RocketMQ一个新的消费组初次启动时从何处开始消费呢?
@
1、抛出问题
一个新的消费组订阅一个已存在的Topic主题时,消费组是从该Topic的哪条消息开始消费呢?
首先翻阅DefaultMQPushConsumer的API时,setConsumeFromWhere(ConsumeFromWhere consumeFromWhere)API映入眼帘,从字面意思来看是设置消费者从哪里开始消费,正是解开该问题的”钥匙“。ConsumeFromWhere枚举类图如下:

- CONSUME_FROM_MAX_OFFSET
从消费队列最大的偏移量开始消费。 - CONSUME_FROM_FIRST_OFFSET
从消费队列最小偏移量开始消费。 - CONSUME_FROM_TIMESTAMP
从指定的时间戳开始消费,默认为消费者启动之前的30分钟处开始消费。可以通过DefaultMQPushConsumer#setConsumeTimestamp。
是不是点小激动,还不快试试。
需求:新的消费组启动时,从队列最后开始消费,即只消费启动后发送到消息服务器后的最新消息。
1.1 环境准备
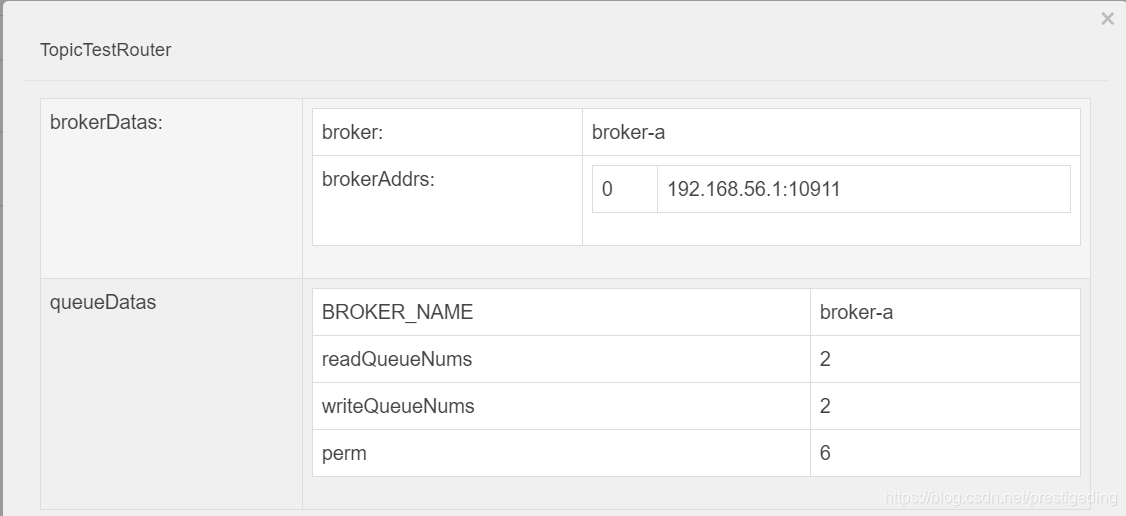
本示例所用到的Topic路由信息如下:
Broker的配置如下(broker.conf)
brokerClusterName = DefaultCluster
brokerName = broker-a
brokerId = 0
deleteWhen = 04
fileReservedTime = 48
brokerRole = ASYNC_MASTER
flushDiskType = ASYNC_FLUSH
storePathRootDir=E:/SH2019/tmp/rocketmq_home/rocketmq4.5_simple/store
storePathCommitLog=E:/SH2019/tmp/rocketmq_home/rocketmq4.5_simple/store/commitlog
namesrvAddr=127.0.0.1:9876
autoCreateTopicEnable=false
mapedFileSizeCommitLog=10240
mapedFileSizeConsumeQueue=2000
其中重点修改了如下两个参数:
- mapedFileSizeCommitLog
单个commitlog文件的大小,这里使用10M,方便测试用。 - mapedFileSizeConsumeQueue
单个consumequeue队列长度,这里使用1000,表示一个consumequeue文件中包含1000个条目。
1.2 消息发送者代码
public static void main(String[] args) throws MQClientException, InterruptedException {
DefaultMQProducer producer = new DefaultMQProducer("please_rename_unique_group_name");
producer.setNamesrvAddr("127.0.0.1:9876");
producer.start();
for (int i = 0; i < 300; i++) {
try {
Message msg = new Message("TopicTest" ,"TagA" , ("Hello RocketMQ " + i).getBytes(RemotingHelper.DEFAULT_CHARSET));
