算法导论-散列表(Hash Table)-大量数据快速查找算法
目录
内容
1、引言
如果想在一个n个元素的列表中,查询元素x是否存在于列表中,首先想到的就是从头到尾遍历一遍列表,逐个进行比较,这种方法效率是Θ(n);当然,如果列表是已经排好序的话,可以采用二分查找算法进行查找,这时效率提升到Θ(logn); 本文中,我们介绍散列表(HashTable),能使查找效率提升到Θ(1);
Question 1:那么什么是Hash Table,是如何定义的呢?
给定一个关键字Key(整数),通过一个定义好的散列函数,可以计算出数据存放的索引位置,这样我们不用遍历,就可以通过计算出的索引位置获取到要查询的数。如下图所示:

因此:散列表是普通数组概念的推广,在散列表中,不是直接把关键字用作数组下标,而是根据关键字通过散列函数计算出来的。下面会进行讲解。
question 2:那么,Hash Function 如何定义呢?
hash function 有很多种定义方法,其中 最常用的是除法散列;在散列函数小节中会进行详细介绍【除法散列、乘法散列、全域散列、完全散列】
question 3:当给定的keys不是整数怎么办?
如下图所示,想通过各hash function将Non-InTeger key转换为Integer key,然后再进行正常的运算。
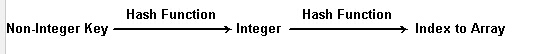
Question 4:当多个关键字Key,通过hash function计算出的索引相同,就是说他们产生了“冲突”,这时该怎么办呢?
针对这个问题,我们的处理方法有:开放寻址法和链表法。具体会在碰撞处理方法小节讲解。
Ok,下面开始枯燥地讲解了:
2、直接寻址
当关键字的的全域(范围)U比较小的时,直接寻址是简单有效的技术,一般可以采用数组实现直接寻址表,数组下标对应的就是关键字的值,即具有关键字k的元素被放在直接寻址表的槽k中。直接寻址表的字典操作实现比较简单,直接操作数组即可以,只需O(1)的时间。见下图:
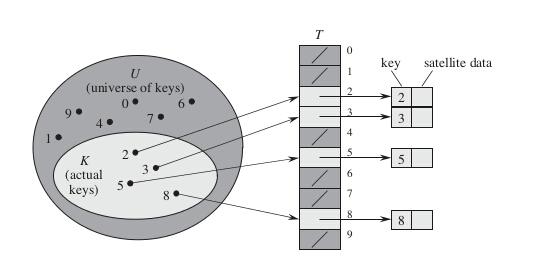
假设某应用要用到一个动态集合,其中每个元素都是取自全域U={0,1,...,m-1}中的一个关键字,这里m不是一个很大的数。另外,假设没有两个元素具有相同的关键字。
为表示动态集合,我们用一个数组,或称为直接寻址表(direct-address table),记为T[0...m-1]。其中每个位置,称为一个槽(slot),对应全域U中的一个关键字。上图描述了该方法。槽k指向集合中一个关键字为k的元素。如果该集合中没有关键字为k的元素,则T[k]为NIL
3、散列寻址
直接寻址技术的缺点是非常明显的:如果全域U很大,则在一台标准的计算机可用内存容量中,要存储大小为|U|的一张表T也许不大实际,甚至不可能。还有,实际存储的关键字集合K相对于U来说可能很小,使得分配给T的大部分空间都将浪费掉。当存储在字典中的关键字集合K比所有可能的关键字的全域U要小许多时,散列表需要的存储空间要比直接寻址表少的多。在散列方式下,元素存放在槽h(k)中即利用散列函数h,由关键字k计算出槽的位置。这里,函数h将关键字的全域U映射到散列表T[0...m-1]的槽位上。
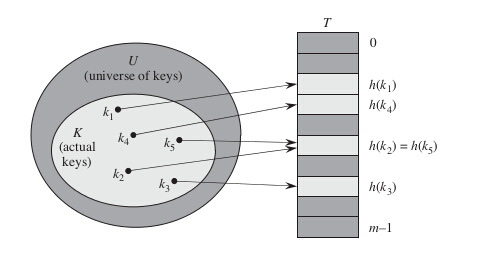
