Pandas进阶笔记 (一) Groupby 重难点总结
如果Pandas只是能把一些数据变成 dataframe 这样优美的格式,那么Pandas绝不会成为叱咤风云的数据分析中心组件。因为在数据分析过程中,描述数据是通过一些列的统计指标实现的,分析结果也需要由具体的分组行为,对各组横向纵向对比。
GroupBy 就是这样的一个有力武器。事实上,SQL语言在Pandas出现的几十年前就成为了高级数据分析人员的标准工具,很大一部分原因正是因为它有标准的SELECT xx FROM xx WHERE condition GROUP BY xx HAVING condition 范式。
感谢 Wes Mckinney及其团队,除了SQL之外,我们多了一个更灵活、适应性更强的工具,而非困在SQL Shell或Python里步履沉重。
【示例】将一段SQL语句用Pandas表达
SQL
SELECT Column1, Column2, mean(Column3), sum(Column4)
FROM SomeTable
WHERE Condition 1
GROUP BY Column1, Column2
HAVING Condition2
Pandas
df [Condition1].groupby([Column1, Column2], as_index=False).agg({Column3: "mean", Column4: "sum"}).filter(Condition2)
Group By: split - apply - combine
GroupBy可以分解为三个步骤:
- Splitting: 把数据按主键划分为很多个小组
- Applying: 对每个小组独立地使用函数
- Combining: 把所得到的结果组合
那么,这一套行云流水的动作是如何完成的呢?
- Splitting 由
groupby实现 - Applying 由
agg、apply、transform、filter实现具体的操作 - Combining 由
concat等实现
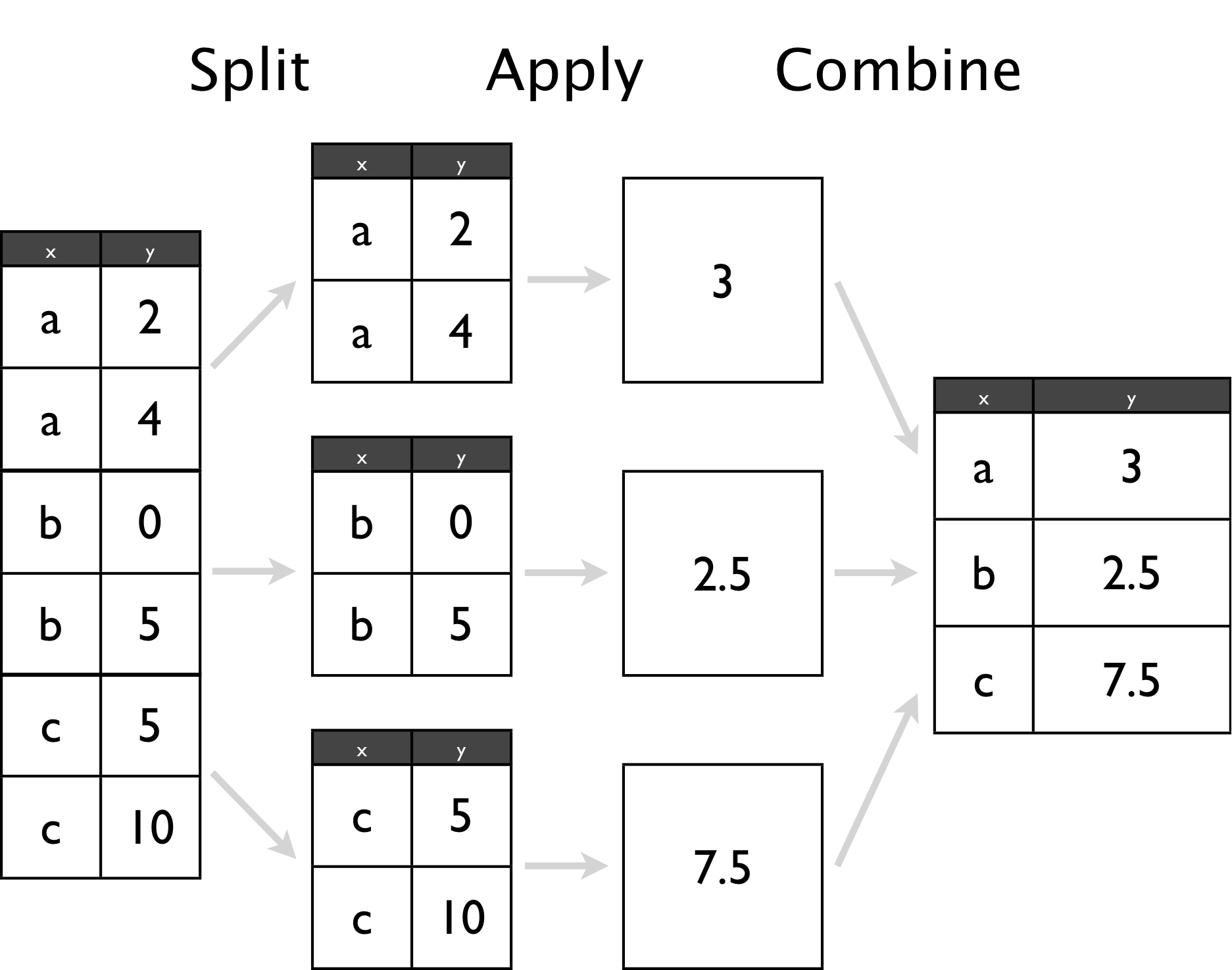
其中,在apply这一步,通常由以下四类操作:
- Aggregation:做一些统计性的计算
- Apply:做一些数据转换
- Transformation:做一些数据处理方面的变换
- Filtration:做一些组级别的过滤
注意,这里讨论的apply,agg,transform,filter方法都是限制在 pandas.core.groupby.DataFrameGroupBy里面,不能跟 pandas.core.groupby.DataFrame混淆。
先导入需要用到的模块
import numpy as np
import pandas as pd
import sys, traceback
from itertools import chain
Part 1: Groupby 详解
df_0 = pd.DataFrame({'A': list(chain(*[['foo', 'bar']*4])),
'B': ['one', 'one', 'two', 'three', 'two', 'two', 'one', 'three'],
'C': np.random.randn(8),
'D': np.random.randn(8)})
df_0
.dataframe tbody tr th:only-of-type {
vertical-align: middle;
}
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
| A | B | C | D | |
|---|---|---|---|---|
| 0 | foo | one | 1.145852 | 0.210586 |
| 1 | bar | one | -1.343518 | -2.064735 |
| 2 | foo | two | 0.544624 | 1.125505 |
| 3 | bar | three | 1.090288 | -0.296160 |
| 4 | foo | two | -1.854274 | 1.348597 |
| 5 | bar | two | -0.246072 | -0.598949 |
| 6 | foo | one | 0.348484 | 0.429300 |
| 7 | bar | three | 1.477379 | 0.917027 |
Talk 1:创建一个Groupby对象时应注意的问题
Good Practice
df_01 = df_0.copy()
df_01.groupby(["A", "B"], as_index=False, sort=False).agg({"C": "sum", "D": "mean"})
.dataframe tbody tr th:only-of-type {
vertical-align: middle;
}
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
| A | B | C | D | |
|---|---|---|---|---|
| 0 | foo | one | 1.494336 | 0.319943 |
| 1 | bar | one | -1.343518 | -2.064735 |
| 2 | foo | two | -1.309649 | 1.237051 |
| 3 | bar | three | 2.567667 | 0.310433 |
| 4 | bar | two | -0.246072 | -0.598949 |
Poor Practice
df_02 = df_0.copy()
df_02.groupby(["A", "B"]).agg({"C": "sum", "D": "mean"}).reset_index()
.dataframe tbody tr th:only-of-type {
vertical-align: middle;
}
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
| A | B | C | D | |
|---|---|---|---|---|
| 0 | bar | one | -1.343518 | -2.064735 |
| 1 | bar | three | 2.567667 | 0.310433 |
| 2 | bar | two | -0.246072 | -0.598949 |
| 3 | foo | one | 1.494336 | 0.319943 |
| 4 | foo | two | -1.309649 | 1.237051 |
- 直接使用
