数据库Oracle组函数和分组函数
组函数:
组函数操作行集,给出每组的结果。组函数不象单行函数,组函数对行的集合进行操作,对每组给出一个结果。这些集合可能是整个表或者是表分成的组。
组函数与单行函数区别:
单行函数对查询到每个结果集做处理,而组函数只对分组数据做处理。
单行函数对每个结果集返回一个结果,而组函数对每个分组返回一个结果。
组函数的类型:
•AVG 平均值
• COUNT 计数
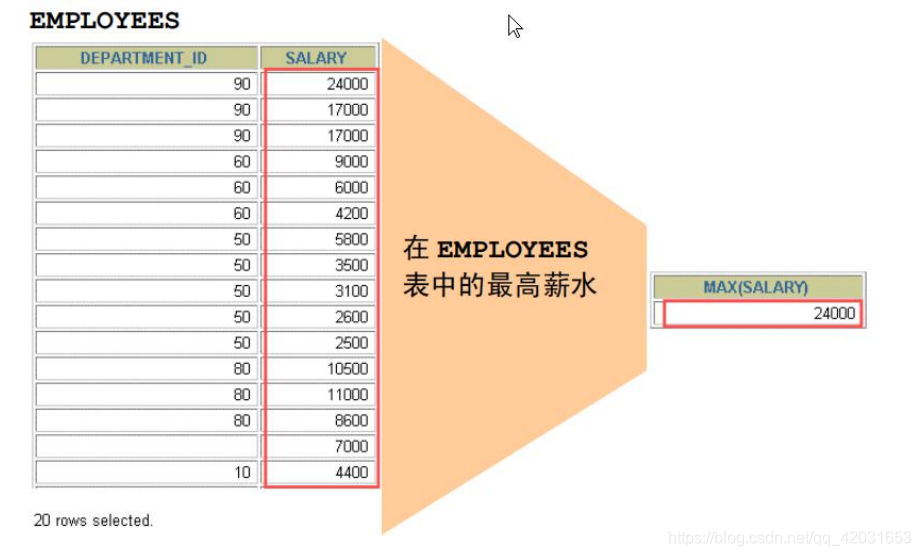
• MAX 最大值
• MIN 最小值
• SUM 合计
组函数的语法:
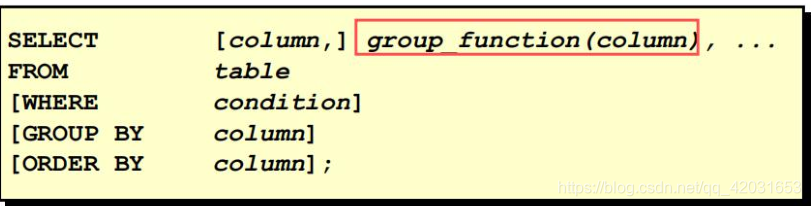
使用组函数的原则:
• 用于函数的参数的数据类型可以是 CHAR、VARCHAR2、NUMBER 或 DATE。
• 所有组函数忽略空值。为了用一个值代替空值,用 NVL、NVL2 或 COALESCE 函数。
组函数的使用:
1.使用 AVG 和 和 SUM
AVG(arg)函数:对分组数据做平均值运算。
arg:参数类型只能是数字类型。
SUM(arg)函数:对分组数据求和。
arg:参数类型只能是数字类型 。
例: 求雇员表中的的平均薪水与薪水总额。
SQL> select sum(e.salary) "薪水总额:",avg(e.salary) "平均薪水:" from employees e;
薪水总额: 平均薪水:
---------- ----------
681816 6432.226412.用 使用 MIN 和 和 MAX
MIN(arg)函数:求分组中最小数据。
arg:参数类型可以是字符、数字、日期。
MAX(arg)函数:求分组中最大数据。
arg:参数类型可以是字符、数字、日期。
例: 求雇员表中的最高薪水与最低薪水。
SQL> select min(e.salary) MIN_SALARY,max(e.salary) MAX_SALARY from employees e;
MIN_SALARY MAX_SALARY
---------- ----------
2100 240003.用 使用 COUNT 函数
COUNT 函数:返回一个表中的行数。
COUNT 函数有三种格式:
• COUNT(*)
• COUNT(expr)
• COUNT(DISTINCT expr)
COUNT(*):
返回表中满足 SELECT 语句标准的行数,包括重复行,包括有空值列的行。如果WHERE 子句包括在 SELECT 语句中,COUNT(*) 返回满足 WHERE 子句条件的行数.