这里存在一个问题:两个关键字可能映射到同一个槽中。我们称这种情形为冲突(collision),解决冲突可以通过选择一个合适的散列函数h来做到这一点。但是,由于|U|>m,故至少有两个关键字其散列值相同,所以想要完全避免冲突是不可能的。因此一方面可以通过精心设计的散列函数来尽量减少冲突的次数,另一方面仍需要解决可能出现冲突的方法。
本文介绍几种冲突解决的方法,主要包括链表法和开放寻址法。其中开放寻址法又有几种可选的方法:线性探查、二次探查、双重散列、随机散列
接下来介绍几种常用的散列函数
4、散列函数
好的散列函数的特点是每个关键字都等可能的散列到m个槽位上的任何一个中去,并与其他的关键字已被散列到哪一个槽位无关。多数散列函数都是假定关键字域为自然数N={0,1,2,....},如果给的关键字不是自然数,则必须有一种方法将它们解释为自然数。例如对关键字为字符串时,可以通过将字符串中每个字符的ASCII码相加,转换为自然数。在实际工作中经常用字符串作为关键字,例如身姓名、职位等等。这个时候需要设计一个好的散列函数进程处理关键字为字符串的元素。下面代码为将字符串中每个字符的ASCII码相加,转换为自然数的方法。
int Hash(const string& key,int tablesize)
{
int hashVal = ;
for(int i=;i<key.length();i++)
hashVal += key[i];
return hashVal % tableSize;
}
有许多优秀的字符串散列函数,下面链接可以参考https://www.byvoid.com/blog/string-hash-compare
4.1、除法散列
通过取k除以m的余数,将关键字k映射到m个槽的某一个中去。散列函数为:h(k)=k mod m 。m不应是2的幂,通常m的值是与2的整数幂不太接近的质数。
例如:下面的数如何通过除法散列映射到具有11个槽的散列表中:
23
346
48
通过除法散列:
23 % 11 = 1(余数是1)
346 % 11 = 5(余数是5)
48 % 11 = 4(余数是4)
则应该插入到1,5,4槽中,想下面所示:

4.2、乘法散列
乘法散列法构造散列函数需要两个步骤。第一步,用关键字k乘上常数A(0<A<1),并抽取kA的小数部分。然后,用m乘以这个值,再取结果的底。散列函数如下:h(k) = m(kA mod 1)。
4.3、全域散列
任何一个特定的散列函数都可能将特定的n个关键字全部散列到同一个槽中,使得平均的检索时间为Θ(n)。为了避免这种情况,唯一有效的改进方法是随机地选择散列函数,使之独立与要存储的关键字。这种方法称为全域散列(universal hashing)
全域散列在执行开始时,就从一组精心设计的函数中,随机地选择一个作为散列函数。因为随机地选择散列函数,算法在每一次执行时都会有所不同,甚至相同的输入都会如此。这样就可以确保对于任何输入,算法都具有较好的平均情况性能.
选择一个足够大的质数p,使得每一个可能的关键字都落在0到p-1的范围内。设Zp表示集合{0, 1, …, p-1},Zp*表示集合{1, 2, …, p-1}。对于任何a∈Zp*和任何b∈Zp,定义散列函数ha,b
ha,b = ((ak+b) mod p) mod m;其中a,b是满足自己集合的随机数;
4.4、完全散列
