Python网络爬虫入门实战(爬取最近7天的天气以及最高/最低气温)
python版本: 3.5
IDE : pycharm 5.0.4
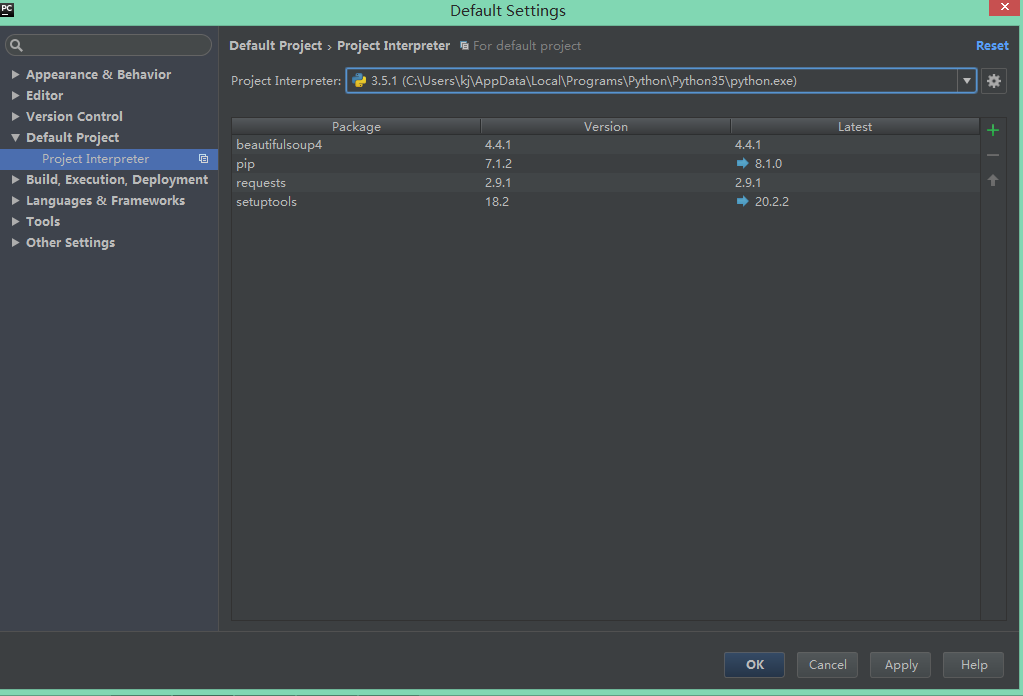
要用到的包可以用pycharm下载:
File->Default Settings->Default Project->Project Interpreter
选择python版本并点右边的加号安装想要的包
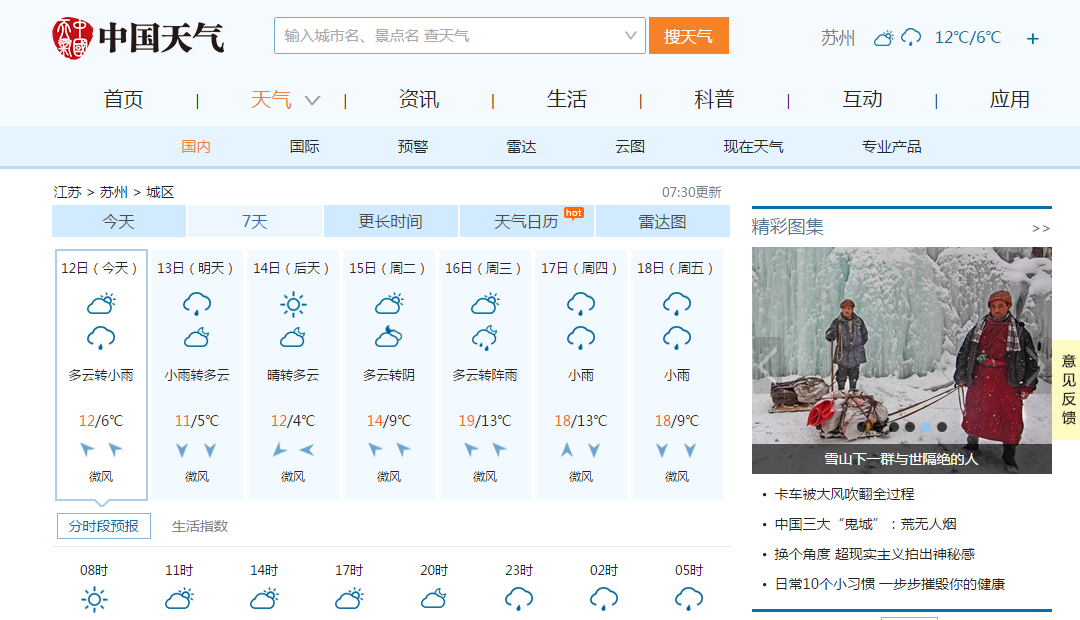
我选择的网站是中国天气网中的苏州天气,准备抓取最近7天的天气以及最高/最低气温
http://www.weather.com.cn/weather/101190401.shtml
PS:如有需要最新Python入门到实战学习资料的朋友可以点击下方链接自行获取
http://note.youdao.com/noteshare?id=a3a533247e4c084a72c9ae88c271e3d1
程序开头我们添加:
# coding : UTF-8
- 1
- 2
这样就能告诉解释器该py程序是utf-8编码的,源程序中可以有中文。
要引用的包:
import requests
import csv
import random
import time
import socket
import http.client
# import urllib.request
from bs4 import BeautifulSoup- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
requests:用来抓取网页的html源代码
csv:将数据写入到csv文件中
random:取随机数
time:时间相关操作
socket和http.client 在这里只用于异常处理
BeautifulSoup:用来代替正则式取源码中相应标签中的内容
urllib.request:另一种抓取网页的html源代码的方法,但是没requests方便(我一开始用的是这一种)
获取网页中的html代码:
def get_content(url , data = None):
header={
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate, sdch',
