Elasticsearch系列---增量更新原理及优势
概要
本篇主要介绍增量更新(partial update,也叫局部更新)的核心原理,介绍6.3.1版本的Elasticsearch脚本使用实例和增量更新的优势。
增量更新过程与原理
简单回顾
前文我们有简单介绍过增量的语法,简单回顾一下请求示例:
POST /music/children/1/_update
{
"doc": {
"length": "76"
}
}
一般从客户端到Elasticsearch,完整的应用请求流程基本是这样的:
- 客户端先发起GET请求,获取到document信息,展现到前端页面上,供用户进行编辑。
- 用户编辑完数据后,点击提交。
- 后台系统处理修改后的数据,并组装好完整的document报文。
- 发送PUT请求到ES,进行全量替换。
- ES将老的document标记为deleted,然后重新创建一个新的document。
Elasticsearch的document是基于不可变模式设计的,所有的document更新,其实都创建了一个新的document出来,再把老的document标记为deleted,增量更新也不例外,只是GET全量document数据,整合新的document,替换老的document这三步操作全在一个shard里完成,毫秒级完成。
增量更新分片之间的交互
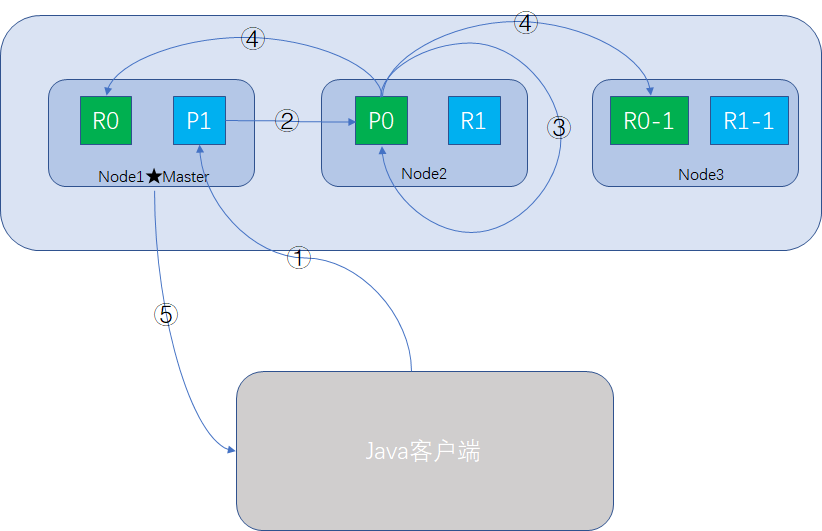
增量更新document的步骤:
- Java客户端向ES集群发送更新请求。
- Coodinate Node收到请求,但该document不在当前node上,它将请求转发到Node2节点的P0 shard上。
- Node 2检索document,修改_source下的JSON,并且重新索引该document,如果有其他线程修改过该document,有版本冲突的话,会重新尝试更新document,最大重试retry_on_conflict次,超出重试次数后放弃。
- 如果步骤3操作成功,Node2会将该document的完整内容异步转发到Node1和Node3的replica shard,重新建立索引。一旦所有replica都返回成功,Node2返回成功消息给Coodinate Node。
- Coodinate Node响应更新成功消息给客户端,此时ES集群内primary shard和replica shard都已经更新完成。
注意几点:
- primary shard向replica shard进行document数据同步时,发送的是document的完整信息,因为异步请求不保证有序,如果发增量信息的话,顺序错乱会导致document内容错误。
- 只要Coodinate Node向Java客户端响应成功,就表示所有的primary shard向replica shard都完成了更新操作,此时ES集群内的数据是一致的,更新是安全的。
- retry策略,ES再次获取document数据和最新版本号,成功就更新,失败再试,最大次数可以设置,如5次:retry_on_conflict=5
- retry策略在增量操作无关顺序的场景更适用,比如说计数操作,谁先执行谁后执行,关系不大,最终结果是对的就行。其他的一些场景,如库存的变化,账户余额的变化,直接更新成指定数值的,肯定不能使用retry策略,但可以转化成加减法,如下单时由直接更新库存数量的逻辑改成“当前可用库存数量=库存数量-订单商品数量”,账户余额的更新加减变化的金额,这样可以在一定程度上,把顺序有关转化成顺序无关,就可以更方便的使用retry策略解决冲突的问题。
增量更新的优点
- 所有的查询、修改和回写操作,都是在ES内部完成的,减小了网络数据传输开销(2次),提升了性能。
- 相比全量替换的时间间隔(秒级以上),缩短了查询和修改的时间间隔(毫秒级),可以有效降低并发冲突的情况。
使用脚本实现增量更新
Elasticsearch支持使用脚本实现更为灵活的逻辑,6.0版本以后,默认支持的脚本是painless,并且不再支持Groovy,因为Groovy编译有一定概率会出现内存不释放,最终导致Full GC的问题。
我们以英文儿歌的案例为背景,假设document的数据是这样:
{
"_index": "music",
"_type": "children",
"_id": "2",
"_version": 6,
"found": true,
"_source": {
"name": "wake me, shark me",
