RabbitMQ基础知识篇
1、Linux安装RabbitMQ。
参考网址:RPM安装RabbitMQ 仔细阅读。
先安装erlang:
su -c 'rpm -Uvh http://mirrors.neusoft.edu.cn/epel/epel-release-latest-7.noarch.rpm'
...
su -c 'yum install foo' ####################################
建议使用这个安装erlang库
wget https://packages.erlang-solutions.com/erlang-solutions-1.0-1.noarch.rpm# 这里还有http://www.rabbitmq.com/releases/erlang/ erlang的各个版本下载,安装这个即可。
rpm -Uvh erlang-solutions-1.0-1.noarch.rpm
####################################
yum install erlang
下载rabbitmq 的rpm包并安装
rpm --import https://www.rabbitmq.com/rabbitmq-release-signing-key.asc
yum install rabbitmq-server-3.6.2-1.noarch.rpm
安装时可能会报需要安装esl-erlang_16.b.3。这个可以到这里下载https://www.erlang-solutions.com/resources/download.html
2、开始编写rabbitmq代码,参照http://www.rabbitmq.com/getstarted.html,重点,下面就不写具体代码了。
cp /usr/share/doc/rabbitmq-server-3.6.2/rabbitmq.config.example /etc/rabbitmq/rabbitmq.config ,service rabbitmq-server restart
1)遇到的问题,报错:pika.exceptions.ProbableAuthenticationError,可以查看日志(重要):
tail -f /var/log/rabbitmq/rabbit\@Minion.log
=ERROR REPORT==== 27-Jun-2016::02:06:19 ===
Error on AMQP connection <0.542.0> (192.168.243.131:43681 -> 192.168.243.131:5672, state: starting):
PLAIN login refused: user 'guest' can only connect via localhost
解决办法:修改配置文件:%% {loopback_users, [<<"guest">>]}, 为 {loopback_users, []} ,service rabbitmq restart,参考http://www.rabbitmq.com/configure.html
2、rabbitmq-server启动,发送、接收、等各种命令执行慢的出奇,原因是dns配置问题。
3、no_ack = False(默认),就拿最简单的"hello world“来说,启动两个recive.py,callback()函数里面根据接收的消息的dot数来sleep,在send.py端连续发送7个消息(带6个点),这时停止一个recive.py,会看到这7个消息会发送到另一个recive.py。但是这里你会发现执行rabbitmqctl list_queues显示队列的消息数并没有减少。
这里呀no_ack = False应该只表示 revice告诉queue,我接收完消息会发acK的,但是发不发ack由:ch.basic_ack(delivery_tag = method.delivery_tag)控制,这个可以写到callback()最后面。
rabbitmqctl list_queues name messages_ready messages_unacknowledged可以看到没有收到ack的消息数量。
4、消息和队列持久化
队列持久化:
channel.queue_declare(queue='hello', durable=True)
消息持久化:
channel.basic_publish(exchange='',
routing_key="task_queue",
body=message,
properties=pika.BasicProperties(
delivery_mode = 2, # make message persistent
))
Note on message persistence
Marking messages as persistent doesn't fully guarantee that a message won't be lost. Although it tells RabbitMQ to save the message to disk, there is still a short time window when RabbitMQ has accepted a message and hasn't saved it yet. Also, RabbitMQ doesn't do fsync(2) for every message -- it may be just saved to cache and not really written to the disk. The persistence guarantees aren't strong, but it's more than enough for our simple task queue. If you need a stronger guarantee then you can use publisher confirms.