'Accept-Language': 'zh-CN,zh;q=0.8',
'Connection': 'keep-alive',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/43.0.235'
}
timeout = random.choice(range(80, 180))
while True:
try:
rep = requests.get(url,headers = header,timeout = timeout)
rep.encoding = 'utf-8'
# req = urllib.request.Request(url, data, header)
# response = urllib.request.urlopen(req, timeout=timeout)
# html1 = response.read().decode('UTF-8', errors='ignore')
# response.close()
break
# except urllib.request.HTTPError as e:
# print( '1:', e)
# time.sleep(random.choice(range(5, 10)))
#
# except urllib.request.URLError as e:
# print( '2:', e)
# time.sleep(random.choice(range(5, 10)))
except socket.timeout as e:
print( '3:', e)
time.sleep(random.choice(range(8,15)))
except socket.error as e:
print( '4:', e)
time.sleep(random.choice(range(20, 60)))
except http.client.BadStatusLine as e:
print( '5:', e)
time.sleep(random.choice(range(30, 80)))
except http.client.IncompleteRead as e:
print( '6:', e)
time.sleep(random.choice(range(5, 15)))
return rep.text
# return html_text- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
header是requests.get的一个参数,目的是模拟浏览器访问
header 可以使用chrome的开发者工具获得,具体方法如下:
打开chrome,按F12,选择network
重新访问该网站,找到第一个网络请求,查看它的header
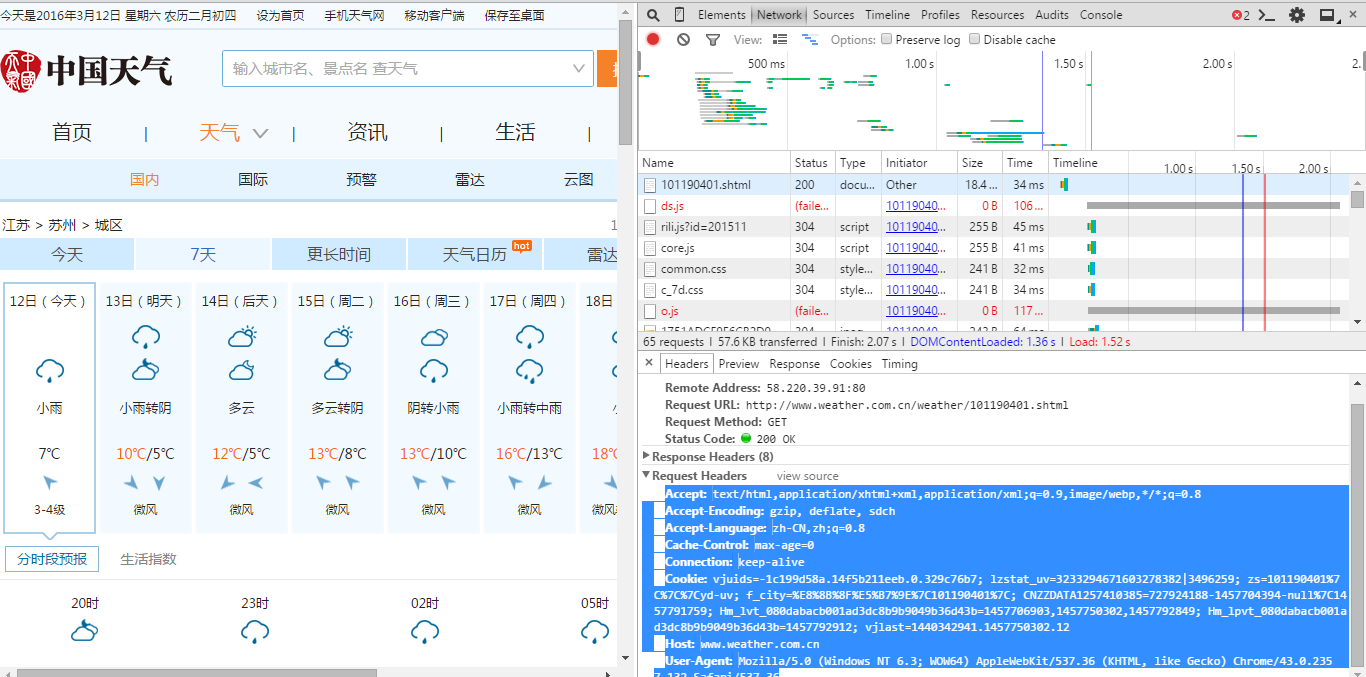
timeout是设定的一个超时时间,取随机数是因为防止被网站认定为网络爬虫。
然后通过requests.get方法获取网页的源代码、
rep.encoding = ‘utf-8’是将源代码的编码格式改为utf-8(不该源代码中中文部分会为乱码)
下面是一些异常处理
返回 rep.text
获取html中我们所需要的字段:
这里我们主要要用到BeautifulSoup
BeautifulSoup 文档http://www.crummy.com/software/BeautifulSoup/bs4/doc/
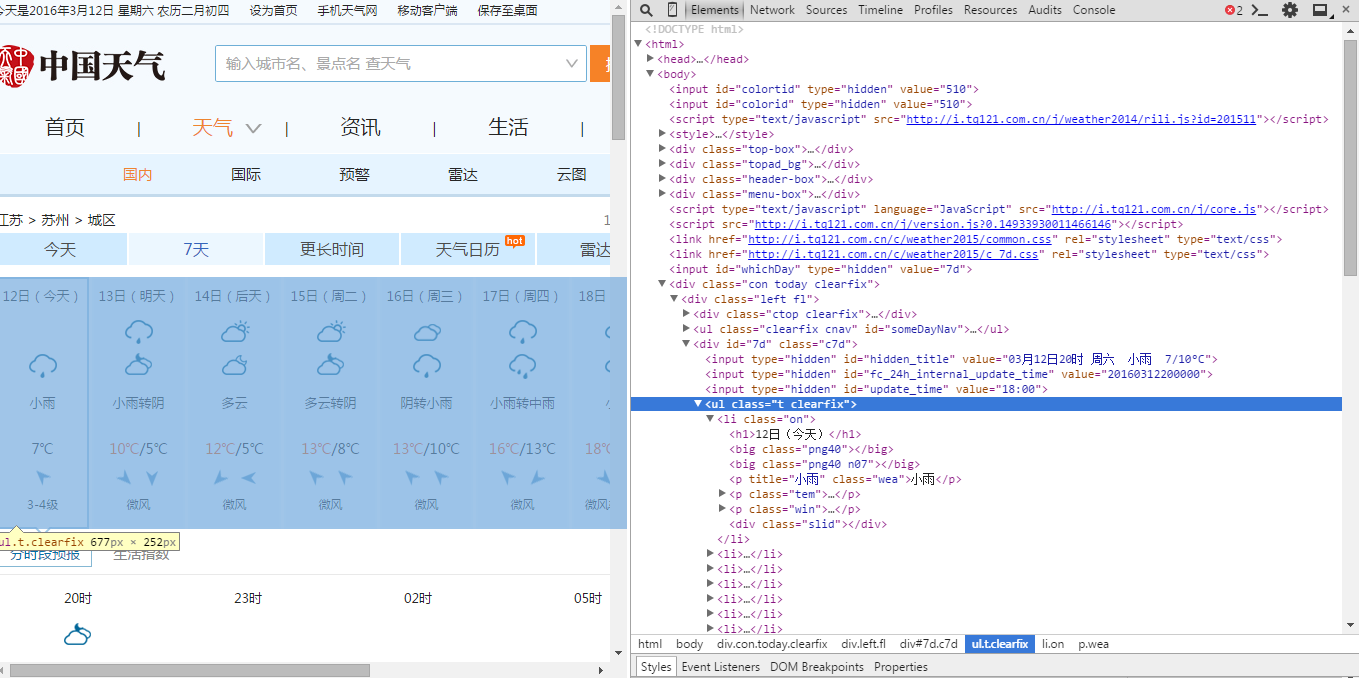
首先还是用开发者工具查看网页源码,并找到所需字段的相应位置
找到我们需要字段都在 id = “7d”的“div”的ul中。日期在每个li中h1 中,天气状况在每个li的第一个p标签内,最高温度和最低温度在每个li的span和i标签中。
感谢Joey_Ko指出的错误:到了傍晚,当天气温会没有最高温度,所以要多加一个判断。
代码如下:
def get_data(html_text):
final = []
bs = BeautifulSoup(html_text, "html.parser") # 创建BeautifulSoup对象
body = bs.body # 获取body部分
data = body.find('div', {'id': '7d'}) # 找到id为7d的div
ul = data.find('ul') # 获取ul部分
li = ul.find_all('li') # 获取所有的li
