基于docker+redis++urlib/request的分布式爬虫原理
一.整体思路及中心节点的配置
1.首先在虚拟机中运行一个docker,docker中运行的是一个linux系统,里面有我们所有需要的东西,linux系统,python,mysql,redis以及一些python的库如request、urllib等,
最好把这个做成一个镜像文件
docker save -o 文文件名 镜像id
2.我们把上面的镜像文件还原为一个镜像:
docker load --input 文件名
3.docker images查看一下是否有多出来一个image
docker images
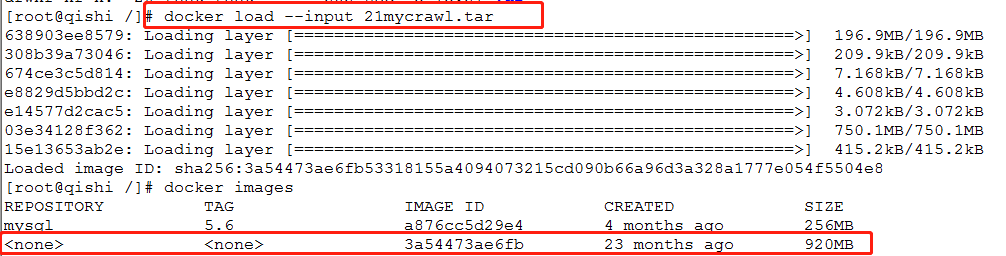
4.以这个镜像为基础创建新的docker(这个docker是作为center中心调度器,所有信息的读写都在这边,3a54是上面加载进来镜像的id)
docker run -tid --name center 3a54
5. 查看docker是否在运行
docker ps -a
6.进入容器并且查看这个docker的ip (center为docker的name)
docke attach center
cat /etc/hosts
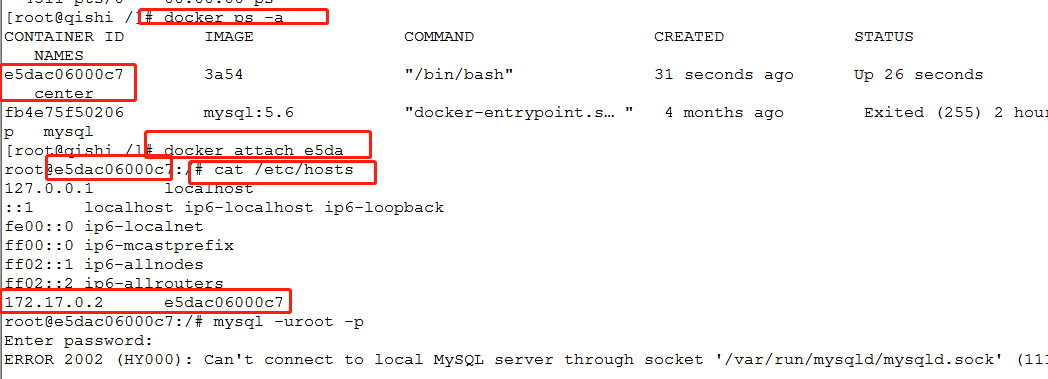
6.配置mysql
1.启动mysql
/etc/init.d/mysql restart 2.登录(以localhost、127.0.0.1成功登录)
mysql -u root -p
3.以本容器的ip登录(不能登录)
mysql -h 127.0.0.1 -u root -p
处理:
修改mysql的启动配置文件:
vim /etc/mysql/my.cnf #把bing 127.0.0.1这一行注释掉,这样一来他就不仅仅只监听本机的ip,外网ip也会监听
4.再次重启(修改过配置文件,要以新的配置启动)
/etc/init.d/mysql restart 5.重复第三步(修改丙丁ip后还是不能登录)
mysql -h 127.0.0.1 -u root -p


6.以root 身份以本机登录后创建新的用户(这是因为root用户不允许远程登录,所以需要创建普通用户)
