复杂模型可解释性方法——LIME
一、模型可解释性
近年来,机器学习(深度学习)取得了一系列骄人战绩,但是其模型的深度和复杂度远远超出了人类理解的范畴,或者称之为黑盒(机器是否同样不能理解?),当一个机器学习模型泛化性能很好时,我们可以通过交叉验证验证其准确性,并将其应用在生产环境中,但是很难去解释这个模型为什么会做出此种预测,是基于什么样的考虑?作为机器学习从业者很容易想清楚为什么有些模型存在性别歧视、种族歧视和民族仇恨言论(训练样本的问题),但是很多场景下我们需要向模型使用方作出解释,让其清楚模型为什么要做出此种预测,如模型替代医生判断病情,给出病人合理的解释至关重要,在商业场景中,模型为公司做出决策,需要给出令管理层信服的解释。另外,给出解释也可以帮助我们进一步改善模型,优化特征,提高泛化性。
本文就LIME( Local Interpretable Model-Agnostic Explanations, LIME)方法如何解释黑盒模型作出简要的介绍和公式推导,介绍其优缺点,文末附上自己的一些简单思考
二、 LIME
LIME的主要思想是利用可解释性模型(如线性模型,决策树)局部近似目标黑盒模型的预测,此方法不深入模型内部,通过对输入进行轻微的扰动,探测黑盒模型的输出发生何种变化,根据这种变化在兴趣点(原始输入)训练一个可解释性模型。值得注意的是,可解释性模型是黑盒模型的局部近似,而不是全局近似,这也是其名字的由来。
LIME的数学表示如下:
\[
explanation(x)=arg\min_{g\in G}L(f,g,\pi_x)+\Omega(g)
\]
对于实例\(x\)的解释模型\(g\),我们通过最小化损失函数来比较模型\(g\)和原模型\(f\)的近似性,其中,\(\Omega (g)\)代表了解释模型\(g\)的模型复杂度,\(G\)表示所有可能的解释模型(例如我们想用线性模型解释,则\(G\)表示所有的线性模型),\(\pi_{x}\) 定义了\(x\)的邻域。我们通过最小化\(L\)使得模型\(f\)变得可解释。其中,模型\(g\),邻域范围大小,模型复杂度均需要定义。
下面对于结构化数据类型,简要说明LIME的工作流程。
对于结构化数据,首先确定可解释性模型,兴趣点x,邻域的范围。LIME首先在全局进行采样,然后对于所有采样点,选出兴趣点x的邻域,然后利用兴趣点的邻域范围拟合可解释性模型。如下图\(^1\)
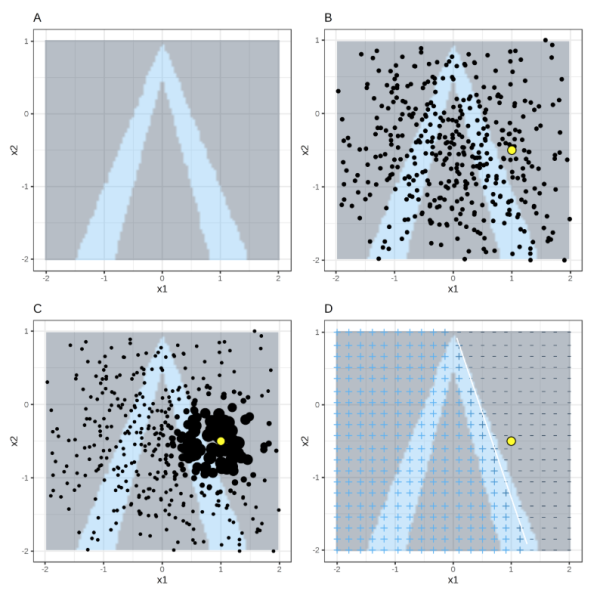
其中,背景灰色为负例,背景蓝色为正例,黄色为兴趣点,小粒度黑色点为采样点,大粒度黑点为邻域范围,右下图为LIME的结果。
LIME的优点我们很容易就可以看到,原理简单,适用范围广,可解释任何黑箱模型。但是在实际应用中,存在几个问题:
- 需要确定邻域范围;邻域范围不同,得到的局部可解释性模型可能会有很大的差别,如下图
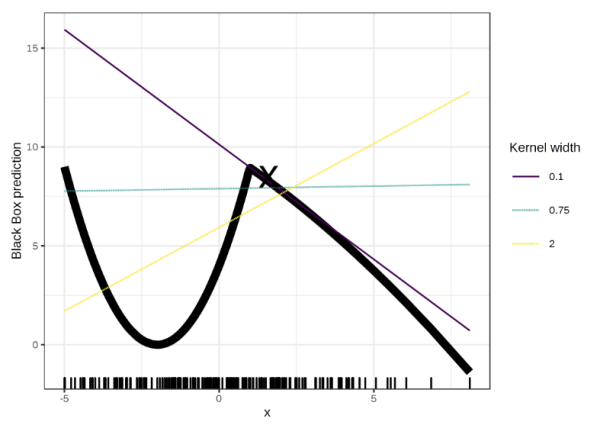
对于x=1.6,不同的邻域范围(0.1,0.75,2)对应的可解释性模型是完全不同的,甚至相悖。
采样是全样本集采样,采样是利用高斯分布进行采样,忽略了特征之间的关系,这可能导致一些不大可能出现的样本点来解释模型。
解释模型的复杂度需要提前定义。