"content": "don't let me sleep too late, gonna get up brightly early in the morning",
"language": "english",
"length": "55",
"likes": 0
}
}
内置脚本
现在有这样一个需求:每当有人点击播放一次歌曲时,该document的likes field就自增1,我们可以用简单的脚本来实现:
POST /music/children/2/_update
{
"script" : "ctx._source.likes++"
}
执行一次后,再查询该document,发现likes变成1,每执行一次,likes都自增1,结果符合预期。
外部脚本
对刚刚那个自增需求做一些改动,支持批量更新播放量,自增的数量由参数传入,脚本也可以通过导入的方式,预先编译存储在ES中,使用的时候调用即可。
创建脚本
POST _scripts/music-likes
{
"script": {
"lang": "painless",
"source": "ctx._source.likes += params.new_likes"
}
}
脚本ID为music-likes,参数为new_likes,是可以在调用时传入的。
使用脚本
我们更新时,执行如下请求,就可以调用刚刚创建的脚本
POST /music/children/2/_update
{
"script": {
"id": "music-likes",
"params": {
"new_likes": 2
}
}
}
id即创建脚本时的music-likes,params是固定写法,里面的参数为new_likes,执行后再查看document信息,可以看到likes field的值按传入的值进行累加,结果符合预期。
查看脚本
命令:
GET _scripts/music-likes
斜杠后面的参数即脚本ID
删除脚本
命令:
DELETE _scripts/music-likes
斜杠后面的参数即脚本ID
脚本注意事项
- ES检测到新脚本时,会执行脚本编译,并将它存储在缓存中,编译比较耗时。
- 脚本的编写能参数化的,就不要硬编码,提高脚本的复用性。
- 短时间内太多的脚本编译,如果超出了ES的承受范围,ES直接报circuit_breaking_exception错误,这个范围默认是15条/分钟。
- 脚本缓存默认100条,默认不设过期时间,每个脚本最大字符65535字节,想自行配置的话可以改script.cache.expire、script.cache.max_size和script.max_size_in_bytes参数。
一句话,提高脚本的复用性。
upsert语法
像刚刚的案例,实现的是一个播放计数器的功能,目前这个计数器是与内容存储在一起,如果计数器单独存储,可能会出现新上架的一首歌,但计数器的document可能还不存在,试图对它做更新操作会报document_missing_exception错误,这种场景我们需要使用upsert语法:
POST /music/children/3/_update
{
"script" : "ctx._source.likes++",
"upsert": {
"likes": 0
}
}
如果id为3的记录不存在,第一次请求时,执行upsert里面的JSON内容,初始化一个新文档,ID为3,likes值为0;第二次请求时,文档已经存在,此时做script脚本的更新操作,likes自增。
小结
本篇简单介绍了增量更新的过程与原理,并与全量替换做了简单的对比,针对一些简单的计数场景,引入脚本的实现方式案例,脚本可以实现很丰富的功能,具体可以查看官网对Painless的介绍。
专注Java高并发、分布式架构,更多技术干货分享与心得,请关注公众号:Java架构社区

Elasticsearch系列---增量更新原理及优势的更多相关文章
- android 增量更新原理
原理如下:服务器端设计增量表,记录数据操作顺序id,和增删改查信息.在进行数据库表操作的时候同时进行将信息保存在增量表. android客户端在请求的时候上传最后保存的id.服务端判断最后的id,返回 ...
- Elasticsearch系列---shard内部原理
概要 本篇我们来看看shard内部的一些操作原理,了解一下人家是怎么玩的. 倒排索引 倒排索引的结构,是非常适合用来做搜索的,Elasticsearch会为索引的每个index为analyzed的字段 ...