例:返回查询结果的总条数:
SQL> select count(*) from employees;
COUNT(*)
----------
106COUNT(expr)
返回在列中的由 expr 指定的非空值的数
例:显示部门 80 中有佣金的雇员人数
SQL> select count(e.commission_pct) from employees e where e.department_id=80;
COUNT(E.COMMISSION_PCT)
-----------------------
33COUNT(DISTINCT expr:
使用 DISTINCT 关键字禁止计算在一列中的重复值。
例:显示 EMPLOYEES 表中不重复的部门数。
SQL> select count(e.department_id) from employees e;
COUNT(E.DEPARTMENT_ID)
----------------------
105
SQL> select count(distinct e.department_id) from employees e;
COUNT(DISTINCTE.DEPARTMENT_ID)
------------------------------
11
4.组函数和 Null :
所有组函数忽略列中的空值。
在组函数中使用 NVL 函数来处理空值。
例:计算有佣金的员工的佣金平均值。
SQL> select avg(e.commission_pct) from employees e where e.commission_pct is not null;
AVG(E.COMMISSION_PCT)
---------------------
0.223529411764706
SQL> select avg(e.commission_pct) from employees e;
AVG(E.COMMISSION_PCT)
---------------------
0.223529411764706例:计算所有员工的佣金的平均值。
SQL> select avg(nvl(e.commission_pct,0)) from employees e;
AVG(NVL(E.COMMISSION_PCT,0))
----------------------------
0.0716981132075472创建数据组(GROUPBY):
可以根据需要将查询到的结果集信息划分为较小的组,用 GROUP BY 子句实现。
GROUP BY 子句用法:

GROUP BY 子句:GROUP BY 子句可以把表中的行划分为组。然后可以用组函数返回每一组的摘要信息
使用分组原则:
• 如果在 SELECT 子句中包含了组函数,就不能选择单独的结果,除非单独的列出现在 GROUP BY 子句中。如果未能在 GROUP BY 子句中包含一个字段列表,你会收到一个错误信息。
• 使用 WHERE 子句,你可以在划分行成组以前过滤行。
• 在 GROUP BY 子句中必须包含列。
• 在 GROUP BY 子句中你不能用列别名。
• 默认情况下,行以包含在 GROUP BY 列表中的字段的升序排序。可以用 ORDER BY子句覆盖这个默认值。
GROUP BY 子句 的使用:
我们可以根据自己的需要对数据进行分组,在分组时,只要将需要做分组的列的列名添加到 GROUP BY 子句后侧就可以。GROUP BY 列不必在 SELECT 列表中。

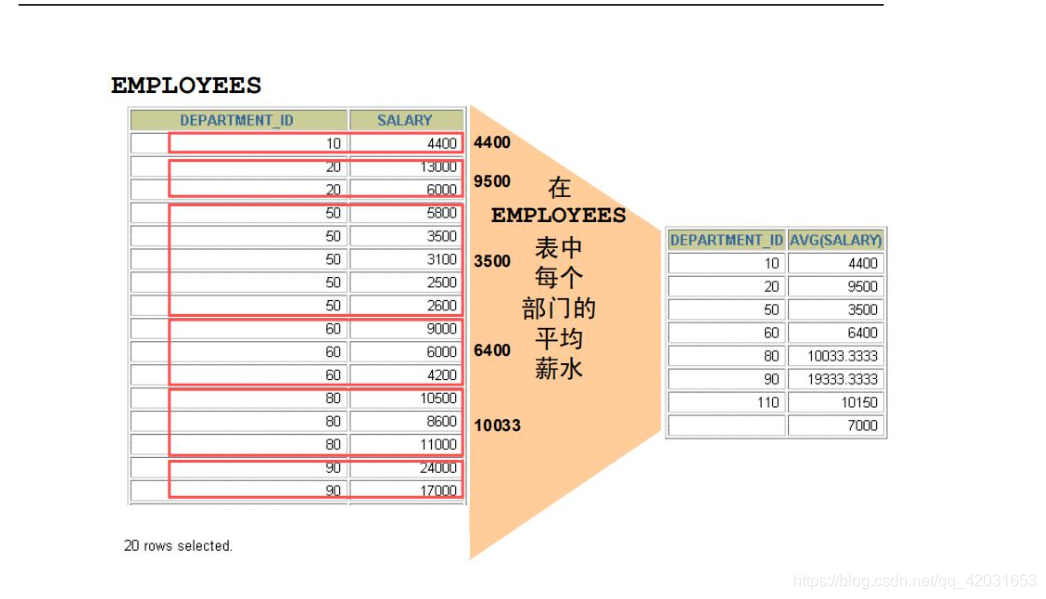
例:求每个部门的平均薪水
SQL> select avg(e.salary),e.department_id from employees e where e.department_id is not null group by e.department_id;
AVG(E.SALARY) DEPARTMENT_ID
------------- -------------
8601.33333333 100
4150 30
19333.3333333 90
9500 20
10000 70
10154 110
3475.55555555 50
8936.36363636 80
6500 40
5760 60
4400 10
11 rows selected多于一个列的分组:
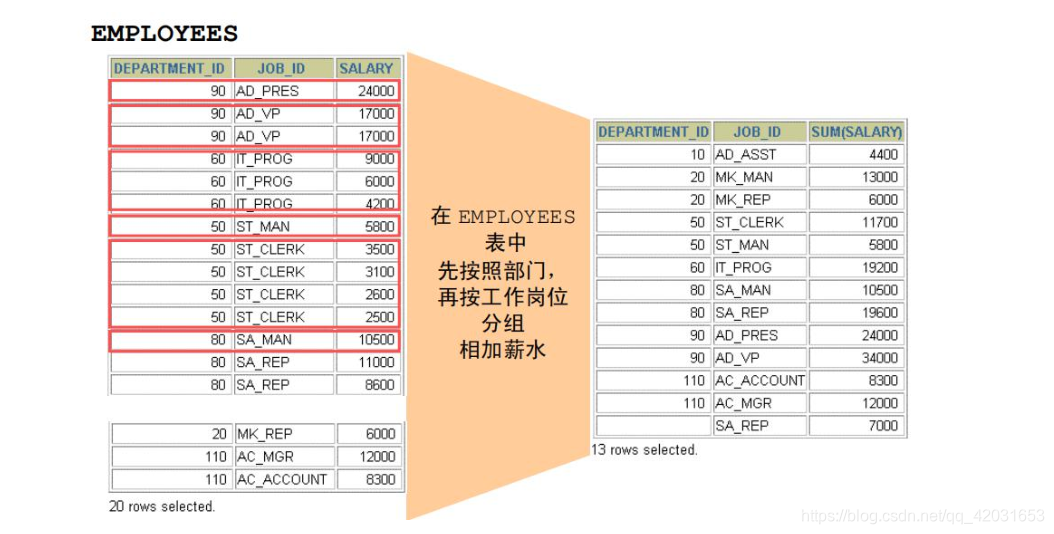
例:显示在每个部门中付给每个工作岗位的合计薪水的报告。