解释的不稳定性。利用相同参数相同方法进行的重复解释,得到的结果可能完全不同.\(^5\)
三、总结
模型可解释性作为目前机器学习领域研究的热门,LIME的成果是很有启发性的,通过对黑盒模型某局部点的无限次探测,拟合出一个局部可解释性的简单模型。但是其缺点同样明显,这些缺点也导致了LIME方法难以大规模应用。
后续将介绍基于Shapley值的SHAP方法(现在在研读,就是有点看不懂。看懂了再写)
参考链接:
- https://christophm.github.io/interpretable-ml-book/lime.html
- https://blog.csdn.net/a358463121/article/details/52313585
- https://cloud.tencent.com/developer/article/1096716
- 论文地址:https://arxiv.org/pdf/1602.04938v1.pdf
Alvarez-Melis, David, and Tommi S. Jaakkola. “On the robustness of interpretability methods.” arXiv preprint arXiv:1806.08049 (2018).)
本文由飞剑客原创,如需转载,请联系私信联系知乎:@AndyChanCD
复杂模型可解释性方法——LIME的更多相关文章
- NNs(Neural Networks,神经网络)和Polynomial Regression(多项式回归)等价性之思考,以及深度模型可解释性原理研究与案例
1. Main Point 0x1:行文框架 第二章:我们会分别介绍NNs神经网络和PR多项式回归各自的定义和应用场景. 第三章:讨论NNs和PR在数学公式上的等价性,NNs和PR是两个等价的理论方法 ...
- 基于 Koa平台Node.js开发的KoaHub.js的控制器,模型,帮助方法自动加载
koahub-loader koahub-loader是基于 Koa平台Node.js开发的KoaHub.js的koahub-loader控制器,模型,帮助方法自动加载 koahub loader I ...
- 评价指标的局限性、ROC曲线、余弦距离、A/B测试、模型评估的方法、超参数调优、过拟合与欠拟合
1.评价指标的局限性 问题1 准确性的局限性 准确率是分类问题中最简单也是最直观的评价指标,但存在明显的缺陷.比如,当负样本占99%时,分类器把所有样本都预测为负样本也可以获得99%的准确率.所以,当 ...
- thinkphp模型中的获取器和修改器(根据字段名自动调用模型中的方法)
thinkphp模型中的获取器和修改器(根据字段名自动调用模型中的方法) 一.总结 记得看下面 1.获取器的作用是在获取数据的字段值后自动进行处理 2.修改器的作用是可以在数据赋值的时候自动进行转换处 ...
- 深度学习模型调优方法(Deep Learning学习记录)
深度学习模型的调优,首先需要对各方面进行评估,主要包括定义函数.模型在训练集和测试集拟合效果.交叉验证.激活函数和优化算法的选择等. 那如何对我们自己的模型进行判断呢?——通过模型训练跑代码,我们可以 ...
