容:
# 一次性加载所有内容到内存
file_obj.read()
# 一次性加载所有内容到内存,并根据行分割成字符串
file_obj.readlines()
# 每次仅读取一行数据
for line in file_obj:
print line
写文件的内容:
file_obj.write('内容')
关闭文件句柄:
file_obj.close()
- python中read() readline()以及readlines()区别 :
- .read() 每次读取整个文件,它通常将读取到底文件内容放到一个字符串变量中,也就是说 .read() 生成文件内容是一个字符串类型
- .readline() 每只读取文件的一行,通常也是读取到的一行内容放到一个字符串变量中,返回str类型
- .readlines() 每次按行读取整个文件内容,将读取到的内容放到一个列表中,返回list类型
2、文件操作
- class file(object):
- def close(self): # real signature unknown; restored from __doc__
- 关闭文件
- """
- close() -> None or (perhaps) an integer. Close the file.
- Sets data attribute .closed to True. A closed file cannot be used for
- further I/O operations. close() may be called more than once without
- error. Some kinds of file objects (for example, opened by popen())
- may return an exit status upon closing.
- """
- def fileno(self): # real signature unknown; restored from __doc__
- 文件描述符
- """
- fileno() -> integer "file descriptor".
- This is needed for lower-level file interfaces, such os.read().
- """
- return
- def flush(self): # real signature unknown; restored from __doc__
- 刷新文件内部缓冲区
- """ flush() -> None. Flush the internal I/O buffer. """
- pass
- def isatty(self): # real signature unknown; restored from __doc__
- 判断文件是否是同意tty设备
- """ isatty() -> true or false. True if the file is connected to a tty device. """
- return False
- def next(self): # real signature unknown; restored from __doc__
- 获取下一行数据,不存在,则报错
- """ x.next() -> the next value, or raise StopIteration """
- pass
- def read(self, size=None): # real signature unknown; restored from __doc__
- 读取指定字节数据
- """
- read([size]) -> read at most size bytes, returned as a string.
- If the size argument is negative or omitted, read until EOF is reached.
- Notice that when in non-blocking mode, less data than what was requested
- may be returned, even if no size parameter was given.
- """
- pass
- def readinto(self): # real signature unknown; restored from __doc__
- 读取到缓冲区,不要用,将被遗弃
- """ readinto() -> Undocumented. Don't use this; it may go away. """
- pass
- def readline(self, size=None): # real signature unknown; restored from __doc__
- 仅读取一行数据
- """
- readline([size]) -> next line from the file, as a string.
- Retain newline. A non-negative size argument limits the maximum
- number of bytes to return (an incomplete line may be returned then).
- Return an empty string at EOF.
- """
- pass
- def readlines(self, size=None): # real signature unknown; restored from __doc__
- 读取所有数据,并根据换行保存值列表
- """
- readlines([size]) -> list of strings, each a line from the file.
- Call readline() repeatedly and return a list of the lines so read.
- The optional size argument, if given, is an approximate bound on the
- total number of bytes in the lines returned.
- """
- return []
- def seek(self, offset, whence=None): # real signature unknown; restored from __doc__
- 指定文件中指针位置
- """
- seek(offset[, whence]) -> None. Move to new file position.
- Argument offset is a byte count. Optional argument whence defaults to
- (offset from start of file, offset should be >= ); other values are
- (move relative to current position, positive or negative), and (move
- relative to end of file, usually negative, although many platforms allow
- seeking beyond the end of a file). If the file is opened in text mode,
- only offsets returned by tell() are legal. Use of other offsets causes
- undefined behavior.
- Note that not all file objects are seekable.
- """
- pass
- def tell(self): # real signature unknown; restored from __doc__
- 获取当前指针位置
- """ tell() -> current file position, an integer (may be a long integer). """
- pass
- def truncate(self, size=None): # real signature unknown; restored from __doc__
- 截断数据,仅保留指定之前数据
- """
- truncate([size]) -> None. Truncate the file to at most size bytes.
