Hadoop(11)-MapReduce概述和简单实操
1.MapReduce的定义

2.MapReduce的优缺点
优点


缺点

3.MapReduce的核心思想
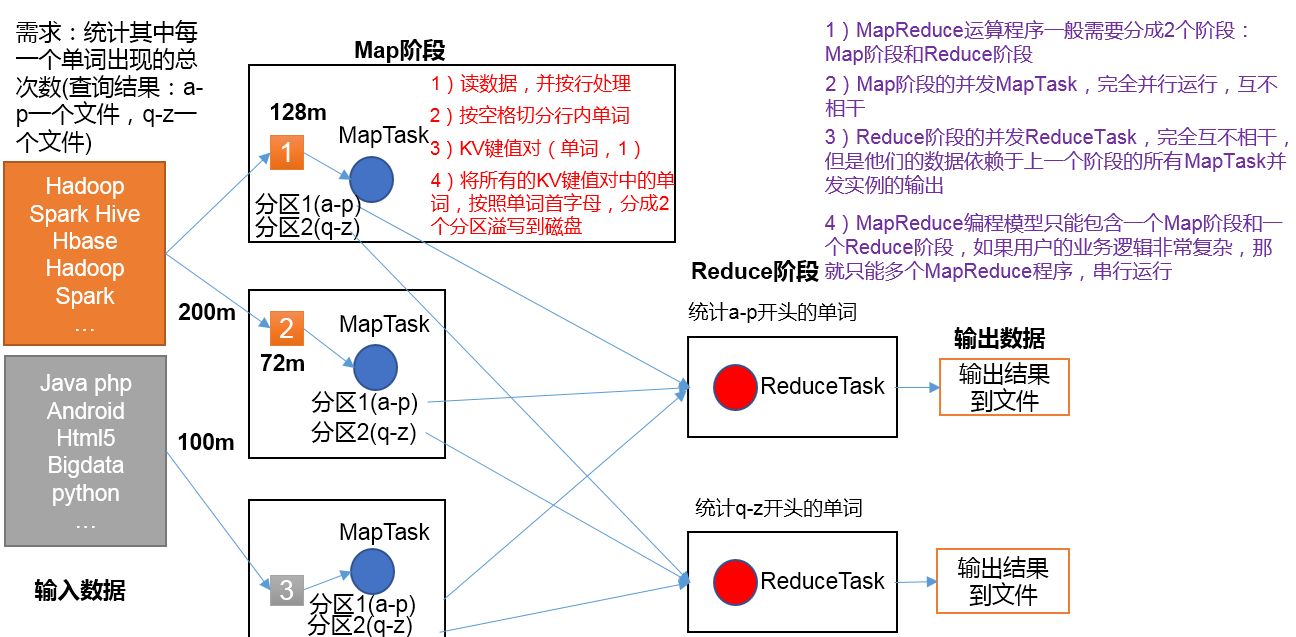
4.MapReduce进程

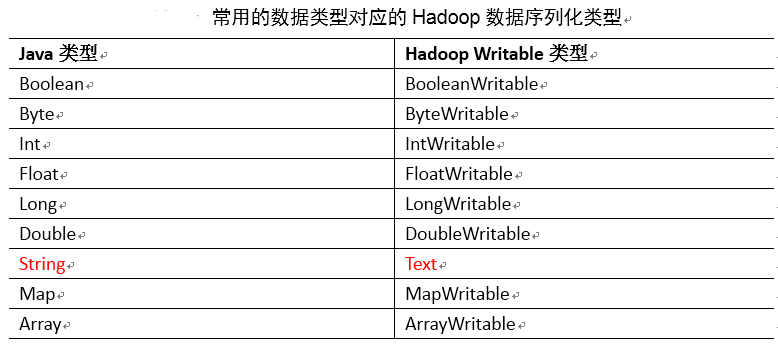
5.常用数据序列化类型
6.MapReduce的编程规范
用户编写的程序分成三个部分:Mapper、Reducer和Driver


7.WordCount简单操作
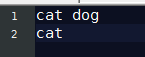
需求:在给定的文本文件中统计输出每一个单词出现的总次数
如一个类似这样的文件
Mapper类
package com.nty.wordcount; import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper; import java.io.IOException; /**
* author nty
* date time 2018-12-07 16:33
*/
//Mapper<KEYIN, VALUEIN, KEYOUT, VALUEOUT> 四个泛型分别表示,输入Key类型,输入Value类型,输出Key类型,输出Value类型
public class WcMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
//定义成员变量,节省堆内存
private Text key = new Text();
private IntWritable value = new IntWritable(1); @Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { String[] words = value.toString().split(" "); for (String word : words) {
this.key.set(word);
context.write(this.key,this.value); }
}
}
Reducer类
package com.nty.wordcount; import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer; import java.io.IOException; /**
* author nty
* date time 2018-12-07 16:34
*/
//Reducer<KEYIN,VALUEIN,KEYOUT,VALUEOUT> 四个泛型分别为,输入Key类型,输入Value类型,输出Key类型,输出Value类型
public class WcReducer extends Reducer<Text, IntWritable, Text, IntWritable> { private int sum; private IntWritable total = new IntWritable(); @Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
sum = 0; for (IntWritable value : values) {
sum += value.get();
}
this.total.set(sum);
context.write(key, this.total); }
}
Driver类
package com.nty.wordcount; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; /**
* author nty
* date time 2018-12-07 16:35
*/
public class WcDriver { public static void main(String[] args) throws Exception {
//1.获取配置信息和任务
Configuration configuration = new Configuration();
Job job = Job.getInstance(configuration);
//2.设置加载路径
job.setJarByClass(WcDriver.class);
//3.设置Mapper和Reducer
job.setMapperClass(WcMapper.class);
job.setReducerClass(WcReducer.class);
//4.设置map和reduce的输入输出类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//5.设置输入和输出路径
FileInputFormat.setInputPaths(job,new Path(args[0]));
FileOutputFormat.setOutputPath(job,new Path(args[1]));
//6 提交
boolean b = job.waitForCompletion(true);
System.exit(b ? 0 : 1);
} }
main方法的args

