机器学习经典算法之EM
一、简介
EM 的英文是 Expectation Maximization,所以 EM 算法也叫最大期望算法。
我们先看一个简单的场景:假设你炒了一份菜,想要把它平均分到两个碟子里,该怎么分?
很少有人用称对菜进行称重,再计算一半的分量进行平分。大部分人的方法是先分一部分到碟子 A 中,然后再把剩余的分到碟子 B 中,再来观察碟子 A 和 B 里的菜是否一样多,哪个多就匀一些到少的那个碟子里,然后再观察碟子 A 和 B 里的是否一样多……整个过程一直重复下去,直到份量不发生变化为止。
你能从这个例子中看到三个主要的步骤:初始化参数、观察预期、重新估计。首先是先给每个碟子初始化一些菜量,然后再观察预期,这两个步骤实际上就是期望步骤(Expectation)。如果结果存在偏差就需要重新估计参数,这个就是最大化步骤(Maximization)。这两个步骤加起来也就是 EM 算法的过程。
/*请尊重作者劳动成果,转载请标明原文链接:*/
/* https://www.cnblogs.com/jpcflyer/p/11143638.html * /
二、EM 算法的工作原理
说到 EM 算法,我们先来看一个概念“最大似然”,英文是 Maximum Likelihood,Likelihood 代表可能性,所以最大似然也就是最大可能性的意思。
什么是最大似然呢?举个例子,有一男一女两个同学,现在要对他俩进行身高的比较,谁会更高呢?根据我们的经验,相同年龄下男性的平均身高比女性的高一些,所以男同学高的可能性会很大。这里运用的就是最大似然的概念。
最大似然估计是什么呢?它指的就是一件事情已经发生了,然后反推更有可能是什么因素造成的。还是用一男一女比较身高为例,假设有一个人比另一个人高,反推他可能是男性。最大似然估计是一种通过已知结果,估计参数的方法。
那么 EM 算法是什么?它和最大似然估计又有什么关系呢?EM 算法是一种求解最大似然估计的方法,通过观测样本,来找出样本的模型参数。
再回过来看下开头我给你举的分菜的这个例子,实际上最终我们想要的是碟子 A 和碟子 B 中菜的份量,你可以把它们理解为想要求得的 模型参数 。然后我们通过 EM 算法中的 E 步来进行观察,然后通过 M 步来进行调整 A 和 B 的参数,最后让碟子 A 和碟子 B 的参数不再发生变化为止。
实际我们遇到的问题,比分菜复杂。我再给你举个一个投掷硬币的例子,假设我们有 A 和 B 两枚硬币,我们做了 5 组实验,每组实验投掷 10 次,然后统计出现正面的次数,实验结果如下:
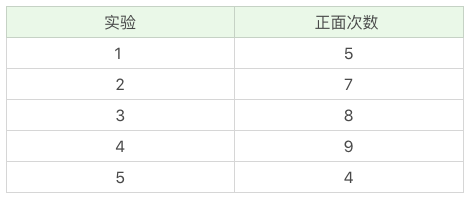
投掷硬币这个过程中存在隐含的数据,即我们事先并不知道每次投掷的硬币是 A 还是 B。假设我们知道这个隐含的数据,并将它完善,可以得到下面的结果:
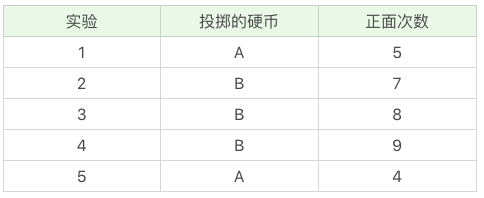
我们现在想要求得硬币 A 和 B 出现正面次数的概率,可以直接求得:
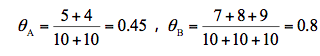
而实际情况是我不知道每次投掷的硬币是 A 还是 B,那么如何求得硬币 A 和硬币 B 出现正面的概率呢?