as_index=False参数是一个好的习惯,因为如果dataframe非常巨大(比如达到GB以上规模)时,先生成一个Groupby对象,然后再调用reset_index()会有额外的时间消耗。 - 在任何涉及数据的操作中,排序都是非常"奢侈的"。如果只是单纯的分组,不关心顺序,在创建Groupby对象的时候应当关闭排序功能,因为这个功能默认是开启的。尤其当你在较大的大数据集上作业时更当注意这个问题。
- 值得注意的是:groupby会按照数据在原始数据框内的顺序安排它们在每个新组内的顺序。这与是否指定排序无关。
如果要得到一个多层索引的数据框,使用默认的as_index=True即可,例如下面的例子:
df_03 = df_0.copy()
df_03.groupby(["A", "B"]).agg({"C": "sum", "D": "mean"})
.dataframe tbody tr th:only-of-type {
vertical-align: middle;
}
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
| C | D | ||
|---|---|---|---|
| A | B | ||
| bar | one | -1.343518 | -2.064735 |
| three | 2.567667 | 0.310433 | |
| two | -0.246072 | -0.598949 | |
| foo | one | 1.494336 | 0.319943 |
| two | -1.309649 | 1.237051 |
注意,as_index仅当做aggregation操作时有效,如果是其他操作,例如transform,指定这个参数是无效的
df_04 = df_0.copy()
df_04.groupby(["A", "B"], as_index=True).transform(lambda x: x * x)
.dataframe tbody tr th:only-of-type {
vertical-align: middle;
}
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
| C | D | |
|---|---|---|
| 0 | 1.312976 | 0.044347 |
| 1 | 1.805040 | 4.263130 |
| 2 | 0.296616 | 1.266761 |
| 3 | 1.188727 | 0.087711 |
| 4 | 3.438331 | 1.818714 |
| 5 | 0.060552 | 0.358740 |
| 6 | 0.121441 | 0.184298 |
| 7 | 2.182650 | 0.840938 |
可以看到,我们得到了一个和df_0一样长度的新dataframe,同时我们还希望A,B能成为索引,但这并没有生效。
Talk 2:使用 pd.Grouper
pd.Grouper 比 groupby更强大、更灵活,它不仅支持普通的分组,还支持按照时间进行升采样或降采样分组
df_1 = pd.read_excel("dataset\sample-salesv3.xlsx")
df_1["date"] = pd.to_datetime(df_1["date"])
df_1.head()
.dataframe tbody tr th:only-of-type {
vertical-align: middle;
}
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
| account number | name | sku | quantity | unit price | ext price | date | |
|---|---|---|---|---|---|---|---|
| 0 | 740150 | Barton LLC | B1-20000 | 39 | 86.69 | 3380.91 | 2014-01-01 07:21:51 |
| 1 | 714466 | Trantow-Barrows | S2-77896 | -1 | 63.16 | -63.16 | 2014-01-01 10:00:47 |
| 2 | 218895 | Kulas Inc | B1-69924 | 23 | 90.70 | 2086.10 | 2014-01-01 13:24:58 |
| 3 | 307599 | Kassulke, Ondricka and Metz | S1-65481 | 41 | 21.05 | 863.05 | 2014-01-01 15:05:22 |
| 4 | 412290 | Jerde-Hilpert | S2-34077 | 6 | 83.21 | 499.26 | 2014-01-01 23:26:55 |
【例子】计算每个月的ext price总和
df_1.set_index("date").resample("M")["ext price"].sum()
date
2014-01-31 185361.66
2014-02-28 146211.62
2014-03-31 203921.38
2014-04-30 174574.11
2014-05-31 165418.55
2014-06-30 174089.33
2014-07-31 191662.11
2014-08-31 153778.59
2014-09-30 168443.17
2014-10-31 171495.32
2014-11-30 119961.22
2014-12-31 163867.26
Freq: M, Name: ext price, dtype: float64
df_1.groupby(pd.Grouper(key="date", freq="M"))["ext price"].sum()
date
2014-01-31 185361.66
2014-02-28 146211.62
2014-03-31 203921.38
2014-04-30 174574.11
2014-05-31 165418.55
2014-06-30 174089.33
2014-07-31 191662.11
2014-08-31 153778.59
2014-09-30 168443.17
2014-10-31 171495.32
2014-11-30 119961.22
2014-12-31 163867.26
Freq: M, Name: ext price, dtype: float64
两种写法都得到了相同的结果,并且看上去第二种写法似乎有点儿难以理解。再看一个例子
【例子】计算每个客户每个月的ext price总和
df_1.set_index("date").groupby("name")["ext price"].resample("M").sum().head(20)
name date
Barton LLC 2014-01-31 6177.57