mysql -h 127.0.0.1 -u root -p
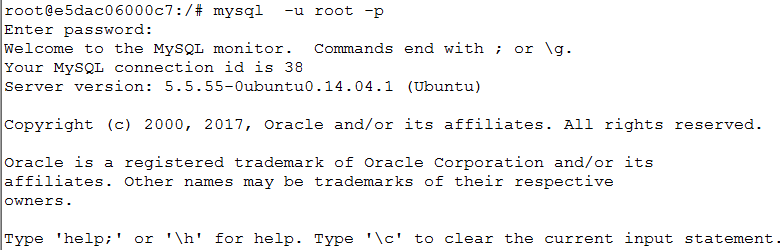
7.创建用户配置权限
create user "tom"@"%" identified by "tom";
grant create,delete,update,select,insert on *.* to tom;

8.退出mysq,再用普通用户,本机ip登录
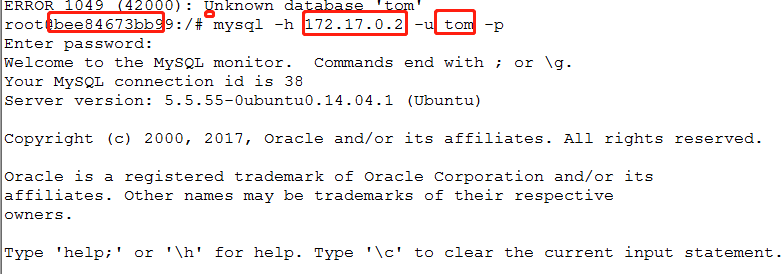
mysql -h 172.17.0.2 -u tom -p
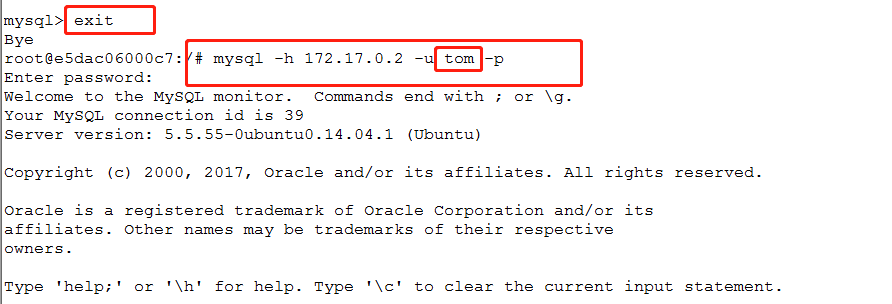
总结:
1.修改配置文件的bind
2。创建普通用户
7. 配置redis
1.启动redis
/etc/init.d/resdis-server
2.连接redis
redis-cli
3.以本机ip连接
redis-cli -h 172.17.0.2 #不成功
4.修改配置文件
vim /etc/redis/redis.conf
#同样把bind 127.0.0.1给注释掉
5.重启
/etc/init.d/resdis-server
6.再用本机ip登录
redis-cli -h 172.17.0.2 #不成功
7.退出容器
ctrl+P+q
8.停止容器
docker stop e5da
9.再次开启容器
docker start e5da
10.进入容器
docker attach e5da
11.重启redis
/etc/init.d/resdis-server
12.再次以本机ip登录 redis-cli -h 172.17.0.2 #成功
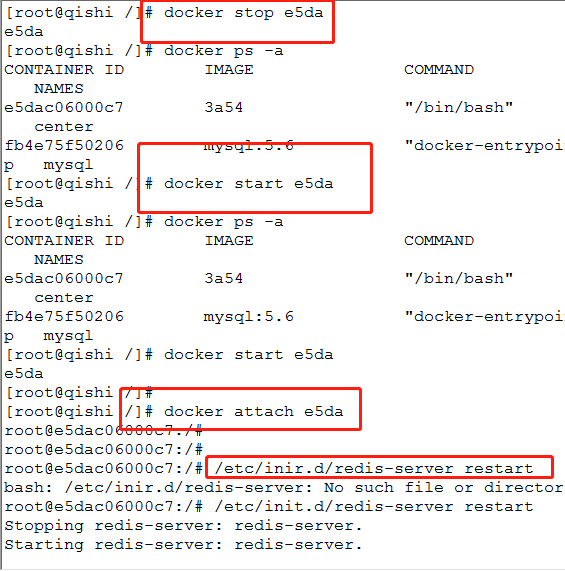

总结:
1.修改配置文件,修改绑定的端口 #bind 127.0.0.1 注释
2.重启容器
1.一定要以ctrl+p+q退出
2.docker stop id
3.docker start id
4.docker attach id
5.启动redis
6.连接redis redis-cli
二.子节点的配置