SendResult sendResult = producer.send(msg);
System.out.printf("%s%n", sendResult);
} catch (Exception e) {
e.printStackTrace();
Thread.sleep(1000);
}
}
producer.shutdown();
}
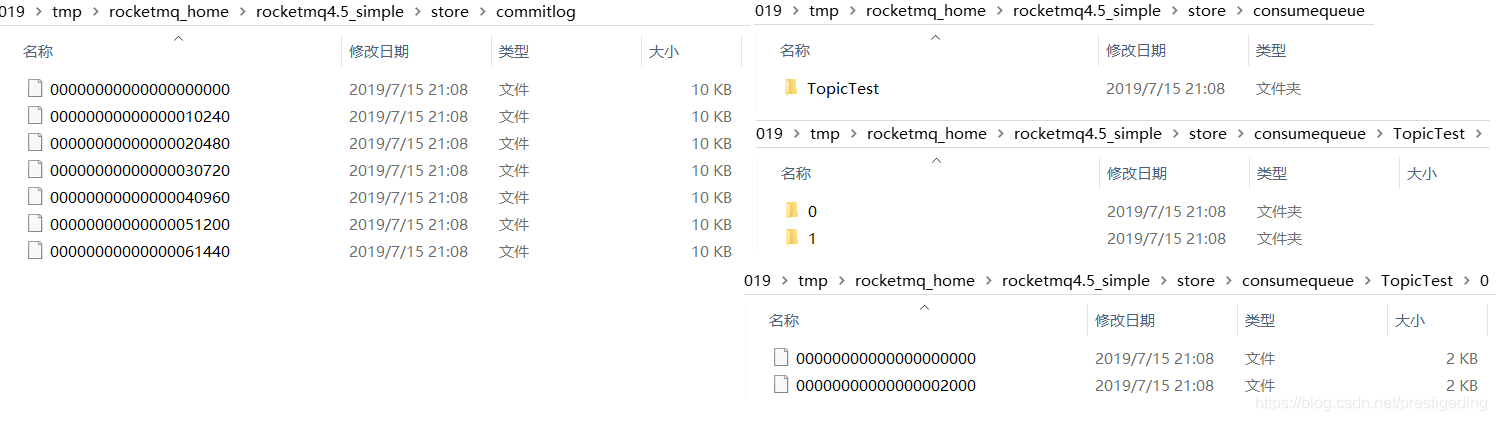
通过上述,往TopicTest发送300条消息,发送完毕后,RocketMQ Broker存储结构如下:
1.3 消费端验证代码
public static void main(String[] args) throws InterruptedException, MQClientException {
DefaultMQPushConsumer consumer = new DefaultMQPushConsumer("my_consumer_01");
consumer.setConsumeFromWhere(ConsumeFromWhere.CONSUME_FROM_LAST_OFFSET);
consumer.subscribe("TopicTest", "*");
consumer.setNamesrvAddr("127.0.0.1:9876");
consumer.registerMessageListener(new MessageListenerConcurrently() {
@Override
public ConsumeConcurrentlyStatus consumeMessage(List<MessageExt> msgs,
ConsumeConcurrentlyContext context) {
System.out.printf("%s Receive New Messages: %s %n", Thread.currentThread().getName(), msgs);
return ConsumeConcurrentlyStatus.CONSUME_SUCCESS;
}
});
consumer.start();
System.out.printf("Consumer Started.%n");
}
执行上述代码后,按照期望,应该是不会消费任何消息,只有等生产者再发送消息后,才会对消息进行消费,事实是这样吗?执行效果如图所示:
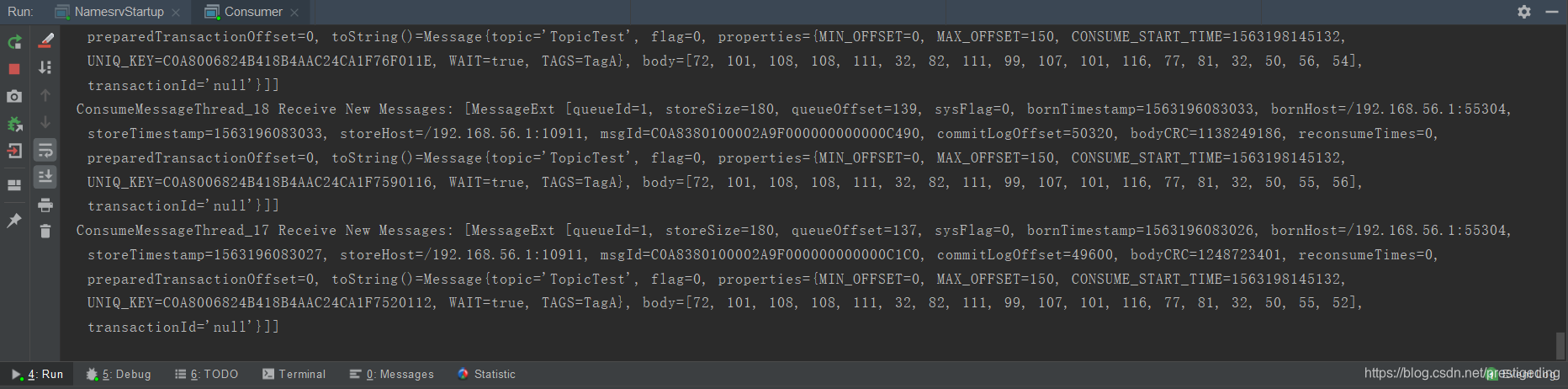
令人意外的是,竟然从队列的最小偏移量开始消费了,这就“尴尬”了。难不成是RocketMQ的Bug。带着这个疑问,从源码的角度尝试来解读该问题,并指导我们实践。
2、探究CONSUME_FROM_MAX_OFFSET实现原理
对于一个新的消费组,无论是集群模式还是广播模式都不会存储该消费组的消费进度,可以理解为-1,此时就需要根据DefaultMQPushConsumer#consumeFromWhere属性来决定其从何处开始消费,首先我们需要找到其对应的处理入口。我们知道,消息消费者从Broker服务器拉取消息时,需要进行消费队列的负载,即RebalanceImpl。
温馨提示:本文不会详细介绍RocketMQ消息队列负载、消息拉取、消息消费逻辑,只会展示出通往该问题的简短流程,如想详细了解消息消费具体细节,建议购买笔者出版的《RocketMQ技术内幕》书籍。
RebalancePushImpl#computePullFromWhere
public long computePullFromWhere(MessageQueue mq) {
long result = -1; // @1
