吴恩达深度学习笔记(七) —— Batch Normalization
主要内容:
一.Batch Norm简介
二.归一化网络的激活函数
三.Batch Norm拟合进神经网络
四.测试时的Batch Norm
一.Batch Norm简介
1.在机器学习中,我们一般会对输入数据进行归一化处理,使得各个特征的数值规模处于同一个量级,有助于加速梯度下降的收敛过程。
2.在深层神经网络中,容易出现梯度小时或者梯度爆炸的情况,导致训练速度慢。那么,除了对输入数据X进行归一化之外,我们是否还可以对隐藏层的输出值进行归一化,从而加速梯度下降的收敛速度呢?答案是可以的。
3.Batch Norm,即基于mini-batch gradient descent的归一化,将其应用于深层神经网络。
二..归一化网络的激活函数
1.一般地,我们并非对a[0](a[0]即输入值X)、a[1]、a[2]……等进行归一化,而是对z[1]、z[2]……等进行归一化(没有z[0])。
2.对于第l层的某个batch数据,计算出z[l]的均值和方差,然后对其进行归一化,使其均值为0,方差为1:
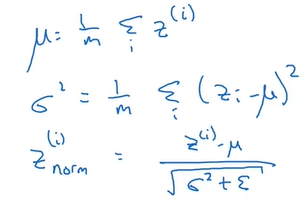 (注意,z的上标i表示数据,而非层数。在课程中层数使用中括号[],这里不标示层数是为了简便。)
(注意,z的上标i表示数据,而非层数。在课程中层数使用中括号[],这里不标示层数是为了简便。)
3.但是,我们不总希望隐藏单元总是含有均值为0,方差为1,也许隐藏单元有了不同的分布会有意义。(这里没能想明白,大概的意思是:如果总是“均值为0,方差为1”,那么深层神经网络的表示能力就减弱。)所以就再对其进行缩放和平移:

其中,β、γ是需要学习的参数。所以总的来说,需要学习四类参数:w、b、β、γ。
三.Batch Norm拟合进神经网络
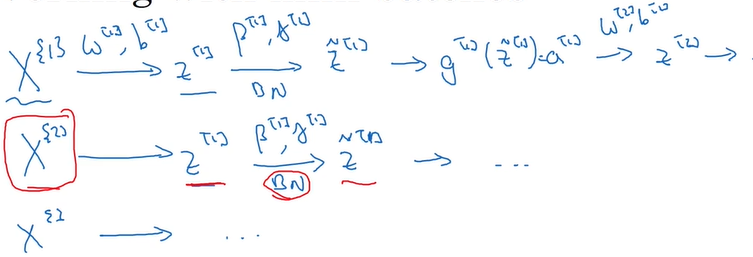
1.在一次梯度下降中(用的batch可能不同),z[1]、z[2]……的均值和方差可能一直在变化,所以对于第l层,需要重新计算z[l]的均值和方差,然后再对其归一化
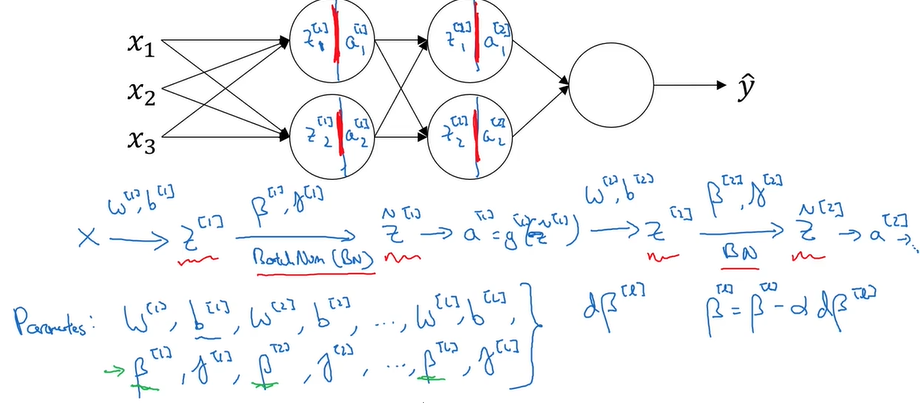
2.当进行了一次梯度下降之后,就利用下一个batch继续梯度下降(大括号标示batch):
四.测试时的Batch Norm
由于每一层中z的均值和方差在每一次梯度下降时都是变化的(与平常的机器学习的不同,机器学习中只需对输入数据X进行归一化,X的均值和方差是恒定的),所以在测试时,用哪个均值和方差进行归一化就成了一个问题。
解决方法是:在训练的过程中,利用指数加权平均去追踪和计算,最终得到用于测试数据的均值和方差。
吴恩达深度学习笔记(七) —— Batch Normalization的更多相关文章
- 【Deeplearning.ai 】吴恩达深度学习笔记及课后作业目录
吴恩达深度学习课程的课堂笔记以及课后作业 代码下载:https://github.com/douzujun/Deep-Learning-Coursera 吴恩达推荐笔记:https://mp.weix ...