for day in li: # 对每个li标签中的内容进行遍历
temp = []
date = day.find('h1').string # 找到日期
temp.append(date) # 添加到temp中
inf = day.find_all('p') # 找到li中的所有p标签
temp.append(inf[0].string,) # 第一个p标签中的内容(天气状况)加到temp中
if inf[1].find('span') is None:
temperature_highest = None # 天气预报可能没有当天的最高气温(到了傍晚,就是这样),需要加个判断语句,来输出最低气温
else:
temperature_highest = inf[1].find('span').string # 找到最高温
temperature_highest = temperature_highest.replace('℃', '') # 到了晚上网站会变,最高温度后面也有个℃
temperature_lowest = inf[1].find('i').string # 找到最低温
temperature_lowest = temperature_lowest.replace('℃', '') # 最低温度后面有个℃,去掉这个符号
temp.append(temperature_highest) # 将最高温添加到temp中
temp.append(temperature_lowest) #将最低温添加到temp中
final.append(temp) #将temp加到final中
return final- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
写入文件csv:
将数据抓取出来后我们要将他们写入文件,具体代码如下:
def write_data(data, name):
file_name = name
with open(file_name, 'a', errors='ignore', newline='') as f:
f_csv = csv.writer(f)
f_csv.writerows(data)- 1
- 2
- 3
- 4
- 5
主函数:
if __name__ == '__main__':
