[考试反思]1029csp-s模拟测试93:殇逝

停止!
思考,
回顾。
疑惑?
遗忘…
一直只是在匆忙的赶进度,实际上的确是一点也不扎实。
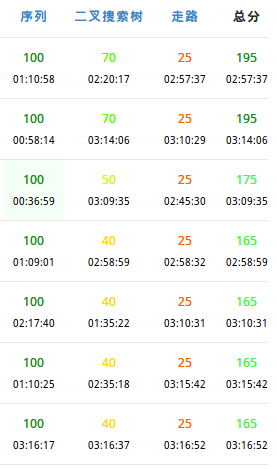
T1,裸的偏序,想了一个多小时什么也没想到,只打了$O(n^2)$
难道之前学的就这么白学了?
T2,简单dp,没有任何优化就扔了。
单调性优化做了无数次还是不会。
T3,暴力和部分分,部分分写错,暴力没取模。
90多场了啊,这些毛病还在犯,那么考试还有什么意义啊?
需要真正的反思与总结了,需要真正内化成自己的东西,才不是浑浑噩噩度日吧。
少说点废话吧。
T1:序列
求区间大于0,其实就是前缀和之后求$b[j] \geq b[i]$且$a[j] \geq a[i]$的最大$j-i$
看起来向一个三维偏序,但是题目保证有大于0的解,所以当$i \geq j$时并不会更新答案。
所以其实$i/j$这一维并不需要偏序,只用考虑$a/b$两个数组即可。
而$i/j$只是转移值,现在转化为二维偏序问题。
乍一下想动用各种数据结构,但是内存都开不下。
而偏序问题的一个技巧就是通过排序某一维来取消这一维的限制。所以维数-1。
然后就是一个一维偏序问题了,树状数组维护即可。
总的来说就是按$a$排序,将$b$离散化,树状数组维护$i/j$下标最小值即可。
#include<cstdio>
#include<algorithm>
#include<map>
using namespace std;
#define ll long long
map<ll,int>M;
struct P{
ll a;int b,p;
friend bool operator<(P x,P y){
return x.a<y.a||(x.a==y.a&&x.p<y.p);
}
}p[];
long long a[],b[];int n,ans,cnt,t[];
int read(){
register int p=,nt=;register char ch=getchar();
while(ch<''||ch>'')nt=ch=='-',ch=getchar();
while(ch>=''&&ch<='')p=(p<<)+(p<<)+ch-'',ch=getchar();
return nt?-p:p;
}
void set(int p,int w){for(;p<=;p+=p&-p)t[p]=min(t[p],w);}
int ask(int p,int w=){for(;p;p^=p&-p)w=min(w,t[p]);return w;}
int main(){//freopen("sequence.in","r",stdin);
n=read();M[];
for(int i=;i<=n;++i)a[i]=a[i-]+read();
for(int i=;i<=n;++i)b[i]=b[i-]+read(),M[b[i]];
for(map<ll,int>::iterator it=M.begin();it!=M.end();it++)(*it).second=++cnt;
for(int i=;i<=n;++i)p[i]=(P){a[i],M[b[i]],i};
sort(p,p++n);
for(int i=;i<=;++i)t[i]=;
for(int i=;i<=n;++i)ans=max(ans,p[i].p-ask(p[i].b)),set(p[i].b,p[i].p);
printf("%d\n",ans);
}
T2:二叉搜索树
简单的$dp$就是$dp[i][j]$表示区间$[i,j]$之间的点形成树的代价,转移很简单:
$dp[i][j]=min(dp[i][k-1]+dp[k][j]+x[j]-x[i-1])$
其中x是权值的前缀和。
考虑优化:当你在某一个区间右端添加一个点的时候,你最后选定的根节点一定不会左移。
同理,你在左段添加一个点的话,最后选定的最优根节点也一定不会左移。
设$rt[i][j]$表示区间$[i,j]$的最优根节点。那么有
$rt[i][j-1] \leq rt[i][j] \leq rt[i+1][j]$
所以就可以dp了,用上面这个限制一下左右端点。
因为是单调的,所以在$n$种长度里每个位置平均只会被扫$O(n)$次。
所以总的复杂度是$O(n^2)$
#include<cstdio>
int n;long long x[],dp[][],rt[][];
main(){
scanf("%d",&n);
for(int i=;i<=n;++i)scanf("%lld",&x[i]),x[i]+=x[i-];