final ConsumeFromWhere consumeFromWhere = this.defaultMQPushConsumerImpl.getDefaultMQPushConsumer().getConsumeFromWhere();
final OffsetStore offsetStore = this.defaultMQPushConsumerImpl.getOffsetStore();
switch (consumeFromWhere) {
case CONSUME_FROM_LAST_OFFSET_AND_FROM_MIN_WHEN_BOOT_FIRST:
case CONSUME_FROM_MIN_OFFSET:
case CONSUME_FROM_MAX_OFFSET:
case CONSUME_FROM_LAST_OFFSET: { // @2
// 省略部分代码
break;
}
case CONSUME_FROM_FIRST_OFFSET: { // @3
// 省略部分代码
break;
}
case CONSUME_FROM_TIMESTAMP: { //@4
// 省略部分代码
break;
}
default:
break;
}
return result; // @5
}
代码@1:先解释几个局部变量。
- result
最终的返回结果,默认为-1。 - consumeFromWhere
消息消费者开始消费的策略,即CONSUME_FROM_LAST_OFFSET等。 - offsetStore
offset存储器,消费组消息偏移量存储实现器。
代码@2:CONSUME_FROM_LAST_OFFSET(从队列的最大偏移量开始消费)的处理逻辑,下文会详细介绍。
代码@3:CONSUME_FROM_FIRST_OFFSET(从队列最小偏移量开始消费)的处理逻辑,下文会详细介绍。
代码@4:CONSUME_FROM_TIMESTAMP(从指定时间戳开始消费)的处理逻辑,下文会详细介绍。
代码@5:返回最后计算的偏移量,从该偏移量出开始消费。
2.1 CONSUME_FROM_LAST_OFFSET计算逻辑
case CONSUME_FROM_LAST_OFFSET: {
long lastOffset = offsetStore.readOffset(mq, ReadOffsetType.READ_FROM_STORE); // @1
if (lastOffset >= 0) { // @2
result = lastOffset;
}
// First start,no offset
else if (-1 == lastOffset) { // @3
if (mq.getTopic().startsWith(MixAll.RETRY_GROUP_TOPIC_PREFIX)) {
result = 0L;
} else {
try {
result = this.mQClientFactory.getMQAdminImpl().maxOffset(mq);
} catch (MQClientException e) { // @4
result = -1;
}
}
} else {
result = -1;
}
break;
}
代码@1:使用offsetStore从消息消费进度文件中读取消费消费进度,本文将以集群模式为例展开。稍后详细分析。
代码@2:如果返回的偏移量大于等于0,则直接使用该offset,这个也能理解,大于等于0,表示查询到有效的消息消费进度,从该有效进度开始消费,但我们要特别留意lastOffset为0是什么场景,因为返回0,并不会执行CONSUME_FROM_LAST_OFFSET(语义)。