SQL> select sum(e.salary),e.job_id,e.department_id from employees e
2 group by e.department_id,e.job_id;
SUM(E.SALARY) JOB_ID DEPARTMENT_ID
------------- ---------- -------------
8300 AC_ACCOUNT 110
34000 AD_VP 90
55700 ST_CLERK 50
233900 SA_REP 80
36400 ST_MAN 50
61000 SA_MAN 80
12008 AC_MGR 110
24000 AD_PRES 90
28800 IT_PROG 60
12008 FI_MGR 100
13900 PU_CLERK 30
64300 SH_CLERK 50
13000 MK_MAN 20
39600 FI_ACCOUNT 100
7000 SA_REP
10000 PR_REP 70
11000 PU_MAN 30
4400 AD_ASST 10
6000 MK_REP 20
6500 HR_REP 40
20 rows selectedGROUP BY 子句执行的顺序
先进行数据查询,在对数据进行分组,然后执行组函数。
约束分结果(having子句)
having子句通常都是和group by一起用,可以放在group by的前面,也可以放在后面(建议:放在group by的后面,方便自己查看。),having子句是用来弥补group by子句不能用where条件语句的不足,它的出现就是为了和where子句一样的效果,
HAVING 的用法:
例:显示那些最高薪水大于 $10,000 的部门的部门号和最高薪水
SQL> select max(e.salary),e.department_id from employees e
2 group by e.department_id
3 having max(e.salary)>10000;
MAX(E.SALARY) DEPARTMENT_ID
------------- -------------
12008 100
11000 30
24000 90
13000 20
12008 110
14000 80
6 rows selected例:查询那些最高薪水大于 $10,000 的部门的部门号和平均薪水
SQL> select avg(e.salary),e.department_id from employees e
2 group by e.department_id
3 having max(e.salary)>10000;
AVG(E.SALARY) DEPARTMENT_ID
------------- -------------
8601.33333333 100
4150 30
19333.3333333 90
9500 20
10154 110
8936.36363636 80
6 rows selected嵌套组函数:
在使用组函数时我们也可以根据需要来做组函数的嵌套使用。
例:显示部门中的最大平均薪水:
SQL> select max(avg(e.salary))from employees e group by e.department_id;
MAX(AVG(E.SALARY))
------------------
19333.3333333333组函数小节练习:
1.显示所有雇员的最高、 、 最低、 、 合计和平均薪水, , 列标签分别为 :Maximum 、Minimum 、Sum 和 和 Average 。四 舍五入结果为最近的整数 :
SQL> select max(e.salary) Maximum,min(e.salary) Minimum,sum(e.salary) Sum,avg(e.salary) Average from employees e
2 ;
MAXIMUM MINIMUM SUM AVERAGE
---------- ---------- ---------- ----------
24000 2100 681816 6432.226412.修改上题 显示每中工作类型的最低、最高、合计和平均薪水:
SQL> select e.job_id,max(e.salary) Maximum,min(e.salary) Minimum,sum(e.salary) Sum,avg(e.salary) Average from employees e group by e.job_id;