for(int l=;l<=n;++l)for(int r=l;r<=n;++r)dp[l][r]=;
for(int l=;l<=n;++l)dp[l][l]=x[l]-x[l-],rt[l][l]=l;
for(int L=;L<n;++L)for(int l=,r=l+L;r<=n;++l,++r)
for(int m=rt[l][l+L-];m<=rt[r-L+][r];++m)
if(dp[l][m-]+dp[m+][r]+x[r]-x[l-]<dp[l][r])
dp[l][r]=dp[l][m-]+dp[m+][r]+x[r]-x[l-],rt[l][r]=m;
printf("%lld\n",dp[][n]);
}
T3:走路
题面差评。非得让我栽$n-1$个跟头干啥???做个题结果就真栽跟头了。
挺神仙的一道题。这种分治思想很巧妙。
之前有一道题好像叫《$Dash \ Speed$》是线段树结构的分治,这个也差不多。。。
我们考虑暴力做法。
因为我对期望的理解直到今天$LNC$好好地给我来了一遍才深刻一点。
因为正着推的时候它的转移概率之和不一定为1,而期望的实际含义则是加权平均数。
所以正着推的话要想得到期望就还得一直带着概率算,在出环的图里不可做。
所以要倒着推:设$f_i$表示期望再经过几步才能到$k$点。
转移就是$f_i=\sum\limits_{i \to j}\frac{f_j}{degree_i}$
$degree_i$表是i的出度。
这样的话转移的总概率就是每一条出边累加$\frac{1}{degree_i}$那么总概率当然是1。
而正着的式子却不是,不再赘述。
暴力的思路就是拆掉每个点的所有出边,然后做一次瓜丝消元$f_1$就是解。
#include<cstdio>
#include<algorithm>
using namespace std;
#define mod 998244353
#define ll long long
int n,m,cnt[][],deg[],spj1=,spj2=;ll x[][],inv[],escape[];
ll pow(ll b,int t=mod-,ll a=){for(;t;t>>=,b=b*b%mod)if(t&)a=a*b%mod;return a;}
void Gauss(){
for(int i=;i<=n;++i){
if(!x[i][i])for(int j=i+;j<=n;++j)if(x[j][i])swap(x[i],x[j]);
int inv=pow(x[i][i]);
for(int j=i;j<=n+;++j)x[i][j]=x[i][j]*inv%mod;
for(int j=i+;j<=n;++j)for(int k=n+;k>=i;--k)x[j][k]=(x[j][k]-x[i][k]*x[j][i]%mod+mod)%mod;
}
for(int i=n;i;--i)for(int j=i-;j;--j)x[j][n+]=(x[j][n+]-x[j][i]*x[i][n+]%mod+mod)%mod;
}
main(){
scanf("%d%d",&n,&m);
for(int i=,X,Y;i<=m;++i){
scanf("%d%d",&X,&Y),deg[X]++,cnt[X][Y]++;
if(i!=m&&X>Y)spj1=;
if(X!=Y&&X!=&&Y!=)spj2=;
}
for(int i=;i<=m;++i)inv[i]=pow(i);
for(int A=;A<=n;++A){
for(int i=;i<=n;++i)for(int j=;j<=n+;++j)x[i][j]=;
for(int i=;i<=n;++i)if(A!=i)for(int j=;j<=n;++j)x[j][i]=cnt[i][j]*inv[deg[i]]%mod;
for(int i=;i<=n;++i)x[i][i]--;x[][n+]=-;
//for(int i=1;i<=n;++i,puts(""))for(int j=1;j<=n+1;++j)printf("%lld ",x[i][j]);
Gauss();for(int i=;i<=n;++i)if(i!=A)x[A][n+]+=x[i][n+];
printf("%lld\n",x[A][n+]%mod-);
}
}
不难发现,我们再每一次重造矩阵的时候,其实只有一行是不一样的,就是你单独考虑的$k$那一行。
考虑这个问题:我在瓜丝消元的时候填了一行,然后这一行一直在被消来消去,但是我们始终不用这一行来消其它的行。
那么最后求出的解当然是不会变的对吧?