这里就需要采用 EM 算法的思想。
1. 初始化参数。我们假设硬币 A 和 B 的正面概率(随机指定)是θA=0.5 和θB=0.9。
2. 计算期望值。假设实验 1 投掷的是硬币 A,那么正面次数为 5 的概率为:
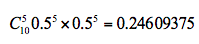
公式中的 C(10,5) 代表的是 10 个里面取 5 个的组合方式,也就是排列组合公式,0.5 的 5 次方乘以 0.5 的 5 次方代表的是其中一次为 5 次为正面,5 次为反面的概率,然后再乘以 C(10,5) 等于正面次数为 5 的概率。
假设实验 1 是投掷的硬币 B ,那么正面次数为 5 的概率为:
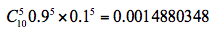
所以实验 1 更有可能投掷的是硬币 A。
然后我们对实验 2~5 重复上面的计算过程,可以推理出来硬币顺序应该是{A,A,B,B,A}。
这个过程实际上是通过假设的参数来估计未知参数,即“每次投掷是哪枚硬币”。
3. 通过猜测的结果{A, A, B, B, A}来完善初始化的参数θA 和θB。
然后一直重复第二步和第三步,直到参数不再发生变化。
简单总结下上面的步骤,你能看出 EM 算法中的 E 步骤就是通过旧的参数来计算隐藏变量。然后在 M 步骤中,通过得到的隐藏变量的结果来重新估计参数。直到参数不再发生变化,得到我们想要的结果。
EM 聚类的工作原理
上面你能看到 EM 算法最直接的应用就是求参数估计。如果我们把潜在类别当做隐藏变量,样本看做观察值,就可以把聚类问题转化为参数估计问题。这也就是 EM 聚类的原理。
相比于 K-Means 算法,EM 聚类更加灵活,比如下面这两种情况,K-Means 会得到下面的聚类结果。

因为 K-Means 是通过距离来区分样本之间的差别的,且每个样本在计算的时候只能属于一个分类,称之为是硬聚类算法。而 EM 聚类在求解的过程中,实际上每个样本都有一定的概率和每个聚类相关,叫做软聚类算法。
你可以把 EM 算法理解成为是一个框架,在这个框架中可以采用不同的模型来用 EM 进行求解。常用的 EM 聚类有 GMM 高斯混合模型和 HMM 隐马尔科夫模型。GMM(高斯混合模型)聚类就是 EM 聚类的一种。比如上面这两个图,可以采用 GMM 来进行聚类。
和 K-Means 一样,我们事先知道聚类的个数,但是不知道每个样本分别属于哪一类。通常,我们可以假设样本是符合高斯分布的(也就是正态分布)。每个高斯分布都属于这个模型的组成部分(component),要分成 K 类就相当于是 K 个组成部分。这样我们可以先初始化每个组成部分的高斯分布的参数,然后再看来每个样本是属于哪个组成部分。这也就是 E 步骤。
再通过得到的这些隐含变量结果,反过来求每个组成部分高斯分布的参数,即 M 步骤。反复 EM 步骤,直到每个组成部分的高斯分布参数不变为止。
这样也就相当于将样本按照 GMM 模型进行了 EM 聚类。

三、 如何使用 EM 工具包
在 Python 中有第三方的 EM 算法工具包。由于 EM 算法是一个聚类框架,所以你需要明确你要用的具体算法,比如是采用 GMM 高斯混合模型,还是 HMM 隐马尔科夫模型。
我们主要讲解 GMM 的使用,在使用前你需要引入工具包:
- from sklearn.mixture import GaussianMixture
我们看下如何在 sklearn 中创建 GMM 聚类。
