爬虫——正则表达式re模块
为什么要学习正则表达式
实际上爬虫一共就四个主要步骤:
- 明确目标:需清楚目标网站
- 爬:将所有的目标网站的内容全部爬下来
- 取:在爬下来的网站内容中去掉对我们没有用处的数据,只留取我们需要的数据
- 处理数据:按照我们想要的方式存储和使用留取的数据
我们在前面的案例里实际上都省略了第3步,也就是“取”的步骤。因为我们down下了的数据是全部的网页,这些数据很庞大并且很混乱,其中大部分的东西是我们不关心的,因此我们需要将之按我们的需要过滤和匹配出来。
那么对于文本的过滤和者规则的匹配,最强大的就是正则表达式了。
那么什么是正则表达式:
- 正则表达式,又称规则表达式,通常被用来检索、替换那些符合某个规则的文本。
- 正则表达式是对字符串操作的一种逻辑公式,就是用事先定义好的一些特定字符及这些特定字符的组合,组成一个“规则字符串”,这个“规则字符串”用来表达对字符串的一种过滤逻辑。
给定一个正则表达式和另一个字符串,我们可以达到如下的目的:
- 给定的字符串是否符合正则表达式的过滤逻辑(“匹配”)
- 通过正则表达式,从文本字符串中获取我们想要的特定部分(“过滤”)
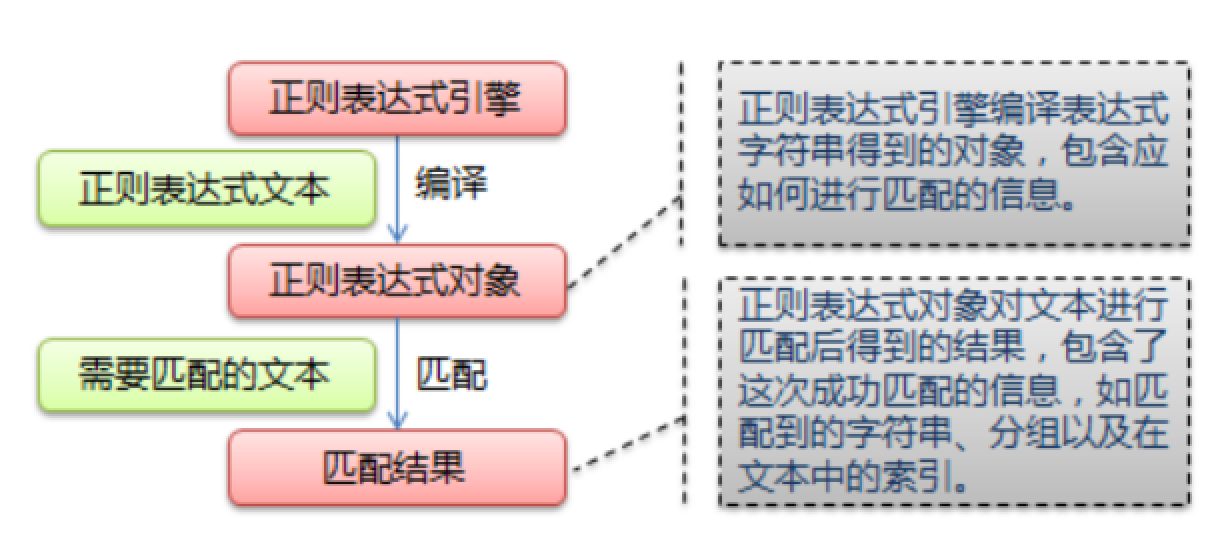
正则表达式规则
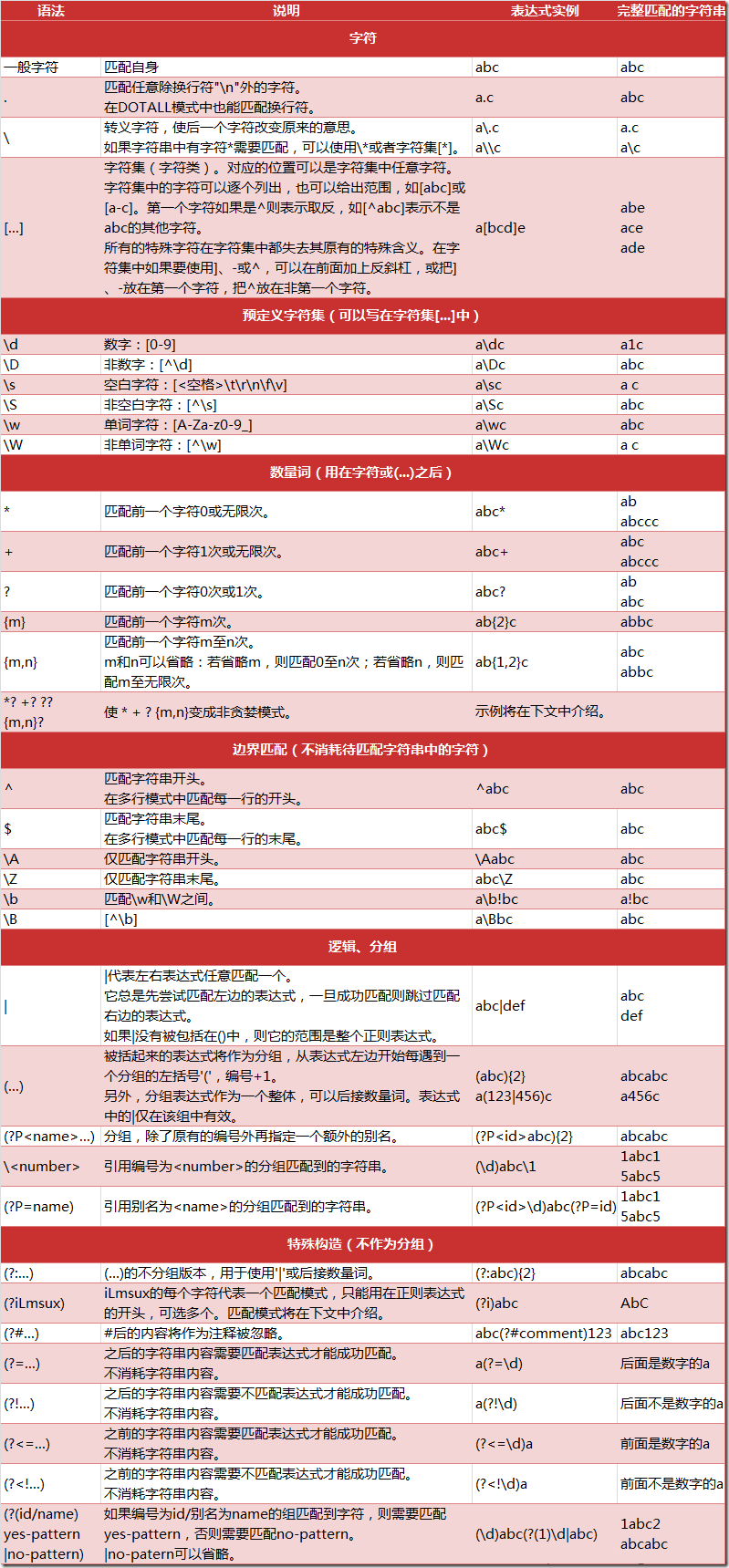
Python的re模块
在Python中,我们可以使用内置的re模块来使用正则表达式。
有一点需要特别注意的是,正则表达式使用对特殊字符进行黑底,所以如果我们要使用原始字符串,只需要加一个r前缀:r'i love\t\.\tpython'
re模块的一般使用步骤如下:
- 使用compile()函数将正则表达式的字符串形式编译为一个Pattern对象
- 通过Pattern对象提供的一系列方法对文本进行匹配查找,获得匹配结果,一个Match对象。
- 最后使用Match对象提供的属性和方法获得信息,根据需要进行其他操作。
compile函数
compile函数用于编译正则表达式,生成一个Pattern对象,它的一般使用形式如下:
#!/usr/bin/python3
# -*- coding:utf-8 -*-
__author__ = 'mayi' import re # 将正则表达式编译成Pattern对象
pattern = re.compile('\d+')
在上面,我们已将一个正则表达式编译成Pattern对象,接下来,我们就可以利用pattern的一系列方法对文本匹配查找了。
Pattern对象的一些常用方法主要有:
- match()方法:从起始位置开始查找,一次匹配
- search()方法:从任何位置开始查找,一次匹配
- findall()方法:全部匹配,返回列表
- finditer()方法:全部匹配,返回迭代器
- split()方法:分割字符串,返回列表
- sub()方法:替换
match()方法
match()方法用于查找字符串的头部(也可以指定起始位置),它是一次匹配,只要找到了一个匹配的结果就返回,而不是查找所有匹配的结果。它的一般使用形式如下:
match(string[, pos[, endpos]])
其中,string是待匹配的字符串,pos和endpos是可选参数,指定字符串的起始和终点位置,默认值分别是0和len(string)。因此,当你不指定pos和endpos时,match()方法默认匹配字符串的头部。
当匹配成功时,返回一个Match对象,如果没有匹配上,则返回None。
>>> import re
>>> pattern = re.compile(r'\d+') # 用于匹配至少一个数字 >>> m = pattern.match('one12twothree34four') # 查找头部,没有匹配
