决策树(上)-ID3、C4.5、CART
参考资料(要是对于本文的理解不够透彻,必须将以下博客认知阅读,方可全面了解决策树):
1.https://zhuanlan.zhihu.com/p/85731206
2.https://zhuanlan.zhihu.com/p/29980400
决策树是一个非常常见并且优秀的机器学习算法,它易于理解、可解释性强,其可作为分类算法,也可用于回归模型。本文将分三篇介绍决策树,第一篇介绍基本树(包括 ID3、C4.5、CART),第二篇介绍 Random Forest、Adaboost、GBDT,第三篇介绍 Xgboost 和 LightGBM。
在进入正题之前,先让我们了解一些有关信息论的知识!
信息论
1.信息熵
在决策树算法中,熵是一个非常非常重要的概念。一件事发生的概率越小,我们说它所蕴含的信息量越大。比如:我们听女人能怀孕不奇怪,如果某天听到哪个男人怀孕了,我们就会觉得emmm…信息量很大了。
所以我们这样衡量信息量:
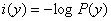
其中,P(y)是事件发生的概率。信息熵就是所有可能发生的事件的信息量的期望:
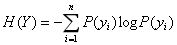 表达了Y事件发生的不确定度。
表达了Y事件发生的不确定度。
决策树属性划分算法
众所周知,决策树学习的关键在于如何选择最优划分属性,一般而言,随着划分过程不断进行,我们希望决策树的分支结点所包含的样本尽可能属于同一类别,即结点的“纯度”越来越高。
1.ID3
(1)思想
从信息论的知识中我们知道:信息熵越大,从而样本纯度越低,。ID3 算法的核心思想就是以信息增益来度量特征选择,选择信息增益最大的特征进行分裂。算法采用自顶向下的贪婪搜索遍历可能的决策树空间(C4.5 也是贪婪搜索)。
(2)划分标准(详细过程以及公式推导见西瓜书即可)
ID3算法使用信息增益为准则来选择划分属性,“信息熵”(information entropy)是度量样本结合纯度的常用指标,假定当前样本集合D中第k类样本所占比例为pk,则样本集合D的信息熵定义为:
假定通过属性划分样本集D,产生了V个分支节点,v表示其中第v个分支节点,易知:分支节点包含的样本数越多,表示该分支节点的影响力越大。故可以计算出划分后相比原始数据集D获得的“信息增益”(information gain)。
信息增益越大,表示使用该属性划分样本集D的效果越好,因此ID3算法在递归过程中,每次选择最大信息增益的属性作为当前的划分属性。
(3)缺点
- ID3 没有剪枝策略,容易过拟合;
- 信息增益准则对可取值数目较多的特征有所偏好,类似“编号”的特征其信息增益接近于 1;
- 只能用于处理离散分布的特征;
- 没有考虑缺失值。
2. C4.5
2.1 思想
C4.5 算法最大的特点是克服了 ID3 对特征数目的偏重这一缺点,引入信息增益率来作为分类标准。
C4.5 相对于 ID3 的缺点对应有以下改进方式:
- 引入悲观剪枝策略进行后剪枝;
- 引入信息增益率作为划分标准;
- 可以处理连续值:将连续特征离散化,假设 n 个样本的连续特征 A 有 m 个取值,C4.5 将其排序并取相邻两样本值的平均数共 m-1 个划分点,分别计算以该划分点作为二元分类点时的信息增益,并选择信息增益最大的点作为该连续特征的二元离散分类点;
- 可以处理缺失值:对于缺失值的处理可以分为两个子问题:
- 问题一:在特征值缺失的情况下进行划分特征的选择?(即如何计算特征的信息增益率)
- 问题二:选定该划分特征,对于缺失该特征值的样本如何处理?(即到底把这个样本划分到哪个结点里)
- 针对问题一,C4.5 的做法是:对于具有缺失值特征,用没有缺失的样本子集所占比重来折算;
