Python的scrapy之爬取豆瓣影评和排名
基于scrapy框架的爬影评
爬虫主程序:
import scrapy
from ..items import DoubanmovieItem class MoviespiderSpider(scrapy.Spider):
name = 'moviespider'
allowed_domains = ['douban.com']
start_urls = ['http://movie.douban.com/top250'] def parse(self, response):
movie_items=response.xpath('//div[@class="item"]')
for item in movie_items:
#print(type(item)) movie =DoubanmovieItem()
movie['rank']=item.xpath('div[@class="pic"]/em/text()').extract()
movie['title']=item.xpath('div[@class="info"]/div[@class="hd"]/a/span[@class="title"][1]/text()').extract()
movie['quote'] = item.xpath(
'div[@class="info"]/div[@class="bd"]/p[@class="quote"]/span[@class="inq"][1]/text()').extract()
movie['star'] = item.xpath(
'div[@class="info"]/div[@class="bd"]/div[@class="star"]/span/text()').extract() movie['src']=item.xpath(
'div[@class="pic"]/a/img/@src').extract() yield movie
pass #取下一页的地址
nextPageURL = response.xpath('//span[@class="next"]/a/@href').extract()
#print(nextPageURL)
if nextPageURL:
url = response.urljoin(nextPageURL[-1])
#print('url', url)
# 发送下一页请求并调用parse()函数继续解析
yield scrapy.Request(url, self.parse, dont_filter=False)
pass
else:
print("退出")
pass
items 对象
import scrapy class DoubanmovieItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
rank=scrapy.Field()
title=scrapy.Field()
quote=scrapy.Field()
star=scrapy.Field()
src=scrapy.Field()
pass
pipelines 输出管道
class DoubanmoviePipeline(object):
def process_item(self, item, spider):
print('电影排名:{0}'.format(item['rank'][0]))
print('电影名称:{0}'.format(item['title'][0]))
print('电影短评:{0}'.format(item['quote'][0]))
print('评价分数:{0}'.format(item['star'][0]))
print('评价人数:{0}'.format(item['star'][1]))
print('图片链接:{0}'.format(item['src']))
print('-' * 20)
return item
在控制台输出的结果
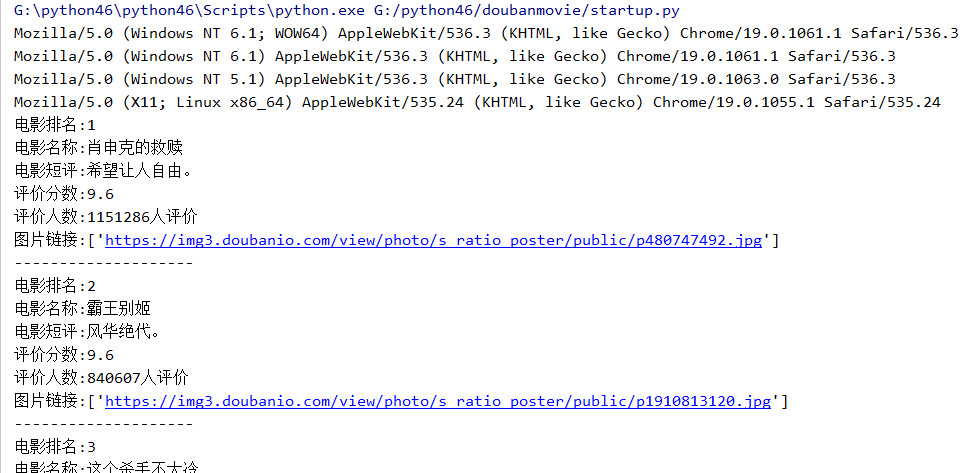
可以通过爬出的图片链接,下载电影的剧照,这就另说了,也可以设置一个插入数据库的管道,将这些数据插入到数据库中
Python的scrapy之爬取豆瓣影评和排名的更多相关文章
- 基于python的scrapy框架爬取豆瓣电影及其可视化
1.Scrapy框架介绍 主要介绍,spiders,engine,scheduler,downloader,Item pipeline scrapy常见命令如下: 对应在scrapy文件中有,自己增加 ...
- Scrapy 通过登录的方式爬取豆瓣影评数据
Scrapy 通过登录的方式爬取豆瓣影评数据 爬虫 Scrapy 豆瓣 Fly 由于需要爬取影评数据在来做分析,就选择了豆瓣影评来抓取数据,工具使用的是Scrapy工具来实现.scrapy工具使用起来 ...
- 【python数据挖掘】爬取豆瓣影评数据
概述: 爬取豆瓣影评数据步骤: 1.获取网页请求 2.解析获取的网页 3.提速数据 4.保存文件 源代码: # 1.导入需要的库 import urllib.request from bs4 impo ...