2014-02-28 12218.03
2014-03-31 3513.53
2014-04-30 11474.20
2014-05-31 10220.17
2014-06-30 10463.73
2014-07-31 6750.48
2014-08-31 17541.46
2014-09-30 14053.61
2014-10-31 9351.68
2014-11-30 4901.14
2014-12-31 2772.90
Cronin, Oberbrunner and Spencer 2014-01-31 1141.75
2014-02-28 13976.26
2014-03-31 11691.62
2014-04-30 3685.44
2014-05-31 6760.11
2014-06-30 5379.67
2014-07-31 6020.30
2014-08-31 5399.58
Name: ext price, dtype: float64
df_1.groupby(["name", pd.Grouper(key="date",freq="M")])["ext price"].sum().head(20)
name date
Barton LLC 2014-01-31 6177.57
2014-02-28 12218.03
2014-03-31 3513.53
2014-04-30 11474.20
2014-05-31 10220.17
2014-06-30 10463.73
2014-07-31 6750.48
2014-08-31 17541.46
2014-09-30 14053.61
2014-10-31 9351.68
2014-11-30 4901.14
2014-12-31 2772.90
Cronin, Oberbrunner and Spencer 2014-01-31 1141.75
2014-02-28 13976.26
2014-03-31 11691.62
2014-04-30 3685.44
2014-05-31 6760.11
2014-06-30 5379.67
2014-07-31 6020.30
2014-08-31 5399.58
Name: ext price, dtype: float64
这次,第二种写法远比第一种写法清爽、便于理解。这种按照特定字段和时间采样的混合分组,请优先考虑用pd.Grouper
Talk 3: 如何访问组
如果只是做完拆分动作,没有做后续的apply,得到的是一个groupby对象。这里讨论下如何访问拆分出来的组
主要方法为:
groupsget_group- 迭代遍历
df_2 = pd.DataFrame({'X': ['A', 'B', 'A', 'B'], 'Y': [1, 4, 3, 2]})
df_2
.dataframe tbody tr th:only-of-type {
vertical-align: middle;
}
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
| X | Y | |
|---|---|---|
| 0 | A | 1 |
| 1 | B | 4 |
| 2 | A | 3 |
| 3 | B | 2 |
- 使用
groups方法可以看到所有的组
df_2.groupby("X").groups
{'A': Int64Index([0, 2], dtype='int64'),
'B': Int64Index([1, 3], dtype='int64')}
- 使用
get_group方法可以访问到指定的组
df_2.groupby("X", as_index=True).get_group(name="A")
.dataframe tbody tr th:only-of-type {
vertical-align: middle;
}
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
| X | Y | |
|---|---|---|
| 0 | A | 1 |
| 2 | A | 3 |
注意,get_group方法中,name参数只能传递单个str,不可以传入list,尽管Pandas中的其他地方常常能看到这类传参。如果是多列做主键的拆分,可以传入tuple。
- 迭代遍历
for name, group in df_2.groupby("X"):
print(name)
print(group,"\n")
A
X Y
0 A 1
2 A 3
B
X Y
1 B 4
3 B 2
这里介绍一个小技巧,如果你得到一个<pandas.core.groupby.groupby.DataFrameGroupBy object对象,想要将它还原成其原本的 dataframe ,有一个非常简便的方法值得一提:
gropbyed_object.apply(lambda x: x)
囿于篇幅,就不对API逐个解释了,这里仅指出最容易忽视也最容易出错的三个参数
| 参数 | 注意事项 |
|---|---|
| level | 仅作用于层次化索引的数据框时有效 |
| as_index | 仅对数据框做 agg 操作时有效, |
| group_keys | 仅在调用 apply 时有效 |
Part 2: Apply 阶段详解
拆分完成后,可以对各个组做一些的操作,总体说来可以分为以下四类:
- aggregation
- apply
- transform
- filter
先总括地对比下这四类操作
- 任何能将一个
Series压缩成一个标量值的都是agg操作,例如求和、求均值、求极值等统计计算 - 对数据框或者
groupby对象做变换,得到子集或一个新的数据框的操作是apply或transform - 对聚合结果按标准过滤的操作是
filter
apply 和 transform有那么一点相似,下文会重点剖析二者
Talk 4:agg VS apply
agg和apply都可以对特定列的数据传入函数,并且依照函数进行计算。但是区别在于,agg更加灵活高效,可以一次完成操作。而apply需要辗转多次才能完成相同操作。
df_3 = pd.DataFrame({"name":["Foo", "Bar", "Foo", "Bar"], "score":[80,80,95,70]})
df_3
.dataframe tbody tr th:only-of-type {
vertical-align: middle;
}
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
| name | score | |
|---|---|---|
| 0 | Foo | 80 |
| 1 | Bar | 80 |
| 2 | Foo | 95 |
| 3 | Bar | 70 |
我们需要计算出每个人的总分、最高分、最低分
(1)使用apply方法
