GBDT,随机森林
author:yangjing
time:2018-10-22
Gradient boosting decision tree
1.main diea
The main idea behind GBDT is to combine many simple models(also known as week kernels),like shallow trees.Each tree can only provide good predictions on part of the data,and so more and more trees are added to iteratively improve performance.
2.parameters setting
the algorithm is a bit more sensitive to parameter settings than random forests,but can provide better accuracy if the parameters are set correctly.
- number of trees
By increasing n_estimators ,also increasing the model complexity,as the model has more chances to correct misticks on the training set. - learning rate
controns how strongly each tree tries to correct the misticks of the previous trees.A higher learning rate means each tree can make stronger correctinos,allowing for more complex models. - max_depth
or alternatively max_leaf_nodes.Usyally max_depth is set very low for gradient-boosted models,often not deeper than five splits.
3.code
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_breast_cancer
cancer=load_breast_cancer()
X_train,X_test,y_train,y_test=train_test_split(cancer.data,cancer.target,random_state=0)
gbrt=GradientBoostingClassifier(random_state=0)
gbrt.fit(X_train,y_train)
gbrt.score(X_test,y_test)
In [261]: X_train,X_test,y_train,y_test=train_test_split(cancer.data,cancer.target,random_state=0)
...: gbrt=GradientBoostingClassifier(random_state=0)
...: gbrt.fit(X_train,y_train)
...: gbrt.score(X_test,y_test)
...:
Out[261]: 0.958041958041958
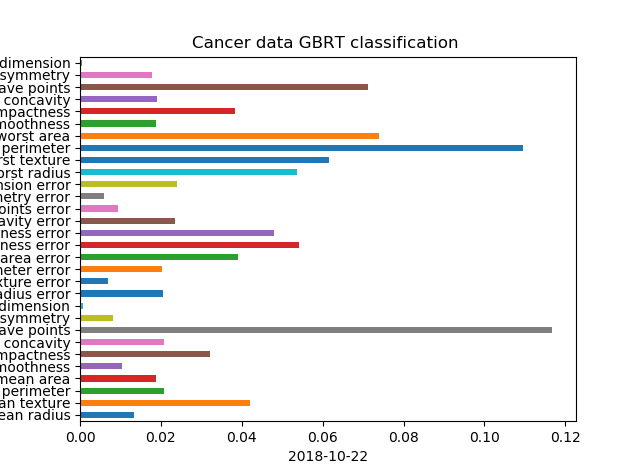
In [262]: gbrt.feature_importances_
Out[262]:
array([0.01337291, 0.04201687, 0.0208666 , 0.01889077, 0.01028091,
0.03215986, 0.02074619, 0.11678956, 0.00820024, 0.00074312,
0.02042134, 0.00680047, 0.02023052, 0.03907398, 0.05406751,
0.04795741, 0.02358101, 0.00934718, 0.00593481, 0.0239241 ,
0.05354265, 0.06160083, 0.10961728, 0.07395201, 0.01867851,
0.03842953, 0.01915824, 0.07128703, 0.01773659, 0.00059199])
In [263]: gbrt.learning_rate
Out[263]: 0.1
In [264]: gbrt.max_depth
Out[264]: 3
In [265]: len(gbrt.estimators_)
Out[266]: 100
In [272]: gbrt.get_params()
Out[272]:
{'criterion': 'friedman_mse',
'init': None,
'learning_rate': 0.1,
'loss': 'deviance',
'max_depth': 3,
'max_features': None,
'max_leaf_nodes': None,
'min_impurity_decrease': 0.0,
'min_impurity_split': None,
'min_samples_leaf': 1,
'min_samples_split': 2,
'min_weight_fraction_leaf': 0.0,
'n_estimators': 100,
'presort': 'auto',
'random_state': 0,
'subsample': 1.0,
'verbose': 0,
'warm_start': False}
Random forest
In [230]: y
Out[230]:
array([1, 1, 0, 1, 1, 1, 1, 0, 0, 0, 1, 0, 1, 1, 0, 1, 1, 0, 1, 0, 1, 0,
0, 0, 1, 1, 0, 1, 0, 1, 0, 0, 0, 0, 1, 0, 1, 1, 0, 0, 0, 0, 0, 0,
1, 1, 1, 1, 1, 0, 1, 1, 1, 1, 0, 1, 1, 1, 1, 1, 0, 1, 1, 1, 0, 1,
0, 0, 0, 0, 0, 1, 1, 0, 1, 1, 0, 1, 1, 0, 1, 0, 1, 0, 0, 0, 0, 0,
0, 1, 0, 0, 1, 0, 0, 0, 1, 1, 0, 0], dtype=int64)
