一文告诉你,Kafka在性能优化方面做了哪些举措!
很多粉丝私信问我Kafka在性能优化方面做了哪些举措,对于相关问题的答案其实我早就写过了,就是没有系统的整理一篇,最近思考着花点时间来整理一下,下次再有粉丝问我相关的问题我就可以潇洒的甩个链接了。这个问题也是Kafka面试的时候的常见问题,面试官问你这个问题也不算刁难你。在网上也有很多相关的文章开讲解这个问题,比如之前各大公众号转载的“为什么Kafka这么快?”,这些文章我看了,写的不错,问题在于只是罗列了部分的要领,没有全部的详述出来。本文所罗列的要领会比你们网上搜寻到的都多,如果你在看完本篇文章之后,在面试的时候遇到相关问题,相信你一定能让面试官眼前一亮。
批量处理
传统消息中间件的消息发送和消费整体上是针对单条的。对于生产者而言,它先发一条消息,然后broker返回ACK表示已接收,这里产生2次rpc;对于消费者而言,它先请求接受消息,然后broker返回消息,最后发送ACK表示已消费,这里产生了3次rpc(有些消息中间件会优化一下,broker返回的时候返回多条消息)。而Kafka采用了批量处理:生产者聚合了一批消息,然后再做2次rpc将消息存入broker,这原本是需要很多次的rpc才能完成的操作。假设需要发送1000条消息,每条消息大小1KB,那么传统的消息中间件需要2000次rpc,而Kafka可能会把这1000条消息包装成1个1MB的消息,采用2次rpc就完成了任务。这一改进举措一度被认为是一种“作弊”的行为,然而在微批次理念盛行的今日,其它消息中间件也开始纷纷效仿。
客户端优化
这里接着批量处理的概念继续来说,新版生产者客户端摒弃了以往的单线程,而采用了双线程:主线程和Sender线程。主线程负责将消息置入客户端缓存,Sender线程负责从缓存中发送消息,而这个缓存会聚合多个消息为一个批次。有些消息中间件会把消息直接扔到broker。
日志格式
Kafka从0.8版本开始日志格式历经了三次变革:v0、v1、v2,Kafka的日志格式越来越利于批量消息的处理。
日志编码
如果了解了Kafka具体的日志格式(可以参考上图),那么你应该了解日志(Record,或者称之为消息)本身除了基本的key和value之外,还有一些其它的字段,原本这些附加字段按照固定的大小占用一定的篇幅(参考上图左),而Kafka最新的版本中采用了变成字段Varints和ZigZag编码,有效地降低了这些附加字段的占用大小。日志(消息)尽可能变小了,那么网络传输的效率也会变高,日志存盘的效率也会提升,从而整理的性能也会有所提升。
消息压缩
Kafka支持多种消息压缩方式(gzip、snappy、lz4)。对消息进行压缩可以极大地减少网络传输 量、降低网络 I/O,从而提高整体的性能。消息压缩是一种使用时间换空间的优化方式,如果对 时延有一定的要求,则不推荐对消息进行压缩。
建立索引,方便快速定位查询
每个日志分段文件对应了两个索引文件,主要用来提高查找消息的效率,这也是提升性能的一种方式。(具体的内容在书中的第5章有详细的讲解,公众号里好像忘记发表了,找了一圈没找到)
分区
很多人会忽略掉这个因素,其实分区也是提升性能的一种非常有效的方式,这种方式所带来的效果会比前面所说的日志编码、消息压缩等更加的明显。分区在其他分布式组件中也有大量涉及,至于为什么分区能够提升性能这种基本知识在这里就不在赘述了。不过需要注意,一昧地增加分区并不能一直带来性能的提升。
一致性
绝大多数的资料在讲述Kafka性能优化的举措之时是不会提及一致性的东西的。我们所了解的通用的一致性协议如Paxos、Raft、Gossip等,而Kafka另辟蹊径采用类似PacificA的做法不是“拍大腿”拍出来的,采用这种模型会提升整理的效率。具体的细节后面会整理一篇,类似《在Kafka中使用Raft替换PacificA的可行性分析及优缺点》。
顺序写盘