如果某种散列技术可以在查找时,最坏情况内存访问次数为O(1)的话,则称其为完全散列(perfect hashing)。当关键字集合是静态的时,这种最坏情况的性能是可以达到的。所谓静态就是指一旦各关键字存入表中后,关键字集合就不再变化了。
我们可以用一种两级的散列方案来实现完全散列,其中每级上采用的都是全域散列。如下图: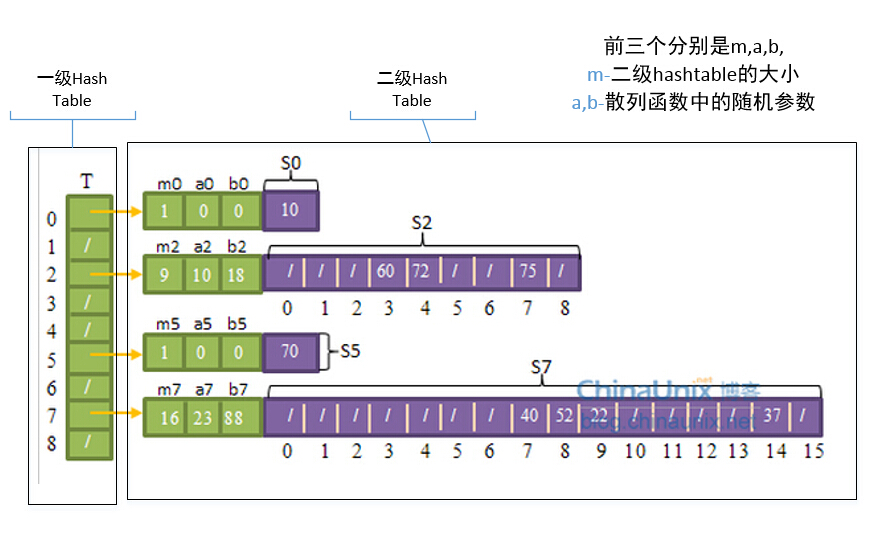
首先第一级使用全域散列把元素散列到各个槽中,这与其它的散列表没什么不一样。但在处理碰撞时,并不像链接法(碰撞处理方法)一样使用链表,而是对在同一个槽中的元素再进行一次散列操作。也就是说,每一个(有元素的)槽里都维护着一张散列表,该表的大小为槽中元素数的平方,例如,有3个元素在同一个槽的话,该槽的二级散列表大小为9。不仅如此,每个槽都使用不同的散列函数,在全域散列函数簇h(k) = ((a*k+b) mod p) mod m中选择不同的a值和b值,但所有槽共用一个p值如101。每个槽中的(二级)散列函数可以保证不发生碰撞情况。
可 以证明,当二级散列表的大小为槽内元素数的平方时,从全域散列函数簇中随机选择一个散列函数,会产生碰撞的概率小于1/2。所以每个槽随机选择散列函数后,如果产生了碰撞,可以再次尝试选择其它散列函数,但这种尝试的次数是非常少的。
虽然二级散列表的大小要求是槽内元素数的平方,看起来很大,但可以证明,当散列表的槽的数量和元素数量相同时(m=n),所有的二级散列表的大小的总量的期望值会小于2*n,即Ө(n)。
5、碰撞处理方法
下面介绍几种冲突解决的方法,主要包括链表法和开放寻址法。其中开放寻址法又有几种可选的方法:线性探查、二次探查、双重散列、随机散列
5.1、链表法
在链接法中,把散列到同一槽中的所有元素(冲突的元素)都放在一个链表中;
若选定的散列表长度为m,则可将散列表定义为一个由m个头指针组成的指针数组T[0..m-1]。凡是散列地址为i的结点,均插入到以T[i]为头指针的单链表中。T中各分量的初值均应为空指针。在拉链法中,装填因子α可以大于1,但一般均取α≤1。
举例说明链接法的执行过程,设有一组关键字为(26,36,41,38,44,15,68,12,6,51),用除余法构造散列函数,初始情况如下图所示: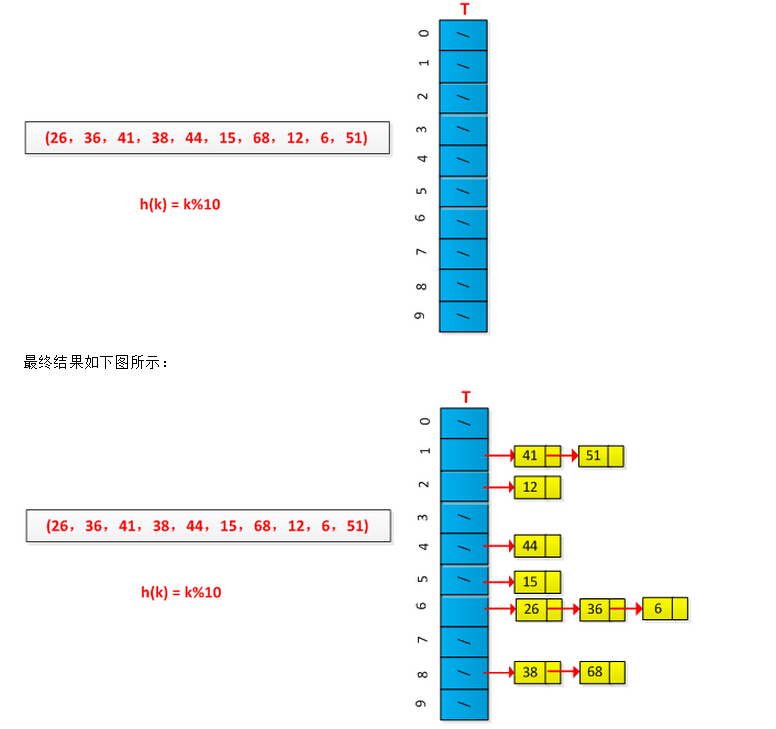
5.2、开放寻址法
开放寻址法是另外一个处理元素冲突的方法;链表法是把冲突的元素依次放到一串链表中,而开放寻址法的思路是:在产生冲突的情况下,在hashtable中寻找其他空闲的槽位插入;当然,如何寻找其他空闲的槽位,我们有几种方法,包括:线性探查、二次探查、双重散列、随机散列;下面逐个讲解。
5.2.1、线性探查
给定一个普通的散列函数h':U-->{0,1,...,m-1},称为辅助散列函数,线性探查方法采用的散列函数为
h(k,i)=(h'(k)+i) mod m, i = 0,1,...,m-1
给定一个关键字k,首先探查槽T[h'(k)],即由辅助三列函数所给出的槽位。再探测T[h'(k)+1],依次类推,直到槽T[m-1]。然后,又绕到槽T[0],T[1],...,直到最后探测到槽T[h'(k)-1]。