5、公平分发
In order to defeat that we can use the basic.qos method with the prefetch_count=1 setting. This tells RabbitMQ not to give more than one message to a worker at a time. Or, in other words, don't dispatch a new message to a worker until it has processed and acknowledged the previous one. Instead, it will dispatch it to the next worker that is not still busy.
channel.basic_qos(prefetch_count=1)
6、消息广播 ,下面这种方式当先开send的话,send的消息会丢失。
发送端定义exchange:
channel.exchange_declare(exchange='logs',
type='fanout')
channel.basic_publish(exchange='logs',
routing_key='',
body=message)
接收端绑定queue到exchange。
result = channel.queue_declare(exclusive=True) # exclusive=Ture,当客户端断开,则此queue也将随之被销毁。
channel.queue_bind(exchange='logs',
queue=result.method.queue) # 绑定queue 到 exchange
[root@test2 ~]# rabbitmqctl list_bindings
Listing bindings ...
logs exchange amq.gen-O86WeoCyhQu0YvjtJo7Dew queue amq.gen-O86WeoCyhQu0YvjtJo7Dew []
logs exchange amq.gen-fYeLgPULbT7hVLgahg21jQ queue amq.gen-fYeLgPULbT7hVLgahg21jQ []
7、消息路由,发送时指定exchange和routing_key,绑定了此routing_key的exchange和queue会接收到此消息。
A binding is a relationship between an exchange and a queue. This can be simply read as: the queue is interested in messages from this exchange.
Bindings can take an extra routing_key parameter. To avoid the confusion with abasic_publish parameter we're going to call it a binding key. This is how we could create a binding with a key:
channel.queue_bind(exchange=exchange_name,
queue=queue_name,
routing_key='black')
The meaning of a binding key depends on the exchange type. The fanout exchanges, which we used previously, simply ignored its value.
We will use a direct exchange instead. The routing algorithm behind a direct exchange is simple - a message goes to the queues whose binding key exactly matches the routing keyof the message.
To illustrate that, consider the following setup:
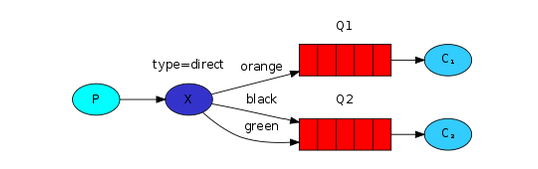
In this setup, we can see the direct exchange X with two queues bound to it. The first queue is bound with binding key orange, and the second has two bindings, one with binding key blackand the other one with green.
In such a setup a message published to the exchange with a routing key orange will be routed to queue Q1. Messages with a routing key of black or green will go to Q2. All other messages will be discarded.
一个binding_key也可以绑定到多个queue。
It is perfectly legal to bind multiple queues with the same binding key. In our example we could add a binding between X and Q1 with binding key black. In that case, the direct exchange will behave like fanout and will broadcast the message to all the matching queues. A message with routing key black will be delivered to both Q1 and Q2.
发送端:
Like always we need to create an exchange first:
channel.exchange_declare(exchange='direct_logs',
type='direct')
And we're ready to send a message:
channel.basic_publish(exchange='direct_logs',
routing_key=severity,
body=message)
To simplify things we will assume that 'severity' can be one of 'info', 'warning', 'error'.
接收端:
Receiving messages will work just like in the previous tutorial, with one exception - we're going to create a new binding for each severity we're interested in.
result = channel.queue_declare(exclusive=True)
queue_name = result.method.queue for severity in severities:
channel.queue_bind(exchange='direct_logs',
queue=queue_name,
routing_key=severity)
启动接收端:python receive_logs_direct.py info warning error
在rabbitmq-server服务器:rabbitmqctl list_bindings
direct_logs exchange amq.gen-W4eTG2YC97A9aMwBVxeJJQ queue error []
direct_logs exchange amq.gen-W4eTG2YC97A9aMwBVxeJJQ queue info []
direct_logs exchange amq.gen-2jS9NghfwuydRFdY5XHkhw queue info []
direct_logs exchange amq.gen-W4eTG2YC97A9aMwBVxeJJQ queue warning []
8、更复杂的消息路由
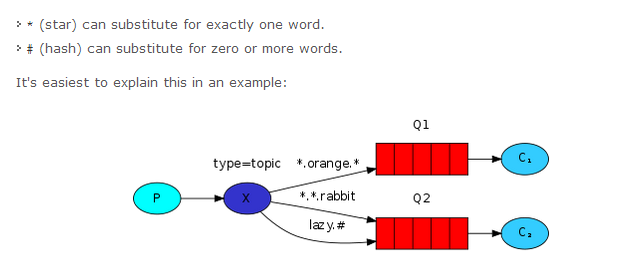
In this example, we're going to send messages which all describe animals. The messages will be sent with a routing key that consists of three words (two dots). The first word in the routing key will describe a celerity, second a colour and third a species: "<celerity>.<colour>.<species>".