url ='http://www.weather.com.cn/weather/101190401.shtml'
html = get_content(url)
result = get_data(html)
write_data(result, 'weather.csv')
- 1
- 2
- 3
- 4
- 5
- 6
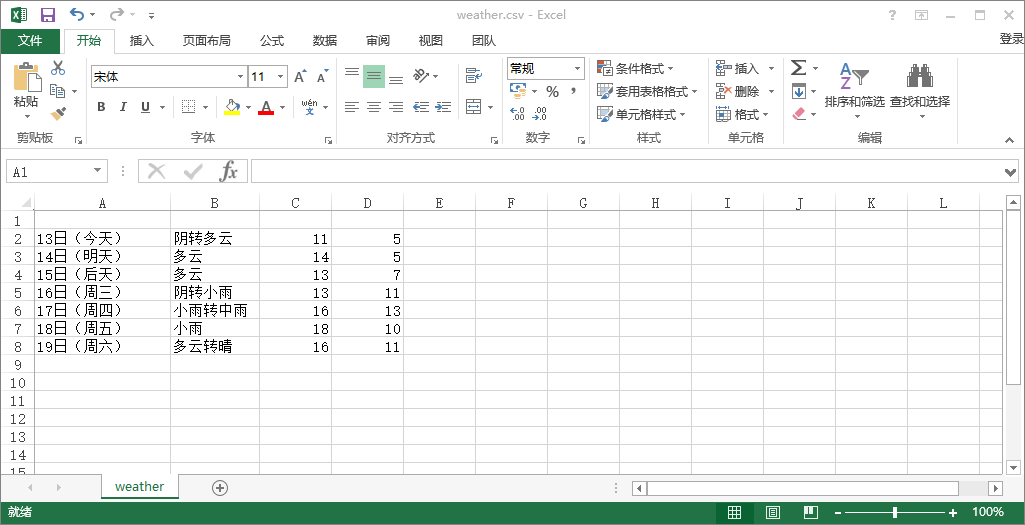
然后运行一下:
生成的weather.csv文件如下:
总结一下,从网页上抓取内容大致分3步:
1、模拟浏览器访问,获取html源代码
2、通过正则匹配,获取指定标签中的内容
3、将获取到的内容写到文件中
刚学python爬虫,可能有些理解有错误的地方,请大家批评指正,谢谢!
Python网络爬虫入门实战(爬取最近7天的天气以及最高/最低气温)的更多相关文章
- Python网络爬虫与如何爬取段子的项目实例
一.网络爬虫 Python爬虫开发工程师,从网站某一个页面(通常是首页)开始,读取网页的内容,找到在网页中的其它链接地址,然后通过这些链接地址寻找下一个网页,这样一直循环下去,直到把这个网站所有的网页 ...
- 精通python网络爬虫之自动爬取网页的爬虫 代码记录
items的编写 # -*- coding: utf-8 -*- # Define here the models for your scraped items # # See documentati ...
- 【Python网络爬虫三】 爬取网页新闻
学弟又一个自然语言处理的项目,需要在网上爬一些文章,然后进行分词,刚好牛客这周的是从一个html中找到正文,就实践了一下.写了一个爬门户网站新闻的程序 需求: 从门户网站爬取新闻,将新闻标题,作者,时 ...
- python网络爬虫之四简单爬取豆瓣图书项目
一.爬虫项目一: 豆瓣图书网站图书的爬取: import requests import re content = requests.get("https://book.douban.com ...
- Python 爬虫入门之爬取妹子图
Python 爬虫入门之爬取妹子图 来源:李英杰 链接: https://segmentfault.com/a/1190000015798452 听说你写代码没动力?本文就给你动力,爬取妹子图.如果 ...