代码@3:如果lastOffset为-1,表示当前并未存储其有效偏移量,可以理解为第一次消费,如果是消费组重试主题,从重试队列偏移量为0开始消费;如果是普通主题,则从队列当前的最大的有效偏移量开始消费,即CONSUME_FROM_LAST_OFFSET语义的实现。
代码@4:如果从远程服务拉取最大偏移量拉取异常或其他情况,则使用-1作为第一次拉取偏移量。
分析,上述执行的现象,虽然设置的是CONSUME_FROM_LAST_OFFSET,但现象是从队列的第一条消息开始消费,根据上述源码的分析,只有从消费组消费进度存储文件中取到的消息偏移量为0时,才会从第一条消息开始消费,故接下来重点分析消息消费进度存储器(OffsetStore)在什么情况下会返回0。
接下来我们将以集群模式来查看一下消息消费进度的查询逻辑,集群模式的消息进度存储管理器实现为:
RemoteBrokerOffsetStore,最终Broker端的命令处理类为:ConsumerManageProcessor。
ConsumerManageProcessor#queryConsumerOffset
private RemotingCommand queryConsumerOffset(ChannelHandlerContext ctx, RemotingCommand request) throws RemotingCommandException {
final RemotingCommand response =
RemotingCommand.createResponseCommand(QueryConsumerOffsetResponseHeader.class);
final QueryConsumerOffsetResponseHeader responseHeader =
(QueryConsumerOffsetResponseHeader) response.readCustomHeader();
final QueryConsumerOffsetRequestHeader requestHeader =
(QueryConsumerOffsetRequestHeader) request
.decodeCommandCustomHeader(QueryConsumerOffsetRequestHeader.class);
long offset =
this.brokerController.getConsumerOffsetManager().queryOffset(
requestHeader.getConsumerGroup(), requestHeader.getTopic(), requestHeader.getQueueId()); // @1
if (offset >= 0) { // @2
responseHeader.setOffset(offset);
response.setCode(ResponseCode.SUCCESS);
response.setRemark(null);
} else { // @3
long minOffset =
this.brokerController.getMessageStore().getMinOffsetInQueue(requestHeader.getTopic(),
requestHeader.getQueueId()); // @4
if (minOffset <= 0
&& !this.brokerController.getMessageStore().checkInDiskByConsumeOffset( // @5