- Elasticsearch系列---聚合查询原理
概要 本篇主要介绍聚合查询的内部原理,正排索引是如何建立的和优化的,fielddata的使用,最后简单介绍了聚合分析时如何选用深度优先和广度优先. 正排索引 聚合查询的内部原理是什么,Elastich ...
- androidstudio实现增量更新步骤
本文demo和参考例子参考-传送 门:http://blog.csdn.net/duguang77/article/details/17676797 一.增量更新优点:节省客户端和服务器端流量 增量 ...
- android黑科技系列——应用市场省流量更新(增量升级)原理解析
一.前言 最近在看热修复相关的框架,之前我们已经看过了阿里的Dexposed和AndFix这两个框架了,不了解的同学可以点击这里进行查看:Dexposed框架原理解析 和 AndFix热修复框架原理解 ...
- Elasticsearch系列---并发控制及乐观锁实现原理
概要 本篇主要介绍一下Elasticsearch的并发控制和乐观锁的实现原理,列举常见的电商场景,关系型数据库的并发控制.ES的并发控制实践. 并发场景 不论是关系型数据库的应用,还是使用Elasti ...
- Elasticsearch 索引的全量/增量更新
Elasticsearch 索引的全量/增量更新 当你的es 索引数据从mysql 全量导入之后,如何根据其他客户端改变索引数据源带来的变动来更新 es 索引数据呢. 首先用 Python 全量生成 ...
- ElasticStack系列之七 & IK自动热更新原理与实现
一.热更新原理 elasticsearch开启加载外部词典功功能后,会每60s间隔进行刷新字典.具体原理代码如下所示: public void loadDic(HttpServletRequest r ...
- 【热更新IK词典】ElasticSearch IK 自动热更新原理与实现
一.热更新原理 elasticsearch开启加载外部词典功功能后,会每60s间隔进行刷新字典.具体原理代码如下所示: public void loadDic(HttpServletRequest r ...
随机推荐
- [springboot 开发单体web shop] 3. 用户注册实现
目录 用户注册 ## 创建数据库 ## 生成UserMapper ## 编写业务逻辑 ## 编写user service UserServiceImpl#findUserByUserName 说明 U ...
- js垃圾回收
内存生命周期 分配你所需要的内存 使用分配到的内存(读.写) 不需要时将其释放\归还 所有语言第二部分都是明确的.第一和第三部分在底层语言中是明确的,但在像 JavaScript 这些高级语言中,嵌入 ...
- 学习笔记63_python反射
####反射预备知识一########### __call__ 对象后面加括号,触发执行. python中,类的默认的内置方法,有一个名为__call__,如 class foo: def __in ...
- Ubuntu18.04 安装MySQL(Linux)解决登陆权限问题及Navicat for mysql 中文乱码问题
一.MySQL(Linux)解决登陆权限问题 Ubuntu18.04 安装mysql或者mariadb之后,发现普通用户和远程都没有权限连接. ERROR 1045: Access denied fo ...
- os模块操作文件
os模块: path=os.path.join(os.path.dirname(os.path.dirname(__file__)),'images') path:运行脚本的当前文件下的上一个文件的地 ...
- NOIP模拟 30
补坑,很多都忘了. T1 树 像我这种人都能考场A掉当然是道水题辣 求出每条有向边的期望就好了 T2 回文串 当时毫无思路,暴力写挂. 首先把B转过来,那么都变成后缀的前缀拼起来 对于每一个LCP,他 ...
- python学习之【第十五篇】:Python中的常用模块之time模块
1.前言 在Python中,对时间的表示或操作通常要使用到time模块.本篇博文就来记录一下time模块中常用的几种时间表示转换方法. 2. 三种时间表示形式 2.1 时间戳 从1970年1月1日零点 ...
- Docker 开篇2 | 树莓派安装docker 续
问题1:安装后出现错误Error! The dkms.conf for this module includes a BUILD_EXCLUSIVE directive which does not ...
- jquery序列帧播放(支持视频自动播放和不是全屏播放)
jquery序列帧播放 这个弊端就是到时候需要升级下带宽 至少10MB 保证不卡.. ae导出序列真的时候 每秒10帧 就是代码每秒播放10张图片 尺寸适当的可以压小点<pre> < ...
- JMeter的安装部署——Linux系统
1.配置Java环境 在官网https://www.oracle.com/technetwork/java/javase/downloads/jdk10-downloads-4416644.html下 ...