- 针对问题二,C4.5 的做法是:将样本同时划分到所有子节点,不过要调整样本的权重值,其实也就是以不同概率划分到不同节点中。
2.2 划分标准
利用信息增益率可以克服信息增益的缺点,其公式为:
注意:信息增益率对可取值较少的特征有所偏好(分母越小,整体越大),因此 C4.5 并不是直接用增益率最大的特征进行划分,而是使用一个启发式方法:先从候选划分特征中找到信息增益高于平均值的特征,再从中选择增益率最高的。
2.3 剪枝策略(预剪枝+后剪枝)
决策树解决过拟合的主要方法:剪枝、随机森林
2.3.1 预剪枝
(1) 在决策树生成过程中,对每个结点在划分前先进行估计,若当前结点的划分不能带来决策树泛化性能提升,则停止划分并将当前结点标记为叶结点。在构造的过程中先评估,再考虑是否分支。衡量决策树泛化性能提升的方法:
- 节点内数据样本低于某一阈值;
- 所有节点特征都已分裂;
- 节点划分前准确率比划分后准确率高。
(2)优缺点
- 降低过拟合风险、显著减少决策树的训练时间开销和测试时间开销。
- 预剪枝基于“贪心”策略,有可能会带来欠拟合风险。
2.3.2 后剪枝(C4.5采用的是基于后剪枝的悲观剪枝方法)
(1) 后剪枝是先从训练集生成一棵完整的决策树,然后自底向上地对非叶子结点进行考察,若将该结点对应的子树替换为叶结点能带来决策树泛化性能提升,则将该子树替换为叶结点。
(2) 后剪枝决策树的欠拟合风险很小,泛化性能往往优于预剪枝决策树。但同时其训练时间会大的多。
2.4 缺点
- 剪枝策略可以再优化;
- C4.5 用的是多叉树,用二叉树效率更高;
- C4.5 只能用于分类;
- C4.5 使用的熵模型拥有大量耗时的对数运算,连续值还有排序运算;
- C4.5 在构造树的过程中,对数值属性值需要按照其大小进行排序,从中选择一个分割点,所以只适合于能够驻留于内存的数据集,当训练集大得无法在内存容纳时,程序无法运行。
3. CRAT
ID3 和 C4.5 虽然在对训练样本集的学习中可以尽可能多地挖掘信息,但是其生成的决策树分支、规模都比较大,CART 算法的二分法可以简化决策树的规模,提高生成决策树的效率。
3.1 思想
CART 在 C4.5 的基础上进行了很多提升。
- C4.5 为多叉树,运算速度慢,CART 为二叉树,运算速度快;
- C4.5 只能分类,CART 既可以分类也可以回归;
- CART 使用 Gini 系数作为变量的不纯度量,减少了大量的对数运算;
- CART 采用代理测试来估计缺失值,而 C4.5 以不同概率划分到不同节点中;
- CART 采用“基于代价复杂度剪枝”方法进行剪枝,而 C4.5 采用悲观剪枝方法。
3.2 划分标准
CART决策树(分类树)使用“基尼指数”(Gini index)来选择划分属性,基尼指数反映的是从样本集D中随机抽取两个样本,其类别标记不一致的概率,因此Gini(D)越小越好,这和信息增益(率)正好相反,基尼指数定义如下:
进而,使用属性α划分后的基尼指数为:
3.3 剪枝策略
采用一种“基于代价复杂度的剪枝”方法进行后剪枝,这种方法会生成一系列树,每个树都是通过将前面的树的某个或某些子树替换成一个叶节点而得到的,这一系列树中的最后一棵树仅含一个用来预测类别的叶节点。然后用一种成本复杂度的度量准则来判断哪棵子树应该被一个预测类别值的叶节点所代替。这种方法需要使用一个单独的测试数据集来评估所有的树,根据它们在测试数据集熵的分类性能选出最佳的树。
3.4类别不平衡
CART 的一大优势在于:无论训练数据集有多失衡,它都可以将其消除不需要建模人员采取其他操作。
CART 使用了一种先验机制,其作用相当于对类别进行加权。这种先验机制嵌入于 CART 算法判断分裂优劣的运算里,在 CART 默认的分类模式中,总是要计算每个节点关于根节点的类别频率的比值,这就相当于对数据自动重加权,对类别进行均衡。
3.5 回归树
