零基础Python知识点回顾(三)
元组
元组是用圆括号括起来的,其中的元素之间用逗号隔开。(都是英文半角)tuple(元组)跟列表类似是一种序列类型的数据,特点就是其中的元素不能更改
既然是有序的,那么,嘿嘿,不错,它也可以有索引,能切片,记住:所有在list中可以修改list的方法,在tuple中,都失效
元组和列表很相似,那怎么区别呢?
- Tuple 比 list 操作速度快。如果您定义了一个值的常量集,并且唯一要用它做的是不断地遍历它,请使用 tuple 代替 list。
- 如果对不需要修改的数据进行 “写保护”,可以使代码更安全。使用 tuple 而不是 list 如同拥有一个隐含的 assert 语句,说明这一数据是常量。如果必须要改变这些值,则需要执行 tuple 到 list 的转换 (需要使用一个特殊的函数)。
- Tuples 可以在 dictionary(字典,后面要讲述) 中被用做 key,但是 list 不行。Dictionary key 必须是不可变的。Tuple 本身是不可改变的,但是如果您有一个 list 的 tuple,那就认为是可变的了,用做 dictionary key 就是不安全的。只有字符串、整数或其它对 dictionary 安全的 tuple 才可以用作 dictionary key。
- Tuples 可以用在字符串格式化中。
突然感觉,元组没啥说的了,不怪我啊,我小白,真不知道了,它跟列表类似,所以。。。内容只能夭折了
字典
person = {"name":"qiwsir","site":"qiwsir.github.io","language":"python"}
person
{'name': 'qiwsir', 'language': 'python', 'site': 'qiwsir.github.io'}
"name":"qiwsir",有一个优雅的名字:键值对。前面的name叫做键(key),后面的qiwsir是前面的键所对应的值(value)。在一个dict中,键是唯一的,不能重复。值则是对应于键,值可以重复。键值之间用(:)英文的冒号,每一对键值之间用英文的逗号(,)隔开。
利用元组在建构字典
name = (["first","Google"],["second","Yahoo"])
website = dict(name)
website
{'second': 'Yahoo', 'first': 'Google'}
使用fromkeys 构建字典
website = {}.fromkeys(("third","forth"),"facebook")
website
{'forth': 'facebook', 'third': 'facebook'}
在字典中的“键”,必须是不可变的数据类型(也就是可哈希);“值”可以是任意数据类型
可哈希数据:不可改变的数据结构(字符串str、元组tuple、对象集objects)。不可哈希数据:即可改变的数据结构 (字典dict,列表list,集合set)
dict数据类型是以键值对的形式存储数据的,所以,只要知道键,就能得到值。这本质上就是一种映射关系
a = {'name2': 'qiwsir', 'name': 'qiwsir'}
a['name']
'qiwsir'
dict中的这类以键值对的映射方式存储数据,是一种非常高效的方法,比如要读取值得时候,如果用列表,python需要从头开始读,直到找到指定的那个索引值。但是,在dict中是通过“键”来得到值。要高效得多。 正是这个特点,键值对这样的形式可以用来存储大规模的数据,因为检索快捷。规模越大越明显
- len(d),返回字典(d)中的键值对的数量
- d[key],返回字典(d)中的键(key)的值
- d[key]=value,将值(value)赋给字典(d)中的键(key)
- del d[key],删除字典(d)的键(key)项(将该键值对删除)
- key in d,检查字典(d)中是否含有键为key的项
关于字典的字符串格式化,有点酷,当当当,请看:
liudana = {"mianfei":"0512", "xiaoshou":"0315", "dashou":"0571"}
" liudana is a beautiful boy, his teachter number is %(mianfei)s " % liudana
' liudana is a beautiful boy, his teachter number is 0512 '
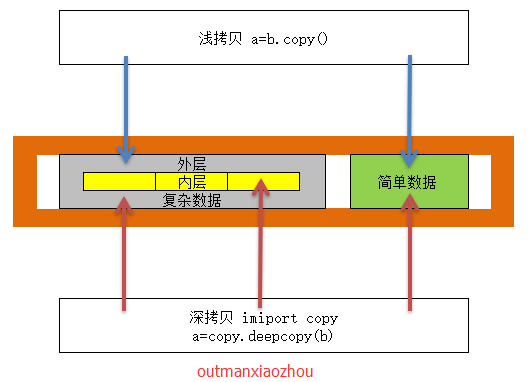
好了,现在说比较难于理解的,在字典中常会见到的,前面也简单提到过“浅拷贝”,还有深拷贝“”
怎么说呢?python在拷贝数据的时候都是能省事就省事,不过这么说好像也不太好,这样吧,比如 a=b 这种赋值方式,你用id()会发现其实他们就是一个,python省事了
估计就这么设计的,既然你们都一样,为何我要弄两个呢,都指向同一个对象(有人称这叫传址,指向同一个地址)这种赋值方式,其实不管你的数据有多复杂,都是一个“容器”
指向一个地方,你变我也变,因为我的就是你赋予的。如果我们用a=b.copy(),就不一样,会用两个“容器”,你抄袭了我的,但是你改你的,我改我的,咱两用的不是一份哦!