df_3.groupby("name", sort=False).score.apply(lambda x: x.sum())
name
Foo 175
Bar 150
Name: score, dtype: int64
df_3.groupby("name", sort=False).score.apply(lambda x: x.max())
name
Foo 95
Bar 80
Name: score, dtype: int64
df_3.groupby("name", sort=False).score.apply(lambda x: x.min())
name
Foo 80
Bar 70
Name: score, dtype: int64
显然,我们辗转操作了3次,并且还需要额外一次操作(将所得到的三个值粘合起来)
(2)使用agg方法
df_3.groupby("name", sort=False).agg({"score": [np.sum, np.max, np.min]})
.dataframe tbody tr th:only-of-type {
vertical-align: middle;
}
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead tr th {
text-align: left;
}
.dataframe thead tr:last-of-type th {
text-align: right;
}
| score | |||
|---|---|---|---|
| sum | amax | amin | |
| name | |||
| Foo | 175 | 95 | 80 |
| Bar | 150 | 80 | 70 |
小结 agg一次可以对多个列独立地调用不同的函数,而apply一次只能对多个列调用相同的一个函数。
Talk 5:transform VS agg
transform作用于数据框自身,并且返回变换后的值。返回的对象和原对象拥有相同数目的行,但可以扩展列。注意返回的对象不是就地修改了原对象,而是创建了一个新对象。也就是说原对象没变。
df_4 = pd.DataFrame({'A': range(3), 'B': range(1, 4)})
df_4
.dataframe tbody tr th:only-of-type {
vertical-align: middle;
}
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
| A | B | |
|---|---|---|
| 0 | 0 | 1 |
| 1 | 1 | 2 |
| 2 | 2 | 3 |
df_4.transform(lambda x: x + 1)
.dataframe tbody tr th:only-of-type {
vertical-align: middle;
}
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
| A | B | |
|---|---|---|
| 0 | 1 | 2 |
| 1 | 2 | 3 |
| 2 | 3 | 4 |
可以对数据框先分组,然后对各组赋予一个变换,例如元素自增1。下面这个例子意义不大,可以直接做变换。
df_2.groupby("X").transform(lambda x: x + 1)
.dataframe tbody tr th:only-of-type {
vertical-align: middle;
}
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
| Y | |
|---|---|
| 0 | 2 |
| 1 | 5 |
| 2 | 4 |
| 3 | 3 |
下面举一个更实际的例子
df_5 = pd.read_csv(r"dataset\tips.csv")
df_5.head()
.dataframe tbody tr th:only-of-type {
vertical-align: middle;
}
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
| total_bill | tip | sex | smoker | day | time | size | |
|---|---|---|---|---|---|---|---|
| 0 | 16.99 | 1.01 | Female | No | Sun | Dinner | 2 |
| 1 | 10.34 | 1.66 | Male | No | Sun | Dinner | 3 |
| 2 | 21.01 | 3.50 | Male | No | Sun | Dinner | 3 |
| 3 | 23.68 | 3.31 | Male | No | Sun | Dinner | 2 |
| 4 | 24.59 | 3.61 | Female | No | Sun | Dinner | 4 |
现在我们想知道每天,各数值列的均值
对比以下 agg 和 transform 两种操作
df_5.groupby("day").aggregate("mean")
.dataframe tbody tr th:only-of-type {
vertical-align: middle;
}
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
| total_bill | tip | size | |
|---|---|---|---|
| day | |||
| Fri | 17.151579 | 2.734737 | 2.105263 |
| Sat | 20.441379 | 2.993103 | 2.517241 |
| Sun | 21.410000 | 3.255132 | 2.842105 |
| Thur | 17.682742 | 2.771452 | 2.451613 |
df_5.groupby('day').transform(lambda x : x.mean()).total_bill.unique()
array([21.41 , 20.44137931, 17.68274194, 17.15157895])
观察得知,两种操作是相同的,都是对各个小组求均值。所不同的是,agg方法仅返回4行(即压缩后的统计值),而transform返回一个和原数据框同样长度的新数据框。
Talk 6:transform VS apply
transform 和 apply 的不同主要体现在两方面:
apply对于每个组,都是同时在所有列上面调用函数;而transform是对每个组,依次在每一列上调用函数- 由上面的工作方法决定了:
apply可以返回标量、Series、dataframe——取决于你在什么上面调用了apply方法;而transform只能返回一个类似于数组的序列,例如一维的Series、array、list,并且最重要的是,要和原始组有同样的长度,否则会引发错误。
【例子】通过打印对象的类型来对比两种方法的工作对象
df_6 = pd.DataFrame({'State':['Texas', 'Texas', 'Florida', 'Florida'],
'a':[4,5,1,3], 'b':[6,10,3,11]})
df_6
.dataframe tbody tr th:only-of-type {
vertical-align: middle;
}
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
| State | a | b | |
|---|---|---|---|
| 0 | Texas | 4 | 6 |
| 1 | Texas | 5 | 10 |
| 2 | Florida | 1 | 3 |
| 3 | Florida | 3 | 11 |
def inspect(x):
print(type(x))
print(x)
df_6.groupby("State").apply(inspect)
<class 'pandas.core.frame.DataFrame'>
State a b
2 Florida 1 3
3 Florida 3 11
<class 'pandas.core.frame.DataFrame'>
State a b
2 Florida 1 3
3 Florida 3 11
<class 'pandas.core.frame.DataFrame'>
State a b
0 Texas 4 6
1 Texas 5 10
.dataframe tbody tr th:only-of-type {
vertical-align: middle;
}
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
从打印结果我们清晰地看到两点:apply 每次作用的对象是一个 dataframe,其次第一个组被计算了两次,这是因为pandas会通过这种机制来对比是否有更快的方式完成后面剩下组的计算。
df_6.groupby("State").transform(inspect)
<class 'pandas.core.series.Series'>
2 1
3 3
Name: a, dtype: int64
<class 'pandas.core.series.Series'>
2 3
3 11
Name: b, dtype: int64
<class 'pandas.core.frame.DataFrame'>
a b
2 1 3
3 3 11
<class 'pandas.core.series.Series'>
0 4
1 5
Name: a, dtype: int64
<class 'pandas.core.series.Series'>
0 6
1 10
Name: b, dtype: int64
从打印结果我们也清晰地看到两点:transform每次只计算一列;会出现计算了一个组整体的情况,这有点令人费解,待研究。
从上面的对比,我们直接得到了一个有用的警示:不要传一个同时涉及到多列的函数给transform方法,因为那么做只会得到错误。例如下面的代码所示:
def subtract(x):
return x["a"] - x["b"]
try:
df_6.groupby("State").transform(subtract)
except Exception:
exc_type, exc_value, exc_traceback = sys.exc_info()
formatted_lines = traceback.format_exc().splitlines()
print(formatted_lines[-1])
KeyError: ('a', 'occurred at index a')
另一个警示则是:在使用 transform 方法的时候,不要去试图修改返回结果的长度,那样不仅会引发错误,而且traceback的信息非常隐晦,很可能你需要花很长时间才能真正意识到错误所在。
def return_more(x):
return np.arange(3)
try:
df_6.groupby("State").transform(return_more)
except Exception:
exc_type, exc_value, exc_traceback = sys.exc_info()
formatted_lines = traceback.format_exc().splitlines()
print(formatted_lines[-1])
ValueError: Length mismatch: Expected axis has 6 elements, new values have 4 elements
这个报错信息有点别扭,期待返回6个元素,但是返回的结果只有4个元素;其实,应该说预期的返回为4个元素,但是现在却返回6个元素,这样比较容易理解错误所在。
最后,让我们以一条有用的经验结束这个talk:如果你确信自己想要的操作时同时作用于多列,并且速度最好还很快,请不要用transform方法,Talk9有一个这方面的好例子。
Talk 7:agg 用法总结
(1)一次对所有列调用多个函数
df_0.groupby("A").agg([np.sum, np.mean, np.min])
.dataframe tbody tr th:only-of-type {
vertical-align: middle;
}
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead tr th {
text-align: left;
}
.dataframe thead tr:last-of-type th {
text-align: right;
}
| C | D | |||||
|---|---|---|---|---|---|---|
| sum | mean | amin | sum | mean | amin | |
| A | ||||||
| bar | 0.978077 | 0.244519 | -1.343518 | -2.042817 | -0.510704 | -2.064735 |
| foo | 0.184686 | 0.046172 | -1.854274 | 3.113988 | 0.778497 | 0.210586 |
(2)一次对特定列调用多个函数
df_0.groupby("A")["C"].agg([np.sum, np.mean, np.min])
.dataframe tbody tr th:only-of-type {
