Paper | Residual Dense Network for Image Super-Resolution
发表在2018年CVPR。
摘要和结论都在强调方法的优势。我们还是先从RDN的结构看起,再理解它的背景和思想。
Residual dense block & network
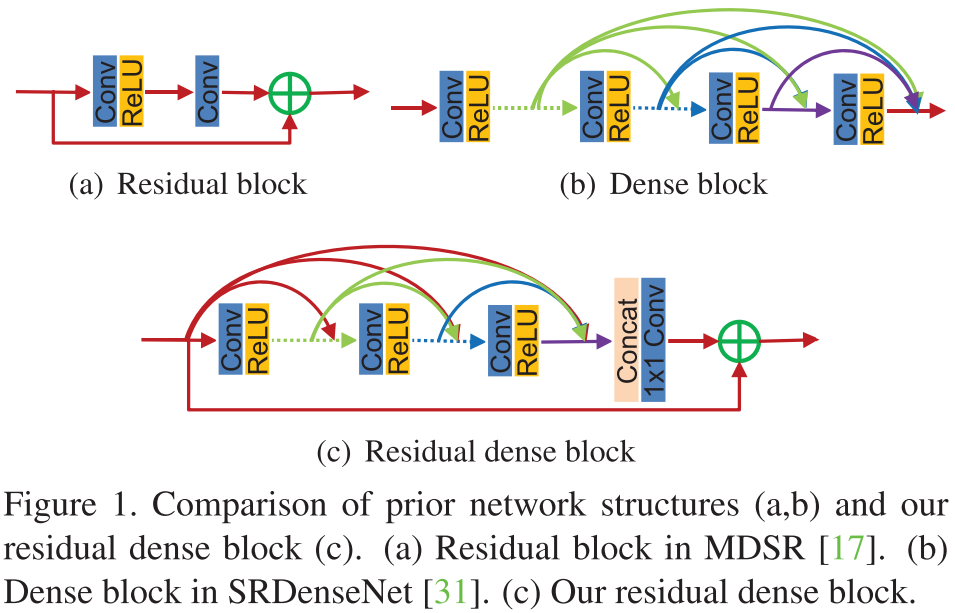
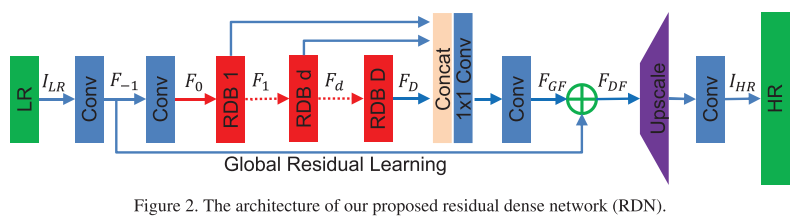
乍一看,这种block结构就是在内部采用了稠密连接,在外部采用残差学习。并且,RDN在全局上也是类似的设计:内部稠密,整体残差。无论是RDB还是RDN,内部都同时采用了\(3 \times 3\)和\(1 \times 1\)卷积。
我们来看看作者怎么解释这种设计的合理性,以及实验是否验证了其有效性。
和DenseNet的不同
在RDN和RDB中,我们取消了BN和池化层,因为作者认为它们不仅消耗资源,而且阻碍了网络学习(批注:在一些去噪工作中,有些作者也发现了BN无益于除高斯噪声以外的噪声去除)。
在DenseNet中,不同的block之间需要过渡层,但在这里采用\(1 \times 1\)卷积,即所谓的local feature fusion。(批注:本质是一样的,只不过过渡层多了BN和池化层,因为需要服务于高层视觉任务——图像分类)
全局和局部都有残差学习,而DenseNet中没有。这种局部残差连接,使得上一个RDB的输出,可以直接联系至当前RDB的输出结果。这就是作者所谓的contiguous memory(CM)。
算了,看完解释,我已经不想看实验了,因为还是比较trick的(没有太多能让人high的思想点,解释有点勉强)。我们回头看看摘要和结论吧。
摘要和结论
摘要
A very deep convolutional neural network (CNN) has recently achieved great success for image super-resolution (SR) and offered hierarchical features as well. However, most deep CNN based SR models do not make full use of the hierarchical features from the original low-resolution (LR) images, thereby achieving relatively-low performance. In this paper, we propose a novel residual dense network (RDN) to address this problem in image SR. We fully exploit the hierarchical features from all the convolutional layers. Specifically, we propose residual dense block (RDB) to extract abundant local features via dense connected convolutional layers. RDB further allows direct connections from the state of preceding RDB to all the layers of current RDB, leading to a contiguous memory (CM) mechanism. Local feature fusion in RDB is then used to adaptively learn more effective features from preceding and current local features and stabilizes the training of wider network. After fully obtaining dense local features, we use global feature fusion to jointly and adaptively learn global hierarchical features in a holistic way. Experiments on benchmark datasets with different degradation models show that our RDN achieves favorable performance against state-of-the-art methods.
结论
In this paper, we proposed a very deep residual dense network (RDN) for image SR, where residual dense block (RDB) serves as the basic build module. In each RDB, the dense connections between each layers allow full usage of local layers. The local feature fusion (LFF) not only stabilizes the training wider network, but also adaptively controls the preservation of information from current and preceding RDBs. RDB further allows direct connections between the preceding RDB and each layer of current block, leading to a contiguous memory (CM) mechanism. The local residual leaning (LRL) further improves the flow of information and gradient. Moreover, we propose global feature fusion (GFF) to extract hierarchical features in the LR space. By fully using local and global features, our RDN leads to a dense feature fusion and deep supervision. We use the same RDN structure to handle three degradation models and real-world data. Extensive benchmark evaluations well demonstrate that our RDN achieves superiority over state-of-theart methods.
