Spark SQL External Data Sources JDBC简易实现
在spark1.2版本中最令我期待的功能是External Data Sources,通过该API可以直接将External Data Sources注册成一个临时表,该表可以和已经存在的表等通过sql进行查询操作。External Data Sources API代码存放于org.apache.spark.sql包中。
具体的分析可参见OopsOutOfMemory的两篇精彩博文:
http://blog.csdn.net/oopsoom/article/details/42061077
http://blog.csdn.net/oopsoom/article/details/42064075
自己尝试实现了一个简易的读取关系型数据库的外部数据源,代码参见:https://github.com/luogankun/spark-jdbc
支持MySQL/Oracle/DB2,以及几种简单的数据类型,暂时还不支持PrunedScan、PrunedFilteredScan,仅支持TableScan,后续在接着完善。
使用步骤:
1、编译spark-jdbc代码
sbt package
2、添加jar包到spark-env.sh
export SPARK_CLASSPATH=/home/spark/software/source/spark_package/spark-jdbc/target/scala-2.10/spark-jdbc_2.-0.1.jar:$SPARK_CLASSPATH
export SPARK_CLASSPATH=/home/spark/lib/ojdbc6.jar:$SPARK_CLASSPATH
export SPARK_CLASSPATH=/home/spark/lib/db2jcc4.jar:$SPARK_CLASSPATH
export SPARK_CLASSPATH=/home/spark/lib/mysql-connector-java-3.0..jar:$SPARK_CLASSPATH
3、SQL使用:启动spark-sql
参数说明:
url :关系型数据库url
user :关系型数据库用户名
password: 关系型数据库密码
sql:关系型数据库sql查询语句
MySQL:
CREATE TEMPORARY TABLE jdbc_table
USING com.luogankun.spark.jdbc
OPTIONS (
url 'jdbc:mysql://hadoop000:3306/hive',
user 'root',
password 'root',
sql 'select TBL_ID,TBL_NAME,TBL_TYPE FROM TBLS WHERE TBL_ID < 100'
); SELECT * FROM jdbc_table;
Oracle:
CREATE TEMPORARY TABLE jdbc_table
USING com.luogankun.spark.jdbc
OPTIONS (
url 'jdbc:oracle:thin:@hadoop000:1521/ora11g',
user 'coc',
password 'coc',
sql 'select HISTORY_ID, APPROVE_ROLE_ID, APPROVE_OPINION from CI_APPROVE_HISTORY'
); SELECT * FROM jdbc_table;
DB2:
CREATE TEMPORARY TABLE jdbc_table
USING com.luogankun.spark.jdbc
OPTIONS (
url 'jdbc:db2://hadoop000:60000/CI',
user 'ci',
password 'ci',
sql 'select LABEL_ID from coc.CI_APPROVE_STATUS'
); SELECT * FROM jdbc_table;
在测试过程中遇到的问题:
如上的代码在连接MySQL数据库操作时没有问题,但是在操作Oracle或者DB2数据库时,报错如下:
09:56:48,302 [Executor task launch worker-0] ERROR Logging$class : Error in TaskCompletionListener
java.lang.AbstractMethodError: oracle.jdbc.driver.OracleResultSetImpl.isClosed()Z
at org.apache.spark.rdd.JdbcRDD$$anon$1.close(JdbcRDD.scala:99)
at org.apache.spark.util.NextIterator.closeIfNeeded(NextIterator.scala:63)
at org.apache.spark.rdd.JdbcRDD$$anon$1$$anonfun$1.apply(JdbcRDD.scala:71)
at org.apache.spark.rdd.JdbcRDD$$anon$1$$anonfun$1.apply(JdbcRDD.scala:71)
at org.apache.spark.TaskContext$$anon$1.onTaskCompletion(TaskContext.scala:85)
at org.apache.spark.TaskContext$$anonfun$markTaskCompleted$1.apply(TaskContext.scala:110)
at org.apache.spark.TaskContext$$anonfun$markTaskCompleted$1.apply(TaskContext.scala:108)
at scala.collection.mutable.ResizableArray$class.foreach(ResizableArray.scala:59)
at scala.collection.mutable.ArrayBuffer.foreach(ArrayBuffer.scala:47)
at org.apache.spark.TaskContext.markTaskCompleted(TaskContext.scala:108)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:64)
at org.apache.spark.scheduler.Task.run(Task.scala:54)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:181)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1145)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:615)
at java.lang.Thread.run(Thread.java:744)
09:56:48,302 [Executor task launch worker-1] ERROR Logging$class : Error in TaskCompletionListener
跟了下JdbcRDD源代码发现,问题在于:
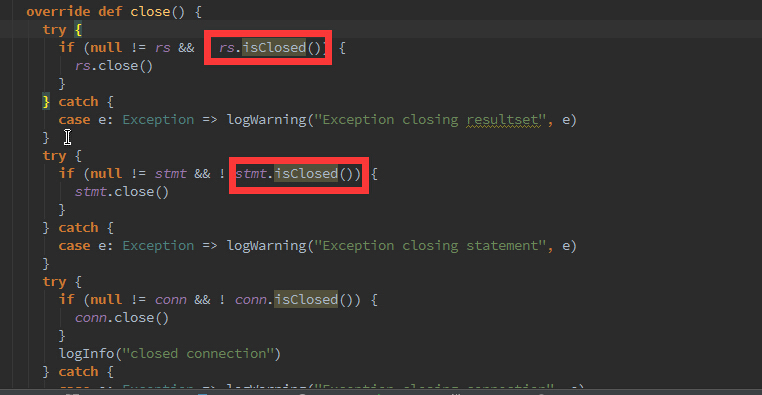
我在本案例中使用的oracle的驱动是ojdbc14-10.2.0.3.jar,查阅了些资料说是Oracle的实现类没有该方法;
该issues详见: https://issues.apache.org/jira/browse/SPARK-5239
解决办法:
1)升级驱动包;
2)暂时屏蔽掉这两个isClosed的判断方法(https://github.com/apache/spark/pull/4033)
4、Scala API使用方式
import com.luogankun.spark.jdbc._
val sqlContext = new HiveContext(sc)
val cities = sqlContext.jdbcTable("jdbc:mysql://hadoop000:3306/test", "root","root","select id, name from city")
cities.collect
后续将会继续完善,现在的实现确实很“丑陋”,凑合着先能使用吧。
Spark SQL External Data Sources JDBC简易实现的更多相关文章
- Spark SQL External Data Sources JDBC官方实现写测试
通过Spark SQL External Data Sources JDBC实现将RDD的数据写入到MySQL数据库中. jdbc.scala重要API介绍: /** * Save this RDD ...