我们再用id()查看会发现,指向了不同的地址,这也就说明,他们放在两个不同地方,是不同的对象。但是我们没修改前在用id()查看里面数据,发现,他大爷的,ID还是指向的
同一个,怎么回事,python你就这么涂省事么?里面数据还是传址,因为你没改,我认为你还是用的同一个数据,所以他省事了。但是,如果我改了呢?是不是再用查看其ID,
就不一样了呢?这个啊,不一定!为何这么说?我先总结说下,他拷贝时候看数据就看了一层,怎么理解呢?如果是简单数据,比如,数字、字符串,他一眼看到了,他就想:
“你复制一份出来,数据都一样,我就给你指向同一个地址,如果你修改了,嘿嘿,我再你的容器内写进去呗,不同数据了嘛,指向不同地方喽!” 问题就出在这里,
如果是复杂的数据结构,比如列表、字典之类,他就看到了[]或{} 就知道是个列表或字典,里面具体是啥,他不知道,这也就是我前面所说的他就看了一层,第二层数据是啥他
压根就不关心,所以说,如果是简单数据你改了,用id()查看会发现其指向了不同的ID,因为改了python他看到的。如果是复杂数据你改了,用id()查看会发现其指向同一个的ID,
因为改了里面数据,python他看不到的,他也就不知道喽,所以他还是认为是同一个数据,就还给你传址。你搞清楚了么?这些才是真正的浅拷贝,
那深拷贝呢?当然是里面数据,他都能看到,要用下 import 来导入一个模块
import copy
w = copy.deepcopy(q) #拷贝q一份给w
深拷贝,前面其实也是一样,发现数据都用同一个,他还是传址,区别就在于他不只看一层了,对于复杂数据改变,他能知道了。嘿嘿,知道了,那就不能省事喽!
clear()是将字典清空,得到的是“空”字典。这个和del有着很大的区别。del是将字典删除,内存中就没有它了,不是为“空”
要清空一个字典a,还能够使用a = {}这种方法,但这种方法本质是将变量a转向了{}这个对象,那么原来的呢?原来的成为了断线的风筝。这样的东西在python中称之为垃圾,
而且python能够自动的将这样的垃圾回收。你就不用关心它了,反正python会处理。
.items()返回字典 键:值 对 .keys()返回字典的键 .values()返回字典的值
.get()就是要得到字典中某个键的值,举例d.get("name"),如果字典d有这个键"name"和对应键的值1,便返回这个键的值1,如果没有这个键"name"就返回None
但是如果没有键,却自己把键值对都写上,即d.get("name",2),那么就自欺欺人的返回值2,但字典还是原来样子,并没加上键值对‘’name‘’:2 ,这个函数仅仅是看看有没有
如果是.setdefault()就不一样,举例x.setdefault("name"),如果有键值对,返回就可以了,如果没有键值对,会创建键值对 “name”:None 如果这样写x.setdefault("name",6)
就会创建键值对“name”:6 还有.pop() 是t我弹出键值对,懒得打命令了,截图下,抱歉!