1.退出中心节点的容器(不停止运行)
crtrl + p + q
2.创建子节点并且进入
#创建名为c1的自己节点,并且连接到center这个节点的docker,以3a54(和中心节点一样)的镜像创建
docker run -tid --name c1 ---link center 3a54
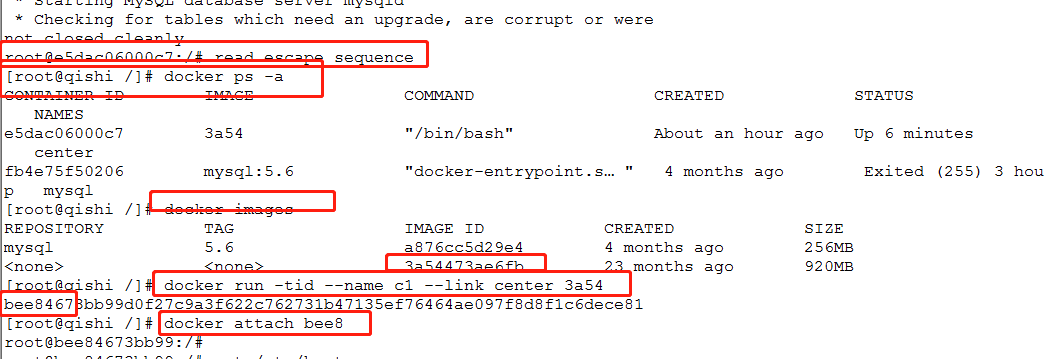
3.查看本机ip和连接主机的ip
cat /etc/hosts
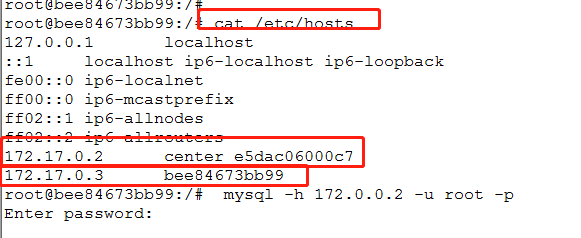
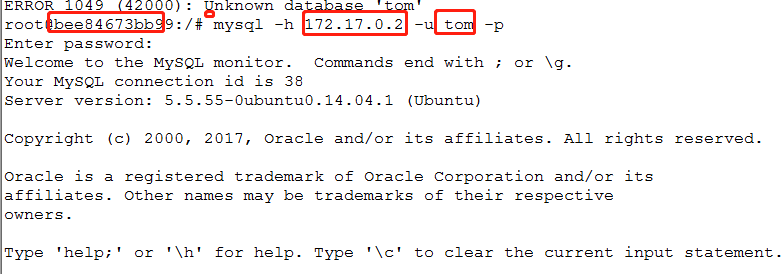
4.测试子节点和中心节点的连通
#就是在子节点下用中心节点的ip和用户连接中心节点的数据库,都没问题 mysql -h 172.17.0.2 -u tom -p
redis-cli -h 172.17.0.2
三.在子节点编写爬虫文件
编写爬虫文件并且测试可以进行
import redis
import pymysql
import urllib.request
import re
#这里的ip是中心节点的ip
rconn=redis.Redis("172.17.0.8","")
#url:http://www.17k.com/book/2.html
'''
url-i-"1"
'''
for i in range(0,5459058):
#先判断url是否怕取过进行过就过掉
isdo=rconn.hget("url",str(i))
if(isdo!=None):
continue
#没有爬取就,做个标志并且进爬取
rconn.hset("url",str(i),"")
try:
data=urllib.request.urlopen("http://www.17k.com/book/"+str(i)+".html").read().decode("utf-8","ignore")
except Exception as err:
print(str(i)+str(err))
continue
pat='<a class="red" .*?>(.*?)</a>
'
rst=re.compile(pat,re.S).findall(data)