JOB_ID MAXIMUM MINIMUM SUM AVERAGE
---------- ---------- ---------- ---------- ----------
IT_PROG 9000 4200 28800 5760
AC_MGR 12008 12008 12008 12008
AC_ACCOUNT 8300 8300 8300 8300
ST_MAN 8200 5800 36400 7280
PU_MAN 11000 11000 11000 11000
AD_ASST 4400 4400 4400 4400
AD_VP 17000 17000 34000 17000
SH_CLERK 4200 2500 64300 3215
FI_ACCOUNT 9000 6900 39600 7920
FI_MGR 12008 12008 12008 12008
PU_CLERK 3100 2500 13900 2780
SA_MAN 14000 10500 61000 12200
MK_MAN 13000 13000 13000 13000
PR_REP 10000 10000 10000 10000
AD_PRES 24000 24000 24000 24000
SA_REP 11500 6100 240900 8306.89655
MK_REP 6000 6000 6000 6000
ST_CLERK 3600 2100 55700 2785
HR_REP 6500 6500 6500 6500
19 rows selected3.写一个查询显示每一工作岗位的人数:
SQL> select e.job_id,count(e.employee_id) from employees e group by e.job_id;
JOB_ID COUNT(E.EMPLOYEE_ID)
---------- --------------------
AC_ACCOUNT 1
AC_MGR 1
AD_ASST 1
AD_PRES 1
AD_VP 2
FI_ACCOUNT 5
FI_MGR 1
HR_REP 1
IT_PROG 5
MK_MAN 1
MK_REP 1
PR_REP 1
PU_CLERK 5
PU_MAN 1
SA_MAN 5
SA_REP 29
SH_CLERK 20
ST_CLERK 20
ST_MAN 5
19 rows selected4.确定经理人数,不需要列出他们,列标签是 Number ofManagers 。
SQL> select count(distinct e.manager_id) from employees e;
COUNT(DISTINCTE.MANAGER_ID)
---------------------------
185.写一个查询显示最高和最低薪水之间的差。列标签是DIFFERENCE 。
SQL> select (max(e.salary)-min(e.salary)) DIFFERENCE from employees e;
DIFFERENCE
----------
219006.显示经理号和经理付给雇员的最低薪水。 。 排除那些经理未知的人 。排除最低薪水小于等于 $6,000 的组 。 按薪水降序排序输出。
SQL> select e.manager_id, min(e.salary) from employees e where e.manager_id is not null
2 group by e.manager_id
3 having min(e.salary)<=6000
4 order by min(e.salary) desc;
MANAGER_ID MIN(E.SALARY)
---------- -------------
201 6000
100 5800
101 4400
103 4200
123 2500
114 2500
124 2500
122 2200
120 2200
121 2100
10 rows selected7. 写一个查询显示每个部门的名字、地点、人数和部门中所有雇员的平均薪水。四舍五入薪水到两位小数
SQL> select d.department_name,d.location_id,count(e.employee_id),round(avg(e.salary),2) from employees e,departments d