首先我们使用 gmm = GaussianMixture(n_components=1, covariance_type=‘full’, max_iter=100) 来创建 GMM 聚类,其中有几个比较主要的参数(GMM 类的构造参数比较多,我筛选了一些主要的进行讲解),我分别来讲解下:
1.n_components:即高斯混合模型的个数,也就是我们要聚类的个数,默认值为 1。如果你不指定 n_components,最终的聚类结果都会为同一个值。
2.covariance_type:代表协方差类型。一个高斯混合模型的分布是由均值向量和协方差矩阵决定的,所以协方差的类型也代表了不同的高斯混合模型的特征。协方差类型有 4 种取值:
covariance_type=full,代表完全协方差,也就是元素都不为 0;
covariance_type=tied,代表相同的完全协方差;
covariance_type=diag,代表对角协方差,也就是对角不为 0,其余为 0;
covariance_type=spherical,代表球面协方差,非对角为 0,对角完全相同,呈现球面的特性。
3.max_iter:代表最大迭代次数,EM 算法是由 E 步和 M 步迭代求得最终的模型参数,这里可以指定最大迭代次数,默认值为 100。
创建完 GMM 聚类器之后,我们就可以传入数据让它进行迭代拟合。
我们使用 fit 函数,传入样本特征矩阵,模型会自动生成聚类器,然后使用 prediction=gmm.predict(data) 来对数据进行聚类,传入你想进行聚类的数据,可以得到聚类结果 prediction。
你能看出来拟合训练和预测可以传入相同的特征矩阵,这是因为聚类是无监督学习,你不需要事先指定聚类的结果,也无法基于先验的结果经验来进行学习。只要在训练过程中传入特征值矩阵,机器就会按照特征值矩阵生成聚类器,然后就可以使用这个聚类器进行聚类了。
四、 如何用 EM 算法对王者荣耀数据进行聚类
了解了 GMM 聚类工具之后,我们看下如何对王者荣耀的英雄数据进行聚类。
首先我们知道聚类的原理是“人以群分,物以类聚”。通过聚类算法把特征值相近的数据归为一类,不同类之间的差异较大,这样就可以对原始数据进行降维。通过分成几个组(簇),来研究每个组之间的特性。或者我们也可以把组(簇)的数量适当提升,这样就可以找到可以互相替换的英雄,比如你的对手选择了你擅长的英雄之后,你可以选择另一个英雄作为备选。
我们先看下数据长什么样子:
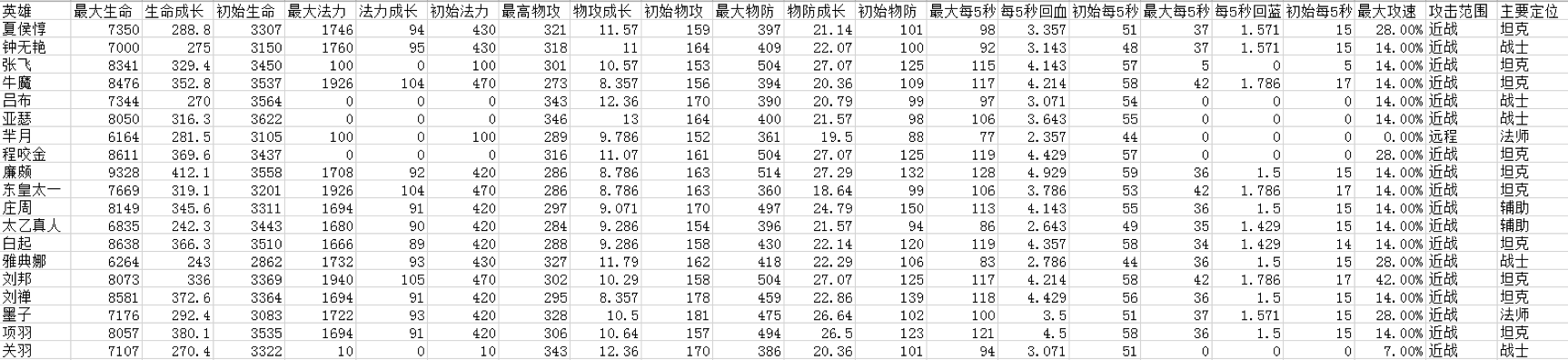
这里我们收集了 69 名英雄的 20 个特征属性,这些属性分别是最大生命、生命成长、初始生命、最大法力、法力成长、初始法力、最高物攻、物攻成长、初始物攻、最大物防、物防成长、初始物防、最大每 5 秒回血、每 5 秒回血成长、初始每 5 秒回血、最大每 5 秒回蓝、每 5 秒回蓝成长、初始每 5 秒回蓝、最大攻速和攻击范围等。
具体的数据集你可以在 GitHub 上下载: https://github.com/cystanford/EM_data 。
现在我们需要对王者荣耀的英雄数据进行聚类,我们先设定项目的执行流程:
首先我们需要加载数据源;
在准备阶段,我们需要对数据进行探索,包括采用数据可视化技术,让我们对英雄属性以及这些属性之间的关系理解更加深刻,然后对数据质量进行评估,是否进行数据清洗,最后进行特征选择方便后续的聚类算法;
聚类阶段:选择适合的聚类模型,这里我们采用 GMM 高斯混合模型进行聚类,并输出聚类结果,对结果进行分析。
按照上面的步骤,我们来编写下代码。完整的代码如下:
- # -*- coding: utf-8 -*-
- import pandas as pd