if(len(rst)==0):
continue
name=rst[0]
rconn.hset("rst",str(i),str(name))
四.增加子节点
1.退出子节点容器并且停止容器运行
exit
2.把上面子节点容器封装成一个镜像
#docker commit 容器id 名称:tag
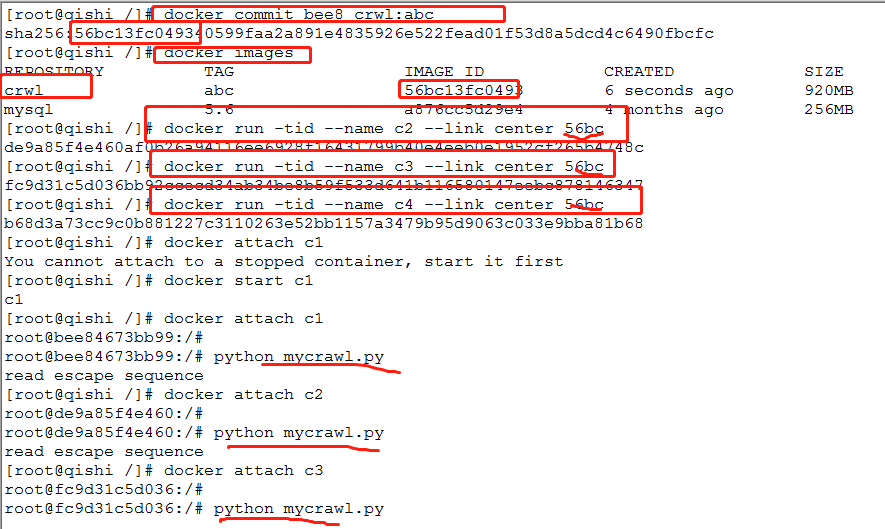
docker commit bee8 crwl:abc
3.用子节点容器鞥装好的镜像创建新的docker
docker run -tid --name c2 --link center 56bc
docker run -tid --name c3 --link center 56bc
docker run -tid --name c4 --link center 56bc
4.分别进入子节点编写爬虫文件并且启动
基于docker+redis++urlib/request的分布式爬虫原理的更多相关文章
- 基于 Scrapy-redis 两种形式的分布式爬虫
基于 Scrapy-redis 两种形式的分布式爬虫 .caret, .dropup > .btn > .caret { border-top-color: #000 !important ...
- Python分布式爬虫原理
转载 permike 原文 Python分布式爬虫原理 首先,我们先来看看,如果是人正常的行为,是如何获取网页内容的. (1)打开浏览器,输入URL,打开源网页 (2)选取我们想要的内容,包括标题,作 ...
- 基于Redis的三种分布式爬虫策略
前言: 爬虫是偏IO型的任务,分布式爬虫的实现难度比分布式计算和分布式存储简单得多. 个人以为分布式爬虫需要考虑的点主要有以下几个: 爬虫任务的统一调度 爬虫任务的统一去重 存储问题 速度问题 足够“ ...
- 基于Python使用scrapy-redis框架实现分布式爬虫
1.首先介绍一下:scrapy-redis框架 scrapy-redis:一个三方的基于redis的分布式爬虫框架,配合scrapy使用,让爬虫具有了分布式爬取的功能.github地址: https: ...