我来翻译一下:
在每个RDB内部,都有一个全局短连接;因此上一个RDB的输出,会直接送到当前RDB的输出端;这就是作者所谓的连续记忆(contiguous memory)机制。
每个RDB之间采用了\(1 \times 1\)卷积,作者将其称为local feature fusion;这不就是大家都在用的、降低通道数的方法嘛,有点故弄玄虚哦。作者还强调:该LFF可以稳定宽网络的训练。实际上,DenseNet为了降低计算量,特地让网络更窄。这是在增大冗余(增强泛化能力)和减小计算量之间的权衡,详情参见我的博客。
Paper | Residual Dense Network for Image Super-Resolution的更多相关文章
- Paper | Dynamic Residual Dense Network for Image Denoising
目录 1. 故事 2. 动机 3. 做法 3.1 DRDB 3.2 训练方法 4. 实验 发表于2019 Sensors.这篇文章的思想可能来源于2018 ECCV的SkipNet[11]. 没开源, ...
- ASRWGAN: Wasserstein Generative Adversarial Network for Audio Super Resolution
ASEGAN:WGAN音频超分辨率 这篇文章并不具有权威性,因为没有发表,说不定是外国的某个大学的毕业设计,或者课程结束后的作业.或者实验报告. CS230: Deep Learning, Sprin ...
- Paper | Residual Attention Network for Image Classification
目录 1. 相关工作 2. Residual Attention Network 2.1 Attention残差学习 2.2 自上而下和自下而上 2.3 正则化Attention 最近看了些关于att ...
- Speech Super Resolution Generative Adversarial Network
博客作者:凌逆战 博客地址:https://www.cnblogs.com/LXP-Never/p/10874993.html 论文作者:Sefik Emre Eskimez , Kazuhito K ...
- Residual Attention Network for Image Classification(CVPR 2017)详解
一.Residual Attention Network 简介 这是CVPR2017的一篇paper,是商汤.清华.香港中文和北邮合作的文章.它在图像分类问题上,首次成功将极深卷积神经网络与人类视觉注 ...
- Computer Vision Applied to Super Resolution
Capel, David, and Andrew Zisserman. "Computer vision applied to super resolution." Signal ...
- Super Resolution
Super Resolution Accepted : 121 Submit : 187 Time Limit : 1000 MS Memory Limit : 65536 KB Super ...
- Google Pixel 超分辨率--Super Resolution Zoom
Google Pixel 超分辨率--Super Resolution Zoom Google 的Super Res Zoom技术,主要用于在zoom时增强画面细节以及提升在夜景下的效果. 文章的主要 ...
- Paper | Multi-scale Dense Networks for Resource Efficient Image Classification
目录 故事背景 方法 两种加速策略 网络设计 网络优化 失败设计 回头品味 实验 数据集和数据处理 结果 第二次阅读 本文不是第一个提出early exit思想的 写作流畅 网络回顾 其他 发表在IC ...
随机推荐
- linux编程fcntl获取和设置文件锁
#include <stdio.h> #include <stdlib.h> #include <unistd.h> #include <sys/types. ...
- 第04组 Beta冲刺(2/5)
队名:new game 组长博客 作业博客 组员情况 鲍子涵(队长) 过去两天完成了哪些任务 验收游戏素材 学习Unity 2D Animation系统 基本做完了人物的各个动画 接下来的计划 冲击E ...
- 向github中已创建好的repository提交文件
git init git remote add origin git@github.com:taishan1994/learn_django.git git pull origin master gi ...
- 解决 canvas 下载含图片的画布时的报错
Uncaught DOMException: Failed to execute 'toDataURL' on 'HTMLCanvasElement': Tainted canvases may no ...
- Java中的ThreadLocal
关于 ThreadLocal,我们经常用它来解决多线程并发问题,那它究竟是如何做到的?今天就让我们来好好看一下. 从源码入手 首先,让我们看看 ThreadLocal 类中的介绍: This clas ...
- Z从壹开始前后端分离【 .NET Core2.0/3.0 +Vue2.0 】框架之十 || AOP面向切面编程浅解析:简单日志记录 + 服务切面缓存
本文梯子 本文3.0版本文章 代码已上传Github+Gitee,文末有地址 大神反馈: 零.今天完成的深红色部分 一.AOP 之 实现日志记录(服务层) 1.定义服务接口与实现类 2.在API层中添 ...
- VUE组内培训
最近去参加了一个外部VUE的周末培训,加上自己比较感兴趣所以对这项很热的前端框架做了点学习,顺便给组内同事做个简单的分享,希望下次有项目可以使用上- VUE的语法教程网上很多我就不一一列举,截图放一下 ...
- kali linux maltego-情报收集工具
Maltego是一个交互式数据挖掘工具,它为链接分析呈现有向图.该工具用于在线调查,以发现互联网上各种来源的信息片段之间的关系. 注册Maltego账号,注册地址:https://www.paterv ...
- jQuery-File-Upload $(...).fileupload is not a function $.widget is not a function
使用 jQuery-File-Upload 库的时候碰到了 $(...).fileupload is not a function 和 $.widget is not a function 问题. ...
- 论文学习-混沌系统以及机器学习模型-11-29-wlg
混沌系统以及机器学习模型 概述: 必要条件下: negative values of the sub-Lyapunov exponents. 通过rc方法, 可以在参数不匹配的情况下,实现输入信号,混 ...