操作系统可以针对线性读写做深层次的优化,比如预读(read-ahead,提前将一个比较大的磁盘块读入内存) 和后写(write-behind,将很多小的逻辑写操作合并起来组成一个大的物理写操作)技术。Kafka 在设计时采用了文件追加的方式来写入消息,即只能在日志文件的尾部追加新的消 息,并且也不允许修改已写入的消息,这种方式属于典型的顺序写盘的操作,所以就算 Kafka 使用磁盘作为存储介质,它所能承载的吞吐量也不容小觑。
页缓存
为什么Kafka性能这么高?当遇到这个问题的时候很多人都会想到上面的顺序写盘这一点。其实在顺序斜盘前面还有页缓存(PageCache)这一层的优化。
页缓存是操作系统实现的一种主要的磁盘缓存,以此用来减少对磁盘 I/O 的操作。具体 来说,就是把磁盘中的数据缓存到内存中,把对磁盘的访问变为对内存的访问。为了弥补性 能上的差异,现代操作系统越来越“激进地”将内存作为磁盘缓存,甚至会非常乐意将所有 可用的内存用作磁盘缓存,这样当内存回收时也几乎没有性能损失,所有对于磁盘的读写也 将经由统一的缓存。
当一个进程准备读取磁盘上的文件内容时,操作系统会先查看待读取的数据所在的页 (page)是否在页缓存(pagecache)中,如果存在(命中)则直接返回数据,从而避免了对物 理磁盘的 I/O 操作;如果没有命中,则操作系统会向磁盘发起读取请求并将读取的数据页存入 页缓存,之后再将数据返回给进程。同样,如果一个进程需要将数据写入磁盘,那么操作系统也会检测数据对应的页是否在页缓存中,如果不存在,则会先在页缓存中添加相应的页,最后将数据写入对应的页。被修改过后的页也就变成了脏页,操作系统会在合适的时间把脏页中的 数据写入磁盘,以保持数据的一致性。
对一个进程而言,它会在进程内部缓存处理所需的数据,然而这些数据有可能还缓存在操 作系统的页缓存中,因此同一份数据有可能被缓存了两次。并且,除非使用 Direct I/O 的方式, 否则页缓存很难被禁止。此外,用过 Java 的人一般都知道两点事实:对象的内存开销非常大, 通常会是真实数据大小的几倍甚至更多,空间使用率低下;Java 的垃圾回收会随着堆内数据的 增多而变得越来越慢。基于这些因素,使用文件系统并依赖于页缓存的做法明显要优于维护一 个进程内缓存或其他结构,至少我们可以省去了一份进程内部的缓存消耗,同时还可以通过结构紧凑的字节码来替代使用对象的方式以节省更多的空间。如此,我们可以在 32GB 的机器上使用 28GB 至 30GB 的内存而不用担心 GC 所带来的性能问题。此外,即使 Kafka 服务重启, 页缓存还是会保持有效,然而进程内的缓存却需要重建。这样也极大地简化了代码逻辑,因为 维护页缓存和文件之间的一致性交由操作系统来负责,这样会比进程内维护更加安全有效。
Kafka 中大量使用了页缓存,这是 Kafka 实现高吞吐的重要因素之一。虽然消息都是先被写入页缓存,然后由操作系统负责具体的刷盘任务的。
零拷贝
Kafka使用了Zero Copy技术提升了消费的效率。前面所说的Kafka将消息先写入页缓存,如果消费者在读取消息的时候如果在页缓存中可以命中,那么可以直接从页缓存中读取,这样又节省了一次从磁盘到页缓存的copy开销。另外对于读写的概念可以进一步了解一下什么是写放大和读放大。
附
一个磁盘IO流程可以参考下图:
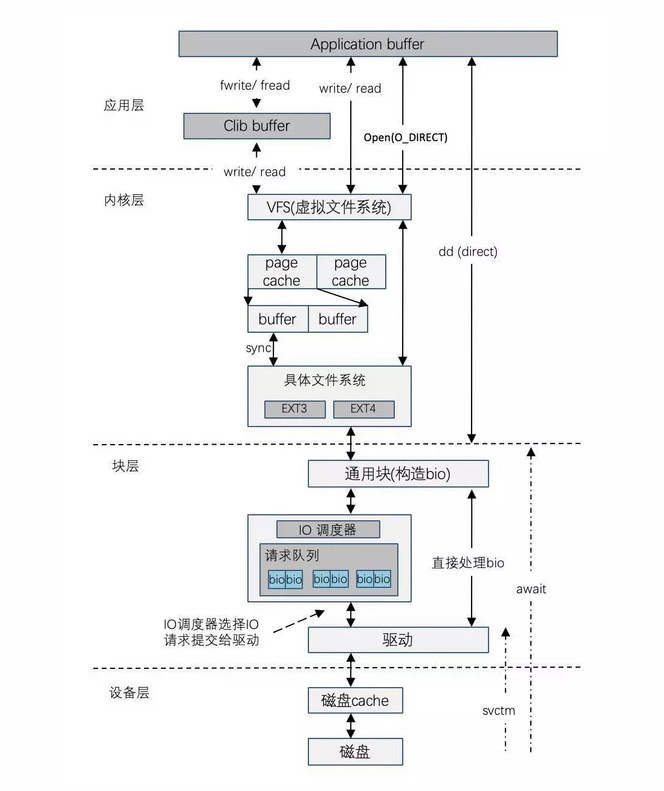
注:文章转载自网络,如果您觉得本文对您有帮助,欢迎关注我的公众号【Java技术zhai】,有新文章发布会第一时间通知您。
一文告诉你,Kafka在性能优化方面做了哪些举措!的更多相关文章
- JS JavaScript中的文档碎片 DocumentFragement JS性能优化
文档碎片是什么: 如果我们要在一个ul中添加100个li,如果不使用文档碎片,那么我们就需要使用append经常100次的追加,这会导致浏览器一直不停的渲染,是非常消耗资源的.但是如果我们使用文档碎片 ...