In [231]: axes.ravel()
Out[231]:
array([<matplotlib.axes._subplots.AxesSubplot object at 0x000001F46F3694A8>,
<matplotlib.axes._subplots.AxesSubplot object at 0x000001F46C099F28>,
<matplotlib.axes._subplots.AxesSubplot object at 0x000001F46E6E3BE0>,
<matplotlib.axes._subplots.AxesSubplot object at 0x000001F46BEB72E8>,
<matplotlib.axes._subplots.AxesSubplot object at 0x000001F46ED67198>,
<matplotlib.axes._subplots.AxesSubplot object at 0x000001F46F292C88>],
dtype=object)
In [232]: from sklearn.model_selection import train_test_split
In [233]: X_trai,X_test,y_train,y_test=train_test_split(X,y,stratify=y,random_state=42)
In [234]: len(X_trai)
Out[234]: 75
In [235]: fores=RandomForestClassifier(n_estimators=5,random_state=2)
In [236]: fores.fit(X_trai,y_train)
Out[236]:
RandomForestClassifier(bootstrap=True, class_weight=None, criterion='gini',
max_depth=None, max_features='auto', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=1, min_samples_split=2,
min_weight_fraction_leaf=0.0, n_estimators=5, n_jobs=1,
oob_score=False, random_state=2, verbose=0, warm_start=False)
In [237]: fores.score(X_test,y_test)
Out[237]: 0.92
In [238]: fores.estimators_
Out[238]:
[DecisionTreeClassifier(class_weight=None, criterion='gini', max_depth=None,
max_features='auto', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=1, min_samples_split=2,
min_weight_fraction_leaf=0.0, presort=False,
random_state=1872583848, splitter='best'),
DecisionTreeClassifier(class_weight=None, criterion='gini', max_depth=None,
max_features='auto', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=1, min_samples_split=2,
min_weight_fraction_leaf=0.0, presort=False,
random_state=794921487, splitter='best'),
DecisionTreeClassifier(class_weight=None, criterion='gini', max_depth=None,
max_features='auto', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=1, min_samples_split=2,
min_weight_fraction_leaf=0.0, presort=False,
random_state=111352301, splitter='best'),
DecisionTreeClassifier(class_weight=None, criterion='gini', max_depth=None,
max_features='auto', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=1, min_samples_split=2,
min_weight_fraction_leaf=0.0, presort=False,
random_state=1853453896, splitter='best'),
DecisionTreeClassifier(class_weight=None, criterion='gini', max_depth=None,
max_features='auto', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=1, min_samples_split=2,
min_weight_fraction_leaf=0.0, presort=False,
random_state=213298710, splitter='best')]
GBDT,随机森林的更多相关文章
- ObjectT5:在线随机森林-Multi-Forest-A chameleon in track in
原文::Multi-Forest:A chameleon in tracking,CVPR2014 下的蛋...原文 使用随机森林的优势,在于可以使用GPU把每棵树分到一个流处理器里运行,容易并行化 ...
- 机器学习中的算法(1)-决策树模型组合之随机森林与GBDT
版权声明: 本文由LeftNotEasy发布于http://leftnoteasy.cnblogs.com, 本文可以被全部的转载或者部分使用,但请注明出处,如果有问题,请联系wheeleast@gm ...
- 机器学习中的算法——决策树模型组合之随机森林与GBDT
前言: 决策树这种算法有着很多良好的特性,比如说训练时间复杂度较低,预测的过程比较快速,模型容易展示(容易将得到的决策树做成图片展示出来)等.但是同时,单决策树又有一些不好的地方,比如说容易over- ...