>>> print m
None >>> m = pattern.match('one12twothree34four', 2, 10) # 从'e'的位置开始匹配,没有匹配
>>> print(m)
None >>> m = pattern.match('one12twothree34four', 3, 10) # 从'1'的位置开始匹配,正好匹配
>>> print(m) # 返回一个 Match 对象
<_sre.SRE_Match object; span=(3, 5), match='12'> >>> print(m.group(0)) # 可省略 0
12
>>> print(m.start(0)) # 可省略 0
3
>>> print(m.end(0)) # 可省略 0
5
>>> print(m.span(0)) # 可省略 0
(3, 5)
在上面,当匹配成功时返回一个Match对象,其中:
- group([group1,...])方法用于获得一个或多个分组匹配的字符串,当要获得整个匹配的子串时,可直接使用group()或group(0)
- start([group])方法用于获取分组匹配的子串在整个字符串中的起始位置(子串第一个字符的索引),参数默认值为0
- end([group])方法用于获取分组匹配的子串在整个字符串中的结束位置(子串最后一个字符的索引 + 1),参数默认值为0
- span([group])方法返回(start(group), end(group))
再看一个例子:
>>> import re
>>> pattern = re.compile(r'([a-z]+) ([a-z]+)', re.I) # re.I 表示忽略大小写
>>> m = pattern.match('Hello World Wide Web') >>> print(m) # 匹配成功,返回一个 Match 对象
<_sre.SRE_Match object; span=(0, 11), match='Hello World'> >>> print(m.group(0)) # 返回匹配成功的整个子串
Hello World >>> print(m.span(0)) # 返回匹配成功的整个子串的索引
(0, 11) >>> print(m.group(1)) # 返回第一个分组匹配成功的子串
Hello >>> print(m.span(1)) # 返回第一个分组匹配成功的子串的索引
(0, 5) >>> print(m.group(2)) # 返回第二个分组匹配成功的子串
World >>> print(m.span(2)) # 返回第二个分组匹配成功的子串
(6, 11) >>> print(m.groups()) # 等价于 (m.group(1), m.group(2), ...)
('Hello', 'World') >>> print(m.group(3)) # 不存在第三个分组
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
IndexError: no such group
search()方法
search()方法用于查找字符串的任何位置,它也是一次匹配,只要找到了一个匹配的结果就返回,而不是查找所有匹配的结果,它的一般使用形式如下:
search(string[, pos[, endpos]])
其中,string是待匹配的字符串,pos和endpos是可选参数,指定字符串的起始和终点位置,默认值分别是0和len(string)。
当匹配成功时,返回一个Match对象,如果没有匹配上,则返回None。
如下例子:
>>> import re
>>> pattern = re.compile('\d+')
