排序算法| Array.sort()算法规则
1、js的Array.sort()是使用什么算法排序;
1、火狐中是“归并排序”
2、V8引擎是 “插入排序和快速排序结合”。数组长度不超过10时,使用插入排序。长度超过10使用快速排序。在数组较短时插入排序更有效率。
2、各种算法
下图来自文章 各种排序实现以及稳定性分析
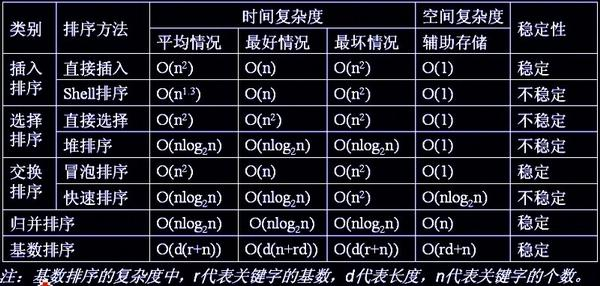
归并排序:
最好情况:O(nlogn)
最坏情况:O(nlogn)
平均情况:O(nlogn) 归并排序需要一个与原数组相同长度的数组做辅助来排序
空间复杂度:O(n)
稳定性:稳定(归并排序是稳定的排序算法,temp[i++] = arr[p1] <= arr[p2] ? arr[p1++] : arr[p2++];这行代码可以保证当左右两部分的值相等的时候,先复制左边的值,这样可以保证值相等的时候两个元素的相对位置不变。)
冒泡排序
优点:比较简单,空间复杂度较低,是稳定的;
缺点:时间复杂度太高,效率慢;
选择排序
优点:一轮比较只需要换一次位置;
缺点:效率慢,不稳定(举个例子5,8,5,2,9 我们知道第一遍选择第一个元素5会和2交换,那么原序列中2个5的相对位置前后顺序就破坏了)。
插入排序
1、插入排序不适合对于数据量比较大的排序应用。
2、时间复杂度最好为o(n) 最坏为(n^2) 平均为o(n^2) 空间复杂度为o(1) 稳定
3、如果想把n个元素的序列升序排列,那么采用插入排序存在最好情况和最坏情况。最好情况就是,序列已经是升序排列了,在这种情况下,需要进行的比较操作需(n-1)次即可。最坏情况就是,序列是降序排列,那么此时需要进行的比较共有n(n-1)/2次。插入排序的赋值操作是比较操作的次数加上 (n-1)次。平均来说插入排序算法的时间复杂度为O(n^2)。
4、当n较大时,时间复杂度太大,因此插入排序的不适合大数据量的排序,一般来说适合小数据量排序,如n<1000,插入排序也作为快排的补充,v8中当n<10时,使用插排,否则使用快排。
快速排序
快速排序既不浪费空间速度又快,但不稳定
快速排序是通过一轮的排序将序列分割成独立的两部分,其中一部分序列的基准点(这里主要用值来表示)均比另一部分基准点小。继续对长度较短的序列进行同样的分割,最后到达整体有序。在排序过程中,由于已经分开的两部分的元素不需要进行比较,故减少了比较次数,降低了排序时间。
其他文章总结
三个基本排序算法执行效率比较(冒泡排序,选择排序和插入排序)
从测试结果得到下面的表格:
| Bubble | Selection | Insertion | Bubble/Selection | Bubble/Insertion | Selection/Insertion | |
| 1000 | 15 | 4 | 3 | 3.75 | 5 | 1.333333333 |
| 10000 | 1342 | 412 | 283 | 3.257281553 | 4.74204947 | 1.455830389 |
| 100000 | 125212 | 40794 | 27570 | 3.069372947 | 4.541603192 | 1.479651795 |
| Avg | 3.358884833 | 4.761217554 | 1.422938506 |
忽略测试环境,因为三个算法都是在同一个环境中跑的, 可以得出如下结论:
1.冒泡算法效率最低。
2.插入算法效率最高。
3.选择算法是冒泡算法的3.3倍。
4.插入算法是冒泡算法的4.7倍。
5.插入算法是选择算法的1.4陪。
https://blog.csdn.net/wqf363/article/details/1604458?utm_source=blogxgwz8
排序算法| Array.sort()算法规则的更多相关文章
- 6种字符串数组的java排序 (String array sort)
注意,本文不是字符串排序,是字符串数组的排序. 方法分别是: 1.低位优先键索引排序 2.高位优先建索引排序 3.Java自带排序(经过调优的归并排序) 4.冒泡排序 5.快速排序 6.三向快速排序 ...
- “漂亮的”排序算法 Stooge Sort 如何完成排序
Stooge Sort 是一种低效的递归排序算法,甚至慢于冒泡排序.在<算法导论>第二版第7章(快速排序)的思考题中被提到,是由Howard.Fine等教授提出的所谓“漂亮的”排序算法. ...