2 where e.department_id=d.department_id
3 group by d.department_name,d.location_id;
DEPARTMENT_NAME LOCATION_ID COUNT(E.EMPLOYEE_ID) ROUND(AVG(E.SALARY),2)
------------------------------ ----------- -------------------- ----------------------
Administration 1700 1 4400
Marketing 1800 2 9500
Sales 2500 33 8936.36
Purchasing 1700 6 4150
Finance 1700 6 8601.33
IT 1400 5 5760
Executive 1700 3 19333.33
Shipping 1500 45 3475.56
Accounting 1700 2 10154
Human Resources 2400 1 6500
Public Relations 2700 1 100008.创建一个查询显示雇员总数,和在 2001 、2002 、2003 和受雇的雇员人数。创建适当的列标题。
SQL> select count(e.employee_id),sum(decode(to_char(e.hire_date,'yyyy'),'2001',1,0)) "2001",sum(decode(to_char(e.hire_date,'yyyy'),'2002',1,0)) "2002",sum(decode(to_char(e.hire_date,'yyyy'),'2003',1,0)) "2003" from employees e;
COUNT(E.EMPLOYEE_ID) 2001 2002 2003
-------------------- ---------- ---------- ----------
106 1 7 6
9.创建一个混合查询显示工作岗位和工作岗位的薪水合计,并门 且合计部门 20 、50 、80 和 和 90 的工作岗位的薪水。给每
列一个恰当的列标题
SQL> select e.job_id,sum(e.salary),sum(decode(e.department_id,20,e.salary)) "dept_20",sum(decode(e.department_id,50,e.salary)) "dept_50",sum(decode(e.department_id,20,e.salary)) "dept_80",sum(decode(e.department_id,90,e.salary)) "dept_90" from employees e group by e.job_id;
JOB_ID SUM(E.SALARY) dept_20 dept_50 dept_80 dept_90
---------- ------------- ---------- ---------- ---------- ----------
IT_PROG 28800
AC_MGR 12008
AC_ACCOUNT 8300
ST_MAN 36400 36400
PU_MAN 11000
AD_ASST 4400
AD_VP 34000 34000
SH_CLERK 64300 64300
FI_ACCOUNT 39600
FI_MGR 12008
PU_CLERK 13900
SA_MAN 61000
MK_MAN 13000 13000 13000
PR_REP 10000
AD_PRES 24000 24000
SA_REP 240900
MK_REP 6000 6000 6000
ST_CLERK 55700 55700
HR_REP 6500
19 rows selected数据库Oracle组函数和分组函数的更多相关文章
- Oracle学习笔记_05_分组函数
组函数:avg sum max min count group by having group by 增强:rollup cube grouping groupi ...
- oracle(sql)基础篇系列(一)——基础select语句、常用sql函数、组函数、分组函数
花点时间整理下sql基础,温故而知新.文章的demo来自oracle自带的dept,emp,salgrade三张表.解锁scott用户,使用scott用户登录就可以看到自带的表. #使用ora ...