>>> m = pattern.search('one12twothree34four')
>>> print(m)
<_sre.SRE_Match object; span=(3, 5), match='12'>
>>> print(m.group())
12
>>> m = pattern.search('one12twothree34four', 10, 30)
>>> print(m)
<_sre.SRE_Match object; span=(13, 15), match='34'>
>>> print(m.group())
34
>>> print(m.span())
(13, 15)
再看一个例子:
#!/usr/bin/python3
# -*- coding:utf-8 -*-
__author__ = 'mayi' import re # 将正则表达式编译成Pattern对象
pattern = re.compile(r'\d+') # 使用search() 查找匹配的子串,不存在匹配的子串时,返回None
m = pattern.search('hello 123 456 789') # 若这里使用match(),返回None if m:
print("matching string:", m.group())
print("position:", m.span())
执行结果:
matching string: 123
position: (6, 9)
findall()方法
上面的match()和search()方法都是一次匹配,只要找到了一个匹配的结果就返回。然而,在大多数时候,我们需要搜索整个字符串,获得所有匹配的结果。
findall()方法的使用形式如下:
findall(string[, pos[, endpos]])
其中,string是待匹配的字符串,pos和endpos是可选参数,指定字符串的起始和终点位置,默认值分别是0和len(string)。
findall()以列表形式返回全部能匹配的子串,如果没有匹配成功,则返回一个空列表。
如下:
>>> import re
>>> pattern = re.compile(r'\d+') # 匹配数字
>>> res1 = pattern.findall('hello 123 456 789')
>>> res2 = pattern.findall('one1two2three3four4', 0, 16)
>>> print(res1)
['123', '456', '789']
>>> print(res2)
['1', '2', '3']
再看一个例子:
>>> import re
>>> pattern = re.compile(r'\d+\.\d+') # 匹配小数
>>> res = pattern.findall("3.1415926, 'big', 110, 95.5")
>>> print(res)
['3.1415926', '95.5']
finditer()方法
finditer()方法的行为跟findall()的行为类似,也是搜索整个字符串,获得所有匹配的结果。但它返回一个顺序访问每一个匹配结果(Match对象)的迭代器。
如下:
#!/usr/bin/python3
# -*- coding:utf-8 -*-
__author__ = 'mayi' import re pattern = re.compile(r'\d+') res_iter1 = pattern.finditer("hello 123 456 789")
res_iter2 = pattern.finditer("one1two2three3four4", 0, 16) print(res_iter1)
print(res_iter2) print("res_iter1......")