- Size defaults to the current file position, as returned by tell().
- """
- pass
- def write(self, p_str): # real signature unknown; restored from __doc__
- 写内容
- """
- write(str) -> None. Write string str to file.
- Note that due to buffering, flush() or close() may be needed before
- the file on disk reflects the data written.
- """
- pass
- def writelines(self, sequence_of_strings): # real signature unknown; restored from __doc__
- 将一个字符串列表写入文件
- """
- writelines(sequence_of_strings) -> None. Write the strings to the file.
- Note that newlines are not added. The sequence can be any iterable object
- producing strings. This is equivalent to calling write() for each string.
- """
- pass
- def xreadlines(self): # real signature unknown; restored from __doc__
- 可用于逐行读取文件,非全部
- """
- xreadlines() -> returns self.
- For backward compatibility. File objects now include the performance
- optimizations previously implemented in the xreadlines module.
- """
- pass
3.with
为了避免打开文件后忘记关闭,可以通过管理上下文,即:
- with open('log','r') as f:
- ...
- 如此方式,当with代码块执行完毕时,内部会自动关闭并释放文件资源。
在Python 2.7 后,with又支持同时对多个文件的上下文进行管理,即:
- with open('log1') as obj1, open('log2') as obj2:
- pass
十三、python流程控制
条件控制分支语句 if
if多分支结构: if ...elif ...else..
- count = int(raw_input("Plz input your math record:"))
- if count >= :
- print 'A'
- elif count >= :
- print 'B'
- elif count >= :
- print 'C'
- elif count >= :
- print 'D'
- else:
- print 'No pass !!!'
Python循环语句 while for
python实例:
统计1到100的叠加:1+2+3...100
- i =
- count =
- while i <= :
- print count,i
- count = count + i
- i = i +
- else:
- print 'count = ', count
或者使用range()函数:
- #!/usr/bin/python
- sum=
- for i in range(,): ///range(1,101) 代表从1到101(不包含101)
- sum += i
- print sum
使用for循环来访问list :
- i =
- for w in range(,,): //#代表从1到100,间隔2(不包含100)
- print format(i ,'2d'),w
- i = i +
- else:
- print 'out w'
编写登陆接口:
1.输入用户名密码
2.认证成功后显示欢迎信息
3.输错三次后锁定
- #!/usr/bin/env python
- # -*- coding:utf- -*-
- import sys
- import getpass
- errortimes =
- while True:
- user = raw_input("请输入用户名:").strip()
- # pwd = raw_input("请输入密码:").strip()
- if len(user) == :
- print "\033[31;1m用户名为空,请重新输入\033[0m"
- continue
- elif user != "saneri":
- print "\033[32;1m用户名不存在,请重新输入\033[0m"
- continue
- while errortimes < :
- if user == "saneri":
- pwd = getpass.getpass("请输入密码:").strip()
- if pwd == "":
- print "欢迎 %s 登陆" %user
- sys.exit()
- else:
- print "\033[34;1m请重新输入密码!!!\033[0m"
- errortimes +=
- else:
- print "\033[33;1m你已经超过三次输入,账户已锁定!!!\033[0m"
- break
Python基础之【第一篇】的更多相关文章
- Python基础【第一篇】
一.Python简介 Python的创始人(Guido von Rossum 荷兰人),Guido希望有一种语言既能像C一样方便地调用操作系统的功能接口,也能像shell脚本一样,轻松地实现编程,A ...
- python基础知识第一篇(认识Python)
开发语言: 高级语言:python java php c++ 生成的字节码 字节码转换为机器码 计算机识别运行 低级语言:C 汇编 生成的机器码 PHP语言:适用于网页,局限性 Python,Java ...
- Python 基础【第一篇】环境部署
一.Windows基础环境配置部署 1.1.下载python安装程序 下载地址:https://www.python.org/ftp/python/3.4.1/python-3.4.1.msi 1.2 ...
