基于BP神经网络的字符识别研究
基于BP神经网络的字符识别研究
原文作者:Andrew Kirillov. http://www.codeproject.com/KB/cs/neural_network_ocr.aspx
摘要:本文通过对人工智能课程中BP神经网络的学习,基于一个神经网络的开源项目,开发实现了一个简易的字符识别系统,并给出了较为理想的实验效果。该系统可以在手写体,印刷体字符识别上有广泛的应用。
关键词:BP神经网络; 字符识别;开源;AForge.NET
0 引言
在处理光学字符识别(OCR)问题上有很多种方法,最常见和流行的方法是基于神经网络的方法,它可以应用到不同的任务中,如模式识别,时间序列预测,函数逼近,聚类等等 。本文讨论了利用人工神经网络来进行OCR的方法,并给出一个例子。
1 流行的方法
在处理OCR问题上,最流行的且简单的方法是基于前馈神经网络的反向传播学习方法。其主要思想是,我们先准备一个训练集,然后利用训练集,使用神经网络的方法,得到识别摸式。 在训练阶段,我们教会网络根据指定的输入产生相应的输出。 为此,每一个训练样本是由两个部分组成:可能的输入和对应网络的输出。当训练结束后,我们可以给出任意输入传给网络,该网络将形成一个输出,由此该网络具有一种识别模式。 现在假设我们要训练一个网络,用来识别以
5×6点阵方式表示的26个大写英文字母,如图所示:

要将图像转换成一个训练样本的输入部分,最明显的方法是创建一个大小为30向量(在我们的情况下),“1”表示前景像素,“0”表示背景像素。但是在许多神经网络的训练任务中,它的首选是所谓的“双极”的训练模式,即输入向量用“0.5”代替“1”,用“-0.5”代替“0”。这种编码方式可以有更好的学习性能,这样,我们的训练样本就是这个样子:
float[] input_letterK = new float[] {
0.5f, -0.5f, -0.5f, 0.5f, 0.5f,
0.5f, -0.5f, 0.5f, -0.5f, -0.5f,
0.5f, 0.5f, -0.5f, -0.5f, -0.5f,
0.5f, -0.5f, 0.5f, -0.5f, -0.5f,
0.5f, -0.5f, -0.5f, 0.5f, -0.5f,
0.5f, -0.5f, -0.5f, -0.5f, 0.5f};
对于每一个可能的输入,我们需要建立一个相应的网络输出来完成训练样本。对于OCR的任务,把每个模式表示为矢量大小为26比较合适(因为我们有26个不同的字母),把“0.5”赋值给相应模式的位置,其他位置则被赋值“-0.5” ,因此,一个字母“K”输出向量看起来像这样:
我们看到只有K位置被赋值0.5,其他位置都是-0.5
float[] output_letterK = new float[] {
-0.5f, -0.5f, -0.5f, -0.5f, -0.5f,
-0.5f, -0.5f, -0.5f, -0.5f, -0.5f,
0.5f, -0.5f, -0.5f, -0.5f, -0.5f,
-0.5f, -0.5f, -0.5f, -0.5f, -0.5f,
-0.5f, -0.5f, -0.5f, -0.5f, -0.5f,
-0.5f};
有了所有26个字母作为训练样本,我们就可以开始训练网络了。最后一个问题是关于网络的结构。对于上述任务,我们可以使用一个层的神经网络,对应的输入向量大小30,输出向量的大小为26。
部分代码:
// pattern size
int patternSize = 30;
// patterns count
int patterns = 26;
// learning input vectors
float[][] input = new float[26][]
{
...
new float [] {
0.5f, -0.5f, -0.5f, 0.5f, 0.5f,
0.5f, -0.5f, 0.5f, -0.5f, -0.5f,
0.5f, 0.5f, -0.5f, -0.5f, -0.5f,
0.5f, -0.5f, 0.5f, -0.5f, -0.5f,
0.5f, -0.5f, -0.5f, 0.5f, -0.5f,
0.5f, -0.5f, -0.5f, -0.5f, 0.5f}, // Letter K
...