- import csv
- import matplotlib.pyplot as plt
- import seaborn as sns
- from sklearn.mixture import GaussianMixture
- from sklearn.preprocessing import StandardScaler
- # 数据加载,避免中文乱码问题
- data_ori = pd.read_csv('./heros7.csv', encoding = 'gb18030')
- features = [u'最大生命',u'生命成长',u'初始生命',u'最大法力', u'法力成长',u'初始法力',u'最高物攻',u'物攻成长',u'初始物攻',u'最大物防',u'物防成长',u'初始物防', u'最大每 5 秒回血', u'每 5 秒回血成长', u'初始每 5 秒回血', u'最大每 5 秒回蓝', u'每 5 秒回蓝成长', u'初始每 5 秒回蓝', u'最大攻速', u'攻击范围']
- data = data_ori[features]
- # 对英雄属性之间的关系进行可视化分析
- # 设置 plt 正确显示中文
- plt.rcParams['font.sans-serif']=['SimHei'] # 用来正常显示中文标签
- plt.rcParams['axes.unicode_minus']=False # 用来正常显示负号
- # 用热力图呈现 features_mean 字段之间的相关性
- corr = data[features].corr()
- plt.figure(figsize=(14,14))
- # annot=True 显示每个方格的数据
- sns.heatmap(corr, annot=True)
- plt.show()
- # 相关性大的属性保留一个,因此可以对属性进行降维
- features_remain = [u'最大生命', u'初始生命', u'最大法力', u'最高物攻', u'初始物攻', u'最大物防', u'初始物防', u'最大每 5 秒回血', u'最大每 5 秒回蓝', u'初始每 5 秒回蓝', u'最大攻速', u'攻击范围']
- data = data_ori[features_remain]
- data[u'最大攻速'] = data[u'最大攻速'].apply(lambda x: float(x.strip('%'))/100)
- data[u'攻击范围']=data[u'攻击范围'].map({'远程':1,'近战':0})
- # 采用 Z-Score 规范化数据,保证每个特征维度的数据均值为 0,方差为 1
- ss = StandardScaler()
- data = ss.fit_transform(data)
- # 构造 GMM 聚类
- gmm = GaussianMixture(n_components=30, covariance_type='full')
- gmm.fit(data)
- # 训练数据
- prediction = gmm.predict(data)
- print(prediction)
- # 将分组结果输出到 CSV 文件中
- data_ori.insert(0, '分组', prediction)
- data_ori.to_csv('./hero_out.csv', index=False, sep=',')
运行结果如下:
- [28 14 8 9 5 5 15 8 3 14 18 14 9 7 16 18 13 3 5 4 19 12 4 12
- 12 12 4 17 24 2 7 2 2 24 2 2 24 6 20 22 22 24 24 2 2 22 14 20
- 14 24 26 29 27 25 25 28 11 1 23 5 11 0 10 28 21 29 29 29 17]
同时你也能看到输出的聚类结果文件 hero_out.csv(它保存在你本地运行的文件夹里,程序会自动输出这个文件,你可以自己看下)。
我来简单讲解下程序的几个模块。
关于引用包
首先我们会用 DataFrame 数据结构来保存读取的数据,最后的聚类结果会写入到 CSV 文件中,因此会用到 pandas 和 CSV 工具包。另外我们需要对数据进行可视化,采用热力图展现属性之间的相关性,这里会用到 matplotlib.pyplot 和 seaborn 工具包。在数据规范化中我们使用到了 Z-Score 规范化,用到了 StandardScaler 类,最后我们还会用到 sklearn 中的 GaussianMixture 类进行聚类。
数据可视化的探索
你能看到我们将 20 个英雄属性之间的关系用热力图呈现了出来,中间的数字代表两个属性之间的关系系数,最大值为 1,代表完全正相关,关系系数越大代表相关性越大。从图中你能看出来“最大生命”“生命成长”和“初始生命”这三个属性的相关性大,我们只需要保留一个属性即可。同理我们也可以对其他相关性大的属性进行筛选,保留一个。你在代码中可以看到,我用 features_remain 数组保留了特征选择的属性,这样就将原本的 20 个属性降维到了 13 个属性。
关于数据规范化
我们能看到“最大攻速”这个属性值是百分数,不适合做矩阵运算,因此我们需要将百分数转化为小数。我们也看到“攻击范围”这个字段的取值为远程或者近战,也不适合矩阵运算,我们将取值做个映射,用 1 代表远程,0 代表近战。然后采用 Z-Score 规范化,对特征矩阵进行规范化。
在聚类阶段
我们采用了 GMM 高斯混合模型,并将结果输出到 CSV 文件中。
这里我将输出的结果截取了一段(设置聚类个数为 30):
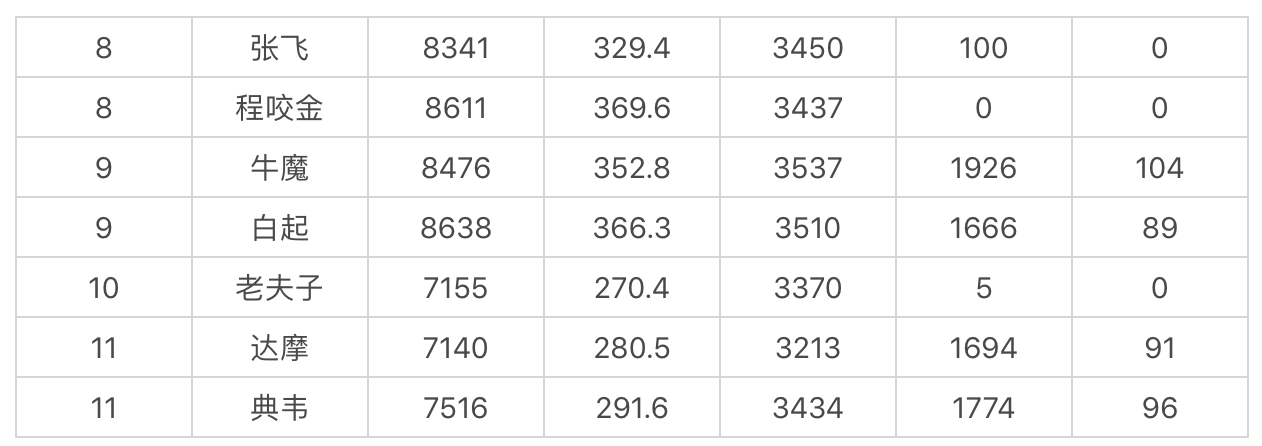
第一列代表的是分组(簇),我们能看到张飞、程咬金分到了一组,牛魔、白起是一组,老夫子自己是一组,达摩、典韦是一组。聚类的特点是相同类别之间的属性值相近,不同类别的属性值差异大。因此如果你擅长用典韦这个英雄,不防试试达摩这个英雄。同样你也可以在张飞和程咬金中进行切换。这样就算你的英雄被别人选中了,你依然可以有备选的英雄可以使用。
机器学习经典算法之EM的更多相关文章
- 机器学习经典算法详解及Python实现--基于SMO的SVM分类器
原文:http://blog.csdn.net/suipingsp/article/details/41645779 支持向量机基本上是最好的有监督学习算法,因其英文名为support vector ...
- Python3入门机器学习经典算法与应用
<Python3入门机器学习经典算法与应用> 章节第1章 欢迎来到 Python3 玩转机器学习1-1 什么是机器学习1-2 课程涵盖的内容和理念1-3 课程所使用的主要技术栈第2章 机器 ...
- Python3实现机器学习经典算法(三)ID3决策树
一.ID3决策树概述 ID3决策树是另一种非常重要的用来处理分类问题的结构,它形似一个嵌套N层的IF…ELSE结构,但是它的判断标准不再是一个关系表达式,而是对应的模块的信息增益.它通过信息增益的大小 ...