- Python开发【第一篇】:目录
本系列博文包含 Python基础.前端开发.Web框架.缓存以及队列等,希望可以给正在学习编程的童鞋提供一点帮助!!! Python开发[第一篇]:目录 Python开发[第二篇]:初识Python ...
- Python开发【第一篇】:目录
本系列博文包含Python基础.前端开发.Web框架.缓存以及队列等,希望可以给正在学习Python编程的朋友们提供一点帮助! .Python开发[第一篇]:目录 .Python开发[第二篇]:初始P ...
- 【MM系列】SAP MM模块-基础配置第一篇
公众号:SAP Technical 本文作者:matinal 原文出处:http://www.cnblogs.com/SAPmatinal/ 原文链接:[MM系列]SAP MM模块-基础配置第一篇 ...
- Python之路(第一篇):Python简介和基础
一.开发简介 1.开发: 开发语言: 高级语言:python.JAVA.PHP.C#..ruby.Go-->字节码 低级语言: ...
- python基础-第六篇-6.2模块
python之强大,就是因为它其提供的模块全面,模块的知识点不仅多,而且零散---一个字!错综复杂 没办法,二八原则抓重点咯!只要抓住那些以后常用开发的方法就可以了,哪些是常用的?往下看--找答案~ ...
- Android基础学习第一篇—Project目录结构
写在前面的话: 1. 最近在自学Android,也是边看书边写一些Demo,由于知识点越来越多,脑子越来越记不清楚,所以打算写成读书笔记,供以后查看,也算是把自己学到所理解的东西写出来,献丑,如有不对 ...
- Python 基础学习 总结篇
Python 基础学习总结 先附上所有的章节: Python学习(一)安装.环境配置及IDE推荐 Python学习(二)Python 简介 Python学习(三)流程控制 Python学习(四)数据结 ...
随机推荐
- 100722A
这道题抄了答案: 思路:旋转,其实只用旋转四次,因为在换行的过程中旋转其实是没有意义的,因为行列只不过转了个角度.然后主要的是行列的交换,这里我很头疼,写了个盲目搜索,当然wa掉了 问了问某位同志,是 ...
- fastq to tasta using linux shell script
#!/bin/bash usage() { echo " "; echo "############################################### ...
- iOS开发基础知识碎片
1:contentSize.contentInset和contentOffset区别 contentSize 是scrollview中的一个属性,它代表scrollview中的可显示区域,假如有一个s ...
- js-JavaScript高级程序设计学习笔记4
第六章 面向对象的程序设计 1.面向对象的语言有一个标志,那就是它们都有类的概念,而通过类可以创建任意多个具有相同属性和方法的对象.如python.ES中没有类的概念. 2.ES的对象可以想象成散列表 ...
- Leetcode Move Zeros
Given an array nums, write a function to move all 0's to the end of it while maintaining the relativ ...
- 【BZOJ-2460&3105】元素&新Nim游戏 动态维护线性基 + 贪心
3105: [cqoi2013]新Nim游戏 Time Limit: 10 Sec Memory Limit: 128 MBSubmit: 839 Solved: 490[Submit][Stat ...
- 【BZOJ-1468】Tree 树分治
1468: Tree Time Limit: 10 Sec Memory Limit: 64 MBSubmit: 1025 Solved: 534[Submit][Status][Discuss] ...
- linux永久更改eth0的ip地址
linux中永久修改ip和子网掩码,可以用命令也可以直接到文件里修改.这里推荐直接到文件中修改.1.进入网卡配置文件 vi /etc/sysconfig/network-scripts/ifcfg-e ...
- Linux内核版本类型
对于Linux内核发布的版本类型有如下,也是自己的理解: [mainline]:主线版本,由Linux Torvalds维护和发布. [stable/EOL]:稳定版本,每个由主线发布的版本都叫做稳定 ...
- VisualSVN Server和Subversion的联系
VisualSVN Server是只能在Windows平台上搭建的SVN服务器,内核使用的是Subversion,做了整合:apache+subversion+WMI(实现操作界面等). 用这个的好处 ...