线性探测方法比较容易实现,但它存在着一个问题,称为一次群集。随着连续被占用的槽不断增加,平均查找时间也随之不断增加。集群现象很容易出现,这是因为当一个空槽前有i个满的槽时,该空槽下一个将被占用的概率是(i+1)/m。连续被占用的槽就会变得越来越长,因而平均查询时间也会越来越大。采用例子进行说明线性探测过程,已知一组关键字为(26,36,41,38,44,15,68,12,6,51),用除法散列构造散列函数,初始情况如下图所示: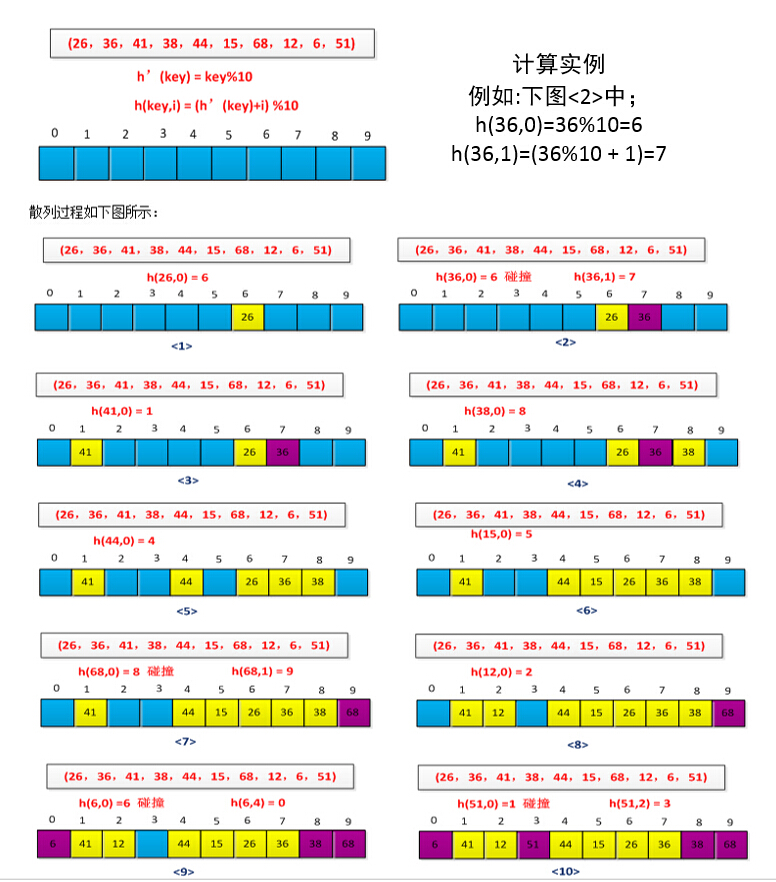
5.2.2、二次探查
h(k,i)=(h'(k)+c₁i+c₂i²) mod m , i = 0,1,...,m-1
其中h'是一个辅助散列函数,c₁和c₂为正的辅助常数,i=0,1,...m-1。初始的探查位置为T[h'(k)],后续的探查位置要加上一个偏移量,该偏移量以二次的方式依赖于探查序号i。这种探查方法的效果要比线性探查好很多,但是,为了能够充分利用散列表,c₁,c₂和m的值要受到限制。此外,如果两个关键字的初始探查位置相同,那么它们的探查序列也是相同的。这一性质可导致一种轻度的群集,称为二次群集。
5.2.3、双重散列
双重散列(double hashing)是用于开放寻址法的最好方法之一,因为它所产生的排列具有随机选择队列的许多特性。双重散列采用如下形式的散列函数:
h(k,i)=(h₁(k)+ih₂(k)) mod m, i = 0,1,...,m-1
其中h₁和h₂均为辅助散列函数。初始探查位置为T[h₁(k)],后续的探查位置是前一个位置加上偏移量h₂(k)模m。因此,不像线性探查或二次探查,这里的探查序列以两种不同方式依赖于关键字k,因为初始探查位置、偏移量或者两则都可能发生变化。下图给出了一个使用双重散列法进行插入的例子。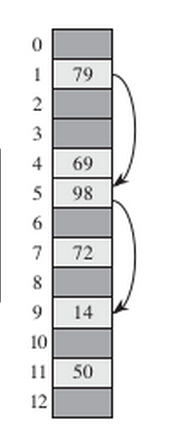
上图说明:双重散列法的插入。此处,散列表的大小为13,h₁(k)=k mod13,h₂(k)=1+(k mod 11)。以元素14为例:因为h₁(14)=(14 mod13)=1,槽1已被79占用,--》h₂(14)=1+(14 mod 11)=4,则h(14,1)=h₁(14)+h₂(14)=1+4=5,槽5已被98占用,--》h(14,2)=h₁(14)+2*h₂(14)=1+2*4=9,槽9空闲,则插入到槽9中;所以在探查了槽1和槽5,并发现它们被占用后,关键字14插入了槽9中
5.2.4、随机散列
随机散列散列函数:
h(k,i)=(h₁(k)+Random(i)) mod m,Random(i)是随机整数,大小属于集合{0,1,2,......,m-1}
其中h₁为辅助散列函数。初始探查位置为T[h₁(k)],后续的探查位置是前一个位置加上偏移量Random(i)模m;Random(i)是系统产生的随机数,随机散列数组在探查之前生成,数组内的随机数相互独立;类似于全域散列函数,其实属于散列函数范畴的,这里专门当做一种探查方法来说明,只是为了说明一个随机的探查思想;
6、再散列问题
如果散列表满了,再往散列表中插入新的元素时候就会失败;或者散列表快满时,进行插入是一个效率很低的过程;这个时候可以通过创建另外一个散列表,使得新的散列表的长度是当前散列表的2倍多一些,重新计算各个元素的hash值,插入到新的散列表中。再散列的问题是在什么时候进行最好,有下面情况可以判断是否该进行再散列:
(1)当散列表将快要满了,给定一个范围,例如散列被中已经被用到了80%,这个时候进行再散列。
(2)当插入一个新元素失败时候(相同关键字失败除外),进行再散列。