CART(Classification and Regression Tree,分类回归树),从名字就可以看出其不仅可以用于分类,也可以应用于回归。其回归树的建立算法上与分类树部分相似,这里简单介绍下不同之处。
3.6.1 连续值处理
对于连续值的处理,CART 分类树采用基尼系数的大小来度量特征的各个划分点。在回归模型中,我们使用常见的和方差度量方式,对于任意划分特征 A,对应的任意划分点 s 两边划分成的数据集 和
,求出使
和
各自集合的均方差最小,同时
和
的均方差之和最小所对应的特征和特征值划分点。表达式为:
其中, 为
数据集的样本输出均值,
为
数据集的样本输出均值。
3.6.2 预测方式
对于决策树建立后做预测的方式,上面讲到了 CART 分类树采用叶子节点里概率最大的类别作为当前节点的预测类别。而回归树输出不是类别,它采用的是用最终叶子的均值或者中位数来预测输出结果。
4.总结
最后通过总结的方式对比下 ID3、C4.5 和 CART 三者之间的差异。
除了之前列出来的划分标准、剪枝策略、连续值确实值处理方式等之外,我再介绍一些其他差异:
- 划分标准的差异:ID3 使用信息增益偏向特征值多的特征,C4.5 使用信息增益率克服信息增益的缺点,偏向于特征值小的特征,CART 使用基尼指数克服 C4.5 需要求 log 的巨大计算量,偏向于特征值较多的特征。
- 使用场景的差异:ID3 和 C4.5 都只能用于分类问题,CART 可以用于分类和回归问题;ID3 和 C4.5 是多叉树,速度较慢,CART 是二叉树,计算速度很快;
- 样本数据的差异:ID3 只能处理离散数据且缺失值敏感,C4.5 和 CART 可以处理连续性数据且有多种方式处理缺失值;从样本量考虑的话,小样本建议 C4.5、大样本建议 CART。C4.5 处理过程中需对数据集进行多次扫描排序,处理成本耗时较高,而 CART 本身是一种大样本的统计方法,小样本处理下泛化误差较大 ;
- 样本特征的差异:ID3 和 C4.5 层级之间只使用一次特征,CART 可多次重复使用特征;
- 剪枝策略的差异:ID3 没有剪枝策略,C4.5 是通过悲观剪枝策略来修正树的准确性,而 CART 是通过代价复杂度剪枝
决策树(上)-ID3、C4.5、CART的更多相关文章
- 决策树模型 ID3/C4.5/CART算法比较
决策树模型在监督学习中非常常见,可用于分类(二分类.多分类)和回归.虽然将多棵弱决策树的Bagging.Random Forest.Boosting等tree ensembel 模型更为常见,但是“完 ...
- 机器学习算法总结(二)——决策树(ID3, C4.5, CART)
决策树是既可以作为分类算法,又可以作为回归算法,而且在经常被用作为集成算法中的基学习器.决策树是一种很古老的算法,也是很好理解的一种算法,构建决策树的过程本质上是一个递归的过程,采用if-then的规 ...
- ID3\C4.5\CART
目录 树模型原理 ID3 C4.5 CART 分类树 回归树 树创建 ID3.C4.5 多叉树 CART分类树(二叉) CART回归树 ID3 C4.5 CART 特征选择 信息增益 信息增益比 基尼 ...
- 决策树(ID3,C4.5,CART)原理以及实现
决策树 决策树是一种基本的分类和回归方法.决策树顾名思义,模型可以表示为树型结构,可以认为是if-then的集合,也可以认为是定义在特征空间与类空间上的条件概率分布. [图片上传失败...(image ...
- 决策树 ID3 C4.5 CART(未完)
1.决策树 :监督学习 决策树是一种依托决策而建立起来的一种树. 在机器学习中,决策树是一种预测模型,代表的是一种对象属性与对象值之间的一种映射关系,每一个节点代表某个对象,树中的每一个分叉路径代表某 ...
