机器学习笔记(十)---- KNN(K Nearst Neighbor)
KNN是一种常见的监督学习算法,工作机制很好理解:给定测试样本,基于某种距离度量找出训练集中与其最靠近的k个训练样本,然后基于这k个“邻居”的信息来进行预测。总结一句话就是“近朱者赤,近墨者黑”。
KNN可用作分类也可用于回归,在分类任务中可使用“投票法”,即选择这k个样本中出现最多的类别标记作为测试结果;在回归任务中可使用“平均法”将这k个样本的标记平均值作为预测结果;还可以基于距离远近进行加权平均或加权投票,距离越近的样本权重越大。
KNN和之前介绍的监督学习算法有一个很大的不同,它没有前期的训练过程,是一种“懒惰学习”的算法,只有收到测试样本后,再和训练样本进行比较处理。
初学者容易把KNN和K-means搞混淆,虽然都有K,:-)但这是两种不同的算法,二者区别如下:
| KNN | K-Means | |
| 不同点 | 是一种分类算法,属于监督学习的范畴,训练数据是带有label的 | 是一种聚类算法,属于非监督学习的范畴,训练数据没有label,杂乱无章的 |
| 没有明显的训练过程,属于lazy learning | 有明确的训练过程 | |
| K的含义:与预测样本距离最近的K个样本 | K的含义:K是事前人工定好的参数,假设数据集可分为K个簇 | |
| 相同点 | 都用到了NN(nearst Neighbor)算法,一般用KD树来实现。 | |
--KNN算法基本原理
KNN算法简单的步骤如下:
(1)计算距离:给定测试对象,计算它与训练集中每个对象的距离,空间距离的计算方法有多种,有欧式距离、夹角余弦(多在文本分类中使用)等。
(2)找邻居:圈定距离最近的k个对象,作为测试对象的近邻。
(3)做分类:根据这k个近邻归属的主要类别,对测试对象进行分类。
下面通过一个简单的示例说明下KNN算法是怎么进行分类的:
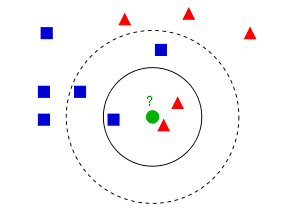
上图的蓝色方块和红色三角是已经打好label的数据,绿色圆圈是待分类的测试数据。
如果我们让K=3,那么上图实心圆圈中的两个三角和一个方块就是离测试数据最近的3个点,那么通过投票法则,测试数据会被分类为红色三角;
如果我们让K=5,那么上图虚线圆圈中的两个三角和三个方块就是离测试数据最近的5个点,通过投票法则,测试数据则会被分类为蓝色方块;
整个算法的原理是不是很简单?但实际上并没有那么简单,K如何选择?数据之间的距离怎么计算?
--K值的选择
如果K值太小,整体模型会变得复杂,容易发生过拟合,容易将一些噪声学习进来,二忽略数据的真实分布。
如果K值过大,模型会变得相对简单,可以减少学习的估计误差,但近似误差会变大,比如极端情况下K=N(N维训练样本数),则不论预测对象是什么,预测结果都将是训练集中最多的类型,这显然是一个过渡简化的模型,无法实际应用。
k值一般采用交叉验证或者Grid Search的方法确定。
--距离计算
提取数据的特征值,根据特征值组成一个n维实数向量空间(特征空间),然后计算向量之间的空间距离,如欧式距离、余弦相似度等。
对于数据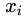 和
和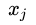 ,其特征空间为n维实数向量空间:
,其特征空间为n维实数向量空间: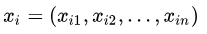 ,
,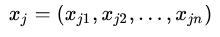
欧式距离计算公式为: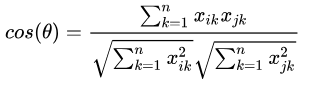
余弦相似度计算公式为: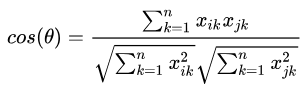
余弦相似度的值越接近1表示其越相似,接近0表示其差异越大。余弦相似度更多应用在文本类任务中。
--代码示例
依旧以sklearn中的cancer数据集为例,做一个通过30维特征判断是否患癌症的示例,示例中数据量很少,只有569条数据,每条数据各有30个特征数值。采用sklearn中的KNN分类器,除k外都采用默认参数,距离度量采用欧式距离 。通过交叉验证法来确定最佳的K值,从下图可见,K=14时,验证准确率最高。

__author__ = 'z00421185'
import pandas as pd
from sklearn import datasets
import matplotlib.pyplot as plt
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
from sklearn.neighbors import KNeighborsClassifier
breast_data = datasets.load_breast_cancer()
data = pd.DataFrame(datasets.load_breast_cancer().data)
data.columns = breast_data['feature_names']
data_np = breast_data['data']
target_np = breast_data['target']
print(data_np.shape)
x_train, x_test, y_train, y_test = train_test_split(data_np, target_np, test_size=0.3, random_state=0)
# 设定交叉验证k的范围,一般从1~样本数的开方
k_range = range(1, 24)
scores = []
for k in k_range:
knn = KNeighborsClassifier(k, metric='euclidean')
score = cross_val_score(knn, x_train, y_train, cv=10, scoring='accuracy')
scores.append(score.mean())
# 从折线图上看最佳K取值
plt.plot(k_range, scores)
plt.xlabel('K')
plt.ylabel('Accuracy')
plt.show()
model = KNeighborsClassifier(n_neighbors=13)
model.fit(x_train, y_train)
y_pred = model.predict(x_test)
print(accuracy_score(y_test, y_pred))
---------------------------------
0.9649122807017544作者:华为云专家 周捷
机器学习笔记(十)---- KNN(K Nearst Neighbor)的更多相关文章
- 机器学习笔记(5) KNN算法
这篇其实应该作为机器学习的第一篇笔记的,但是在刚开始学习的时候,我还没有用博客记录笔记的打算.所以也就想到哪写到哪了. 你在网上搜索机器学习系列文章的话,大部分都是以KNN(k nearest nei ...