- 17.基于scrapy-redis两种形式的分布式爬虫
redis分布式部署 1.scrapy框架是否可以自己实现分布式? - 不可以.原因有二. 其一:因为多台机器上部署的scrapy会各自拥有各自的调度器,这样就使得多台机器无法分配start_urls ...
- 基于scrapy-redis两种形式的分布式爬虫
redis分布式部署 1.scrapy框架是否可以自己实现分布式? - 不可以.原因有二. 其一:因为多台机器上部署的scrapy会各自拥有各自的调度器,这样就使得多台机器无法分配start_urls ...
- 17,基于scrapy-redis两种形式的分布式爬虫
redis分布式部署 1.scrapy框架是否可以自己实现分布式? - 不可以.原因有二. 其一:因为多台机器上部署的scrapy会各自拥有各自的调度器,这样就使得多台机器无法分配start_urls ...
- Redis、Zookeeper实现分布式锁——原理与实践
Redis与分布式锁的问题已经是老生常谈了,本文尝试总结一些Redis.Zookeeper实现分布式锁的常用方案,并提供一些比较好的实践思路(基于Java).不足之处,欢迎探讨. Redis分布式锁 ...
- 基于(Redis | Memcache)实现分布式互斥锁
设计一个缓存系统,不得不要考虑的问题就是:缓存穿透.缓存击穿与失效时的雪崩效应. 缓存击穿 缓存穿透是指查询一个一定不存在的数据,由于缓存是不命中时被动写的,并且出于容错考虑,如果从存储层查不到数据则 ...
随机推荐
- Windows下用Nginx配置遇到的问题
Nginx是一款轻量级的web服务器/反向代理服务器,更详细的释义自己百度了.目前国内像新浪.网易等都在使用它.先说下我的服务器软件环境: 系统:Windows Server + IIS + ngin ...
- Flask 之 上下文管理
Flask上下文管理 分类: 请求上下文管理 应用上下文管理 请求上下文管理 request a. 温大爷:wsig b. 赵毅: ctx = ReuqestContext(session,reque ...
- c# 常规验证基类
using System;using System.Collections.Generic;using System.Linq;using System.Text.RegularExpressions ...
- Part10-C语言环境初始化-栈初始化lesson1
1.概念解析 ARM系统使用的是满栈! ARM采用降栈!!! 栈帧 每一个进程会有一个栈,该进程中的每一个函数会分割栈的一部分,那么每一个函数使用的那部分栈就叫做栈帧.那么所有栈帧组成了整个栈. 子函 ...
- Java反射学习:深入学习Java反射机制
一.Java反射的理解(反射是研究框架的基础之一) Java反射机制是在运行状态中,对于任意一个类,都能够知道这个类的所有属性和方法:对于任意一个对象,都能够调用它的任意一个方法和属性:这种动态获取的 ...
- word 2013如何从某一页开始插入页码
把光标移入要插入页面的最前面 插入分页符 在要插入页码的页脚双击打开页脚设计 取消页脚和前面页眉的链接 插入页码
- MongoDB整理笔记のMapReduce
MongDB的MapReduce相当于MySQL中的“group by”,所以在MongoDB上使用Map/Reduce进行并行“统计”很容易. 使用MapReduce要实现两个函数Map函数和Red ...
- create-react-app设置proxy反向代理不起作用
在CRA2.X升级以后对proxy的设置做了修改,引用官方升级文档: Object proxy configuration is superseded by src/setupProxy.js To ...
- TriggerAction扩展----ExInvokeCommandAction
Wp&Win8中使用命令绑定时,除了Button控件自带命令绑定,其他的时候是用Interactivity库中的InvokeCommandAction实现的(Win8 需要额外安装第三方NuG ...
- 教你如何选择BI数据可视化工具
本文来自网易云社区. 关于如何选择BI数据可视化工具,总体而言,主流BI产品在选择的时候要除了需要考虑从数据到展现.从公司内到公司外等各种场景,结合前面朋友的回答,还需要考虑以下几点:1:以后的数据处 ...