- 排序算法六:计数排序(Counting sort)
前面介绍的几种排序算法,都是基于不同位置的元素比较,算法平均时间复杂度理论最好值是θ(nlgn). 今天介绍一种新的排序算法,计数排序(Counting sort),计数排序是一个非基于比较的线性时间 ...
- 【算法】桶排序(Bucket Sort)(九)
桶排序(Bucket Sort) 桶排序是计数排序的升级版.它利用了函数的映射关系,高效与否的关键就在于这个映射函数的确定.桶排序 (Bucket sort)的工作的原理:假设输入数据服从均匀分布,将 ...
- 【算法】计数排序(Counting Sort)(八)
计数排序(Counting Sort) 计数排序不是基于比较的排序算法,其核心在于将输入的数据值转化为键存储在额外开辟的数组空间中. 作为一种线性时间复杂度的排序,计数排序要求输入的数据必须是有确定范 ...
- 算法----希尔排序(shell sort)
在分析插入排序(插入排序算法实现)的算法性能的过程时知道.当数组规模较小或者存在较多的有序子序列时.插入排序将会在非常短的时间内完毕数组的排序,为此能够设计一个单调序列h[n],将数组分为多个小的序列 ...
- 算法----选择排序(select sort)
排序不是一个时间的数组进行排序,找到最小的元素,其与阵列的第一个元素交换,因此,排序的数组. 算法: void sort::select_sort(int* a,const int n) { for( ...
- 《算法4》2.1 - 选择排序算法(Selection Sort), Python实现
选择排序算法(Selection Sort)是排序算法的一种初级算法.虽然比较简单,但是基础,理解了有助于后面学习更高深算法,勿以勿小而不为. 排序算法的语言描述: 给定一组物体,根据他们的某种可量化 ...
- Python排序算法——希尔排序(Shell’s Sort)
有趣的事,Python永远不会缺席! 如需转发,请注明出处:小婷儿的python https://www.cnblogs.com/xxtalhr/p/10793487.html 一.希尔排序(Shel ...
随机推荐
- ES中index和type区分
参考: https://bayescafe.com/database/elasticsearch-using-index-or-type.html https://www.cnblogs.com/hu ...
- Java中"或"运算与"与"运算快慢的三三两两
先上结论 模运算比与运算慢20%到30% 这是通过实验的方式得到的结论.因为没有大大可以进行明确指导,所以我以最终运行的结果为准.欢迎指正. 测试代码 @Test public void test10 ...
- 性能调优 -- Java编程中的性能优化
String作为我们使用最频繁的一种对象类型,其性能问题是最容易被忽略的.作为Java中重要的数据类型,是内存中占据空间比较大的一个对象.如何高效地使用字符串,可以帮助我们提升系统的整体性能. 现在, ...
- SQLserver、MySQL、ORCAL查询数据库、表、表中字段以及字段类型
一.SQLServer命令 1.查询SQLServer中的每个数据库 SELECT * from sysdatabases 2.查询SQLServer中指定数据库的所有表名 select name f ...
- phpstudy漏洞检测
后门检测脚本 # !/usr/bin/env python # -*- coding:utf-8 -*- import gevent from gevent import monkey gevent. ...
- Android 网络交互之移动端与服务端的加密处理
在开发项目的网络模块时,我们为了保证客户端(Client)和服务端(Server)之间的通信安全,我们会对数据进行加密. 谈到网络通信加密,我们可以说出:对称加密,非对称加密,md5单向加密,也能提到 ...
- 从0系统学Android--3.6 RecyclerView
从0系统学Android--更强大的滚动控件---RecyclerView 本系列文章目录:更多精品文章分类 本系列持续更新中.... 参考<第一行代码> 首先说明一点昨天发了一篇关于 L ...
- SQL Server通过条件搜索获取相关的存储过程等对象
在SQL Server中,我们经常遇到一些需求,需要去搜索存储过程(Procedure).函数(Function)等对象是否包含某个对象或涉及某个对象,例如,我需要查找那些存储过程.函数是否调用了链接 ...
- spring @Transaction事务回滚失败
今天客户提出一个新问题,出库一批商品,提示失败了,但是库存数量却减少了.看了一下代码一头雾水,我们的代码加了事物,且捕获异常. 经过调试代码发现就是两个原因导致的 第一.在当前方法的catch中处理了 ...
- leetcode动态规划--基础题
跳跃游戏 给定一个非负整数数组,你最初位于数组的第一个位置. 数组中的每个元素代表你在该位置可以跳跃的最大长度. 判断你是否能够到达最后一个位置. 思路 根据题目意思,最大跳跃距离,说明可以跳0--n ...