所以我们先不拆任何边,这样建出一个矩阵。
然后我们对于目前要处理出的k,把这一行看成我们乱加的那一行,这行怎么被消都没有关系,但是我们不能用这一行去消其它行。
这样的话就相当与我们没有加这一堆边,它们对答案没有影响。
考虑递归解决,$solve(l,r)$表示我们正在处理$[l,r]$之内的k。
那么如果k在$[l,mid]$里面,那么$[mid+1,r]$里面的所有边都要生效,就是这些行都要被当作主元来给其它行消元。
消完之后我们就可以递归求解$solve(l,mid)$了。
这样的话如果我们可以发现,$solve(l,r)$的时候其实除了$[l,r]$以外的区间都被当成主元消过了。
那么如果我们递归到了某一个叶节点,那么就是除了这一行以外所有的行都被消过了。
这就和我上面说的情况一致了,这样就可以解出当前点的答案了。
当然如果我们要求解$solve(mid+1,r)$时,我们就需要用$[l,mid]$的边消元。
在这之前我们首先需要把矩阵还原,开数组存一下就好了。
为了方便,我们在每一次消元的时候,并不是把它消成上三角矩阵,而是消成单位矩阵,这样在后面方程比较好解,不用回代。
要注意:如果你的代码递归处函数出现了2个$n$级别的循环而不是$[l,r]$的循环,那么你的复杂度就是$O(n^3 \ log \ n)$了。并不是正解。
而如果只有一个$n$级别的循环,那么你的复杂度就是$O(n^3)$
证明稍后写吧。
问题就在于你的迭代式是下面的哪个:
$T(n)=Nn^2+2T(\frac{n}{2})$
$T(n)=N^2n+2T(\frac{n}{2})$
其中N是指题目输入的N,而n是指当前递归区间的大小。
当然在计算复杂度的时候可以把$N$直接提出,那么第一个式子就是:
$T(n)=N \times t(n) $
$t(n)=n^2+2t(\frac{n}{2})$
根据主定理,得到$t(n)=n^2$
所以$T(n)=n^3$
而对于第二个式子,其复杂度为:
$T(n)=N^2 \times t(n)$
$t(n)=n+2t(\frac{n}{2})$
这是一个非常常见的分治复杂度了。根据常识或者根据主定理,$t(n)=n\ log \ n $
所以$T(n)=n^3 \ log \ n$
#include<cstdio>
#include<algorithm>
using namespace std;
#define mod 998244353
#define int long long
int n,m,cnt[][],deg[],x[][],inv[],ans[];
int pow(int b,int t=mod-,int a=){for(;t;t>>=,b=b*b%mod)if(t&)a=a*b%mod;return a;}
void Gauss(int l,int r,int L,int R){
for(int i=L;i<=R;++i){
int inv=pow(x[i][i]);
for(int j=l;j<=r;++j)x[i][j]=x[i][j]*inv%mod;x[i][]=x[i][]*inv%mod;
for(int j=;j<=n;++j)if(i!=j){
int t=x[j][i];
for(int k=l;k<=r;++k)x[j][k]=(x[j][k]-x[i][k]*t%mod+mod)%mod;
x[j][]=(x[j][]-x[i][]*t%mod+mod)%mod;
}
}
}
void solve(int l,int r){
if(l==r)return ans[l]=(mod+x[][])%mod,(void);
int m=l+r>>;int re[][];
for(int i=;i<=n;++i){for(int j=l;j<=r;++j)re[i][j]=x[i][j];re[i][]=x[i][];}
Gauss(l,r,l,m);solve(m+,r);
for(int i=;i<=n;++i){for(int j=l;j<=r;++j)x[i][j]=re[i][j];x[i][]=re[i][];}
Gauss(l,r,m+,r);solve(l,m);
for(int i=;i<=n;++i){for(int j=l;j<=r;++j)x[i][j]=re[i][j];x[i][]=re[i][];}
}
main(){
scanf("%lld%lld",&n,&m);
for(int i=,X,Y;i<=m;++i)scanf("%lld%lld",&X,&Y),deg[X]++,cnt[X][Y]++;
for(int i=;i<=m;++i)inv[i]=pow(i);
for(int i=;i<=n;++i)for(int j=;j<=n;++j)x[i][j]=cnt[i][j]*inv[deg[i]]%mod;
for(int i=;i<=n;++i)x[i][i]--,x[i][]=-;
solve(,n);for(int i=;i<=n;++i)printf("%lld\n",ans[i]);
}
[考试反思]1029csp-s模拟测试93:殇逝的更多相关文章
- [考试反思]0718 NOIP模拟测试5
最后一个是我...rank#11 rank#1和rank#2被外校大佬包揽了. 啊...考的太烂说话底气不足... 我考场上在干些什么啊!!! 20分钟“切”掉T2,又27分钟“切”掉T1 切什么切, ...
- csp-s模拟测试93
csp-s模拟测试93 自闭场. $T1$想到$CDQ$,因为复杂度少看见一个$0$打了半年还用了$sort$直接废掉,$T2$,$T3$直接自闭暴力分都没有.考场太慌了,心态不好. 02:07:34 ...
- 2019.10.29 csp-s模拟测试93 反思总结
T1: 求出前缀和,三维偏序O(nlog2n)CDQ 二维其实就可以 #include<iostream> #include<cstdio> #include<cstri ...