We created three bindings: Q1 is bound with binding key "*.orange.*" and Q2 with "*.*.rabbit" and "lazy.#".
These bindings can be summarised as:
- Q1 is interested in all the orange animals.
- Q2 wants to hear everything about rabbits, and everything about lazy animals.
A message with a routing key set to "quick.orange.rabbit" will be delivered to both queues. Message "lazy.orange.elephant" also will go to both of them. On the other hand "quick.orange.fox" will only go to the first queue, and "lazy.brown.fox" only to the second. "lazy.pink.rabbit" will be delivered to the second queue only once, even though it matches two bindings. "quick.brown.fox" doesn't match any binding so it will be discarded.
What happens if we break our contract and send a message with one or four words, like "orange" or "quick.orange.male.rabbit"? Well, these messages won't match any bindings and will be lost.
On the other hand "lazy.orange.male.rabbit", even though it has four words, will match the last binding and will be delivered to the second queue.
9、消息属性,通过在send端,basic_publish(properties = pika.BasicProperties(xx=xxx)配置。
Message properties
The AMQP protocol predefines a set of 14 properties that go with a message. Most of the properties are rarely used, with the exception of the following:
- delivery_mode: Marks a message as persistent (with a value of 2) or transient (any other value). You may remember this property from the second tutorial.
- content_type: Used to describe the mime-type of the encoding. For example for the often used JSON encoding it is a good practice to set this property to:application/json.
- reply_to: Commonly used to name a callback queue.
- correlation_id: Useful to correlate RPC responses with requests.
10、RPC
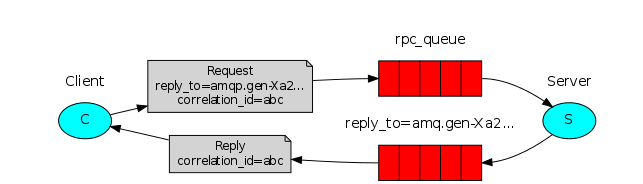
Our RPC will work like this:
- When the Client starts up, it creates an anonymous exclusive callback queue.
- For an RPC request, the Client sends a message with two properties: reply_to, which is set to the callback queue and correlation_id, which is set to a unique value for every request.
- The request is sent to an rpc_queue queue.
- The RPC worker (aka: server) is waiting for requests on that queue. When a request appears, it does the job and sends a message with the result back to the Client, using the queue from the reply_to field.
- The client waits for data on the callback queue. When a message appears, it checks the correlation_id property. If it matches the value from the request it returns the response to the application.
The code for rpc_server.py:
#!/usr/bin/env python
import pika connection = pika.BlockingConnection(pika.ConnectionParameters(
host='localhost')) channel = connection.channel() channel.queue_declare(queue='rpc_queue') def fib(n):
if n == 0:
return 0
elif n == 1:
return 1
else:
return fib(n-1) + fib(n-2) def on_request(ch, method, props, body):
n = int(body) print(" [.] fib(%s)" % n)
response = fib(n) ch.basic_publish(exchange='',
routing_key=props.reply_to,
properties=pika.BasicProperties(correlation_id = \
props.correlation_id),
body=str(response))
ch.basic_ack(delivery_tag = method.delivery_tag) channel.basic_qos(prefetch_count=1)
channel.basic_consume(on_request, queue='rpc_queue') print(" [x] Awaiting RPC requests")
channel.start_consuming()
The server code is rather straightforward:
- (4) As usual we start by establishing the connection and declaring the queue.