- Python3实现机器学习经典算法(二)KNN实现简单OCR
一.前言 1.ocr概述 OCR (Optical Character Recognition,光学字符识别)是指电子设备(例如扫描仪或数码相机)检查纸上打印的字符,通过检测暗.亮的模式确定其形状,然 ...
- Python3实现机器学习经典算法(一)KNN
一.KNN概述 K-(最)近邻算法KNN(k-Nearest Neighbor)是数据挖掘分类技术中最简单的方法之一.它具有精度高.对异常值不敏感的优点,适合用来处理离散的数值型数据,但是它具有 非常 ...
- Python3实现机器学习经典算法(四)C4.5决策树
一.C4.5决策树概述 C4.5决策树是ID3决策树的改进算法,它解决了ID3决策树无法处理连续型数据的问题以及ID3决策树在使用信息增益划分数据集的时候倾向于选择属性分支更多的属性的问题.它的大部分 ...
- 机器学习经典算法具体解释及Python实现--线性回归(Linear Regression)算法
(一)认识回归 回归是统计学中最有力的工具之中的一个. 机器学习监督学习算法分为分类算法和回归算法两种,事实上就是依据类别标签分布类型为离散型.连续性而定义的. 顾名思义.分类算法用于离散型分布预測, ...
- 机器学习经典算法具体解释及Python实现--K近邻(KNN)算法
(一)KNN依旧是一种监督学习算法 KNN(K Nearest Neighbors,K近邻 )算法是机器学习全部算法中理论最简单.最好理解的.KNN是一种基于实例的学习,通过计算新数据与训练数据特征值 ...
- Python3入门机器学习经典算法与应用☝☝☝
Python3入门机器学习经典算法与应用 (一个人学习或许会很枯燥,但是寻找更多志同道合的朋友一起,学习将会变得更加有意义✌✌) 使用新版python3语言和流行的scikit-learn框架,算法与 ...
随机推荐
- python 教程 第十二章、 标准库
第十二章. 标准库 See Python Manuals ? The Python Standard Library ? 1) sys模块 import sys if len(sys.argv) ...
- 构建自己的PHP框架(composer)
完整项目地址:https://github.com/Evai/Aier Composer 利用 PSR-0 和 PSR-4 以及 PHP5.3 的命名空间构造了一个繁荣的 PHP 生态系统.Compo ...
- 从零开始学习 asp.net core 2.1 web api 后端api基础框架(一)-环境介绍
原文:从零开始学习 asp.net core 2.1 web api 后端api基础框架(一)-环境介绍 版权声明:本文为博主原创文章,未经博主允许不得转载. https://blog.csdn.ne ...
- Matlab随笔之画图函数总结
原文:Matlab随笔之画图函数总结 MATLAB函数画图 MATLAB不但擅长於矩阵相关的数值运算,也适合用在各种科学目视表示(Scientific visualization).本节将介绍MATL ...
- Http请求格式(在Linux下使用telnet亲测,通过这篇我才明白)
命令行窗口中用telnet测试HTTP协议请求消息格式响应消息格式1. 命令行窗口中用telnet测试HTTP协议 HTTP消息是由普通ASCII文本组成.消息包括消息头和数据体部分.消息头以行为单位 ...
- get与post一些特殊情况下
p=574"> 文章已经迁移至http://androiddevelop.cn/?p=574 版权声明:本文博客原创文章.博客,未经同意,不得转载.
- jquery layer插件弹出弹层 结构紧凑,功能强大
/* 去官方网站下载最新的js http://sentsin.com/jquery/layer/ ①引用jquery ②引用layer.min.js */ 事件触发炸弹层可以自由绑定,例如: $('# ...
- SGI STL中内存池的实现
最近这两天研究了一下SGI STL中的内存池, 网上对于这一块的讲解很多, 但是要么讲的不完整, 要么讲的不够简单(至少对于我这样的初学者来讲是这样的...), 所以接下来我将把我对于对于SGI ST ...
- ASP .NET Model
Model是全局变量,一个页面一个 前台 @ModelWebApplication1.Models.Movie; @{ ViewBag.Title = "ModelTest"; } ...
- 如何将编码转为自己想要的编码 -- gbk utf-8
/** * 数组转码 * @param array $arr 要转码的数组 * @param string $in_charset 输入的字符集 * @param string $out_ch ...