Storm 系列(一)—— Storm和流处理简介
一、Storm
1.1 简介
Storm 是一个开源的分布式实时计算框架,可以以简单、可靠的方式进行大数据流的处理。通常用于实时分析,在线机器学习、持续计算、分布式 RPC、ETL 等场景。Storm 具有以下特点:
- 支持水平横向扩展;
- 具有高容错性,通过 ACK 机制每个消息都不丢失;
- 处理速度非常快,每个节点每秒能处理超过一百万个 tuples ;
- 易于设置和操作,并可以与任何编程语言一起使用;
- 支持本地模式运行,对于开发人员来说非常友好;
- 支持图形化管理界面。
1.2 Storm 与 Hadoop对比
Hadoop 采用 MapReduce 处理数据,而 MapReduce 主要是对数据进行批处理,这使得 Hadoop 更适合于海量数据离线处理的场景。而 Strom 的设计目标是对数据进行实时计算,这使得其更适合实时数据分析的场景。
1.3 Storm 与 Spark Streaming对比
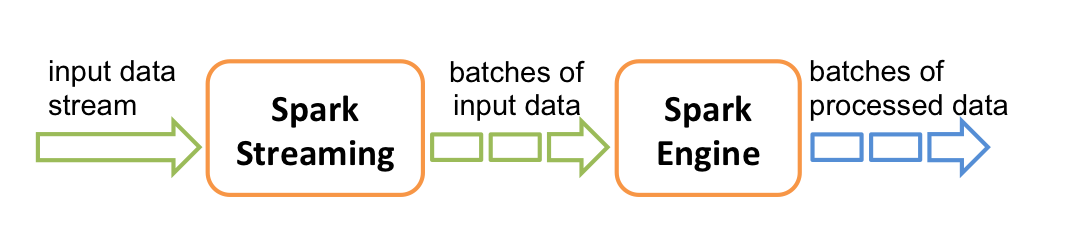
Spark Streaming 并不是真正意义上的流处理框架。 Spark Streaming 接收实时输入的数据流,并将数据拆分为一系列批次,然后进行微批处理。只不过 Spark Streaming 能够将数据流进行极小粒度的拆分,使得其能够得到接近于流处理的效果,但其本质上还是批处理(或微批处理)。
1.4 Strom 与 Flink对比
storm 和 Flink 都是真正意义上的实时计算框架。其对比如下:
| storm | flink | |
|---|---|---|
| 状态管理 | 无状态 | 有状态 |
| 窗口支持 | 对事件窗口支持较弱,缓存整个窗口的所有数据,窗口结束时一起计算 | 窗口支持较为完善,自带一些窗口聚合方法, 并且会自动管理窗口状态 |
| 消息投递 | At Most Once At Least Once |
At Most Once At Least Once Exactly Once |
| 容错方式 | ACK 机制:对每个消息进行全链路跟踪,失败或者超时时候进行重发 | 检查点机制:通过分布式一致性快照机制, 对数据流和算子状态进行保存。在发生错误时,使系统能够进行回滚。 |
注 : 对于消息投递,一般有以下三种方案:
- At Most Once : 保证每个消息会被投递 0 次或者 1 次,在这种机制下消息很有可能会丢失;