- (11) We declare our fibonacci function. It assumes only valid positive integer input. (Don't expect this one to work for big numbers, it's probably the slowest recursive implementation possible).
- (19) We declare a callback for basic_consume, the core of the RPC server. It's executed when the request is received. It does the work and sends the response back.
- (32) We might want to run more than one server process. In order to spread the load equally over multiple servers we need to set the prefetch_count setting.
The code for rpc_client.py:
#!/usr/bin/env python
import pika
import uuid class FibonacciRpcClient(object):
def __init__(self):
self.connection = pika.BlockingConnection(pika.ConnectionParameters(
host='localhost')) self.channel = self.connection.channel() result = self.channel.queue_declare(exclusive=True)
self.callback_queue = result.method.queue self.channel.basic_consume(self.on_response, no_ack=True,
queue=self.callback_queue) def on_response(self, ch, method, props, body):
if self.corr_id == props.correlation_id:
self.response = body def call(self, n):
self.response = None
self.corr_id = str(uuid.uuid4())
self.channel.basic_publish(exchange='',
routing_key='rpc_queue',
properties=pika.BasicProperties(
reply_to = self.callback_queue,
correlation_id = self.corr_id,
),
body=str(n))
while self.response is None:
self.connection.process_data_events()
return int(self.response) fibonacci_rpc = FibonacciRpcClient() print(" [x] Requesting fib(30)")
response = fibonacci_rpc.call(30)
print(" [.] Got %r" % response)
The client code is slightly more involved:
- (7) We establish a connection, channel and declare an exclusive 'callback' queue for replies.
- (16) We subscribe to the 'callback' queue, so that we can receive RPC responses.
- (18) The 'on_response' callback executed on every response is doing a very simple job, for every response message it checks if the correlation_id is the one we're looking for. If so, it saves the response in self.response and breaks the consuming loop.
- (23) Next, we define our main call method - it does the actual RPC request.
- (24) In this method, first we generate a unique correlation_id number and save it - the 'on_response' callback function will use this value to catch the appropriate response.
- (25) Next, we publish the request message, with two properties: reply_to andcorrelation_id.
- (32) At this point we can sit back and wait until the proper response arrives.
- (33) And finally we return the response back to the user.
Our RPC service is now ready. We can start the server:
$ python rpc_server.py
[x] Awaiting RPC requests
To request a fibonacci number run the client:
$ python rpc_client.py
[x] Requesting fib(30)
The presented design is not the only possible implementation of a RPC service, but it has some important advantages:
- If the RPC server is too slow, you can scale up by just running another one. Try running a second rpc_server.py in a new console.
- On the client side, the RPC requires sending and receiving only one message. No synchronous calls like queue_declare are required. As a result the RPC client needs only one network round trip for a single RPC request.
Our code is still pretty simplistic and doesn't try to solve more complex (but important) problems, like:
- How should the client react if there are no servers running?
- Should a client have some kind of timeout for the RPC?
- If the server malfunctions and raises an exception, should it be forwarded to the client?
- Protecting against invalid incoming messages (eg checking bounds) before processing.
下章将分析上面这几个问题。
RabbitMQ基础知识篇的更多相关文章
- RabbitMQ基础知识
RabbitMQ基础知识 一.背景 RabbitMQ是一个由erlang开发的AMQP(Advanced Message Queue )的开源实现.AMQP 的出现其实也是应了广大人民群众的需求,虽然 ...
- 转:RabbitMQ基础知识
RabbitMQ基础知识 一.背景 RabbitMQ是一个由erlang开发的AMQP(Advanced Message Queue )的开源实现.AMQP 的出现其实也是应了广大人民群众的需求,虽然 ...
- RabbitMQ基础知识(转载)
RabbitMQ基础知识(转载) 一.背景 RabbitMQ是一个由erlang开发的AMQP(Advanced Message Queue )的开源实现.AMQP 的出现其实也是应了广大人民群众的需 ...