requestHeader.getTopic(), requestHeader.getQueueId(), 0)) {
responseHeader.setOffset(0L);
response.setCode(ResponseCode.SUCCESS);
response.setRemark(null);
} else { // @6
response.setCode(ResponseCode.QUERY_NOT_FOUND);
response.setRemark("Not found, V3_0_6_SNAPSHOT maybe this group consumer boot first");
}
}
return response;
}
代码@1:从消费消息进度文件中查询消息消费进度。
代码@2:如果消息消费进度文件中存储该队列的消息进度,其返回的offset必然会大于等于0,则直接返回该偏移量该客户端,客户端从该偏移量开始消费。
代码@3:如果未从消息消费进度文件中查询到其进度,offset为-1。则首先获取该主题、消息队列当前在Broker服务器中的最小偏移量(@4)。如果小于等于0(返回0则表示该队列的文件还未曾删除过)并且其最小偏移量对应的消息存储在内存中而不是存在磁盘中,则返回偏移量0,这就意味着ConsumeFromWhere中定义的三种枚举类型都不会生效,直接从0开始消费,到这里就能解开其谜团了(@5)。
代码@6:如果偏移量小于等于0,但其消息已经存储在磁盘中,此时返回未找到,最终RebalancePushImpl#computePullFromWhere中得到的偏移量为-1。
看到这里,大家应该能回答文章开头处提到的问题了吧?
看到这里,大家应该明白了,为什么设置的CONSUME_FROM_LAST_OFFSET,但消费组是从消息队列的开始处消费了吧,原因就是消息消费进度文件中并没有找到其消息消费进度,并且该队列在Broker端的最小偏移量为0,说的更直白点,consumequeue/topicName/queueNum的第一个消息消费队列文件为00000000000000000000,并且消息其对应的消息缓存在Broker端的内存中(pageCache),其返回给消费端的偏移量为0,故会从0开始消费,而不是从队列的最大偏移量处开始消费。
为了知识体系的完备性,我们顺便来看一下其他两种策略的计算逻辑。
2.2 CONSUME_FROM_FIRST_OFFSET
case CONSUME_FROM_FIRST_OFFSET: {
long lastOffset = offsetStore.readOffset(mq, ReadOffsetType.READ_FROM_STORE); // @1
if (lastOffset >= 0) { // @2
result = lastOffset;
} else if (-1 == lastOffset) { // @3
result = 0L;
} else {
result = -1; // @4
}
break;
}
从队列的开始偏移量开始消费,其计算逻辑如下:
代码@1:首先通过偏移量存储器查询消费队列的消费进度。
代码@2:如果大于等于0,则从当前该偏移量开始消费。
代码@3:如果远程返回-1,表示并没有存储该队列的消息消费进度,从0开始。
代码@4:否则从-1开始消费。
2.4 CONSUME_FROM_TIMESTAMP
从指定时戳后的消息开始消费。
case CONSUME_FROM_TIMESTAMP: {
ong lastOffset = offsetStore.readOffset(mq, ReadOffsetType.READ_FROM_STORE); // @1
