scrapy抓取斗鱼APP主播信息
如何进行APP抓包
首先确保手机和电脑连接的是同一个局域网(通过路由器转发的网络,校园网好像还有些问题)。
1.安装抓包工具Fiddler,并进行配置
Tools>>options>>connections>>勾选allow remote computers to connect
2.查看本机IP
在cmd窗口(win+R快捷键),输入ipconfig,查看(以太网)IP地址。
3.配置手机端。
手机连网后(和电脑端同一局域网),打开手机浏览器并访问:http://ip:8888(ip是你第二步查看到的IP地址, 8888端口是Fiddler默认端口),
有些浏览器打不开网页,换一下浏览器就行。
如果访问成功,会出现一个网页:
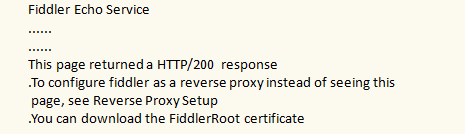
4.下载证书
点击FiddlerRoot certificate,下载证书。如果不下载证书的话,只能抓到http请求,抓不到https请求。
5.安装证书
部分手机可以直接点击安装
部分手机需要通过:
设置>>wifi(或WLAN)>>高级设置>>安装证书>>选中下载好的FiddlerRoot.cer>>确定
或:
设置>>更多设置>>系统安全>>从存储设备安装
安装后,可以按照自己的意愿,给证书起一个名字,例如Fiddler,确定后会显示安装完成!
6.设置手机代理

手机设置代理后,打开Fiddler,接下来在手机端打开app或者浏览器,所有通过手机发送的请求都会被Fiddler抓取。
scrapy框架下载图片
Scrapy用ImagesPipeline类提供一种方便的方式下载和存储图片(需要PIL库支持)。
主要特征:
- 将下载图片转化为通用的jpg和rgb格式
- 避免重复下载
- 缩略图生成
- 图片大小过滤
工作流程:
- 抓取一个item,将图片的urls放入image_urls字段
- 从Spider返回的item,传递到 Item Pipeline
- 当Item传递到ImagePipeline,将调用scrapy调度器和下载器完成image_urls中的url调度和下载。ImagePipeline会自动高优先级抓取这些url,同时,item会被锁定直到图片抓取完毕才解锁
- 图片下载成功后,图片下载路径,url和校验信息等会被填充到images字段中
scrapy抓取斗鱼主播图像
ImagePipeline简介
首先介绍一下图片下载中的ImagePipeline类中的两个重要方法。在自定义的ImagePipeline类中要重写:
get_media_requests(item, info)和item_completed(results, items, info);其中,正如工作流所述,Pipeline从item中获取图片的urls并下载,
所以必须重载get_media_requests,并返回一个Request对象,这些请求对象将被pipelines处理
下载完成后,结果发送发哦item_complete方法,下载结果为一个二元组的list, 每个元组包含:
(success, image_info_or_failure),其中:
success: bool值,true表示下载成功
image_info_or_error: 如果success为True,则该字典包含以下键值对:{path:本地存储路径, checksum:校验码}
分析及编码
通过Fiddler抓包工具分析,请求连接为:http://capi.douyucdn.cn/api/v1/getVerticalRoom?limit=20&offset=0,其中
offset为变量,每次翻页增加20。
首先,使用命令创建项目
scrapy startproject Douyu
来到items.py文件,编写需要抓取的字段如下:
# -*- coding: utf-8 -*- import scrapy class DouyuItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field() # 图片链接
image_link = scrapy.Field() # 图片保存路径
image_path = scrapy.Field() # 主播名
nick_name = scrapy.Field() # 房间号
room_id = scrapy.Field() # 所在城市
city = scrapy.Field() # 数据源
source = scrapy.Field()
明确抓取目标后,生成爬虫,开始编写爬虫逻辑
scrapy genspider douyu douyucdn.com # 生成爬虫
编写爬虫逻辑之前,在下载中间件中,给每个请求添加头部信息:
# -*- coding: utf-8 -*- # Define here the models for your spider middleware
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/spider-middleware.html from scrapy import signals
from Douyu.settings import USER_AGENTS as ua
import random class DouyuSpiderMiddleware(object):
def process_request(self, request, spider):
"""
给每一个请求随机分配一个代理
:param request:
:param spider:
:return:
"""
user_agent = random.choice(ua)
request.headers['User-Agent'] = user_agent
然后来到spiders文件夹下的爬虫文件,开始编写爬虫逻辑:
# -*- coding: utf-8 -*-
import json
import scrapy
from Douyu.items import DouyuItem class DouyuSpider(scrapy.Spider):
name = 'douyu'
allowed_domains = ['douyucdn.cn'] offset = 0 # 请求url
base_url = "http://capi.douyucdn.cn/api/v1/getVerticalRoom?limit=20&offset="
start_urls = [base_url + str(offset)] def parse(self, response): # 手机端斗鱼返回的是json格式的数据,所有数据都在data中
# 直接从请求响应体中获取数据
node_list = json.loads(response.body)['data'] # 如果拿不到数据,说明已经爬取完所有翻页
if not node_list:
return # 对具体数据进行解析
for node in node_list: # 数据保存
item = DouyuItem()
item['image_link'] = node['vertical_src']
item['nick_name'] = node['nickname']
item['room_id'] = node['room_id']
item['city'] = node['anchor_city'] yield item # 实现翻页
self.offset += 20
yield scrapy.Request(self.base_url + str(self.offset), callback=self.parse)
编写完爬虫逻辑后,可以开始编写图片下载逻辑了,来到pipelines文件:
# -*- coding: utf-8 -*-
import os
import scrapy # scrapy下载图片专用管道
from scrapy.pipelines.images import ImagesPipeline
# 在setting中指定图片存储路径
from Douyu.settings import IMAGES_STORE class ImageSourcePipeline(object): # 添加数据源
def process_item(self, item, spider):
item['source'] = spider.name
return item class DouyuImagePipeline(ImagesPipeline): # 发送图片链接请求
def get_media_requests(self, item, info):
# 获取item数据的图片链接
image_link = item['image_link'] # 发送图片请求,响应会保存在settings中指定的路径下(IMAGES_STORE)
try:
yield scrapy.Request(url=image_link)
except:
print(image_link) def item_completed(self, results, item, info):
"""
:param results: 下载图片结果,包含一个二元组(下载状态,图片路径)
:param item:
:param info:
:return:
"""
# 取出每个图片的原本路径
# path为设定的图片存储路径
image_path = [x['path'] for ok, x in results if ok] # 默认保存当前图片的路径
old_name = IMAGES_STORE + '\\' + image_path[0] # 新建当前图片路径,因为默认路径有一些不需要的东西
new_name = IMAGES_STORE + '\\'+item['nick_name'] + '.jpg' item['image_path'] = new_name
try:
# 将原本路径的图片名,修改为新建的图片名
os.rename(old_name, new_name)
except:
print("INFO:图片更名错误!") return item
整体逻辑编写完成,在settings文件中分别打开中间件、管道等的注释信息,即可运行爬虫!
运行结果:
完整代码
参见:https://github.com/zInPython/Douyu
scrapy抓取斗鱼APP主播信息的更多相关文章
- scrapy抓取拉勾网职位信息(一)——scrapy初识及lagou爬虫项目建立
本次以scrapy抓取拉勾网职位信息作为scrapy学习的一个实战演练 python版本:3.7.1 框架:scrapy(pip直接安装可能会报错,如果是vc++环境不满足,建议直接安装一个visua ...
- scrapy自动抓取蛋壳公寓最新房源信息并存入sql数据库
利用scrapy抓取蛋壳公寓上的房源信息,以北京市为例,目标url:https://www.dankegongyu.com/room/bj 思路分析 每次更新最新消息,都是在第一页上显示,因此考虑隔一 ...
- scrapy抓取淘宝女郎
scrapy抓取淘宝女郎 准备工作 首先在淘宝女郎的首页这里查看,当然想要爬取更多的话,当然这里要查看翻页的url,不过这操蛋的地方就是这里的翻页是使用javascript加载的,这个就有点尴尬了,找 ...
- 分布式爬虫:使用Scrapy抓取数据
分布式爬虫:使用Scrapy抓取数据 Scrapy是Python开发的一个快速,高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据.Scrapy用途广泛,可以用于数据挖掘. ...