};
// learning ouput vectors
float[][] output = new float[26][]
{
...
new float [] {
-0.5f, -0.5f, -0.5f, -0.5f, -0.5f,
-0.5f, -0.5f, -0.5f, -0.5f, -0.5f,
0.5f, -0.5f, -0.5f, -0.5f, -0.5f,
-0.5f, -0.5f, -0.5f, -0.5f, -0.5f,
-0.5f, -0.5f, -0.5f, -0.5f, -0.5f,
-0.5f}, // Letter K
...
};
// create neural network
AForge.NeuralNet.Network neuralNet =
new AForge.NeuralNet.Network(new BipolarSigmoidFunction(2.0f),
patternSize, patterns);
// randomize network`s weights
neuralNet.Randomize();
// create network teacher
AForge.NeuralNet.Learning.BackPropagationLearning teacher = new
AForge.NeuralNet.Learning.BackPropagationLearning(neuralNet);
teacher.LearningLimit = 0.1f;
teacher.LearningRate = 0.5f;
// teach the network
int i = 0;
do
{
teacher.LearnEpoch(input, output);
i++;
}
while (!teacher.IsConverged);
System.Diagnostics.Debug.WriteLine("total learning epoch:" + i);
上面的代码提供了一个完整的针对模式识别任务的神经网络训练代码。在每一个学习阶段,所有训练集样本都提供给了网络,错误信息也被同时计算, 当错误小于指定的错误值,训练结束,网络就可以用来识别字符了。
如何识别呢? 我们需要提供输入给一个训练好的网络,并得到它的输出。然后我们找到那个在输出向量中具有最大值的元素,那个元素的值就是我们所要识别的结果。
// "K" letter, but a little bit noised
float[] pattern = new float [] {
0.5f, -0.5f, -0.5f, 0.5f, 0.5f,
0.5f, -0.5f, 0.5f, -0.5f, 0.5f,
0.5f, 0.5f, -0.5f, -0.5f, -0.5f,
0.5f, -0.5f, 0.5f, -0.5f, -0.5f,
0.5f, -0.5f, -0.5f, 0.5f, -0.5f,
0.3f, -0.5f, -0.5f, 0.5f, 0.5f};
// get network's output
float[] output = neuralNet.Compute(pattern);
int i, n, maxIndex = 0;
// find the maximum from output
float max = output[0];
for (i = 1, n = output.Length; i < n; i++)
{
if (output[i] > max)
{
max = output1[i];
maxIndex = i;
}
}
System.Diagnostics.Debug.WriteLine("network thinks it is - " + (char)((int) 'A' + maxIndex));
2 另一种方法
上面描述的方法工作得很好。但也有一些问题。假设我们使用上述大小为5x6字母训练我们的网络。当碰到一个8x8图像表示的字母我们应该怎样做?答案显然是要调整图片的大小。但是,对于那些包含一个字母是用字体大小为72打印的图像我们又怎么办? 如果把它缩小到5x6的图像,识别的结果应该不会很好。好,为提供精度,让我们用8X8图像,或者16x16图像来训练网络,但是,16x16图像将需要一个大小为256的输入向量,这将消耗更多的性能来训练神经网络。
