爬取编程常用词汇,保存为Excel
编程常用词汇
import requests
import openpyxl
from lxml import etree
import re
url = 'https://www.runoob.com/w3cnote/common-english-terminology-in-programming.html'
# 得到响应结果
res = requests.get(url)
# xpath取值
selector = etree.HTML(res.text)
# 字母的索引
word_letter = selector.xpath('//h2/text()')
# 删除列表里前两个多余的值
del word_letter[0:2]
# print(word_letter)
# word_letter 最后的值为
# ['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J', 'K', 'L', 'M', 'N', 'O', 'P', 'Q', 'R', 'S', 'T', 'U', 'V', 'W', 'X', 'Y', 'Z', '专业名词']
# 得到每个索引的table,每个table里包含各索引的所有单词
result = selector.xpath('//table')
# 删除多余的数据
result.pop(0)
# 创建workbook
wb = openpyxl.Workbook()
# 创建worksheet
ws = wb.active
# 利用下标取出词汇的索引
index = -1
for table in result:
# 一开始就进行计数,即从0开始
index += 1
# 先添加索引,再取出每个table里的所有单词
ws.append([word_letter[index]])
# 打印索引
print(word_letter[index])
# X索引里没有单词
if word_letter[index] == 'X':
# 每个字母索引之间空一行
ws.append([])
# 继续循环对后面table里的单词进行添加
continue
# 添加一行Excel数据
ws.append(['英文', '译法 1', '译法 2', '译法 3'])
# 将Element类型显示为字符,为byte类型,需要decode
# 中文不显示,需要设置 encoding='utf-8'
words_html = etree.tostring(table, encoding='utf-8').decode()
# 一个tr:单词和译法
# 利用正则得到一个table里所有tr的内容
word_html = re.findall('<tr>.*?</tr>', words_html, re.S)
# 删除带<strong>标签的'英文 译法1 译法2 译法3'这条数据
# 前面已经手动添加,后面不需要每条都去判断去除<strong>标签
word_html.pop(0)