if (lastOffset >= 0) { // @2
result = lastOffset;
} else if (-1 == lastOffset) { // @3
if (mq.getTopic().startsWith(MixAll.RETRY_GROUP_TOPIC_PREFIX)) {
try {
result = this.mQClientFactory.getMQAdminImpl().maxOffset(mq);
} catch (MQClientException e) {
result = -1;
}
} else {
try {
long timestamp = UtilAll.parseDate(this.defaultMQPushConsumerImpl.getDefaultMQPushConsumer().getConsumeTimestamp(),
UtilAll.YYYYMMDDHHMMSS).getTime();
result = this.mQClientFactory.getMQAdminImpl().searchOffset(mq, timestamp);
} catch (MQClientException e) {
result = -1;
}
}
} else {
result = -1;
}
break;
}
其基本套路与CONSUME_FROM_LAST_OFFSET一样:
代码@1:首先通过偏移量存储器查询消费队列的消费进度。
代码@2:如果大于等于0,则从当前该偏移量开始消费。
代码@3:如果远程返回-1,表示并没有存储该队列的消息消费进度,如果是重试主题,则从当前队列的最大偏移量开始消费,如果是普通主题,则根据时间戳去Broker端查询,根据查询到的偏移量开始消费。
原理就介绍到这里,下面根据上述理论对其进行验证。
3、猜想与验证
根据上述理论分析我们得知设置CONSUME_FROM_LAST_OFFSET但并不是从消息队列的最大偏移量开始消费的“罪魁祸首”是因为消息消费队列的最小偏移量为0,如果不为0,则就会符合预期,我们来验证一下这个猜想。
首先我们删除commitlog目录下的文件,如图所示:
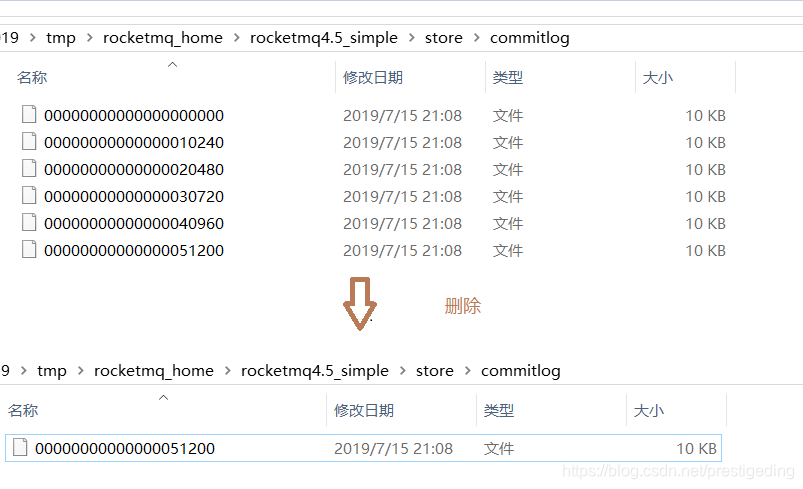
其消费队列截图如下:
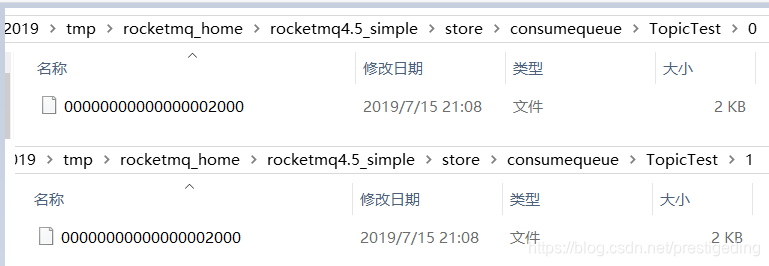
消费端的验证代码如下:
public static void main(String[] args) throws InterruptedException, MQClientException {
DefaultMQPushConsumer consumer = new DefaultMQPushConsumer("my_consumer_02");
consumer.setConsumeFromWhere(ConsumeFromWhere.CONSUME_FROM_LAST_OFFSET);
consumer.subscribe("TopicTest", "*");
consumer.setNamesrvAddr("127.0.0.1:9876");
consumer.registerMessageListener(new MessageListenerConcurrently() {
@Override
public ConsumeConcurrentlyStatus consumeMessage(List<MessageExt> msgs,
ConsumeConcurrentlyContext context) {