- Kafka生产者性能优化之吞吐量VS延迟
When we are talking about performance of Kafka Producer, we are really talking about two different t ...
- 1002-谈谈ELK日志分析平台的性能优化理念
在生产环境中,我们为了更好的服务于业务,通常会通过优化的手段来实现服务对外的性能最大化,节省系统性能开支:关注我的朋友们都知道,前段时间一直在搞ELK,同时也记录在了个人的博客篇章中,从部署到各个服务 ...
- 浅谈webpack4.0 性能优化(转)
前言:在现实项目中,我们可能很少需要从头开始去配置一个webpack 项目,特别是webpack4.0发布以后,零配置启动一个项目成为一种标配.正因为零配置的webpack对项目本身提供的“打包”和“ ...
- CSS性能优化的8个技巧
本文作者:高峰,360奇舞团前端工程师,W3C性能工作组成员,同时参与WOT工作组的学习. 我们都知道对于网站来说,性能至关重要,CSS作为页面渲染和内容展现的重要环节,影响着用户对整个网站的第一体验 ...
- React性能优化总结
本文主要对在React应用中可以采用的一些性能优化方式做一下总结整理 前言 目的 目前在工作中,大量的项目都是使用react来进行开展的,了解掌握下react的性能优化对项目的体验和可维护性都有很大的 ...
- 复杂TableView在iOS上的性能优化
声明:本文翻译自<iOS performance optimization>,原文作者 Khang Vo.翻译本文纯属为了技术交流的目的,并不具有任何的商业性质,也不得利用本文内容进行商业 ...
- iOS 程序性能优化
前言 转载自:http://www.samirchen.com/ios-performance-optimization/ 程序性能优化不应该是一件放在功能完成之后的事,对性能的概念应该从我们一开始写 ...
- vuejs项目性能优化总结
在使用elementUI构建公司管理系统时,发现首屏加载时间长,加载的网络资源比较多,对系统的体验性会差一点,而且用webpack打包的vuejs的vendor包会比较大.所以通过搜集网上所有对于vu ...
随机推荐
- pytest系列(二):筛选用例新姿势,mark 一下,你就知道。
pytest系列(一)中给大家介绍了pytest的特性,以及它的编写用例的简单至极. 那么在实际工作当中呢,我们要写的自动化用例会比较多,不会都放在一个py文件里. 如下图所示,我们编写的用例存放在不 ...
- Vue小练习 03
""" 1.有以下广告数据(实际数据命名可以略做调整) ad_data = { tv: [ {img: 'img/tv/tv1.jpg', title: 'tv1'}, ...
- win7安装centos7虚拟机
1. 场景描述 因测试中需要linux集群,目前的服务器不太方便部署,需要本机(windows7)启动多个linux虚拟机,记录下,希望能帮到需要的朋友. 2. 解决方案 2.1 软件准备 (1)使用 ...
- thinkphp5.0学习笔记
2019-11-11学习笔记 安装TP5.0 a)源代码包下载 在thinkphp官网下载(www.thinkphp.cn)下载 完整版本的TP5.0 b) composer 安装 切换到网站的根目录 ...
- ETCD:HTTP JSON API通过gRPC网关
原文地址:HTTP JSON API through the gRPC gateway etcd v3 使用 gRPC 作为消息协议.etcd项目包括一个基于gRPC的Go客户端和一个命令行工具,et ...
- HttpModules配置事项
前沿:还是那句话 ASP.NET管道,浏览器 - isAPI32.dll - HttpModules - HttpHandler - 返回客户端Web.Config:<httpModules&g ...
- .NET多线程知识快速学习
多线程是一个不会过时的话题,因为每个开发的成长必然要掌握这个知识点,否则半懂不懂怎么保证系统的可靠性和性能,其实在网上随便一搜都会有海量的文章说这个话题,大多数写得很细写得非常好,但发现很少有概览性的 ...
- SSM框架中mapper和mapping.xml文件在同一个包下需要的配置
前言 当我们在开发过程中,由于maven项目本身的限制,我们不能直接把我们的mapper.xml文件和对应mapper.java接口文件放到一起,也就是不能直接放在java包中,如图: 因为mave ...
- 多个div使用display:inline-block时候div之间有间隔
开发场景中用到display:inline-block;然后呢,div间就有间隙,但是ajax加载出来的数据没有间隙,解决办法如下 display:inline-block表示行内块元素,后面自带 ...
- Html table 内容超出显示省略号
内容超出显示省略号: <html> <style> table { table-layout: fixed; width: 100%; } table, th, td { bo ...