for tr in word_html:
# 一个td:一个单词或一个译法
# 利用正则得到一个tr里所有td的内容
# 得到的为list,一个td_list里面包含一个单词和对应的译文(含空格)
td_list = re.findall('<td>(.*?)</td>', tr, re.S)
# 用新的列表接收去除空格后的单词和译文
word = []
for i in td_list:
# 去除每个td里包含的空格,添加为一个列表
word.append(i.strip())
# 打印单词
print(word)
# 一个word包含一个单词和对应的译文(不含空格)
# 将这个单词添加进Excel
ws.append(word)
# 每个字母索引之间空一行
ws.append([])
# 保存Excel
path = r'C:\Users\Hlzy\Desktop\编程常用词汇.xlsx'
wb.save(path)
# 没有设置单元格样式,可以直接打开Excel,设置边宽,全选居中
控制台打印
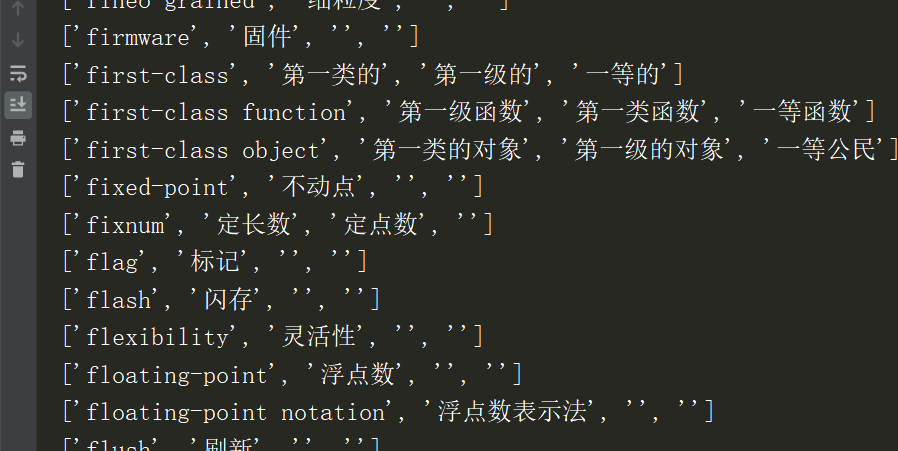
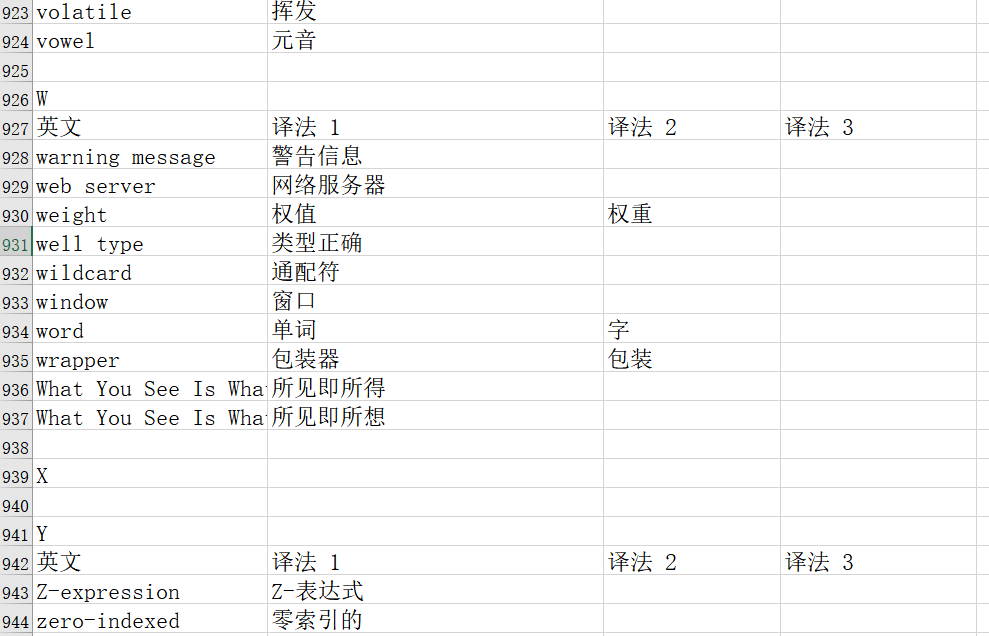
Excel内容
提取链接:https://pan.baidu.com/s/11kQnMQU_ilOtgf4Mom0nhw
爬取编程常用词汇,保存为Excel的更多相关文章
- VBA编程常用词汇英汉对照表
表 20‑1到表 20‑8是VBA编程中使用频率最高的英文单词,按字母排序.词性列中,a表示形容词,n表示名词,v表示动词,p表示介词以及其他词性. 表 20‑1 VBA编程常用词汇表 单词 中文 词 ...
- Python:爬取网站图片并保存至本地
Python:爬取网页图片并保存至本地 python3爬取网页中的图片到本地的过程如下: 1.爬取网页 2.获取图片地址 3.爬取图片内容并保存到本地 实例:爬取百度贴吧首页图片. 代码如下: imp ...
- Python爬虫学习(二) ——————爬取前程无忧招聘信息并写入excel
作为一名Pythoner,相信大家对Python的就业前景或多或少会有一些关注.索性我们就写一个爬虫去获取一些我们需要的信息,今天我们要爬取的是前程无忧!说干就干!进入到前程无忧的官网,输入关键字&q ...
- pyhton 网络爬取软考题库保存text
#-*-coding:utf-8-*-#参考文档#https://www.crummy.com/software/BeautifulSoup/bs4/doc/index.zh.html#find-al ...
- Python爬取拉勾网招聘信息并写入Excel
这个是我想爬取的链接:http://www.lagou.com/zhaopin/Python/?labelWords=label 页面显示如下: 在Chrome浏览器中审查元素,找到对应的链接: 然后 ...