.update() 这个函数没有返回值,或者说返回值是None,它的作用就是更新字典。其参数可以是字典或者某种可迭代的数据类型。
>>> d1 = {"lang":"python"}
>>> d2 = {"song":"I dreamed a dream"}
>>> d1.update(d2)
>>> d1 {'lang': 'python', 'song': 'I dreamed a dream'}
>>> d2 {'song': 'I dreamed a dream'}
这样就把字典d2更新入了d1那个字典,于是d1中就多了一些内容,把d2的内容包含进来了。d2当然还存在,并没有受到影响
>>> d2 {'song': 'I dreamed a dream'}
>>> d2.update([("name","qiwsir"), ("web","itdiffer.com")]) #列表的元组是键值对
>>> d2
{'web': 'itdiffer.com', 'name': 'qiwsir', 'song': 'I dreamed a dream'}
.has_key() 这个函数的功能是判断字典中是否存在某个键
>>> d2 {'web': 'itdiffer.com', 'name': 'qiwsir', 'song': 'I dreamed a dream'}
>>> d2.has_key("web")
True
>>> "web" in d2
True
集合
在已经学过的数据类型中:
- 能够索引的,如list/str,其中的元素可以重复
- 可变的,如list/dict,即其中的元素/键值对可以原地修改
- 不可变的,如str/int,即不能进行原地修改
- 无索引序列的,如dict,即其中的元素(键值对)没有排列顺序
现在要介绍另外一种类型的数据,英文是set,叫做“集合”。用符号{} 它的特点是:有的可变,有的不可变;元素无次序,不可重复
无序当然就不能用索引了,不能切片喽,.add()添加一个元素 .discard()删除,有错不反馈 .remove()删除,有错反馈 .pop()随机弹出一个元素 .clear()原地清空所有元素
set()来建立集合,这种方式所创立的集合都是可原处修改的集合,或者说是可变的,也可以说是unhashable
还有一种集合,不能在原处修改。这种集合的创建方法是用frozenset(),顾名思义,这是一个被冻结的集合,当然是不能修改了,那么这种集合就是hashable类型——可哈希

.intersection()交集 .difference()差集 .union()并集 .issubset()子集 .issuperset()超集 .sysmmetric_difference()对称差集
dict() 构造函数可以直接从 key-value 对中创建字典
>>> dict([('sape', 4139), ('guido', 4127), ('jack', 4098)])
{'sape': 4139, 'jack': 4098, 'guido': 4127}
零基础Python知识点回顾(三)的更多相关文章
- 零基础Python知识点回顾(一)
如果你是小白,建议只要安装官网的python-3.7.0-amd64.exe 然后在电脑cmd命令提示符 输入检查是否已经安装pip,一般安装了python都会有的. >pip ...
- 零基础Python知识点回顾(二)
开始了,继续说!字符串替换,就是预留着空间,后边再定义要填上什么,这种叫字符串格式化,其有两种方法: % 和 format %s 就是一个占位符,这个占位符可以被其它的字符串代替 >&g ...
- 嵩天老师的零基础Python笔记:https://www.bilibili.com/video/av13570243/?from=search&seid=15873837810484552531 中的15-23讲
#coding=gbk#嵩天老师的零基础Python笔记:https://www.bilibili.com/video/av13570243/?from=search&seid=1587383 ...
- 嵩天老师的零基础Python笔记:https://www.bilibili.com/video/av15123607/?from=search&seid=10211084839195730432#page=25 中的42-45讲 {字典}
#coding=gbk#嵩天老师的零基础Python笔记:https://www.bilibili.com/video/av15123607/?from=search&seid=1021108 ...
- 嵩天老师的零基础Python笔记:https://www.bilibili.com/video/av13570243/?from=search&seid=15873837810484552531 中的1-14讲
#coding=gbk#嵩天老师的零基础Python笔记:https://www.bilibili.com/video/av13570243/?from=search&seid=1587383 ...