for m1 in res_iter1:
print("matching string:{}, position:{}".format(m1.group(), m1.span())) print("res_iter2......")
for m2 in res_iter2:
print("matching string:{}, position:{}".format(m2.group(), m2.span()))
执行结果:
<callable_iterator object at 0x00ADF7F0>
<callable_iterator object at 0x00ADF230>
res_iter1......
matching string:123, position:(6, 9)
matching string:456, position:(10, 13)
matching string:789, position:(14, 17)
res_iter2......
matching string:1, position:(3, 4)
matching string:2, position:(7, 8)
matching string:3, position:(13, 14)
split()方法
spilt()方法按照能够匹配的子串将字符串分割后返回列表,它的使用形式如下:
split(string[, maxsplit])
其中,maxsplit用于指定最大分割次数,不指定将全部分割。
如下:
>>> import re
>>> pattern = re.compile(r'[\s\,\;]+')
>>> print(pattern.split('a,b;; c d'))
['a', 'b', 'c', 'd']
sub()方法
sub()方法用于替换。它的使用形式如下:
sub(repl, string[, count])
其中,repl可以是字符串也可以是一个函数:
- 如果repl是字符串,则会使用repl去替换字符串每一个匹配的子串,并返回替换后的字符串,另外,repl还可以使用id的形式来引用分组,但不能使用编号0
- 如果repl是函数,这个方法应当只接受一个参数(Match对象),并返回一个字符串用于替换(返回的字符串中不能再引用分组)
- count用于指定最多替换次数,默认全部替换
如下:
#!/usr/bin/python3
# -*- coding:utf-8 -*-
__author__ = 'mayi' import re pattern = re.compile(r'(\w+) (\w+)') # \w: [A-Za-z0-9] string = 'hello 123, hello 456' print(pattern.sub('hello world', string))
# 我是分割线
print("*" * 30) print(pattern.sub(r'\2 \1', string)) # 我是分割线
print("*" * 30) def func(m):
return 'hi ' + m.group(2) print(pattern.sub(func, string)) # 我是分割线
print("*" * 30) # 最多替换一次
print(pattern.sub(func, string, 1))
执行结果:
hello world, hello world
******************************
123 hello, 456 hello
******************************
hi 123, hi 456
******************************
hi 123, hello 456
匹配中文
在某些情况下,我们想匹配文本中的汉字,中文的unicode编码范围主要在[u4e00-u9fa5],这里说主要是因为这个范围并不完整,比如没有包括全角(中文)标点,不过,在大部分情况下,应该是够用的。
例如:要想把字符串s = "您好,世界。hello world!"中的中文提取出来,可以这么做
#!/usr/bin/python3
# -*- coding:utf-8 -*-
__author__ = 'mayi' import re string = "你好,世界。hello world!" pattern = re.compile(r"[\u4e00-\u9fa5]+") res = pattern.findall(string) print(res)
执行结果
['你好', '世界']
爬虫——正则表达式re模块的更多相关文章
- python爬虫主要就是五个模块:爬虫启动入口模块,URL管理器存放已经爬虫的URL和待爬虫URL列表,html下载器,html解析器,html输出器 同时可以掌握到urllib2的使用、bs4(BeautifulSoup)页面解析器、re正则表达式、urlparse、python基础知识回顾(set集合操作)等相关内容。
本次python爬虫百步百科,里面详细分析了爬虫的步骤,对每一步代码都有详细的注释说明,可通过本案例掌握python爬虫的特点: 1.爬虫调度入口(crawler_main.py) # coding: ...