- Python-爬虫实战 简单爬取豆瓣top250电影保存到本地
爬虫原理 发送数据 获取数据 解析数据 保存数据 requests请求库 res = requests.get(url="目标网站地址") 获取二进制流方法:res.content ...
- Python使用requests爬取一个网页并保存
#导入 requests模块import requests #设置请求头,让网站监测是浏览器 headers = { 'user-agent': 'Mozilla/5.0 (Windows NT 6. ...
- 将爬取的网页数据保存到数据库时报错不能提交JPA,Caused by: java.sql.SQLException: Incorrect string value: '\xF0\x9F\x98\xB6 \xE2...' for column 'content' at row 1
错误原因:我们可以看到错误提示中的字符0xF0 0x9F 0x98 0x84 ,这对应UTF-8编码格式中的4字节编码(UTF-8编码规范).正常的汉字一般不会超过3个字节,为什么为出现4个字节呢?实 ...
- 爬取豆瓣电影信息保存到Excel
from bs4 import BeautifulSoup import requests import html.parser from openpyxl import Workbook,load_ ...
随机推荐
- C# 面向切面编程 AOP
AOP(Aspect Oriented Programming) 面向切面编程 起源 引言 http://wayfarer.cnblogs.com/articles/241012.html AOP技 ...
- Microsemi Libero使用技巧——查看芯片资源占用情况
前言 与MCU不同,FPGA的资源主要包括:逻辑资源,IO资源,Flash大小,PLL资源,SoC硬核处理器资源等,其中逻辑资源和IO资源是我们主要关心的,本篇文章将介绍,如何通过Microsemi ...
- 精通awk系列(2):本教程测试所用示例文件
回到: Linux系列文章 Shell系列文章 Awk系列文章 本系列的awk教程中,将大量使用到如下示例文件a.txt. ID name gender age email phone 1 Bob m ...
- python中time.strftime不支持中文,报错UnicodeEncodeError: 'locale' codec can't encode character '\u5e74' in position 2: encoding error
使用time.strftime将 "2020-10-10 10:10:10" 转化为 2020年10月10日10时10分10 报错: import time timestr=&q ...
- Ligg.EasyWinApp-102-Ligg.EasyWinForm:Function--ControlBox、Tray、Resize、Menu
首先请在VS里打开下面的文件,我们将对源码分段进行说明: Function(功能):一个应用的功能界面,一个应用对应多个Function(功能):如某应用可分为管理员界面.用户界面. 首先我们来看一下 ...
- QT执行shell脚本或者执行linux指令
由于我在做linux下的QT开发,有时候会用到shell脚本的辅助,但是需要QT运行shell脚本并获取执行结果,今天给大家分享下我的技巧,废话少说直接上代码: //执行shell指令或者shell脚 ...
- 损失函数———有关L1和L2正则项的理解
一.损失函: 模型的结构风险函数包括了 经验风险项 和 正则项,如下所示: 二.损失函数中的正则项 1.正则化的概念: 机器学习中都会看到损失函数之后会添加一个额外项,常用的额外项一般有2种, ...
- mysql DDL 锁表
mysql DDL 锁表 select trx_state, trx_started, trx_mysql_thread_id, trx_query from information_schema.i ...
- Java之IO初识(字节流和字符流)
IO概述 生活中,你肯定经历过这样的场景.当你编辑一个文本文件,忘记了 ctrl+s ,可能文件就白白编辑了.当你电脑上插入一个U盘,可以把一个视频,拷贝到你的电脑硬盘里.那么数据都是在哪些设备上的呢 ...
- Java之Collection接口(单列集合根接口)
集合概述 集合到底是什么呢?集合:集合是java中提供的一种容器,可以用来存储多个数据 集合和数组既然都是容器,它们有啥区别呢? 区别1: 数组的长度是固定的. 集合的长度是可变的. 区别2: 数组 ...