- 通过Scrapy抓取QQ空间
毕业设计题目就是用Scrapy抓取QQ空间的数据,最近毕业设计弄完了,来总结以下: 首先是模拟登录的问题: 由于Tencent对模拟登录比较讨厌,各个防备,而本人能力有限,所以做的最简单的,手动登录后 ...
- python scrapy 抓取脚本之家文章(scrapy 入门使用简介)
老早之前就听说过python的scrapy.这是一个分布式爬虫的框架,可以让你轻松写出高性能的分布式异步爬虫.使用框架的最大好处当然就是不同重复造轮子了,因为有很多东西框架当中都有了,直接拿过来使用就 ...
- Fiddler高级用法-抓取手机app数据包
在上一篇中介绍了Fiddler的基本使用方法.通过上一篇的操作我们可以直接抓取浏览器的数据包.但在APP测试中,我们需要抓取手机APP上的数据包,应该怎么操作呢? Andriod配置方法 1)确保手机 ...
- 利用scrapy爬取腾讯的招聘信息
利用scrapy框架抓取腾讯的招聘信息,爬取地址为:https://hr.tencent.com/position.php 抓取字段包括:招聘岗位,人数,工作地点,发布时间,及具体的工作要求和工作任务 ...
- scrapy抓取中国新闻网新闻
目标说明 利用scrapy抓取中新网新闻,关于自然灾害滑坡的全部国内新闻:要求主题为滑坡类新闻,包含灾害造成的经济损失等相关内容,并结合textrank算法,得到每篇新闻的关键词,便于后续文本挖掘分析 ...
随机推荐
- 最强中文NLP预训练模型艾尼ERNIE官方揭秘【附视频】
“最近刚好在用ERNIE写毕业论文” “感觉还挺厉害的” “为什么叫ERNIE啊,这名字有什么深意吗?” “我想让艾尼帮我写作业” 看了上面火热的讨论,你一定很好奇“艾尼”.“ERNIE”到底是个啥? ...
- 二:Mysql库相关操作
1:系统数据库 information_schema: 虚拟库,不占用磁盘空间,存储的是数据库启动后的一些参数,如用户表信息.列信息.权限信息.字符信息等.performance_schema: My ...
- 【Auto.js images.matchTemplate() 函数的特点】
Auto.js images.matchTemplate() 函数的特点 官方文档:https://hyb1996.github.io/AutoJs-Docs/#/images?id=imagesm ...
- Shiro笔记---授权
1.搭建shiro环境(*) idea2018.2.maven3.5.4.jdk1.8 项目结构: pom.xml: <?xml version="1.0" encoding ...
- VMware问题--无法获得 VMCI 驱动程序的版本: 句柄无效
关于VMware问题:无法获得 VMCI 驱动程序的版本: 句柄无效.驱动程序“vmci.sys”的版本不正确 问题截图: 解决 1.根据配置文件路径找到对应的.vmx文件: 2.用编辑器打开,找到v ...
- 关于ReentrantLock 中的lockInterruptibly方法的简单探究
今天在看Lock,都知道相比于synchronized,多了公平锁,可中断等优秀性能. 但是说到可中断这个特点,看到很多博客是这么描述的: “与synchronized关键字不同,获取到锁的线程能够响 ...
- Luogu P1816 忠诚
rmq模板题.用st表切一个. 关于st表的详解见我的博客:st表.树状数组与线段树 笔记与思路整理 题目描述 老管家是一个聪明能干的人.他为财主工作了整整10年,财主为了让自已账目更加清楚.要求管家 ...
- 等距结点下的Newton插值多项式系数计算(向前差分)
插值多项式的牛顿法 1.为何需要牛顿法? 使用Lagrange插值法不具备继承性.当求好经过\(({x_0},{y_0})-({x_n},{y_n})\)共n+1个点的插值曲线时候,如果再增加一个 ...
- Zabbix 四 主动模式
本次的主机192.168.131.8 被动模式. 将zabbix4.4.4的源码包放过去,解压安装依赖准备编译安装,并创建zabbix账户. tar -xf zabbix-4.4.0.tar.gz & ...
- 8*8LED点阵
基础认识 1.5英寸LED点阵管数码管8*8红色16pin 有如下两种型号: 共阳1588BS 共阴1588AS 共阴1588AS 共阳1588BS 编程导向 共阴和共阳其编程思路基本类似,只是对应I ...