另一个想法是基于使用所谓的接受器(receptor)。 假设我们有一个任意大小的字母图像,在这种方法中,我们不使用点阵像素值作为输入向量,而使用接受器值 receptor values,这些接受器是什么呢?接受器表示为一个具有任意大小和方向的多个行的集合。任何接受器如果和字母相交这输入向量值为0.5, 如果不和字母相交则输入向量值为-0.5, 一个输入向量的大小将和接受器的数量相同。顺便说一下,我们可以使用一个小的水平的和垂直的接受器集合,来获得和用像素值表示的小尺寸图像的相同效果。 如图:
这种方法的优点是,我们能够用少量的接受器训练大图像的神经网络。调整一副包含字母的图像到75x75像素(甚至150x150)将不会产生一个低质量的图像,所以它会更容易来识别。另一方面,我们总是可以轻松地调整我们的接受器集,因为它们定义为包含两个坐标的多个行。另一大优势是,我们可以尝试产生一个相当小的接受器集合,它只用最显著的字母特征来识别出整个训练集。这个方法也有一些缺点,这个方法只能应用于OCR任务, 它不能识别复杂的图案,原因是我们需要太多的接受器来表示特征。 如果我们正在做OCR识别领域上的研究,就不会受到太多干扰。还有另外一个更困难的问题,如何生成接受器集?手动还是随机? 如何确保集合是最优的? 我们可以用下面的方法来生成接受器:首先,我们将随机生成一个大的接受器的集合, 然后我们会选择一个指定的最合适的接受器数量,如何指定接受器数量是好还是不好?我们将尝试用信息论里的熵。
用一个小例子解释一下:
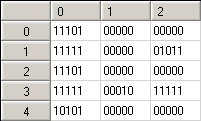
这里有一个表,包含了一些训练数据。在这里我们可以看到五个对象(用行表示), 和三个接受器(用列表示),每个对象有五个不同的变量。举例来说,表的第一个值“11101”意味着,第一个接受器和第一个对象的第一个变量交叉,它也和第二,第三和第五个的变量交叉,但它不和第四个变量交叉。让我们在看看第五行第一列:这个接受器和第一,第三和第五的变量交叉,但它并没有和第二个和第四个变量交叉。
我们将使用两个概念:内熵和外熵。内熵是一个为指定对象的接受器的熵。内熵会告诉我们识别指定对象的接受器有多好,其值应尽可能的小。让我们来看看第二行第一列,其中有“11111”。该集合的熵应该为0,这是很好的,因为这种接受器将有100%的把握来确定正在识别第二个对象,因为该接受器的值和指定对象的所有变量值相同。同样在第二行第二列:“00000”,它的熵也为0。但是,让我们来看看第五行第一列:“10101”。该集合的熵为0.971,这个值不大好,因为接受器不确定是不是指定的对象。外部熵是对整个列计算,值越接近“1”越好。为什么呢?因为如果外部熵的值比较小,则该接受器是无用的,因为它不能区分图案。最好的接受器是,所有的对象一半被激活另一半停止。因此,接受器的可用性计算公式为:
usability = OuterEntropy * ( 1 - AverageInnerEntropy)
平均内熵(AverageInnerEntropy)指的是所有对象的内熵之和除以对象的总数。
基于此,最初我们应该随机生成一个大的接受器集,例如500,然后我们用这些接受器来生成临时的训练输入值。在这个数据的基础上,我们可以用预先定义的接受器过滤值来过滤,比如我们可以使用值100。过滤程序将减少训练数据和神经网络的输入计数值。然后,在筛选的训练数据基础上,我们可以继续用上面的方法以同样的方式来训练我们的网络。
3 测试应用程序
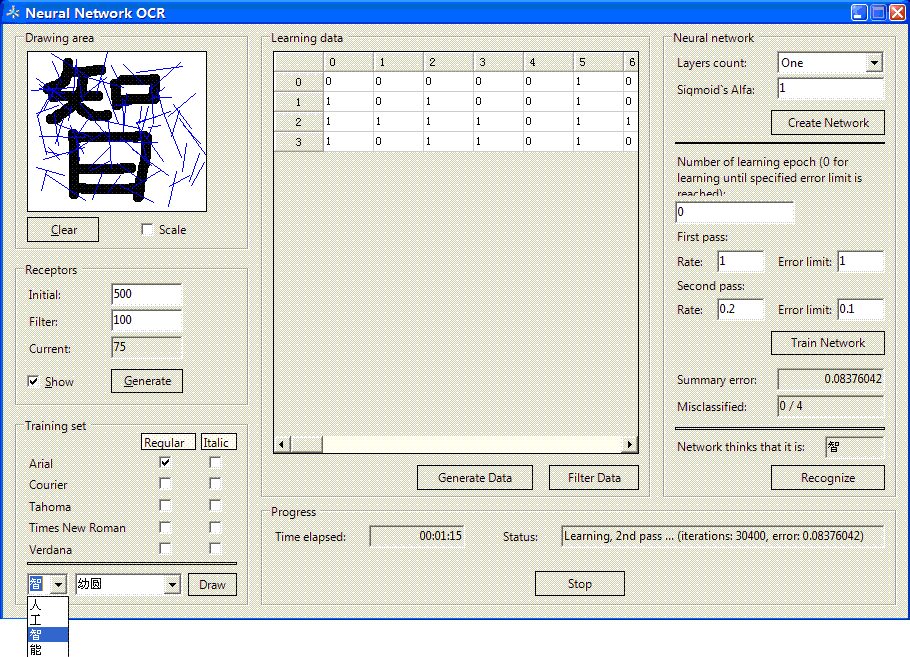
(原来的程序是识别26个英文大写字母,这里我改成识别中文字符“人工智能”四个字,并且换成幼圆字体来训练网络,幼圆字体和鼠标画汉字的图像差不多,经测试识别效果理想。)
这里我们用一个测试应用程序来实现第二种方式,该程序使用了一个开源软件库AForge.NET
AForge.NET (www.aforgenet.com)是一个用C#语言写的开源软件,它可用在机器视觉和人工智能领域:图像处理,神经网络,遗传算法,机器学习,机器人等等,作者是英国的一个软件工程师Andrew Kirillov.