- 吴恩达深度学习笔记(八) —— ResNets残差网络
(很好的博客:残差网络ResNet笔记) 主要内容: 一.深层神经网络的优点和缺陷 二.残差网络的引入 三.残差网络的可行性 四.identity block 和 convolutional bloc ...
- 吴恩达深度学习笔记(十二)—— Batch Normalization
主要内容: 一.Normalizing activations in a network 二.Fitting Batch Norm in a neural network 三.Why does ...
- 吴恩达深度学习笔记(deeplearning.ai)之卷积神经网络(二)
经典网络 LeNet-5 AlexNet VGG Ng介绍了上述三个在计算机视觉中的经典网络.网络深度逐渐增加,训练的参数数量也骤增.AlexNet大约6000万参数,VGG大约上亿参数. 从中我们可 ...
- 吴恩达深度学习笔记(deeplearning.ai)之卷积神经网络(CNN)(上)
作者:szx_spark 1. Padding 在卷积操作中,过滤器(又称核)的大小通常为奇数,如3x3,5x5.这样的好处有两点: 在特征图(二维卷积)中就会存在一个中心像素点.有一个中心像素点会十 ...
- 吴恩达深度学习笔记(deeplearning.ai)之循环神经网络(RNN)(三)
1. 导读 本节内容介绍普通RNN的弊端,从而引入各种变体RNN,主要讲述GRU与LSTM的工作原理. 事先声明,本人采用ng在课堂上所使用的符号系统,与某些学术文献上的命名有所不同,不过核心思想都是 ...
- 吴恩达深度学习笔记(五) —— 优化算法:Mini-Batch GD、Momentum、RMSprop、Adam、学习率衰减
主要内容: 一.Mini-Batch Gradient descent 二.Momentum 四.RMSprop 五.Adam 六.优化算法性能比较 七.学习率衰减 一.Mini-Batch Grad ...
- 吴恩达深度学习笔记(deeplearning.ai)之卷积神经网络(一)
Padding 在卷积操作中,过滤器(又称核)的大小通常为奇数,如3x3,5x5.这样的好处有两点: 在特征图(二维卷积)中就会存在一个中心像素点.有一个中心像素点会十分方便,便于指出过滤器的位置. ...
- 吴恩达深度学习笔记1-神经网络的编程基础(Basics of Neural Network programming)
一:二分类(Binary Classification) 逻辑回归是一个用于二分类(binary classification)的算法.在二分类问题中,我们的目标就是习得一个分类器,它以对象的特征向量 ...
随机推荐
- PHPStorm2017去掉参数提示 parameter name hints
JetBrains 的各种语言的 IDE 都灰常灰常好用, 个个都是神器, PHPStorm 作为PHP开发的神器也不必多说了 今天升级到 PHPStorm 2017.1 发现增加了好些新功能, 有个 ...
- SQL Server 还原错误“restore database正在异常终止 错误 3154”
今天在还原数据库时,先建立相同名字的数据库,然后在该数据库上右键还原数据库.遇到了这样的一个错误: “备份集中的数据库备份与现有的 'RM_DB' 数据库不同. RESTORE DATABASE 正在 ...
- Kotlin——初级篇(二):变量、常量、注释
在Kotlin中的变量.常量以及注释多多少少和Java语言是有着不同之处的.不管是变量.常量的定义方式,还是注释的使用.下面详细的介绍Kotlin中的变量.常量.注释的使用.以及和Java的对比. 如 ...
- Java+selenium自动化测试基础
Java+selenium maven配置 maven的配置,但还需要建立maven的本地库,修改apach-maven的setting.xml http://www.cnblogs.com/haoa ...
- 1052 最大M子段和(DP)
1052 最大M子段和 基准时间限制:2 秒 空间限制:131072 KB 分值: 80 难度:5级算法题 N个整数组成的序列a[1],a[2],a[3],…,a[n],将这N个数划分为互不相交的M个 ...
- sublime Text的一些用法(emmet插件、)
在学的过程中,看到了一个非常方便的html的标签的写法:,插件emmet 一.安装emmet 看清楚哦~~这是Sublime text 3不是2的版本,两者的安装还是有区别的1 ONE:建议到官方下载 ...
- python系列十二:python3模块
#!/usr/bin/python # This Python file uses the following encoding: gbk #Python3 模块 '''用 python 解释器来编程 ...
- JavaScript-onerror事件:图片加载失败后不显示
HTML: <img src="http://www.mazey.net/images/upload/image/20170518/1495122198180663.gif" ...
- MySql存储过程、函数
存储过程和函数是在数据库中定义一些SQL语句的集合,然后直接调用这些存储过程和函数来执行已经定义好的SQL语句.存储过程和函数可以避免开发人员重复的编写相同的SQL语句.而且,存储过程和函数是在MyS ...
- (4.14)存储:RAID在数据库存储上的应用
关键词:(4.14)存储:RAID在数据库存储上的应用 转自:http://blog.51cto.com/qianzhang/1251260 随着单块磁盘在数据安全.性能.容量上呈现出的局限,磁盘阵列 ...