Hadoop SequenceFile数据结构介绍及读写
在一些应用中,我们需要一种特殊的数据结构来存储数据,并进行读取,这里就分析下为什么用SequenceFile格式文件。
Hadoop SequenceFile
Hadoop提供的SequenceFile文件格式提供一对key,value形式的不可变的数据结构。同时,HDFS和MapReduce job使用SequenceFile文件可以使文件的读取更加效率。
SequenceFile的格式
SequenceFile的格式是由一个header 跟随一个或多个记录组成。前三个字节是一个Bytes SEQ代表着版本号,同时header也包括key的名称,value class , 压缩细节,metadata,以及Sync markers。Sync markers的作用在于可以读取任意位置的数据。
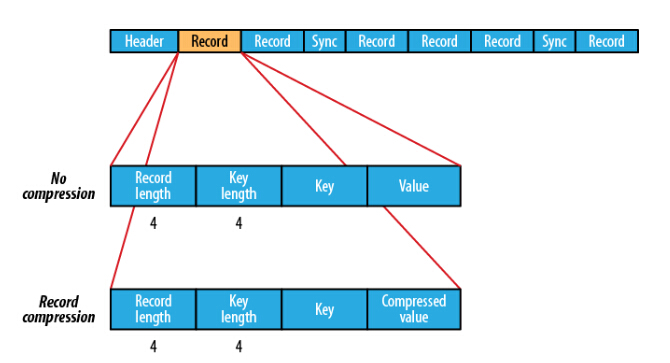
在recourds中,又分为是否压缩格式。当没有被压缩时,key与value使用Serialization序列化写入SequenceFile。当选择压缩格式时,record的压缩格式与没有压缩其实不尽相同,除了value的bytes被压缩,key是不被压缩的。
在Block中,它使所有的信息进行压缩,压缩的最小大小由配置文件中,io.seqfile.compress.blocksize配置项决定。
SequenceFile的MapFile
一个MapFile可以通过SequenceFile的地址,进行分类查找的格式。使用这个格式的优点在于,首先会将SequenceFile中的地址都加载入内存,并且进行了key值排序,从而提供更快的数据查找。
写SequenceFile文件:
将key按100-1以IntWritable object进行倒叙写入sequence file,value为Text objects格式。在将key和value写入Sequence File前,首先将每行所在的位置写入(writer.getLength())
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.SequenceFile;
import org.apache.hadoop.io.Text;
import java.io.IOException;
import java.net.URI;
public class SequenceFileWriteDemo {
private static final String[] DATA = {
"One, two, buckle my shoe",
"Three, four, shut the door",
"Five, six, pick up sticks",
"Seven, eight, lay them straight",
"Nine, ten, a big fat hen"
};
public static void main(String[] args) throws IOException {
String uri = args[0];
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(URI.create(uri), conf);
Path path = new Path(uri);
IntWritable key = new IntWritable();
Text value = new Text();
SequenceFile.Writer writer = null;
try {
writer = SequenceFile.createWriter(fs, conf, path,
key.getClass(), value.getClass());
for (int i = 0; i < 100; i++) {
key.set(100 - i);
value.set(DATA[i % DATA.length]);
System.out.printf("[%s]\t%s\t%s\n", writer.getLength(), key, value);
writer.append(key, value);
}
} finally {
IOUtils.closeStream(writer);
}
}
}
读取SequenceFile文件:
首先需要创建SequenceFile.Reader实例,随后通过调用next()函数进行每行结果集的迭代(需要依赖序列化).
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.io.SequenceFile;
import org.apache.hadoop.io.Writable;
import org.apache.hadoop.util.ReflectionUtils;
import java.io.IOException;
import java.net.URI;
public class SequenceFileReadDemo {
public static void main(String[] args) throws IOException {
String uri = args[0];
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(URI.create(uri), conf);
Path path = new Path(uri);
SequenceFile.Reader reader = null;
try {
reader = new SequenceFile.Reader(fs, path, conf);
Writable key = (Writable)
ReflectionUtils.newInstance(reader.getKeyClass(), conf);
Writable value = (Writable)
ReflectionUtils.newInstance(reader.getValueClass(), conf);
long position = reader.getPosition();
while (reader.next(key, value)) {
//同步记录的边界
String syncSeen = reader.syncSeen() ? "*" : "";
System.out.printf("[%s%s]\t%s\t%s\n", position, syncSeen, key, value);
position = reader.getPosition(); // beginning of next record
}
} finally {
IOUtils.closeStream(reader);
}
}
}


参考文献: 《Hadoop:The Definitive Guide, 4th Edition》
Hadoop SequenceFile数据结构介绍及读写的更多相关文章
- Java基础-JAVA中常见的数据结构介绍
Java基础-JAVA中常见的数据结构介绍 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.什么是数据结构 答:数据结构是指数据存储的组织方式.大致上分为线性表.栈(Stack) ...