让我们尝试的第一个测试:
1)我们需要产生的初始接受器集。在应用程序启动它已经产生的,如果不打算改变最初的接受器数量或过滤数量,可以跳过这一步。
2)选择字体用来训练网络。第一次定义为Arial字体。
3)生成数据。在这一步的产生初始训练数据。
4)过滤数据。在此步骤中初始接受器集也就是训练数据将被过滤。
5)创建一个神经网络。
6)训练神经网络。
7)让我们来看看misclassified值.它应该是“0 / 26”,意思是,经过训练的网络可以成功地识别所有图案(即26个字母)。
8)我们可以使用“Draw”和“Recognize”按钮来确定以上的识别过程。
执行完所有这些步骤后,程序现在做正确的识别工作了!你可以尝试一个更复杂的测试,选择所有的字体。数据生成前不要忘了打开“Scale”选项,该选项将放大训练集里的所有图像。然后你可以设置为second pass 里面的error limit为“0.5”而不是0.1,这样可以使网络训练更快,在训练结束时,误判值(misclassified value)应该为“0 / 130”。您可以检查一下训练集的所有图像是否被识别。 你甚至可以尝试训练网络中的所有字体:规则的和斜体的。你应该使用“缩放”选项,它可能要设定的学习速度和误差限值。 程序还可以尝试使用两层网络。我能只用100个接受器得到一个“4 / 260”误判值(misclassified value)。
4 结论
从上面的测试中,看起来第二种方法能够完成OCR的任务。但是,我们所有的实验用了理想数据进行了训练。该应用程序还可以识别手绘字母,我们一直在这种情况下使用程序里的“缩放”选项,结果不是最理想。未来可以在更好的接受器集产生,过滤和图像缩放等方面作进一步的研究。 尽管如此,程序可以工作!如果做一些额外的研究和改进,我们就可以用它来做一些真正的识别工作了。
参考文献:
[1] Andrew Kirillov. http://www.codeproject.com/KB/cs/neural_network_ocr.aspx
[2] Andrew Kirillov. http://www.aforgenet.com/
[3] 蒋宗礼. 人工神经网络导论. 北京:高等教育出版社,2001.
基于BP神经网络的字符识别研究的更多相关文章
- 基于BP神经网络的简单字符识别算法自小结(C语言版)
本文均属自己阅读源代码的点滴总结.转账请注明出处谢谢. 欢迎和大家交流.qq:1037701636 email:gzzaigcn2009@163.com 写在前面的闲话: 自我感觉自己应该不是一个非常 ...
- 基于steam的游戏销量预测 — PART 3 — 基于BP神经网络的机器学习与预测
语言:c++ 环境:windows 训练内容:根据从steam中爬取的数据经过文本分析制作的向量以及标签 使用相关:无 解释: 就是一个BP神经网络,借鉴参考了一些博客的解释和代码,具体哪些忘了,给出 ...