输出结果



Hadoop(11)-MapReduce概述和简单实操的更多相关文章
- 学以致用 | Redis概念与简单实操
Redis概念 Redis是一个由C语言编写.基于key-value存储结构的开源NoSQL数据库,其读写速度为10万次/秒,这个速度已经远远大于传统的关系型数据库. 使用场景 在高并发的情况下,可将 ...
- Python列表和字典的简单实操例子
# coding=utf-8 name_l = [] passwd_l = [] money_l = [] goods = {} index = 0 def input_user(): print(& ...
- Hadoop(十二)MapReduce概述
前言 前面以前把关于HDFS集群的所有知识给讲解完了,接下来给大家分享的是MapReduce这个Hadoop的并行计算框架. 一.背景 1)爆炸性增长的Web规模数据量 2)超大的计算量/计算复杂度 ...
- Hadoop基础-MapReduce入门篇之编写简单的Wordcount测试代码
Hadoop基础-MapReduce入门篇之编写简单的Wordcount测试代码 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 本文主要是记录一写我在学习MapReduce时的一些 ...
- 大数据技术之Hadoop(MapReduce)
第1章 MapReduce概述 1.1 MapReduce定义 1.2 MapReduce优缺点 1.2.1 优点 1.2.2 缺点 1.3 MapReduce核心思想 MapReduce核心编程思想 ...
- 【hadoop】MapReduce分布式计算框架原理
PS:实操部分就省略了哈,准备最近好好看下理论这块,其实我是比较懒得哈!!! <?>MapReduce的概述 MapReduce是一种计算模型,进行大数据量的离线计算.MapReduce实 ...
- HDFS集群PB级数据迁移方案-DistCp生产环境实操篇
HDFS集群PB级数据迁移方案-DistCp生产环境实操篇 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 用了接近2个星期的时间,终于把公司的需要的大数据组建部署完毕了,当然,在部 ...
- Hadoop(12)-MapReduce框架原理-Hadoop序列化和源码追踪
1.什么是序列化 2.为什么要序列化 3.为什么不用Java的序列化 4.自定义bean对象实现序列化接口(Writable) 在企业开发中往往常用的基本序列化类型不能满足所有需求,比如在Hadoop ...
- Hadoop学习笔记【Hadoop家族成员概述】
Hadoop家族成员概述 一.Hadoop简介 1.1 什么是Hadoop? Hadoop是一个分布式系统基础架构,由Apache基金会所开发,目前Yahoo!是其最重要的贡献者. Hadoop实现了 ...
随机推荐
- 安装lombok(eclipse)
下载 lombok.jar (https://projectlombok.org/download.html) 将 lombok.jar 放在eclipse安装目录下,和 eclipse.ini 文件 ...
- asyncio标准库7 Producer/consumer
使用asyncio.Queue import asyncio import random async def produce(queue, n): for x in range(1, n + 1): ...
- GridView的分页代码
1.前台代码 <PagerTemplate><div style="text-align:center; color:Blue"> <asp:Link ...
- sqlserver row_number函数的用法
ROW_NUMBER()函数将针对SELECT语句返回的每一行,从1开始编号,赋予其连续的编号 必须和over一起使用 select *,ROW_NUMBER() over(order by prod ...
- HTML <meta> Attribute
HTML <meta> Attribute http-equiv 定义和用法 The http-equiv attribute provides an HTTP header for th ...
- ORACLE_DELETE
SQL DELETE Statement The SQL DELETE Statement The DELETE statement is used to delete existing record ...
- 第五章 LED的魔性操作
想必大家都见过城市里漂亮的led广告牌吧,这一节我将带大家学习这些LED广告牌最基本的实现原理. 初识LED 接线方法:D1~D8从接23~37号数字端口,v1和前面的针头分别接41号和39号数字端口 ...
- Opportunity的chance of success的赋值逻辑
该字段的值和另外两个字段Sales Stage和Status都相关. 从下列function module CRM_OPPORT_H_PROB_SET_EC可看出,当status不为代码中的这些硬编码 ...
- 二维数组展示到DataGridView(c#)
窗体程序中二维数组展示到DataGridView public void TwoDArrayShowINDatagridview(string[,] arr) { DataTable dt = new ...
- 【转载】#446 - Deciding Between an Abstract Class and an Interface
An abstract class is a base class that may have some members not implemented in the base class, but ...