- Machine Learning for hackers读书笔记(十)KNN:推荐系统
#一,自己写KNN df<-read.csv('G:\\dataguru\\ML_for_Hackers\\ML_for_Hackers-master\\10-Recommendations\\ ...
- K NEAREST NEIGHBOR 算法(knn)
K Nearest Neighbor算法又叫KNN算法,这个算法是机器学习里面一个比较经典的算法, 总体来说KNN算法是相对比较容易理解的算法.其中的K表示最接近自己的K个数据样本.KNN算法和K-M ...
- 机器学习(四) 分类算法--K近邻算法 KNN (上)
一.K近邻算法基础 KNN------- K近邻算法--------K-Nearest Neighbors 思想极度简单 应用数学知识少 (近乎为零) 效果好(缺点?) 可以解释机器学习算法使用过程中 ...
- 机器学习实战 之 KNN算法
现在 机器学习 这么火,小编也忍不住想学习一把.注意,小编是零基础哦. 所以,第一步,推荐买一本机器学习的书,我选的是Peter harrigton 的<机器学习实战>.这本书是基于pyt ...
- Python机器学习笔记:sklearn库的学习
网上有很多关于sklearn的学习教程,大部分都是简单的讲清楚某一方面,其实最好的教程就是官方文档. 官方文档地址:https://scikit-learn.org/stable/ (可是官方文档非常 ...
- Python机器学习笔记:不得不了解的机器学习面试知识点(1)
机器学习岗位的面试中通常会对一些常见的机器学习算法和思想进行提问,在平时的学习过程中可能对算法的理论,注意点,区别会有一定的认识,但是这些知识可能不系统,在回答的时候未必能在短时间内答出自己的认识,因 ...
- K Nearest Neighbor 算法
文章出处:http://coolshell.cn/articles/8052.html K Nearest Neighbor算法又叫KNN算法,这个算法是机器学习里面一个比较经典的算法, 总体来说KN ...
- Python机器学习笔记:不得不了解的机器学习知识点(2)
之前一篇笔记: Python机器学习笔记:不得不了解的机器学习知识点(1) 1,什么样的资料集不适合用深度学习? 数据集太小,数据样本不足时,深度学习相对其它机器学习算法,没有明显优势. 数据集没有局 ...
随机推荐
- Apache的虚拟主机功能
Apache的虚拟主机功能 (Virtual Host) 是可以让一台服务器基于IP.主机名或端口号实现提供多个网站服务的技术. 第一种情况:基于IP地址 这种情况很常见:一台服务器拥有多个IP地址, ...
- 大数据之路week01--自学之面向对象java(static,this指针(初稿))
函数的重载 返回值不一样会报错 java中,如果自己定义了构造函数的话,它就不会给你默认一个无参函数 如果一个属性,只进行定义,不初始化,自动补0,如果是一个布尔属性,默认是false但是如果一个局部 ...
- 关于数论分块里r=sum/(sum/l)的证明!
今天的模拟赛里T2要使用到数论分块,里面有一个重要的坎就是关于r=sum/(sum/l)的证明,网上关于这道题的题解里都没有关于这个的证明,那么我就来填补一下: 在以下的文章里,我都会使用lo(x)表 ...
- Python Socket学习之旅(二)
Socket函数 注解: Socket的close和shutdown--结束数据传输: close-----关闭本进程的socket id,但链接还是开着的,用这个socket id的其它进程还能用这 ...
- [网络]HTTP
HTTP HTTP 简介 HTTP 协议是 Hyper Text Transfer Protocol(超文本传输协议)的缩写,是用于从万维网(WWW:World Wide Web)服务器传输超文本到本 ...
- NLP-BM25算法理解
前两天老师给我们讲解了BM25算法,其中包括由来解释,以及算法推导,这里我再将其整理,这里我不讲解之前的BIM模型,大家有兴趣可以自行了解.Okapi BM25:一个非二值的模型bm25 是一种用来评 ...
- jstl-将List中的数据展示到表格中
功能: 使用jstl将List中的数据动态展示到Jsp表格中,并实现隔行换色功能. 效果图: Jsp代码: <%@ page import="java.util.ArrayList&q ...
- AngularJS: Error reports on $injector:modulerr
Angular JS最常见的问题是,程序启动失败,error为$injector:modulerr 错误是因为加载对应的Module失败,但很难找到需要修改的Module. 一个简单的小技巧是,不要使 ...
- Anaconda 笔记
Anaconda笔记 conda 功能 管理版本的切换 安装其他的包 conda 创建python27环境 conda create --name python27 python=2.7 conda ...
- 在代码生成工具Database2Sharp中使用ODP.NET(Oracle.ManagedDataAccess.dll)访问Oracle数据库,实现免安装Oracle客户端,兼容32位64位Oracle驱动
由于我们开发的辅助工具Database2Sharp需要支持多种数据库,虽然我们一般使用SQLServer来开发应用较多,但是Oracle等其他数据库也是常用的数据库之一,因此也是支持使用Oracle等 ...