- 决策树模型组合之(在线)随机森林与GBDT
前言: 决策树这种算法有着很多良好的特性,比如说训练时间复杂度较低,预测的过程比较快速,模型容易展示(容易将得到的决策树做成图片展示出来)等.但是同时, 单决策树又有一些不好的地方,比如说容易over ...
- 机器学习中的算法-决策树模型组合之随机森林与GBDT
机器学习中的算法(1)-决策树模型组合之随机森林与GBDT 版权声明: 本文由LeftNotEasy发布于http://leftnoteasy.cnblogs.com, 本文可以被全部的转载或者部分使 ...
- 随机森林与GBDT
前言: 决策树这种算法有着很多良好的特性,比如说训练时间复杂度较低,预测的过程比较快速,模型容易展示(容易将得到的决策树做成图片展示出来)等.但是同时,单决策树又有一些不好的地方,比如说容易over- ...
- 决策树模型组合之随机森林与GBDT
版权声明: 本文由LeftNotEasy发布于http://leftnoteasy.cnblogs.com, 本文可以被全部的转载或者部分使用,但请注明出处,如果有问题,请联系wheeleast@gm ...
- 随机森林和GBDT
1. 随机森林 Random Forest(随机森林)是Bagging的扩展变体,它在以决策树 为基学习器构建Bagging集成的基础上,进一步在决策树的训练过程中引入了随机特征选择,因此可以概括RF ...
- 随机森林RF、XGBoost、GBDT和LightGBM的原理和区别
目录 1.基本知识点介绍 2.各个算法原理 2.1 随机森林 -- RandomForest 2.2 XGBoost算法 2.3 GBDT算法(Gradient Boosting Decision T ...
随机推荐
- luogu P1938找工就业
一头牛在一个城市最多只能赚D元,然后它必须到另一个城市工作.当然它可以在别处工作一阵子后,又回到原来的城市再最多赚D美元.而且这样的往返次数没有限制城市间有P条单向路径,共有C座城市,编号1~C,奶牛 ...
- hdu6158(圆的反演)
hdu6158 题意 初始有两个圆,按照标号去放圆,问放完 \(n\) 个圆后的总面积. 分析 圆的反演的应用. 参考blog 设反演圆心为 \(O\) 和反演半径 \(R\) 圆的反演的定义: 已知 ...
- 树链剖分【p4114】Qtree-Query on a tree I
Description 给定一棵n个节点的树,有两个操作: CHANGE i ti 把第i条边的边权变成ti QUERY a b 输出从a到b的路径中最大的边权,当a=b的时候,输出0 Input 第 ...
- hiho一下第134周 1468 : 2-SAT·hihoCoder新春晚会
1468 : 2-SAT·hihoCoder新春晚会 时间限制:10000ms 单点时限:1000ms 内存限制:256MB 描述 hihoCoder新春晚会正在紧张地筹备中.晚会分为上半场和下半场, ...
- UVA548 Tree (二叉树的遍历)
You are to determine the value of the leaf node in a given binary tree that is the terminal node of ...
- Linux命令之free
free [选项] 显示系统中未使用和使用的内存情况,包括物理内存.交换区内存(swap)和内核缓冲区内存.共享内存将被忽略. (1).选项 -b,-k,-m,-g 以Byte,KB,MB,GB为单位 ...
- 【数论】【快速幂】bzoj1008 [HNOI2008]越狱
根据 高中的数学知识 即可推出 ans=m^n-m*(m-1)^(n-1) .快速幂取模搞一下即可. #include<cstdio> using namespace std; typed ...
- 【最短路】【spfa】CODEVS 2645 Spore
spfa最短路+判负权回路(是否某个点入队超过n次). #include<cstdio> #include<queue> #include<cstring> usi ...
- Bean实例化(三种方法)
(一)构造器实例化Bean 1. Bean1.java package com.inspur.ioc; public class Bean1 { } 2.Beans1.xml <?xml ver ...
- React Native学习之自定义Navigator
Navigator还是最常用的组件, 所以自己封装了一个, 使用起来也比较简单, 如下: 首先导入组件 var MLNavigator = require('../Lib/MLNavigator'); ...