- oracle(sql)基础篇系列(一)——基础select语句、常用sql函数、组函数、分组函数
花点时间整理下sql基础,温故而知新.文章的demo来自oracle自带的dept,emp,salgrade三张表.解锁scott用户,使用scott用户登录就可以看到自带的表. #使用oracle用 ...
- DQL---条件查询、单行函数、多行函数、分组函数、数据类型
一.DQL 1.基本规则: (1)对于日期型数据,做 *,/ 运算不合法,可以进行 +, - 运算.比如给日期加一天或减一个月,结果仍为一个日期.两个日期间只能为减法,返回两个日期相差的天数,两个日期 ...
- mysql 字符串函数、分组函数
字符串函数 1.concat 函数 drop table test;create table test(id int(4), name varchar(10), sex char(2));insert ...
- 《官方资料》 例如:string 函数 、分组函数
site:www.mysql.com SUBSTRING_INDEX ----------------------------------------------------------------- ...
- oracle强化练习之分组函数
1. 显示平均工资为>2000的职位 select job,avg(sal) from emp group by job having avg(sal)>2500; 2. ...
- oracle 10g 学习之多表查询、分组函数(6)
笛卡尔集 l 笛卡尔集会在下面条件下产生: 省略连接条件 连接条件无效 所有表中的所有行互相连接 l 为了避免笛卡尔集, 可以在 WHERE 加入有效的连接条件. 自连接 select m.las ...
- Oracle系列六 分组函数
分组函数作用于一组数据,并对一组数据返回一个值. 组函数类型 AVG COUNT MAX MIN STDDEV SUM 组函数语法 SELECT [column,] group_function(co ...
随机推荐
- css3 svg 物体跟随路径动画教程
css3 svg 物体跟随路径动画教程https://www.jianshu.com/p/992488f3f3fc
- Python 面向对象之一 类与属性
Python 面向对象之 类与属性 今天接触了一下面向对象,发现面向对象和之前理解的简直就是天壤之别,在学Linux的时候,一切皆文件,现在学面向对象了,so,一切皆对象. 之前不是一直在学的用面向函 ...
- Dubbo的应用
导语:Dubbo是阿里巴巴的一个分布式服务的开源框架,致力于提供高性能和透明化的RPC远程服务调用方案,是阿里巴巴SOA服务化治理方案的核心框架,每天为2,000+个服务提供3,000,000,000 ...
- 五分钟学会HTML5的WebSocket协议
1.背景 很多网站为了实现推送技术,所用的技术都是Ajax轮询.轮询是在特定的的时间间隔由浏览器对服务器发出HTTP请求,然后由服务器返回最新的数据给客户端的浏览器.这种传统的模式带来很明显的缺点 ...
- 开始逆向objc基础准备(一)简单认识一下arm32,以及与x86汇编指令类比
ARM32体系中有31或33个通用寄存器,没有特定的某种态下有r0-r15一共16个寄存器,快速中断态下有另一组r8-r12备份寄存器,在用户态和系统态之外其它态下都各自有一组r13-r14备份寄存器 ...
- 用.net core mvc 开发一个虽小但五脏俱全的网站
.net core mvc 发布有很长时间了,但是一直没有用过,最近突然想开发一个导航网站,于是就抽时间开发了一个专门为开发者使用的导航站点,想看的话请移步我的上一篇博客https://www.cnb ...
- LinearLayout适配不同机型技巧
<View android:layout_width="match_parent" android:layout_height="0dp" android ...
- 今天是python专场UDP socket 链接
type = SOCK_DGRAM UDP 协议的通信优势 允许一个服务器的同时和多个客户端通信 server import socket sk = socket.socket(type=socket ...
- DVWA学习之SQL注入
DVWA学习之SQL注入 环境工具 dvwa 1.9 phpstudy firefox burpsuite 实验步骤 一.设置安全级别为LOW 1. 登录DVWA,并将安全级别设置为LOW 2. 进入 ...
- SpringSecurity环境下配置CORS跨站资源共享规则
一.CORS简述 要说明CORS(Cross Origin Resourse-Sharing) 跨站资源共享,就必须先说同源策略.长话短说,同源策略就是向服务端发起请求的时候,以下三项必须与当前浏览器 ...