- Spark SQL External Data Sources JDBC官方实现读测试
在最新的master分支上官方提供了Spark JDBC外部数据源的实现,先尝为快. 通过spark-shell测试: import org.apache.spark.sql.SQLContext v ...
- Spark SQL 之 Data Sources
#Spark SQL 之 Data Sources 转载请注明出处:http://www.cnblogs.com/BYRans/ 数据源(Data Source) Spark SQL的DataFram ...
- Spark(3) - External Data Source
Introduction Spark provides a unified runtime for big data. HDFS, which is Hadoop's filesystem, is t ...
- Spark SQL External DataSource简介
随着Spark1.2的发布,Spark SQL开始正式支持外部数据源.这使得Spark SQL支持了更多的类型数据源,如json, parquet, avro, csv格式.只要我们愿意,我们可以开发 ...
- How to: Provide Credentials for the Dashboards Module when Using External Data Sources
XAF中使用dashboard模块时,如果使用了sql数据源,可以使用此方法提供连接信息 https://www.devexpress.com/Support/Center/Question/Deta ...
- 【转载】Spark SQL之External DataSource外部数据源
http://blog.csdn.net/oopsoom/article/details/42061077 一.Spark SQL External DataSource简介 随着Spark1.2的发 ...
- Apache Spark 2.2.0 中文文档 - Spark SQL, DataFrames and Datasets Guide | ApacheCN
Spark SQL, DataFrames and Datasets Guide Overview SQL Datasets and DataFrames 开始入门 起始点: SparkSession ...
- What’s new for Spark SQL in Apache Spark 1.3(中英双语)
文章标题 What’s new for Spark SQL in Apache Spark 1.3 作者介绍 Michael Armbrust 文章正文 The Apache Spark 1.3 re ...
随机推荐
- C++ / CLI 调用 C++ /Native 随记
C# 封装 原生C++ 方法:1.C++ CLR(托管) 调用 C++(原生)2.C#调用C++ CLR , 注意各个平台编译版本需一致.3.C# 默认编绎生成版本是 any cpu , 需修改成 ...
- mybaits入门
1.回顾jdbc开发 orm概述 orm是一种解决持久层对象关系映射的规则,而不是一种具体技术.jdbc/dbutils/springdao,hibernate/springorm,mybaits同属 ...
- leetcode N-Queens/N-Queens II, backtracking, hdu 2553 count N-Queens, dfs 分类: leetcode hdoj 2015-07-09 02:07 102人阅读 评论(0) 收藏
for the backtracking part, thanks to the video of stanford cs106b lecture 10 by Julie Zelenski for t ...
- HDFS中的checkpoint( 检查点 )的问题
1.问题的描述 由于某种原因,需要在原来已经部署了Cloudera CDH集群上重新部署,重新部署之后,启动集群,由于Cloudera Manager 会默认设置dfs.namenode.checkp ...
- UIRefreshControl自动刷新
不知道UIRefreshController是什么的朋友可以参考iOS6新特征:UIRefreshControl[下拉刷新]使用示例 一文了解这是什么,这里只提怎么使用代码的方式触发UIRefresh ...
- 关于VS中文件属性的解释
生成操作(BuildAction) 属性:BuildAction 属性指示 Visual Studio .NET 在执行生成时对文件执行的操作.BuildAction 可以具有以下几个值之一: 无(N ...
- 使用GnuRadio+OpenLTE+SDR搭建4G LTE基站(上)
0×00 前言 在移动互联网大规模发展的背景下,智能手机的普及和各种互联网应用的流行,致使对无线网络的需求呈几何级增长,导致移动运营商之间的竞争愈发激烈.但由于资费下调等各种因素影响,运营商从用户获得 ...
- readfile() 函数
定义和用法 readfile() 函数输出一个文件. 该函数读入一个文件并写入到输出缓冲. 若成功,则返回从文件中读入的字节数.若失败,则返回 false.您可以通过 @readfile() 形式调用 ...
- 转:GROUPING SETS、ROLLUP、CUBE
转:http://blog.csdn.net/shangboerds/article/details/5193211 大家对GROUP BY应该比较熟悉,如果你感觉自己并不完全理解GROUP BY,那 ...
- maven web project打包为war包,目录结构的变化
一个maven web project工程目录: 资源管理器中的目录层级如下: 导出为war包之后的目录层级为: 我们会发现,其实并没有如下的这些目录层级: 所以这两个目录层级只是IDE为我们添加的, ...