vertical-align: middle;
}
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
| sum | mean | amin | |
|---|---|---|---|
| A | |||
| bar | 0.978077 | 0.244519 | -1.343518 |
| foo | 0.184686 | 0.046172 | -1.854274 |
(3)对不同列调用不同函数
df_0.groupby("A").agg({"C": [np.sum, np.mean], "D": [np.max, np.min]})
.dataframe tbody tr th:only-of-type {
vertical-align: middle;
}
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead tr th {
text-align: left;
}
.dataframe thead tr:last-of-type th {
text-align: right;
}
| C | D | |||
|---|---|---|---|---|
| sum | mean | amax | amin | |
| A | ||||
| bar | 0.978077 | 0.244519 | 0.917027 | -2.064735 |
| foo | 0.184686 | 0.046172 | 1.348597 | 0.210586 |
df_0.groupby("A").agg({"C": "sum", "D": "min"})
.dataframe tbody tr th:only-of-type {
vertical-align: middle;
}
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
| C | D | |
|---|---|---|
| A | ||
| bar | 0.978077 | -2.064735 |
| foo | 0.184686 | 0.210586 |
(4)对同一列调用不同函数,并且直接重命名
df_0.groupby("A")["C"].agg([("Largest", "max"), ("Smallest", "min")])
.dataframe tbody tr th:only-of-type {
vertical-align: middle;
}
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
| Largest | Smallest | |
|---|---|---|
| A | ||
| bar | 1.477379 | -1.343518 |
| foo | 1.145852 | -1.854274 |
(5)对多个列调用同一个函数
agg_keys = {}.fromkeys(["C", "D"], "sum")
df_0.groupby("A").agg(agg_keys)
.dataframe tbody tr th:only-of-type {
vertical-align: middle;
}
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
| C | D | |
|---|---|---|
| A | ||
| bar | 0.978077 | -2.042817 |
| foo | 0.184686 | 3.113988 |
(6)注意agg会忽略缺失值,这在计数时需要加以注意
df_7 = pd.DataFrame({"ID":["A","A","A","B","B"], "Num": [1,np.nan, 1,1,1]})
df_7
.dataframe tbody tr th:only-of-type {
vertical-align: middle;
}
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
| ID | Num | |
|---|---|---|
| 0 | A | 1.0 |
| 1 | A | NaN |
| 2 | A | 1.0 |
| 3 | B | 1.0 |
| 4 | B | 1.0 |
df_7.groupby("ID").agg({"Num":"count"})
.dataframe tbody tr th:only-of-type {
vertical-align: middle;
}
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
| Num | |
|---|---|
| ID | |
| A | 2 |
| B | 2 |
注意:Pandas 中的 count,sum,mean,median,std,var,min,max等函数都用C语言优化过。所以,还是那句话,如果你在大数据集上使用agg,最好使用这些函数而非从numpy那里借用np.sum等方法,一个缓慢的程序是由每一步的缓慢积累而成的。
Talk 8:**Filtration ** 易错点剖析
通常,在对一个 dataframe 分组并且完成既定的操作之后,可以直接返回结果,也可以视需求对结果作一层过滤。这个过滤一般都是指 filter 操作,但是务必要理解清楚自己到底需要对组作过滤还是对组内的每一行作过滤。这个Talk就来讨论过滤这个话题。
【例子】找出每门课程考试分数低于这门课程平均分的学生
df_8 = pd.DataFrame({"Subject": list(chain(*[["Math"]*3,["Computer"]*3])),
"Student": list(chain(*[["Chan", "Ida", "Ada"]*2])),
"Score": [80,90,85,90,85,95]})
df_8
.dataframe tbody tr th:only-of-type {
vertical-align: middle;
}
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
| Subject | Student | Score | |
|---|---|---|---|
| 0 | Math | Chan | 80 |
| 1 | Math | Ida | 90 |
| 2 | Math | Ada | 85 |
| 3 | Computer | Chan | 90 |
| 4 | Computer | Ida | 85 |
| 5 | Computer | Ada | 95 |
这样一个需求是否适合用 filter 来处理呢?我们试试看:
try:
df_8.groupby("Subject").filter(lambda x: x["Score"] < x["Score"].mean())