- At Least Once : 保证了每个消息会被默认投递多次,至少保证有一次被成功接收,信息可能有重复,但是不会丢失;
- Exactly Once : 每个消息对于接收者而言正好被接收一次,保证即不会丢失也不会重复。
二、流处理
2.1 静态数据处理
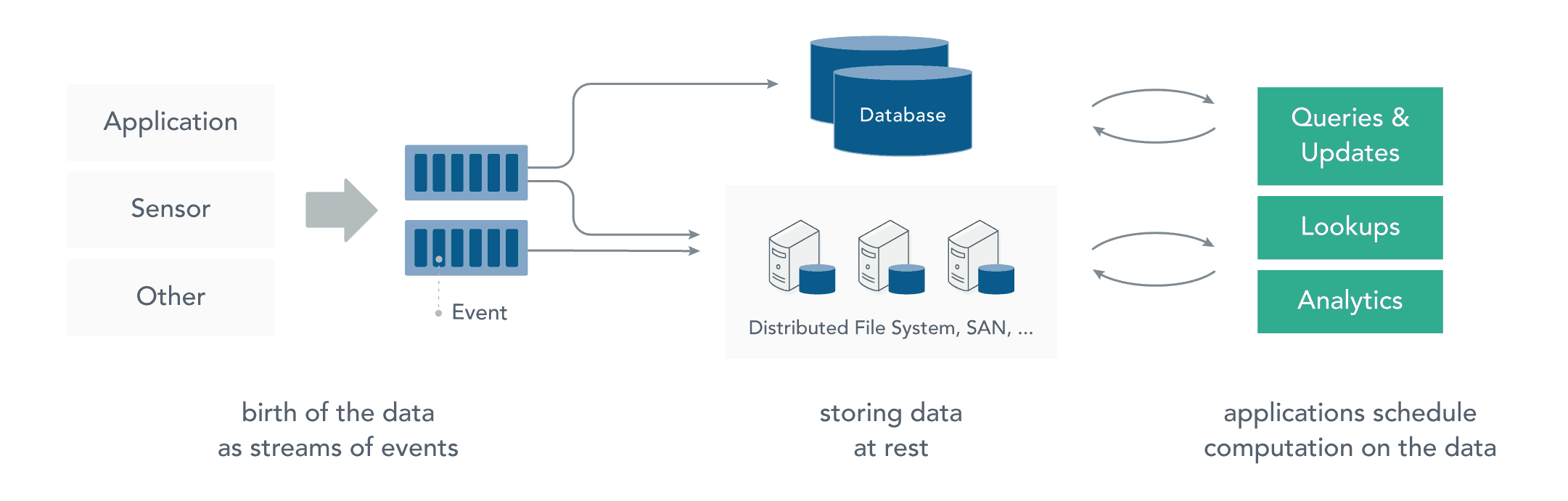
在流处理之前,数据通常存储在数据库或文件系统中,应用程序根据需要查询或计算数据,这就是传统的静态数据处理架构。Hadoop 采用 HDFS 进行数据存储,采用 MapReduce 进行数据查询或分析,这就是典型的静态数据处理架构。
2.2 流处理
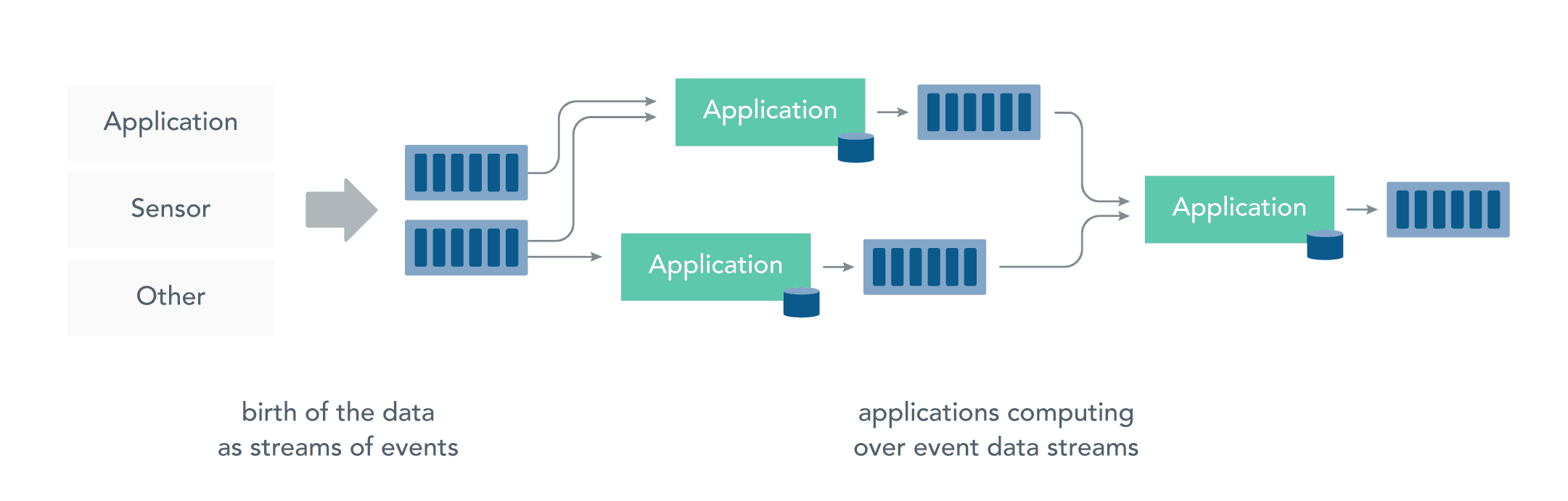
而流处理则是直接对运动中数据的处理,在接收数据的同时直接计算数据。实际上,在真实世界中的大多数数据都是连续的流,如传感器数据,网站用户活动数据,金融交易数据等等 ,所有这些数据都是随着时间的推移而源源不断地产生。
接收和发送数据流并执行应用程序或分析逻辑的系统称为流处理器。流处理器的基本职责是确保数据有效流动,同时具备可扩展性和容错能力,Storm 和 Flink 就是其代表性的实现。
流处理带来了很多优点:
可以立即对数据做出反应:降低了数据的滞后性,使得数据更具有时效性,更能反映对未来的预期;
可以处理更大的数据量:直接处理数据流,并且只保留数据中有意义的子集,然后将其传送到下一个处理单元,通过逐级过滤数据,从而降低实际需要处理的数据量;
更贴近现实的数据模型:在实际的环境中,一切数据都是持续变化的,想要通过历史数据推断未来的趋势,必须保证数据的不断输入和模型的持续修正,典型的就是金融市场、股票市场,流处理能更好地处理这些场景下对数据连续性和及时性的需求;
分散和分离基础设施:流式处理减少了对大型数据库的需求。每个流处理程序通过流处理框架维护了自己的数据和状态,这使其更适合于当下最流行的微服务架构。
参考资料
更多大数据系列文章可以参见 GitHub 开源项目: 大数据入门指南
Storm 系列(一)—— Storm和流处理简介的更多相关文章
- Storm系列一: Storm初步
初入Storm 前言 学习Storm已经有两周左右的时间,但是认真来说学习过程确实是零零散散,遇到问题去百度一下,找到新概念再次学习,在这样的一个循环又不成体系的过程中不断学习Storm. 前人栽树, ...