(3)当插入一个新元素产生冲突次数过多时,进行再散列。
(3)对于链表法,根据装载因子(已存放n个元素的、具有m个槽位的散列表T,装载因子α=n/m)进行判断,当装载因子达到一定的阈值时候,进行再散列。
7、完整源码 c++
下面代码采用开放寻址法处理冲突,包括线性探查、二次探查、双重散列探查、随机散列探查实现;散列函数采用简单的除法散列函数;当插入一个新元素产生冲突次数过多时,进行再散列
HashTable.h
//HashTable.h 开放寻址法哈希表类(HashTable类)
#ifndef _HAXI_H_
#define _HAXI_H_
const int SUCCESS = ;//成功
const int UNSUCCESS = ;//不成功
const int DUPLICATE = -;//关节字冲突(重复),不能再插入
const int N = ;//hashsize[]的容量
int hashsize[N] = { , , , };
//哈希表容量递增表,一个合适的素数序列,(重)建哈希表用到 template<typename D>class HashTable
{//带数据元素类型D模板的开放寻址法哈希表类
private://6个私有成员函数,5个私有数据成员
D *elem;//数据元素存储基址,动态分配数组
int count, length;//数据元素个数,哈希表容量
int sizeindex;//hashsize[sizeindex]为当前容量
int *rando;//随机数数组指针
int Hash(KeyType Key)
{//一个简单的哈希函数
return Key%length;
}
int Hash2(KeyType Key)//用于双重散列探索法
{//双重散列探查法的第二个哈希函数
return Key % (length - );
}
void Random()
{//建立伪随机数组(用于随机探查法)
bool *ra = new bool[length];//
rando = new int[length];
int i;
for (i = ; i<length; i++)//设置ra[i]的初值
ra[i] = false;//i不在随机数数组中的标志
// srand(time(0));//设置随机数种子
for (i = ; i<length; i++)//依次给rando[i]赋随机值
{
do
{
rando[i] = rand() % (length - ) + ;//给rando[i]赋值(1-length-1)
if (!ra[rando[i]])//伪随机数组中没有此数
ra[rando[i]] = true;//赋值成功
else
rando[i] = ;
} while (rando[i] == );//赋值失败则重新赋值
cout << "rando[" << i << "]=" << rando[i] << endl;
}
delete[]ra;
}
int d(int i, KeyType Key)//增量序列函数
{//返回第i次冲突的增量
switch (type)
{
case : return i;//线性探查法
case : return ((i + ) / )*((i + ) / )*(int)pow(-, i - );
//二次探查法(1,-1,4,-4,9,-9,......)