- [纯C#实现]基于BP神经网络的中文手写识别算法
效果展示 这不是OCR,有些人可能会觉得这东西会和OCR一样,直接进行整个字的识别就行,然而并不是. OCR是2维像素矩阵的像素数据.而手写识别不一样,手写可以把用户写字的笔画时间顺序,抽象成一个维度 ...
- 基于BP神经网络的手MNIST写数字识别
import numpy import math import scipy.special#特殊函数模块 import matplotlib.pyplot as plt #创建神经网络类,以便于实例化 ...
- 神经网络中的BP神经网络和贝叶斯
1 贝叶斯网络在地学中的应用 1 1.1基本原理及发展过程 1 1.2 具体的研究与应用 4 2 BP神经网络在地学中的应用 6 2.1BP神经网络简介 6 2.2基本原理 7 2.3 在地学中的具体 ...
- JAVA实现BP神经网络算法
工作中需要预测一个过程的时间,就想到了使用BP神经网络来进行预测. 简介 BP神经网络(Back Propagation Neural Network)是一种基于BP算法的人工神经网络,其使用BP算法 ...
- BP神经网络的参数改进参考?
参考文献:黄巧巧. 基于BP神经网络的手写数字识别系统研究[D].华中师范大学,2009. 47-52 BP神经网络的缺陷:收敛速度慢和局部极小点的问题 使用的改进方案有 1. 学习速率(learn ...
- RBF神经网络和BP神经网络的关系
作者:李瞬生链接:https://www.zhihu.com/question/44328472/answer/128973724来源:知乎著作权归作者所有.商业转载请联系作者获得授权,非商业转载请注 ...
- MATLAB神经网络(2) BP神经网络的非线性系统建模——非线性函数拟合
2.1 案例背景 在工程应用中经常会遇到一些复杂的非线性系统,这些系统状态方程复杂,难以用数学方法准确建模.在这种情况下,可以建立BP神经网络表达这些非线性系统.该方法把未知系统看成是一个黑箱,首先用 ...
随机推荐
- libsvm+eclipse(java)的配置以及开发需要设置的内容
主要参考博客: 1.eclipse + libsvm-3.12 用SVM实现简单线性分类 cnBlog中的主要介绍如何导入jar包的问题. 2.LIBSVM入门解读 CSDN,主要是对LIB ...
- 【leetcode刷题笔记】Minimum Window Substring
Given a string S and a string T, find the minimum window in S which will contain all the characters ...
- Django---Blog系统开发之注册页面(验证码&ajax发送文件)
前端页面及渲染: 静态文件的配置:setting.py: static 文件放在app下 STATIC_URL = '/static/' STATIC_ROOT = ( os.path.join(BA ...
- 主攻ASP.NET.4.5.1 MVC5.0之重生:Web项目语音朗读网页文本,简单语音提示浏览状态
第一步 添加SpeechLib.dll 下载SpeechLib.dll: 在项目中并且引用DLL using SpeechLib; using System.Threading; 第二步 调用并使用 ...
- 父元素设置overflow,绝对定位的子元素会被隐藏或一起滚动
一般情况: <!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <met ...
- h => h(App)解析
在创建Vue实例时经常看见render: h => h(App)的语句,现做出如下解析: h即为createElement,将h作为createElement的别名是Vue生态系统的通用管理,也 ...
- 文件系统的特性,linux的EXT2文件系统【转】
本文转载自:https://blog.csdn.net/tongyijia/article/details/52809281 先来提出三个概念: - superblock - inode - bloc ...
- HTML5 JS 压缩图片,并取得图片的BASE64编码上传
基本过程 1) 调用 FileReader 的 reader.readAsDataURL(img); 方法, 在其onload事件中, 将用户选择的图片读入 Image对象. 2) 在image对象的 ...
- IDEA: 遇到问题Error during artifact deployment. See server log for details.详解
IDEA 的配置确实有些烦人,完整的配置我之前发过,现在有个著名的报错: Error during artifact deployment. See server log for details. 这 ...
- python编程常见小技巧
#主要是记录常见的小问题以及解决办法 ##1.复制的代码,经常出现TAB和空格不一致的情况 将tab或者空格删除,然后重新打出空格或者tab就可以了: ##2.python读取文件,经常出现的编码en ...