- 爬虫入门之爬取策略 XPath与bs4实现(五)
爬虫入门之爬取策略 XPath与bs4实现(五) 在爬虫系统中,待抓取URL队列是很重要的一部分.待抓取URL队列中的URL以什么样的顺序排列也是一个很重要的问题,因为这涉及到先抓取那个页面,后抓取哪 ...
- python网络爬虫入门范例
python网络爬虫入门范例 Windows用户建议安装anaconda,因为有些套件难以安装. 安装使用pip install * 找出所有含有特定标签的HTML元素 找出含有特定CSS属性的元素 ...
- Python网络爬虫入门篇
1. 预备知识 学习者需要预先掌握Python的数字类型.字符串类型.分支.循环.函数.列表类型.字典类型.文件和第三方库使用等概念和编程方法. 2. Python爬虫基本流程 a. 发送请求 使用 ...
- 网络爬虫之scrapy爬取某招聘网手机APP发布信息
1 引言 过段时间要开始找新工作了,爬取一些岗位信息来分析一下吧.目前主流的招聘网站包括前程无忧.智联.BOSS直聘.拉勾等等.有段时间时间没爬取手机APP了,这次写一个爬虫爬取前程无忧手机APP岗位 ...
随机推荐
- 怎么把CAT客户端的RootMessageId记录到每条日志中?
什么是RootMessageId? 为了理解RootMessageId先简单介绍一下CAT的数据结构设计.CAT客户端会将所有消息都封装为一个完整的消息树(MessageTree),消息树可能包括Tr ...
- VS2017,遇到异常:这可能是由某个扩展导致的
网上看的解决办法没有解决,干脆自己亲自动手搞吧! 具体问题如下: 解决方案: 按照提示路径打开日志文件定位问题所在,打开之后,拉倒最后看到如下图所示: 我的问题是因为安装了一个叫 "Clau ...
- 力扣(LeetCode)三个数的最大乘积 个人题解
给定一个整型数组,在数组中找出由三个数组成的最大乘积,并输出这个乘积. 示例 1: 输入: [1,2,3] 输出: 6 示例 2: 输入: [1,2,3,4] 输出: 24 注意: 给定的整型数组长度 ...
- 自制反汇编逆向分析工具 与hopper逆向输出对比
经过一个阶段5次迭代之后,本逆向分析工具功能基本成形.工具的基本功能介绍请参看前面的posts. 现在就和hopper的逆向函数伪代码的功能对比一下效果.在这里并非定胜劣,因为差异可以拿来对比参照,通 ...
- mysql定时任务(event事件)
1.event事件 事件(event)是MySQL在相应的时刻调用的过程式数据库对象.一个事件可调用一次,也可周期性的启动,它由一个特定的线程来管理的,也就是所谓的“事件调度器” 事件和触发器类似,都 ...
- router-link传递参数
有个功能: 依据传入值,跳到产品详情页,但是详情页的内容依据传入值来相应变化. 如果使用点击事件@clic来实现,则有三个重复的跳转代码. 避免多次定义重复函数,可以使用router-link 传参数 ...
- Linux考题(一)
1.创建目录/data/oldboy,并且在该目录下创建oldboy.txt,然后在文件oldybos.txt里写入内容“inet addr:192.168.228.128 Bcast:192.16 ...
- day 38 高级选择器
1.高级选择器 一.高级选择器 1-后代选择器 ***** 儿子.孙子.重孙子 1. .father .wu{ color: red; } 选择父类中特定的子类 2. .father p{ #后代中间 ...
- Chrom谷歌浏览器没网之最全解决办法之一
一开始查找百度很多方法都不行,,第一次尝试.最有希望和看着像的是:1.win+r --> 输入regedit 打开注册表2.打开目录HKEY_CURRENT_USER\Software\Micr ...
- 基于ManagedDataAccess开发的OracleDBHelpe工具集伸手党的福音
在使用前先加入ManagedDataAccessDLL文件方可使用 添加方法:右键项目.点击管理NuGet程序包,点击浏览,在输入框内输入ManagedDataAccess,再点击安装即可 Oracl ...