case : return i*Hash2(Key);//双重散列探查法
case : return rando[i];//随机探查法(由Random()建立的一个伪随机数列)
default:return i;//默认线性探查法
}
}
//开放寻址法求得关键字为Key的第i次冲突的地址p
void collision(KeyType Key, int &p, int i)
{
p = (Hash(Key) + d(i, Key)) % length;//哈希函数加增量后再求余
if (p<)//得到负数(双重探查可能出现)
p = p + length;//保证非负
}
//重建哈希表
void RecreateHashTable()
{
int i, len = length;//原容量
D *p = elem;//p指向哈希表原有数据空间
sizeindex++;//增大容量为下一个序列数
if (sizeindex<N)
{
length = hashsize[sizeindex];
elem = new D[length];
assert(elem != NULL);
for (i = ; i<length; i++)//未填数据的标志
elem[i].key = EMPTY;
for (i = ; i<len; i++)//将p所指原elem中的数据插入到重建的哈希表中
if (p[i].key != EMPTY && p[i].key != TOMB)
InsertHash(p[i]);
delete[]p;
if (type == )//随机探查法
Random();
}
}
public://7个公有成员函数,1个共有数据成员
int type;//探查法类型(0-3)
HashTable()
{//构造函数,构造一个空的哈希表
count = ;
sizeindex = ;
length = hashsize[sizeindex];
elem = new D[length];
assert(elem != NULL);
for (int i = ; i<length; i++)
elem[i].key = EMPTY;//未填数据的格式
cout << "请输入探查法的类型(0:线性;1:二次;2:双散列;3:随机):";
cin >> type;
if (type == )
Random();
else
rando = NULL;
}
~HashTable()
{//析构函数,销毁哈希表
if (elem != NULL)
delete[]elem;
if (type == )
delete[]rando;
}
//在开放寻址哈希表中查找关键字为Key的元素,若查找成功,以p指向待查数据元素在表中位置
//并返回SUCCESS;否则,以p指示插入位置,并返回UNSUCCESS
//c用以计冲突次数,其初值置零,供建表插入时参考
bool SearchHash(KeyType Key, int &p, int &c)
{
int c1, tomb = -;//存找到的第一个墓碑地址(被删除数据)
p = Hash(Key);//哈希地址
//下面的while代码段,如果哈希地址处数据不是要查找的数据,
//则求下一个探查地址p,进行查找,直到碰撞次数超出定义的阈值 while (elem[p].key == TOMB || elem[p].key != EMPTY && !EQ(Key, elem[p].key))
{
if (elem[p].key == TOMB && tomb == -)//数据已被删除,且是找到的第一个墓碑
{
tomb = p;
c1 = c;//冲突次数存于c1
}
c++;//冲突次数+1
if (c <= hashsize[sizeindex]/)//在冲突次数阈值内,求下一个探查地址p
collision(Key, p, c);
else
break;
}
if EQ(Key, elem[p].key)//查找成功
return true;
else//查找不成功
{
if (tomb != -)//查找过程中遇到过墓碑
{
p = tomb;//将墓碑作为插入位置
c = c1;//冲突次数
}
return false;
}
}
//查找不成功时将数据元素e插入到开放寻址哈希表中,并返回SUCCESS;查找成功时返回
//DUPLICATE,不插入数据元素;若冲突次数过大,则不插入,并重建哈希表,返回UNSUCCESS
int InsertHash(D e)
{ int p, c = ;
if (SearchHash(e.key, p, c))//查找成功,已有与e相同关键字 元素,不再插入
return DUPLICATE;
else if (c <= hashsize[sizeindex]/)//为找到,冲突次数c也未达到上限(c的阈值可调),插入
{
elem[p] = e;
++count;
return SUCCESS;
}
else//未找到,但冲突次数已达到上限,重建哈希表
{
cout << "按哈希地址的顺序遍历重建前的哈希表:" << endl;
TraverseHash(Visit);
cout << "重建哈希表" << endl;
RecreateHashTable();
return UNSUCCESS;
}
}
//从哈希表中删除关节字为Key的数据元素,成功返回true,并将该位置的关键字设为TMOB;
//不成功返回false
bool DeleteHash(KeyType Key, D &e)
{ int p, c=;//一定要赋初值,不然c会是个随机的数
if (SearchHash(Key, p, c))//查找成功
{
e = elem[p];
elem[p].key = TOMB;
--count;
return true;
}
else
return false;
}
//返回元素[i]的值
D GetElem(int i)const
{
return elem[i];
}