- [考试反思]0814NOIP模拟测试21
前两名是外校的240.220.kx和skyh拿到了190的[暴力打满]的好成绩. 我第5是170分,然而160分就是第19了. 在前一晚上刚刚爆炸完毕后,心态格外平稳. 想想前一天晚上的挣扎: 啊啊啊 ...
- [考试反思]1109csp-s模拟测试106:撞词
(撞哈希了用了模拟测试28的词,所以这次就叫撞词吧) 蓝色的0... 蓝色的0... 都该联赛了还能CE呢... 考试结束前15分钟左右,期望得分300 然后对拍发现T2伪了写了一个能拿90分的垃圾随 ...
- [考试反思]0909csp-s模拟测试41:反典
说在前面:我是反面典型!!!不要学我!!! 说在前面:向rank1某脸学习,不管是什么题都在考试反思后面稍微写一下题解. 这次是真的真的运气好... 这次知识点上还可以,但是答题策略出了问题... 幸 ...
- [考试反思]0801NOIP模拟测试11
8月开门红. 放假回来果然像是神志不清一样. 但还是要接受这个事实. 嗯,说好听点,并列rank#7. 说难听点,垃圾rank#18. 都不用粘人名就知道我是哪一个吧... 因为图片不能太长,所以就不 ...
- [考试反思]0729NOIP模拟测试10
安度因:哇哦. 安度因:谢谢你. 第三个rank1不知为什么就来了.迷之二连?也不知道哪里来的rp 连续两次考试数学都占了比较大的比重,所以我非常幸运的得以发挥我的优势(也许是优势吧,反正数学里基本没 ...
- [考试反思]0714/0716,NOIP模拟测试3/4
这几天时间比较紧啊(其实只是我效率有点低我在考虑要不要坐到后面去吹空调) 但是不管怎么说,考试反思还是要写的吧. 第三次考试反思没写总感觉缺了点什么,但是题都刷不完... 一进图论看他们刷题好快啊为什 ...
随机推荐
- Android NDK(二) CMake构建工具进行NDK开发
本文目录 一Androidstudio中需要的插件 二项目配置 ①build.gardle配置 ②CMakeLists.txt ③Android和Cpp的代码 ④so文件生成 ⑤so文件的位置 一.A ...
- spring-data-redis-cache 使用及源码走读
预期读者 准备使用 spring 的 data-redis-cache 的同学 了解 @CacheConfig,@Cacheable,@CachePut,@CacheEvict,@Caching 的使 ...
- redis在mac上的下载安装
redis官网下载压缩包: 在终端进入下载后的目录,然后: 解压:tar zxvf redis-5.0.5.tar.gz 移动到:sudo mv redis-5.0.5 /usr/local 切换到: ...
- spring5 源码深度解析----- 事务的回滚和提交(100%理解事务)
上一篇文章讲解了获取事务,并且通过获取的connection设置只读.隔离级别等,这篇文章讲解剩下的事务的回滚和提交 回滚处理 之前已经完成了目标方法运行前的事务准备工作,而这些准备工作最大的目的无非 ...
- [JLOI2014]天天酷跑
请允许我对记忆化搜索进行一个总结,我认为所有的搜索只要数据范围允许,都可以转化为记忆化搜索, 只是,用处的多与少的关系,其本身是求出设出状态之后,为求出当前状态进行递推(搜索),推到 已知状态,之后再 ...
- Linux之shell基础
Shell基础 一.shell概述 1) shell是一个命令行解释器,它为用户提供了一个向Linux内核发送请求以便运行程序的界面系统级程序,用户可以用shell来启动.挂起.停止甚至是编写一些程序 ...
- RF作用与目的
robotframework自动化原理:通过ride工具编写脚本,加载指定的UI测试库,再通过pybot程序去运行指定脚本,调用浏览器驱动,打开浏览器,操作浏览器页面元素,达到模拟用户操作的行为 为什 ...
- PhantomJS not found on PATH
使用vue-cli创建项目后,npm init常出现以下问题:PhantomJS not found on PATH 这是因为文件phantomjs-2.1.1-windows.zip过大,网络不好容 ...
- 我家很管事的猫——mycat初步部署实践与问题排查
mycat,阿里出品的mysql中间件,提供读写分离和分库分表方案.项目中主要使用的是其读写分离功能. [如何部署?] 本文只采用并测试了双主从模式,配置看这一篇足矣: https://www.cnb ...
- nginx::环境搭建
ubuntu18.04 环境 1.需要gcc 环境,如果没有gcc环境,则需要安装 apt install gcc .安装pcre依赖库 PCRE(Perl Compatible Regular Ex ...