- ASP.NET MVC中的模型装配 封装方法 非常好用
下面说一下 我们知道在asp.net mvc中 视图可以绑定一个实体模型 然后我们三层架构中也有一个model模型 但是这两个很多时候却是不一样的对象来的 就拿微软的官方mvc例子来说明 微软的视图实 ...
- PRML读书会第三章 Linear Models for Regression(线性基函数模型、正则化方法、贝叶斯线性回归等)
主讲人 planktonli planktonli(1027753147) 18:58:12 大家好,我负责给大家讲讲 PRML的第3讲 linear regression的内容,请大家多多指教,群 ...
- sklearn中树模型可视化的方法
在机器学习的过程中,我们常常会用到树模型的方式来解决我们的问题.在工业界,我们不仅要针对某个问题利用机器学习的方法来解决问题,而且还需要能力解释其中的原理或原因.今天主要在这里记录一下树模型是怎么做可 ...
- IRT模型的参数估计方法(EM算法和MCMC算法)
1.IRT模型概述 IRT(item response theory 项目反映理论)模型.IRT模型用来描述被试者能力和项目特性之间的关系.在现实生活中,由于被试者的能力不能通过可观测的数据进行描述, ...
随机推荐
- Zabbix面试总结
zabbix官方的一句话描述zabbix: 监视任何事情适用于任何IT基础架构,服务,应用程序和资源的解决方案 Monitor anythingSolutions for any kind of IT ...
- FreeSql (二十六)贪婪加载 Include、IncludeMany、Dto、ToList
贪婪加载顾名思议就是把所有要加载的东西一次性读取. 本节内容为了配合[延时加载]而诞生,贪婪加载和他本该在一起介绍,开发项目的过程中应该双管齐下,才能写出高质量的程序. Dto 映射查询 Select ...
- Winform中自定义xml配置文件后对节点进行读取与写入
场景 Winform中自定义xml配置文件,并配置获取文件路径: https://blog.csdn.net/BADAO_LIUMANG_QIZHI/article/details/100522648 ...
- win下的mongodb安装和基础操作
一.下载地址: https://www.mongodb.com/download-center/community 二.安装错误: 1.安装过程中报错(类似下图): 原因:没有管理员权限 解决:管理员 ...
- Go微服务全链路跟踪详解
在微服务架构中,调用链是漫长而复杂的,要了解其中的每个环节及其性能,你需要全链路跟踪. 它的原理很简单,你可以在每个请求开始时生成一个唯一的ID,并将其传递到整个调用链. 该ID称为Correlati ...
- Linux 笔记 - 第十章 Shell 基础知识
博客地址:http://www.moonxy.com 一.前言 Shell 是系统的用户界面,提供了用户与内核进行交互操作的一种接口,它接收用户输入的命令并把它送入内核去执行.实际上 Shell 是一 ...
- Day 15 文件打包与压缩
1.什么是文件压缩? 将多个文件或目录合并成为一个特殊的文件.比如: 搬家...脑补画面 img. 2.为什么要对文件进行压缩? 当我们在传输大量的文件时,通常都会选择将该文件进行压缩,然后在进行传输 ...
- 38 (OC)* 进程、线程、堆栈
一.进程和线程 1.什么是进程 进程是指在系统中正在运行的一个应用程序 每个进程之间是独立的,每个进程均运行在其专用且受保护的内存空间内 比如同时打开QQ.Xcode,系统就会分别启动2个进程 通过“ ...
- 第一次接触WebSocket遇到的坑以及感受
要求用.net写一个服务,然后通过webscoket实现客户端与服务端之间的通信. 第一次知道.net还可以用来写服务,然后问题来了,服务是什么- -..下面图里的就是服务,可以停止暂停和启动. 我要 ...
- 基于Asp.Net Core MVC和AdminLTE的响应式管理后台之侧边栏处理
说明: .NET Core版本为:2.2 AdminLTE版本为:2.4.18 Bootstrap版本为:3.4.1 font-awesome版本为:4.7.0 1.新建项目:AdminLteDemo ...