except Exception:
exc_type, exc_value, exc_traceback = sys.exc_info()
formatted_lines = traceback.format_exc().splitlines()
print(formatted_lines[-1])
TypeError: filter function returned a Series, but expected a scalar bool
显然不行,因为 filter 实际上做的事情是要么留下这个组,要么过滤掉这个组。我们在这里弄混淆的东西,和我们初学 SQL时弄混 WHERE 和 HAVING 是一回事。就像需要记住 HAVING 是一个组内语法一样,请记住 filter 是一个组内方法。
我们先解决这个例子,正确的做法如下:
df_8.groupby("Subject").apply(lambda g: g[g.Score < g.Score.mean()])
.dataframe tbody tr th:only-of-type {
vertical-align: middle;
}
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
| Subject | Student | Score | ||
|---|---|---|---|---|
| Subject | ||||
| Computer | 4 | Computer | Ida | 85 |
| Math | 0 | Math | Chan | 80 |
而关于 filter,我们援引官方文档上的例子作为对比
df_9 = pd.DataFrame({'A' : ['foo', 'bar', 'foo', 'bar',
'foo', 'bar'],
'B' : [1, 2, 3, 4, 5, 6],
'C' : [2.0, 5., 8., 1., 2., 9.]})
df_9
.dataframe tbody tr th:only-of-type {
vertical-align: middle;
}
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
| A | B | C | |
|---|---|---|---|
| 0 | foo | 1 | 2.0 |
| 1 | bar | 2 | 5.0 |
| 2 | foo | 3 | 8.0 |
| 3 | bar | 4 | 1.0 |
| 4 | foo | 5 | 2.0 |
| 5 | bar | 6 | 9.0 |
df_9.groupby('A').filter(lambda x: x['B'].mean() > 3.)
.dataframe tbody tr th:only-of-type {
vertical-align: middle;
}
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
| A | B | C | |
|---|---|---|---|
| 1 | bar | 2 | 5.0 |
| 3 | bar | 4 | 1.0 |
| 5 | bar | 6 | 9.0 |
Part 3:groupby 应用举例
Talk 9:组内缺失值填充
df_10 = pd.DataFrame({"ID":["A","A","A","B","B","B"], "Num": [100,np.nan,300,np.nan,500,600]})
df_10
.dataframe tbody tr th:only-of-type {
vertical-align: middle;
}
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
| ID | Num | |
|---|---|---|
| 0 | A | 100.0 |
| 1 | A | NaN |
| 2 | A | 300.0 |
| 3 | B | NaN |
| 4 | B | 500.0 |
| 5 | B | 600.0 |
df_10.groupby("ID", as_index=False).Num.transform(lambda x: x.fillna(method="ffill")).transform(lambda x: x.fillna(method="bfill"))
.dataframe tbody tr th:only-of-type {
vertical-align: middle;
}
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
| Num | |
|---|---|
| 0 | 100.0 |
| 1 | 100.0 |
| 2 | 300.0 |
| 3 | 500.0 |
| 4 | 500.0 |
| 5 | 600.0 |
如果dataframe比较大(超过1GB),transform + lambda方法会比较慢,可以用下面这个方法,速度约比上面的组合快100倍。
df_10.groupby("ID",as_index=False).ffill().groupby("ID",as_index=False).bfill()
.dataframe tbody tr th:only-of-type {
vertical-align: middle;
}
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
| ID | Num | |
|---|---|---|
| 0 | A | 100.0 |
| 1 | A | 100.0 |
| 2 | A | 300.0 |
| 3 | B | 500.0 |
| 4 | B | 500.0 |
| 5 | B | 600.0 |
参考资料:
https://stackoverflow.com/questions/44864655/pandas-difference-between-apply-and-aggregate-functions
https://stackoverflow.com/questions/27517425/apply-vs-transform-on-a-group-object
https://pandas.pydata.org/pandas-docs/stable/user_guide/groupby.html

Pandas进阶笔记 (一) Groupby 重难点总结的更多相关文章
- Pandas进阶笔记 (0)为什么写这个系列
使用Pandas数年之久了,从最早的0.17版本开始接触Pandas,到现在0.25版本,踩过不少坑,面对各种稀奇古怪的bug抓耳挠腮.每每想要解决bug,或者想要实现一个特定的数据操作需求,首先想到 ...