- 21.决策树(ID3/C4.5/CART)
总览 算法 功能 树结构 特征选择 连续值处理 缺失值处理 剪枝 ID3 分类 多叉树 信息增益 不支持 不支持 不支持 C4.5 分类 多叉树 信息增益比 支持 ...
- 机器学习相关知识整理系列之一:决策树算法原理及剪枝(ID3,C4.5,CART)
决策树是一种基本的分类与回归方法.分类决策树是一种描述对实例进行分类的树形结构,决策树由结点和有向边组成.结点由两种类型,内部结点表示一个特征或属性,叶结点表示一个类. 1. 基础知识 熵 在信息学和 ...
- 后端程序员之路 16、信息熵 、决策树、ID3
信息论的熵 - guisu,程序人生. 逆水行舟,不进则退. - 博客频道 - CSDN.NEThttp://blog.csdn.net/hguisu/article/details/27305435 ...
- 决策树之ID3,C4.5及CART
决策树的基本认识 决策树学习是应用最广的归纳推理算法之一,是一种逼近离散值函数的方法,年,香农引入了信息熵,将其定义为离散随机事件出现的概率,一个系统越是有序,信息熵就越低,反之一个系统越是混乱,它 ...
随机推荐
- bugku 成绩单
看起来像是SQL注入,先来试试. 输入1,2,3显示的是三个人成绩. 来试试是否存在注入. 输入1,正常.输入1' 错误.输入1’#正常,说明存在注入点. 首先来看下有几列从1开始试,1’ order ...
- 尹吉峰:使用 OpenResty 搭建高性能 Web 应用
2019 年 8 月 31 日,OpenResty 社区联合又拍云,举办 OpenResty × Open Talk 全国巡回沙龙·成都站,原贝壳找房基础架构部工程师尹吉峰在活动上做了<使用 O ...
- java和JavaScript的注释区别
今天在学习JavaScript的注释时候,想到了跟java注释对比一下有什么区别?下面详细的对比了一下. java的注释 java在使用注释的时候分为3种类型的注释. 单行注释:在注释内容前加符号 “ ...
- 白话系列之实现自己简单的mvc式webapi框架
前言:此文为极简mvc式的api框架,只当做入门api的解析方式,并且这里也不算是mvc框架,因为没有view层,毕竟现在大部分都属于前后端分离,当然也可以提供view层,因为只是将view当做文本返 ...
- Python多线程多进程那些事儿看这篇就够了~~
自己以前也写过多线程,发现都是零零碎碎,这篇写写详细点,填一下GIL和Python多线程多进程的坑~ 总结下GIL的坑和python多线程多进程分别应用场景(IO密集.计算密集)以及具体实现的代码模块 ...
- [BZOJ1116] CLO
1116: [POI2008]CLO Time Limit: 10 Sec Memory Limit: 162 MBSubmit: 1311 Solved: 709[Submit][Status] ...
- MongoDB系列---入门安装操作
MongoDB 学习大纲: 1.MongoDB简介与其它数据库对比以及数据类型 2.MongoDB安装 3.MongoDB简单操作 环境要求: Linux 一.MongoDB简介 1 什么是Mongo ...
- Spring Cloud zuul网关服务 一
上一篇进行Netflix Zuul 1.0 与 gateway的对比.今天来介绍一下 zuul的搭建及应用 Zuul 工程创建 工程创建 cloud-gateway-zuul.还是基于之前的工程 po ...
- Spring Data - Spring Data JPA 提供的各种Repository接口
Spring Data Jpa 最近博主越来越懒了,深知这样不行.还是决定努力奋斗,如此一来,就有了一下一波复习 演示代码都基于Spring Boot + Spring Data JPA 传送门: 博 ...
- mysql慢日志分析组件安装
1.pt-query-digest 安装 cd /usr/bin wget percona.com/get/pt-query-digest chmod u+x pt-query-digest yum ...