- Python爬虫之urllib模块1
Python爬虫之urllib模块1 本文来自网友投稿.作者PG,一个待毕业待就业二流大学生.玄魂工作室未对该文章内容做任何改变. 因为本人一直对推理悬疑比较感兴趣,所以这次爬取的网站也是平时看一些悬 ...
- python 正则表达式re模块
#####################总结############## 优点: 灵活, 功能性强, 逻辑性强. 缺点: 上手难,旦上手, 会爱上这个东西 ...
- python基础之正则表达式 re模块
内容梗概: 1. 正则表达式 2. re模块的使⽤ 3. 一堆练习正则表达式是对字符串串操作的一种逻辑公式. 我们一般使用正则表达式对字符串进行匹配和过滤.使用正则的优缺点: 优点: 灵活,功能性强, ...
- 第三百二十五节,web爬虫,scrapy模块标签选择器下载图片,以及正则匹配标签
第三百二十五节,web爬虫,scrapy模块标签选择器下载图片,以及正则匹配标签 标签选择器对象 HtmlXPathSelector()创建标签选择器对象,参数接收response回调的html对象需 ...
- Python爬虫练习(requests模块)
Python爬虫练习(requests模块) 关注公众号"轻松学编程"了解更多. 一.使用正则表达式解析页面和提取数据 1.爬取动态数据(js格式) 爬取http://fund.e ...
- Python爬虫之urllib模块2
Python爬虫之urllib模块2 本文来自网友投稿 作者:PG-55,一个待毕业待就业的二流大学生. 看了一下上一节的反馈,有些同学认为这个没什么意义,也有的同学觉得太简单,关于Beautiful ...
- python正则表达式Re模块备忘录
title: python正则表达式Re模块备忘录 date: 2019/1/31 18:17:08 toc: true --- python正则表达式Re模块备忘录 备忘录 python中的数量词为 ...
- asynicio模块以及爬虫应用asynicio模块(高性能爬虫)
一.背景知识 爬虫的本质就是一个socket客户端与服务端的通信过程,如果我们有多个url待爬取,只用一个线程且采用串行的方式执行,那只能等待爬取一个结束后才能继续下一个,效率会非常低. 需要强调的是 ...
随机推荐
- 区域可编辑contenteditable的问题总结
一.如何在可编辑区域div的光标处通过点击事件来添加文本内容 下面的例子是可编辑div的区域添加文本内容和判断光标位置的方法 <!DOCTYPE html> <html lang=& ...
- 设计模式之简单工厂模式(Simple Factory)
原文地址:http://www.cnblogs.com/BeyondAnyTime/archive/2012/07/06/2579100.html 今天呢,要学习的设计模式是“简单工厂模式”,这是一个 ...
- 【Hibernate那点事儿】—— Hibernate应该了解的知识
前言: 最近由于有点时间,就像深入的学习一下Hibernate.之前只是简单的使用,并没领会它的妙处.这里就趁着分享的机会,好好整理一下. 这篇主要讲到了下面几个部分: Hibernate框架 Hib ...
- March 4 2017 Week 10 Saturday
There is more to life than increasing its speed. 生活不仅仅是匆匆赶路. I always think I have walked very slowl ...
- SAP Fiori里两种锁机制(lock)的实现
方法1: ETAG机制 SAP CRM Fiori采用了这种机制. 看一个具体的例子来理解.假设我用用户名Jerry选中了这个ID为3456的Opportunity,点击Edit按钮之后: 会触发一个 ...
- URL地址解析
URL的一般格式为(带方括号[]的为可选项): protocol :// hostname[:port] / path /[?query]#fragment 1.protocol :// 为传输协 ...
- linux命令之添加删除磁盘分区
之前已经写过df和fdisk的区别了,df可以显示当前已经挂载的磁盘分区,df -T可以额外显示文件系统类型 fdisk -l可以显示出所有挂载未挂载的分区,但不显示文件类型 在我的虚拟机上有一块分配 ...
- hdu-2136 Largest prime factor---巧用素数筛法
题目链接: http://acm.hdu.edu.cn/showproblem.php?pid=2136 题目大意: 每个素数在素数表中都有一个序号,设1的序号为0,则2的序号为1,3的序号为2,5的 ...
- Hive创建外部表以及分区
版权声明:本文为博主原创文章,未经博主同意不得转载. https://blog.csdn.net/sheismylife/article/details/27874943 创建带分区的外部表 创建外部 ...
- CF549BLooksery Party题解
题目描述 The Looksery company, consisting of nn staff members, is planning another big party. Every empl ...