//按哈希地址的顺序遍历哈希表H
void TraverseHash(void(*visit)(int, D*))const
{
int i;
cout << "哈希地址0~" << length - << endl;
for (i = ; i<length; i++)
if (elem[i].key != EMPTY && elem[i].key != TOMB)
visit(i, &elem[i]);
}
};
#endif
HashTable.cpp(主测试函数)
// 验证HashTable类的成员函数
#include <iostream>
#include <fstream>
#include <string>
#include <assert.h>
using namespace std;
// 对两个数值型关键字的比较约定为如下的宏定义
#define EQ(a, b) ((a)==(b))
const int EMPTY=;//设置0为无数据标志(此时关键字不可为0)
const int TOMB=-;//设置-1为删除数据标志(此时关键字不可为-1)
typedef int KeyType;
#include "HashTable.h"
// 定义模板<D>的实参HD及相应的I/O操作
struct HD
{
KeyType key;
int order;
};
void Visit(int i, HD* c)
{
cout << '[' << i << "]: " << '(' << c->key << ", " << c->order << ')' << endl;
}
void Visit(HD c)
{
cout << '(' << c.key << ", " << c.order << ')';
}
void InputFromFile(ifstream &f, HD &c)
{
f >> c.key >> c.order;
}
void InputKey(int &k)
{
cin >> k;
} void main()
{
HashTable<HD> h;
int i, j, n, p=;
bool m;
HD e;
KeyType k;
ifstream fin("input.txt");//第一行的数表示数据个数
fin>>n;//由文件输入数据个数
//建立哈希表
for(i=; i<n; i++)
{
InputFromFile(fin, e);
j=h.InsertHash(e);
if(j==DUPLICATE)
{
cout<<"哈希表中已有关键字为"<<e.key<<"的数据,无法再插入数据";
Visit(e);
cout<<endl;
}
if(j==UNSUCCESS)//插入不成功,重建哈希表
j=h.InsertHash(e);
}
fin.close();
cout<<"按哈希地址的顺序遍历哈希表:"<<endl;
h.TraverseHash(Visit); //删除数据测试
cout<<"请输入待删除数据的关键字:";
InputKey(k);
m=h.DeleteHash(k, e);
if (m)
{
cout << "成功删除数据";
Visit(e);
cout << endl;
}
else
cout << "不存在关键字,无法删除!" << endl;
cout << "按哈希地址的顺序遍历哈希表:" << endl;
h.TraverseHash(Visit);
//查询数据测试
cout<<"请输入待查找数据的关键字:";
InputKey(k);
n=;
j=h.SearchHash(k, p, n);
if(j==SUCCESS)
{
Visit(h.GetElem(p));
cout<<endl;
}
else
cout<<"未找到"<<endl; //插入数据测试
cout<<"插入数据,请输入待插入数据的关键字:";
InputKey(e.key);
cout<<"请输入待插入数据的order:";
cin>>e.order;
j=h.InsertHash(e);
if (j==DUPLICATE)
{
cout << "哈希表中已有关键字为" << e.key << "的数据,无法再插入数据";
Visit(e);
cout << endl;
}
if (j == UNSUCCESS)//插入不成功,重建哈希表
j = h.InsertHash(e);
cout<<"按哈希地址的顺序遍历哈希表:"<<endl;
h.TraverseHash(Visit); }
input.txt 文件内容
测试结果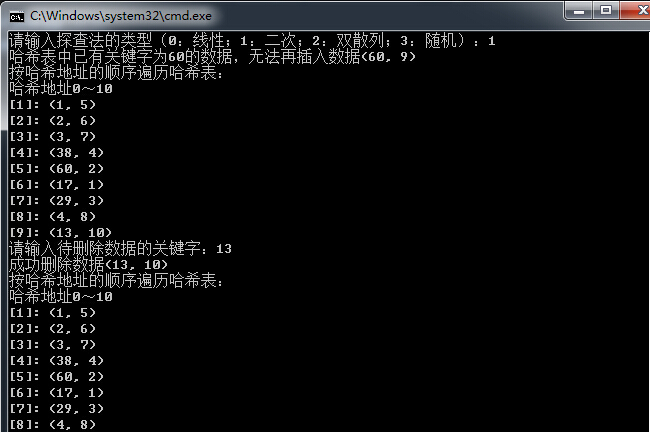

8、参考资料
【1】 http://www.junevimer.com/2014/06/10/algorithms-hash-table.html#universal%20hashing
【2】 http://www.cnblogs.com/Anker/archive/2013/01/27/2879150.html
【3】 http://www.cs.uregina.ca/Links/class-info/210/Hash/#EXERCISE
【4】 https://www.byvoid.com/blog/string-hash-compare
【5】 http://blog.chinaunix.net/uid-26822401-id-3169705.html
【6】 http://blog.csdn.net/intrepyd/article/details/4359818
算法导论-散列表(Hash Table)-大量数据快速查找算法的更多相关文章
- 白话算法(6) 散列表(Hash Table)从理论到实用(上)
处理实际问题的一般数学方法是,首先提炼出问题的本质元素,然后把它看作一个比现实无限宽广的可能性系统,这个系统中的实质关系可以通过一般化的推理来论证理解,并可归纳成一般公式,而这个一般公式适用于任何特殊 ...