- 【Java面试】基础知识篇
[Java面试]基础知识篇 Java基础知识总结,主要包括数据类型,string类,集合,线程,时间,正则,流,jdk5--8各个版本的新特性,等等.不足的地方,欢迎大家补充.源码分享见个人公告.Ja ...
- 【Java面试】1、基础知识篇
[Java面试]基础知识篇 Java基础知识总结,主要包括数据类型,string类,集合,线程,时间,正则,流,jdk5--8各个版本的新特性,等等.不足的地方,欢迎大家补充. 源码分享:https: ...
- RabbitMQ基础知识详解
什么是MQ? MQ全称为Message Queue, 消息队列(MQ)是一种应用程序对应用程序的通信方法.MQ是消费-生产者模型的一个典型的代表,一端往消息队列中不断写入消息,而另一端则可以读取队列中 ...
- RabbitMQ,Apache的ActiveMQ,阿里RocketMQ,Kafka,ZeroMQ,MetaMQ,Redis也可实现消息队列,RabbitMQ的应用场景以及基本原理介绍,RabbitMQ基础知识详解,RabbitMQ布曙
消息队列及常见消息队列介绍 2017-10-10 09:35操作系统/客户端/人脸识别 一.消息队列(MQ)概述 消息队列(Message Queue),是分布式系统中重要的组件,其通用的使用场景可以 ...
- Java白皮书学习笔记+Head First Java--用于自我复习 基础知识篇
本笔记是摘与Hava白皮书上面的内容,用来给自己做提醒的,因此大概并不适合Java的学习者作为笔记参考使用. 以我的水平现在还看不懂这个... 一.基础知识篇 1.常量 final关键字指示常量,只能 ...
- Java 面试知识点解析(一)——基础知识篇
前言: 在遨游了一番 Java Web 的世界之后,发现了自己的一些缺失,所以就着一篇深度好文:知名互联网公司校招 Java 开发岗面试知识点解析 ,来好好的对 Java 知识点进行复习和学习一番,大 ...
随机推荐
- git手动解决内容冲突
<span style="font-size:18px;">git checkout -b lab4 origin/lab4 git merge lab3</sp ...
- dynamic的好处
dynamic 可在反射.json反序列化时使用.已达到减少代码量的效果.看代码 using System; namespace ConsoleApp2 { class Program { stati ...
- vs2010 does not have a strong name
处理步骤: C:\myWorkSpace\IECG Dev. Tool\Forklift\DbUpgraderDLL\bin\Debug 为dll 所在目录 DbUpgraderDLL.dll为dll ...
- PHP删除目录
function delDir($directory) { if(file_exists($directory)) { $dir_handle = @opendir($directory); if($ ...
- 将以太坊封装为 ERC20
将以太坊封装为 ERC20 TOKEN 很多 DAPP 都是在处理 ERC20接口的 token, 其实很容易将以太坊封装为 ERC20,这样就可以统一处理, 至少我目前在做的雷电网络就是这么处理的. ...
- [转]解读Unity中的CG编写Shader系列二
上一篇文章的例子中我们可以看到顶点着色器的输出参数可以说是直接作为了片段着色器的形参传递过来,那么不由得一个问题浮现出来,顶点着色器的形参是从何处传递过来的? 顶点着色器的形参是gameObject ...
- OC语言自定义打印
1.为了全文通用,选择在PCH文件中写: // // 版权所有:Copyright © 2018年 Lelight. All rights reserved. // 创 建 者: Lelight // ...
- 原生态js,返回至顶部
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- Kubernetes -- Server 部署
1. Node 节点配置文件 1.1 下载相关的软件 wget https://dl.k8s.io/v1.13.1/kubernetes-server-linux-amd64.tar.gz wget ...
- ASP Session 对象
http://www.w3school.com.cn/asp/asp_sessions.asp