System.out.printf("%s Receive New Messages: %s %n", Thread.currentThread().getName(), msgs);
return ConsumeConcurrentlyStatus.CONSUME_SUCCESS;
}
});
consumer.start();
System.out.printf("Consumer Started.%n");
}
运行结果如下:
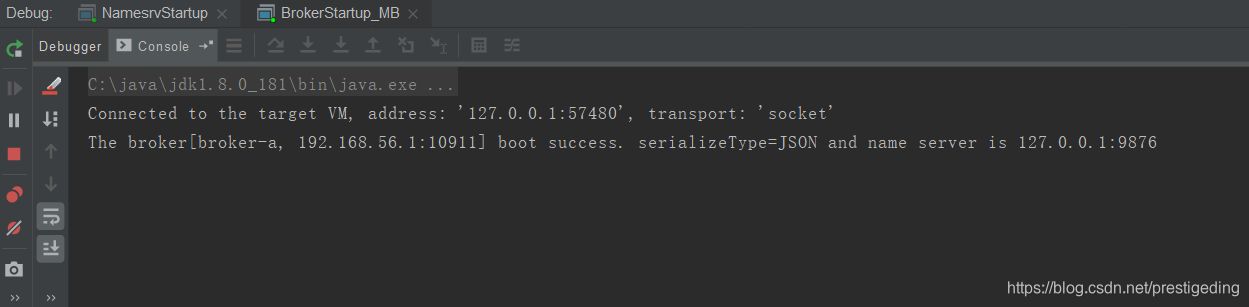
并没有消息存在的消息,符合预期。
4、解决方案
如果在生产环境下,一个新的消费组订阅一个已经存在比较久的topic,设置CONSUME_FROM_MAX_OFFSET是符合预期的,即该主题的consumequeue/{queueNum}/fileName,fileName通常不会是00000000000000000000,如是是上面文件名,想要实现从队列的最后开始消费,该如何做呢?那就走自动创建消费组的路子,执行如下命令:
./mqadmin updateSubGroup -n 127.0.0.1:9876 -c DefaultCluster -g my_consumer_05
//克隆一个订阅了该topic的消费组消费进度
./mqadmin cloneGroupOffset -n 127.0.0.1:9876 -s my_consumer_01 -d my_consumer_05 -t TopicTest
//重置消费进度到当前队列的最大值
./mqadmin resetOffsetByTime -n 127.0.0.1:9876 -g my_consumer_05 -t TopicTest -s -1
按照上上述命令后,即可实现其目的。
您都看到这里了,麻烦帮忙点个赞,谢谢您的认可与鼓励。
作者介绍:
丁威,《RocketMQ技术内幕》作者,RocketMQ 社区布道师,公众号:中间件兴趣圈 维护者,目前已陆续发表源码分析Java集合、Java 并发包(JUC)、Netty、Mycat、Dubbo、RocketMQ、Mybatis等源码专栏。欢迎加入我的知识星球,构建一个高质量的技术交流社群。

RocketMQ一个新的消费组初次启动时从何处开始消费呢?的更多相关文章
- 【IntelliJ IDEA】添加一个新的tomcat,tomcat启动无法访问欢迎页面,空白页,404
===================================第一部分,添加一个tomcat================================================== ...
- Kafka 0.11新功能介绍:空消费组延迟rebalance
Kafka 0.11新功能介绍:空消费组延迟rebalance 在0.11之前的版本中,多个consumer实例加入到一个空消费组将导致多次的rebalance,这是由于每个consumer inst ...
- Kafka 0.11版本新功能介绍 —— 空消费组延时rebalance
在0.11之前的版本中,多个consumer实例加入到一个空消费组将导致多次的rebalance,这是由于每个consumer instance启动的时间不可控,很有可能超出coordinator确定 ...
- 日志服务Python消费组实战(三):实时跨域监测多日志库数据
解决问题 使用日志服务进行数据处理与传递的过程中,你是否遇到如下监测场景不能很好的解决: 特定数据上传到日志服务中需要检查数据内的异常情况,而没有现成监控工具? 需要检索数据里面的关键字,但数据没有建 ...