- Python爬虫实例:爬取豆瓣Top250
入门第一个爬虫一般都是爬这个,实在是太简单.用了 requests 和 bs4 库. 1.检查网页元素,提取所需要的信息并保存.这个用 bs4 就可以,前面的文章中已经有详细的用法阐述. 2.找到下一 ...
- [超详细] Python3爬取豆瓣影评、去停用词、词云图、评论关键词绘图处理
爬取豆瓣电影<大侦探皮卡丘>的影评,并做词云图和关键词绘图第一步:找到评论的网页url.https://movie.douban.com/subject/26835471/comments ...
- Python爬虫入门:爬取豆瓣电影TOP250
一个很简单的爬虫. 从这里学习的,解释的挺好的:https://xlzd.me/2015/12/16/python-crawler-03 分享写这个代码用到了的学习的链接: BeautifulSoup ...
- Python使用Scrapy框架爬取数据存入CSV文件(Python爬虫实战4)
1. Scrapy框架 Scrapy是python下实现爬虫功能的框架,能够将数据解析.数据处理.数据存储合为一体功能的爬虫框架. 2. Scrapy安装 1. 安装依赖包 yum install g ...
- Python的scrapy之爬取顶点小说网的所有小说
闲来无事用Python的scrapy框架练练手,爬取顶点小说网的所有小说的详细信息. 看一下网页的构造: tr标签里面的 td 使我们所要爬取的信息 下面是我们要爬取的二级页面 小说的简介信息: 下面 ...
- python爬虫scrapy框架——爬取伯乐在线网站文章
一.前言 1. scrapy依赖包: 二.创建工程 1. 创建scrapy工程: scrapy staratproject ArticleSpider 2. 开始(创建)新的爬虫: cd Artic ...
随机推荐
- 【NLP_Stanford课堂】正则表达式
或者 [Ww]oods,方括号里的是或的关系,符合其一即被提出.用来匹配单个字符 [A-Z]:表示所有的大写字母之一 [a-z]:表示所有的小写字母之一 [0-9]:表示所有的0-9的数字之一 否定: ...
- Java应用程序
示例: public class HelloWorld { public static void main(String[] args) { System.out.println("Hell ...
- June 08th 2017 Week 23rd Thursday
Life is like a beautiful melody, only the lyrics are messed up. 生命是首美丽的曲子,虽然歌词有些纠结. Now that we get ...
- jsonp跨域请求响应结果处理函数(python)
接口测试跨域请求接口用的jsonp,需要将回调函数里的json字符串提取出来. jsonp跨域请求的响应结果格式: callback_functionname(json字符串). #coding:ut ...
- NO.013-2018.02.18《鹊桥仙·纤云弄巧》宋代:秦观
鹊桥仙·纤云弄巧_古诗文网 鹊桥仙·纤云弄巧 宋代:秦观 纤云弄巧,飞星传恨,银汉迢迢暗度.金风玉露一相逢,便胜却人间无数.(度 通:渡)纤薄的云彩在天空中变幻多端,天上的流星传递着相思的愁怨,遥远无 ...
- 《机器学习实战》中贝叶斯分类中导入RSS源例子
跟着书中代码往下写在这里卡住了,考虑到可能还会有其他同学也遇到了这样的问题,记下来分享. 先吐槽一下,相信大部分网友在这里卡住的主要原因是伟大的GFW,所以无论是软件FQ还是肉身FQ的小伙伴们估计是无 ...
- 转 tcp协议里rst字段讲解
TCP协议的原理来谈谈rst复位攻击 http://russelltao.iteye.com/blog/1405349 几种TCP连接中出现RST的情况 https://blog.csdn.net/c ...
- 创建一个dynamics 365 CRM online plugin (十二) - Asynchronous Plugins
这篇是plugin的终结. 通过之前的11期我们应该发现了plugin其实学习起来不难. async plugin 是把plugin的功能async run起来. e.g. 我们之前做过的preOp ...
- App版本号定义与说明基础知识
版本控制比较普遍的三种命名格式 GNU 风格的版本号命名格式 主版本号 . 次版本号 [. 修正版本号 [. 编译版本号 ]] 示例 : 1.2.1, 2.0, 5.0.0 build-13124 W ...
- 手写数字识别的k-近邻算法实现
(本文为原创,请勿在未经允许的情况下转载) 前言 手写字符识别是机器学习的入门问题,k-近邻算法(kNN算法)是机器学习的入门算法.本文将介绍k-近邻算法的原理.手写字符识别问题分析.手写字符识别的k ...