- 这是一份非常适合收藏的Android进阶/面试重难点整理
写在前面 记得我大二时“不务正业”地自学Android并跟了老师做项目,到大三开始在目前的公司实习,至今毕业已有几年多,学习Android已经6.7年多了!但总感觉知识点很零散,并且不够深入,遇到瓶颈 ...
- 读书笔记:《重来REWORK》
读书笔记:<重来REWORK> <重来Rework--更为简单有效的商业思维>这本书是看了别人的书单而购买的,初 拿到这本书翻看时,感觉有两点与平常的书不同,一是每个小节非常短 ...
- Angularjs进阶笔记(2)-自定义指令中的数据绑定
有关自定义指令的scope参数,网上很多文章都在讲这3种绑定方式实现的效果是什么,但几乎没有人讲到底怎么使用,本篇希望聊聊到底怎么用这个话题. 一. 自定义指令 自定义指令,是Angularjs用来实 ...
- Pandas高级教程之:GroupBy用法
Pandas高级教程之:GroupBy用法 目录 简介 分割数据 多index get_group dropna groups属性 index的层级 group的遍历 聚合操作 通用聚合方法 同时使用 ...
- 李洪强漫谈iOS开发[C语言-008]- C语言重难点
C语言学习的重难点 写程序的三个境界: 照抄的境界,翻译的境界,创新的境界 1 伪代码: 描述C语言的编程范式 范式: 规范的一种表示 对于C的范式学会的话,C, C++ Java 都会了 2 ...
- Pandas 学习笔记
Pandas 学习笔记 pandas 由两部份组成,分别是 Series 和 DataFrame. Series 可以理解为"一维数组.列表.字典" DataFrame 可以理解为 ...
- javascript进阶笔记(2)
js是一门函数式语言,因为js的强大威力依赖于是否将其作为函数式语言进行使用.在js中,我们通常要大量使用函数式编程风格.函数式编程专注于:少而精.通常无副作用.将函数作为程序代码的基础构件块. 在函 ...
- Pandas分组运算(groupby)修炼
Pandas分组运算(groupby)修炼 Pandas的groupby()功能很强大,用好了可以方便的解决很多问题,在数据处理以及日常工作中经常能施展拳脚. 今天,我们一起来领略下groupby() ...
随机推荐
- 基于Prometheus和Grafana的监控平台 - 环境搭建
相关概念 微服务中的监控分根据作用领域分为三大类,Logging,Tracing,Metrics. Logging - 用于记录离散的事件.例如,应用程序的调试信息或错误信息.它是我们诊断问题的依据. ...
- Maya零基础新手入门教程第一部分:界面
第1步:菜单 如果您曾经使用过一个软件,那么您将习惯菜单!在Maya中,菜单包含用于在场景中工作的工具和操作.与大多数程序一样,主菜单位于Maya窗口的顶部,然后还有面板和选项窗口的单独菜单.您还可以 ...
- Spring源码分析之IOC的三种常见用法及源码实现(一)
1.ioc核心功能bean的配置与获取api 有以下四种 (来自精通spring4.x的p175) 常用的是前三种 第一种方式 <?xml version="1.0" enc ...
- Ubuntu18.04安装NVIDIA显卡驱动
1. 查看GPU型号 lspci | grep -i nvidia 我是 GeForce GTX 960M 2. NVIDIA官网下载驱动: https://www.nvidia.com/Downlo ...
- web安全之XSS基础-常见编码科普
0x01常用编码 html实体编码(10进制与16进制): 如把尖括号编码[ < ] -----> html十进制: < html十六进制:< javascript的八进制 ...
- JedisCluster与keys/scan查找
最近买了几个专栏,关于算法.JVM.redis,学不过来.主要是身体也不太好,视物光斑转头疼的问题出现越来越频繁.再加上早上起来嗓子痒打喷嚏.很烦. 稍记录一下redis集群的问题: 1.scan在集 ...
- UltraEdit等软件详细安装破解教程,附注册机(全网独家可用)
--- title: "UltraEdit等软件详细安装破解教程,附注册机(全网独家可用)" categories: soft tags: soft author: LIUREN ...
- <学会提问-批判性思维指南>运用
引子 这是我第二遍读此书,我认为并且希望这次阅读对我整个人生产生深远的影响.人一出生身上带着母体的抵抗力,大概6个月以后开始渐渐消失,靠自身的抵抗力活着.30岁前很多人会带着上天给的运气,终有一天,用 ...
- JAVA必知必问问题-1
数据类型 1) 基本类型: byte, int, long, float, double, boolean.... 要求记住基本类型占多少字节.范围.例如:byte 1字节范围-128-127,sho ...
- kali更新源地址更改
问题: Hit:1 http://mirrors.ustc.edu.cn/kali kali-rolling InReleaseIgn:2 http://mirrors.ustc.edu.cn/kal ...