- Kafka技术内幕 读书笔记之(五) 协调者——消费组状态机
协调者保存的消费组元数据中记录了消费组的状态机 , 消费组状态机的转换主要发生在“加入组请求”和“同步组请求”的处理过程中 .协调者处理“离开消费组请求”“迁移消费组请求”“心跳请求” “提交偏移量请 ...
- 日志服务Python消费组实战(二):实时分发数据
场景目标 使用日志服务的Web-tracking.logtail(文件极简).syslog等收集上来的日志经常存在各种各样的格式,我们需要针对特定的日志(例如topic)进行一定的分发到特定的logs ...
- linux基础命令--groupadd 创建新的群组
描述 groupadd命令用于创建一个新的群组. groupadd命令默认会根据命令行指定的值和系统下的/etc/login.defs文件定义的值去修改系统下的/etc/group和/etc/gsha ...
- 012.Adding a New Field --【添加一个新字段】
Adding a New Field 添加一个新字段 2016-10-14 3 分钟阅读时长 作者 By Rick Anderson In this section you'll use Entity ...
- 导入一个新项目需要注意的几大问题(jdk1.6+eclipse4.4+tomcat6)
今天导项目犯了一个很低级的错误,浪费了半个小时,所以在此罗列出在导一个新的项目到eclipse中时需要注意的几个问题,希望对大家有所帮助. 将项目从svn或者github等项目版本控制软件上拷贝下来, ...
随机推荐
- StopWatch任务计时器
介 绍: StopWatch 是用来计算程序块的执行时间工具, 目前有好多框架都有实现提供此工具(实现结果都区别不大), 本文介绍org.springframework.util.StopWatc ...
- Redis(十)集群:Redis Cluster
一.数据分布 1.数据分布理论 2.Redis数据分区 Redis Cluser采用虚拟槽分区,所有的键根据哈希函数映射到0~16383整数槽内,计算公式:slot=CRC16(key)&16 ...
- django-HttpResponse,render,redirect
1.导入相应的包 from django.shortcuts import HttpResponse, render, redirect 2.HttpResponse(返回字符串给浏览器) def i ...
- app消息推送
Mui + 个推 实现消息推送 1.首先去个推 注册一个账号,新建一个消息推送应用 2.配置Mui配置文件 3.使用HBuilder 打包 app 4.然后在到个推后台 发送数据 后台Java代码(官 ...
- Bash shell类型
登录shell(需要密码) 正常通过某一个终端来登录,需要输入用户名和密码. 使用su - username 使用su -l username 非登录shell(不需要密码) su userna ...
- CSPS模拟 84
整场考试就一个字虚 真的啥也不会 T1 80很好打 可是100这鬼畜的数据范围...二分答案? 没做过蚯蚓跪..果然多刷题有好处.. 于是死在80分处 T2 56很好打 可是100这鬼畜....... ...
- NOIP模拟 1
NOIP模拟1,到现在时间已经比较长了.. 那天是6.14,今天7.18了 //然鹅我看着最前边缺失的模拟1,还是终于忍不住把它补上,为了保持顺序2345重新发布了一遍.. # 用 户 名 ...
- 程序员学点xx 之 Redis
程序员学点xx 之 Redis 概述 其实程序员也要和操作系统打交道, 比如最常见的,部署自己电脑上的开发环境. 当然有时某些牛人, 觉得运维或基础部门的同事不够给力, 亲自上手部署服务器或线上环境, ...
- NOIP模拟赛 华容道 (搜索和最短路)蒟蒻的第一道紫题
题目描述 小 B 最近迷上了华容道,可是他总是要花很长的时间才能完成一次.于是,他想到用编程来完成华容道:给定一种局面, 华容道是否根本就无法完成,如果能完成, 最少需要多少时间. 小 B 玩的华容道 ...
- 201871010114-李岩松《面向对象程序设计(java)》第十二周学习总结
项目 内容 这个作业属于哪个课程 https://www.cnblogs.com/nwnu-daizh/ 这个作业的要求在哪里 https://www.cnblogs.com/nwnu-daizh/p ...