- 白话算法(6) 散列表(Hash Table)从理论到实用(中)
不用链接法,还有别的方法能处理碰撞吗?扪心自问,我不敢问这个问题.链接法如此的自然.直接,以至于我不敢相信还有别的(甚至是更好的)方法.推动科技进步的人,永远是那些敢于问出比外行更天真.更外行的问题, ...
- 白话算法(6) 散列表(Hash Table) 从理论到实用(下)
[澈丹,我想要个钻戒.][小北,等等吧,等我再修行两年,你把我烧了,舍利子比钻戒值钱.] ——自扯自蛋 无论开发一个程序还是谈一场恋爱,都差不多要经历这么4个阶段: 1)从零开始.没有束缚的轻松感.似 ...
- [转载] 散列表(Hash Table)从理论到实用(上)
转载自:白话算法(6) 散列表(Hash Table)从理论到实用(上) 处理实际问题的一般数学方法是,首先提炼出问题的本质元素,然后把它看作一个比现实无限宽广的可能性系统,这个系统中的实质关系可以通 ...
- [转载] 散列表(Hash Table)从理论到实用(中)
转载自:白话算法(6) 散列表(Hash Table)从理论到实用(中) 不用链接法,还有别的方法能处理碰撞吗?扪心自问,我不敢问这个问题.链接法如此的自然.直接,以至于我不敢相信还有别的(甚至是更好 ...
- [转载] 散列表(Hash Table) 从理论到实用(下)
转载自: 白话算法(6) 散列表(Hash Table) 从理论到实用(下) [澈丹,我想要个钻戒.][小北,等等吧,等我再修行两年,你把我烧了,舍利子比钻戒值钱.] ——自扯自蛋 无论开发一个程序还 ...
- 散列表(Hash Table)
散列表(hash table): 也称为哈希表. 根据wikipedia的定义:是根据关键字(Key value)而直接访问在内存存储位置的数据结构.也就是说,它通过把键值通过一个函数的计算,映射到表 ...
- Java 集合 散列表hash table
Java 集合 散列表hash table @author ixenos 摘要:hash table用链表数组实现.解决散列表的冲突:开放地址法 和 链地址法(冲突链表方式) hash table 是 ...
- 散列表(Hash table)及其构造
散列表(Hash table) 散列表,是根据关键码值(Key value)而直接进行访问的数据结构.它通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度.这个映射函数叫做散列函数,存放记录 ...
随机推荐
- HDU1045(二分图经典建模)
Fire Net Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536/32768 K (Java/Others)Total Su ...
- TASK_KILLABLE:Linux 中的新进程状态【转】
转自:https://www.ibm.com/developerworks/cn/linux/l-task-killable/index.html 新的睡眠状态允许 TASK_UNINTERRUPTI ...
- I2C和SPI总线对比【转】
转自:http://blog.csdn.net/skyflying2012/article/details/8237881/ 最近2周一直在调试IIC和SPI总线设备,这里记录一下2种总线,以备后忘. ...
- pythontip题目解答
输出字典key 给你一字典a,如a={1:1,2:2,3:3},输出字典a的key,以','连接,如‘1,2,3'.要求key按照字典序升序排列(注意key可能是字符串). 例如:a={1:1,2:2 ...
- 区块链开发(四)Nodejs下载&安装
以太坊框架truffle的安装需要依赖nodejs中的npm命令,本篇博客我们就简单介绍一下node的安装过程.操作系统基于ubuntu 16.04版本. 下载地址 nodejs官网:http://w ...
- ORM- 图书系统查询
图书信息系统 表结构设计 # 书 class Book(models.Model): title = models.CharField(max_length=32) publish_date = mo ...
- Vuejs1.0学习
1.数据双向绑定 双向绑定以后,表单中数据的改变会同步改变H2中的输出 2.v-show 内容输入前: 内容输入后:隐藏提示,展示按钮 代码实现: 此处的v-show可以换成v-if,v-show是隐 ...
- PHP常用函数及其注释
<?php //===============================时间日期=============================== //y返回年最后两位,Y年四位数,m月份数字 ...
- cobbler自动重装
如果物理机上想更换操作系统 yum -y install http://mirrors.163.com/centos/7/extras/x86_64/Packages/epel-release-7-9 ...
- js跳转整理(简记)
location.replace(URL)跳转脱离历史记录流: location.href=url;在历史记录中 子刷新父级 parent.location.replace(parent.locati ...