- 零基础JavaScript编码(三)总结
任务目的 在上一任务基础上继续JavaScript的体验 接触一下JavaScript中的高级选择器 学习JavaScript中的数组对象遍历.读写.排序等操作 学习简单的字符串处理操作 任务描述 参 ...
- 【雕爷学编程】零基础Python(01)---“投机取巧”的三条途径
从3月13日报名尝试上网课学习(4天课8.9元),开始接触Python(中文发音“派森”),到今天有一星期了.这两天广泛搜索了一下相关的学习途径,本着“投机取巧”的出发点,居然小有心得,这里一并分享出 ...
- [Python] 文科生零基础学编程系列三——数据运算符的基本类别
上一篇:[Python] 文科生零基础学编程系列二--数据类型.变量.常量的基础概念 下一篇: ※ 程序的执行过程,就是对数据进行运算的过程. 不同的数据类型,可以进行不同的运算, 按照数据运算类型的 ...
- 零基础Python应该怎样学习呢?(附视频教程)
Python应该怎样学习呢? 阶段一:适合自己的学习方式 对于零基础的初学者来说,最迷茫的是不知道怎样开始学习?那这里小编建议可以采用视频+书籍的方式进行学习.看视频学习可以让你迅速掌握编程的基础语法 ...
随机推荐
- 关于“System.Data.ProviderIncompatibleException”类型的异常
作为刚学习MVC的菜鸟,因为平常的不努力学习.看书,所以只能参考官方的教程学习操作新手入门 一步一步认真的做,前天晚上出现了一个关于数据库连接字符串错误的问题,自己查了很多资料, 问了许多大神,他们的 ...
- C# ADO.NET 面向对象
ADO.NET跟面向对象的结合 把面向对象跟数据库连接用 在项目里面创建一个新的文件夹 名字为App_Code 在这个App_Code里面创建几个类 主要为拆分问题,标上序号,先干什么在干什么 实 ...
- [LeetCode]29. Divide Two Integers两数相除
Given two integers dividend and divisor, divide two integers without using multiplication, division ...
- SVN服务器在Ubuntu16.04下搭建多版本库详细教程
1 介绍 Subversion是一个自由,开源的版本控制系统,这个版本库就像一个普通的文件服务器,不同的是,它可以记录每一次文件和目录的修改情况.这样就可 以很方面恢复到以前的版本,并可以查看数据 ...
- oracle学习篇十一:视图
视图是存储的查询定义. 1. 创建视图的语法如下: Create [OR REPLACE] [FORCE | NOFORCE] VIEW view_name[(alias,alias,...)] AS ...
- Web服务器父与子 Apache和Tomcat
Apache是世界使用排名第一的Web服务器软件.它可以运行在几乎所有广泛使用的计算机平台上,由于其跨平台和安全性被广泛使用,是最流行的Web服务器端软件之一.在Apache基金会里面Apache S ...
- .NET开源工作流RoadFlow-表单设计-单选按钮组
单选按钮组即:<input type='checkbox'/>控件: 绑定字段:与数据表的某个字段绑定. 数据源: 1.数据字典:在下面字段项中选择对应在数据字典项. 2.自定义:自己输入 ...
- Java性能调优实践
1 导论 JVM主要有两类调优标志:布尔标志和附带参数标志 布尔标志:-XX:+FlagName表示开启,-XX:-FlagName表示关闭. 附带参数标志:-XX:FlagName=somethi ...
- 关于移动App开发前端UI框架选择
问题:现在移动开发各种必须,而移动开发纠结在于怎样快速高效的开发出来. 做web开发有些年头了,成熟的前端套件(easyui,extjs,jqueryui)很是方便,可以开发出来规范一直的产品,各种组 ...
- Laravel SMS 短信发送包
Laravel Sms Laravel 贴合实际需求同时满足多种通道的短信发送组件 我们基于业务需求在 overtrue/easy-sms 基础进行扩展开发,主要实现如下目标: 支持短信验证码直接在 ...