- Storm系列之一——Storm Topology并发
1.是什么构成一个可运行的topology? worker processes(worker进程),executors(线程)和tasks. 一台Storm集群里面的机器可能运行一个或多个worker ...
- Storm概念学习系列之Stream消息流 和 Stream Grouping 消息流组
不多说,直接上干货! Stream消息流是Storm中最关键的抽象,是一个没有边界的Tuple序列. Stream Grouping 消息流组是用来定义一个流如何分配到Tuple到Bolt. Stre ...
- Storm 系列(二)实时平台介绍
Storm 系列(二)实时平台介绍 本章中的实时平台是指针对大数据进行实时分析的一整套系统,包括数据的收集.处理.存储等.一般而言,大数据有 4 个特点: Volumn(大量). Velocity(高 ...
- Storm 系列(五)—— Storm 编程模型详解
一.简介 下图为 Strom 的运行流程图,在开发 Storm 流处理程序时,我们需要采用内置或自定义实现 spout(数据源) 和 bolt(处理单元),并通过 TopologyBuilder 将它 ...
- Storm:最火的流式处理框架
伴随着信息科技日新月异的发展,信息呈现出爆发式的膨胀,人们获取信息的途径也更加多样.更加便捷,同时对于信息的时效性要求也越来越高.举个搜索场景中的例子,当一个卖家发布了一条宝贝信息时,他希望的当然是这 ...
- Storm 系列(一)基本概念
Storm 系列(一)基本概念 Apache Storm(http://storm.apache.org/)是由 Twitter 开源的分布式实时计算系统. Storm 可以非常容易并且可靠地处理无限 ...
- Storm系列三: Storm消息可靠性保障
Storm系列三: Storm消息可靠性保障 在上一篇 Storm系列二: Storm拓扑设计 中我们已经设计了一个稍微复杂一点的拓扑. 而本篇就是在上一篇的基础上再做出一定的调整. 在这里先大概提一 ...
- Storm系列二: Storm拓扑设计
Storm系列二: Storm拓扑设计 在本篇中,我们就来根据一个案例,看看如何去设计一个拓扑, 如何分解问题以适应Storm架构,同时对Storm拓扑内部的并行机制会有一个基本的了解. 本章代码都在 ...
- Storm编程入门API系列之Storm的Topology的stream grouping
概念,见博客 Storm概念学习系列之stream grouping(流分组) Storm的stream grouping的Shuffle Grouping 它是随机分组,随机派发stream里面的t ...
随机推荐
- scrapy框架与python爬虫
- linux学习总结--linux100day(day2)
Linux中的哲学--一切皆文件 为了便于操作,我们可以使用secureCRT或Xshell连接到我们的虚拟机. 要用远程工具连接到虚拟机上,我们只需要打开虚拟机上的ssh服务,在xshell中填写主 ...
- intellIJ IDEA学习笔记2
常用的有fori/sout/psvm+Tab即可生成循环.System.out.main方法等boilerplate样板代码 例如要输入for(User user : users)只需输入user.f ...
- TP5使用API时不可预知的内部异常
最常见的错误形式例如 controller不存在或者 action不存在之类的 我们第一时间想到的 就是 使用 try{}catch(){} 来捕获 例如: /** * show方法在common里定 ...
- map redcue filter sorted函数
sorted 函数 接收一个key函数来实现自定义的排序 # 训练集和验证集的文件命名不一样 # test1: data/test1/8973.jpg # train: data/train/cat. ...
- Linux 中如何查询端口被占用的情况
Linux如何查看端口 1.lsof -i:端口号 用于查看某一端口的占用情况,比如查看8000端口使用情况,lsof -i:8000,如下图 可以看到8000端口已经被轻量级文件系统转发服务lwfs ...
- 如何使用python records 库优雅的操作数据库
今天要介绍的这个python第三方库非常厉害,完美操作各种数据库.名字叫 records, 在网上很少有这个库的相关资料,但是在开源社区可是很火热的哦.如果这还不能打消你的顾虑,再告诉你一件事:如果你 ...
- ajax后台处理响应(java)
public static final void sendAsJson(HttpServletResponse response, String str) { response.setContentT ...
- (四十八)c#Winform自定义控件-下拉按钮
前提 入行已经7,8年了,一直想做一套漂亮点的自定义控件,于是就有了本系列文章. GitHub:https://github.com/kwwwvagaa/NetWinformControl 码云:ht ...
- C#简单爬取数据(.NET使用HTML解析器ESoup和正则两种方式匹配数据)
一.获取数据 想弄一个数据库,由于需要一些人名,所以就去百度一下,然后发现了360图书馆中有很多人名 然后就像去复制一下,发现复制不了,需要登陆 此时f12查看源码是可以复制的,不过就算可以复制想要插 ...