- Python pandas 0.19.1 Intro to Data Structures 数据结构介绍 文档翻译
官方文档链接http://pandas.pydata.org/pandas-docs/stable/dsintro.html 数据结构介绍 我们将以一个快速的.非全面的pandas的基础数据结构概述来 ...
- BCM芯片FP原理及相关SDK数据结构介绍
BCM芯片有几个大的模块: VLAN.L2.L3和FP等几个,其中FP的使用也最为灵活,能解析匹配数据包文的前128字节比特级的内容,动作包括转发.丢弃.结合qos修改相应字段.分配vid.流镜像.流 ...
- redis学习(二) redis数据结构介绍以及常用命令
redis数据结构介绍 我们已经知道redis是一个基于key-value数据存储的数据结构数据库,这里的key指的是string类型,而对应的value则可以是多样的数据结构.其中包括下面五种类型: ...
- Hadoop生态圈-hbase介绍-完全分布式搭建
Hadoop生态圈-hbase介绍-完全分布式搭建 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任.
- Hadoop生态圈-hbase介绍-伪分布式安装
Hadoop生态圈-hbase介绍-伪分布式安装 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.HBase简介 HBase是一个分布式的,持久的,强一致性的存储系统,具有近似最 ...
- 大数据之路week06--day07(Hadoop生态圈的介绍)
Hadoop 基本概念 一.Hadoop出现的前提环境 随着数据量的增大带来了以下的问题 (1)如何存储大量的数据? (2)怎么处理这些数据? (3)怎样的高效的分析这些数据? (4)在数据增长的情况 ...
- 读书笔记一、pandas数据结构介绍
pandas数据结构介绍 主要两种数据结构:Series和DataFrame. Series Series是一种类似于一维数组的对象,由一组数据(各种NumPy数据类型)+数据标签(即索引)组 ...
- Hadoop以及组件介绍
一.背景介绍 在接触过大数据相关项目的时候常常都会听到Hadoop这个东西,简单来说,他是一个用分布式计算来处理大数据的开源软件,下面包含了许多的组件和子项目,这篇文章将会介绍Hadoop的原理以及一 ...
随机推荐
- jQuery水平下拉菜单实现
<!DOCTYPE html> <html> <head> <title>jQuery水平下拉菜单实现</title> ...
- 三星在GPL下发布其exFAT文件系统实现源码
exFAT文件系统是微软的一个产品,设计让外置储存设备和PC之间实现无缝的TB级数据转移和数据交换,它只支持Windows和OS X,不支持Linux.作为一个含有大量专利的私有产品,没有人会预计它会 ...
- hdoj 5003
题意:给你一个数组a,降序排序后,求sum+=0.95^(i-1)*ai 这题wa了两发,因为我没看清题意,要排序! 精度上面通过a^(i-1)=e^((i-1)*log(a)) 提到精度,就要想到底 ...
- bzoj 3171: [Tjoi2013]循环格
#include<cstdio> #include<iostream> #include<cstring> #define M 10000 #define inf ...
- mysql命令行创建存储过程命令行定时执行sql语句
mysql -uroot -p show databases; use scm; show tables; show procedure status; 其他命令: SHOW VARIABLES LI ...
- 使用python 提取网页的特定数据转
http://blog.csdn.net/nwpulei/article/details/7272832
- Java中文档制作与继承
1:如何制作帮助文档(了解) (1)写一个类 (2)加入文档注释 (3)通过javadoc工具生成即可 javadoc -d 目录 -author -version ArrayTool.java 2: ...
- android 拉伸图片
Android拉伸图片用的是9.png格式的图片,这种图片可以指定图片的那一部分拉伸,那一部分显示内容,美工给的小图片也能有很好的显示效果. 原背景图片 可以看到原背景图片很小,即使在再长的文字,背景 ...
- WCF vs ASMX WebService
This question comes up a lot in conversations I have with developers. “Why would I want to switch to ...
- 三部曲一(数据结构)-1020-Ultra-QuickSort
通过这道题我大体理解了树状数组的原理和用法,完全用的别人的算法,我把别人算法看懂之后有自己敲了一遍,不得不说这算法真是高深巧妙啊,我开始看都看不懂,还是在别人的讲解下才看懂的,我觉得有必要写个博客记录 ...