LINUX内核CPU负载均衡机制【转】
转自:http://oenhan.com/cpu-load-balance
还是神奇的进程调度问题引发的,参看Linux进程组调度机制分析,组调度机制是看清楚了,发现在重启过程中,很多内核调用栈阻塞在了double_rq_lock函数上,而double_rq_lock则是load_balance触发的,怀疑当时的核间调度出现了问题,在某个负责场景下产生了多核互锁,后面看了一下CPU负载平衡下的代码实现,写一下总结。
内核代码版本:kernel-3.0.13-0.27。
内核代码函数起自load_balance函数,从load_balance函数看引用它的函数可以一直找到schedule函数这里,便从这里开始往下看,在__schedule中有下面一句话。
|
1
2
|
if (unlikely(!rq->nr_running))
idle_balance(cpu, rq);
|
从上面可以看出什么时候内核会尝试进行CPU负载平衡:即当前CPU运行队列为NULL的时候。
CPU负载平衡有两种方式:pull和push,即空闲CPU从其他忙的CPU队列中拉一个进程到当前CPU队列;或者忙的CPU队列将一个进程推送到空闲的CPU队列中。idle_balance干的则是pull的事情,具体push下面会提到。
在idle_balance里面,有一个proc阀门控制当前CPU是否pull:
|
1
2
|
if (this_rq->avg_idle < sysctl_sched_migration_cost)
return;
|
sysctl_sched_migration_cost对应proc控制文件是/proc/sys/kernel/sched_migration_cost,开关代表如果CPU队列空闲了500us(sysctl_sched_migration_cost默认值)以上,则进行pull,否则则返回。
for_each_domain(this_cpu, sd) 则是遍历当前CPU所在的调度域,可以直观的理解成一个CPU组,类似task_group,核间平衡指组内的平衡。负载平衡有一个矛盾就是:负载平衡的频度和CPU cache的命中率是矛盾的,CPU调度域就是将各个CPU分成层次不同的组,低层次搞定的平衡就绝不上升到高层次处理,避免影响cache的命中率。
图例如下;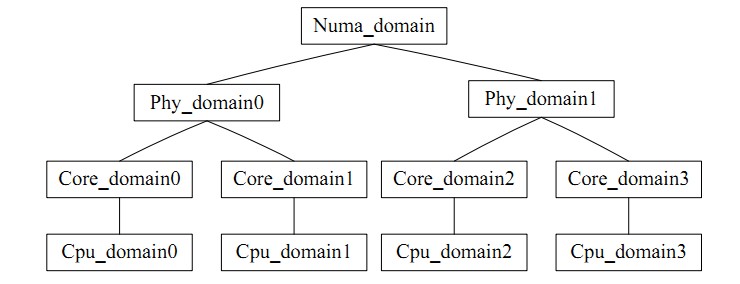
最终通过load_balance进入正题。
首先通过find_busiest_group获取当前调度域中的最忙的调度组,首先update_sd_lb_stats更新sd的状态,也就是遍历对应的sd,将sds里面的结构体数据填满,如下:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
struct sd_lb_stats {
struct sched_group *busiest; /* Busiest group in this sd */
struct sched_group *this; /* Local group in this sd */
unsigned long total_load; /* Total load of all groups in sd */
unsigned long total_pwr; /* Total power of all groups in sd */
unsigned long avg_load; /* Average load across all groups in sd */
/** Statistics of this group */
unsigned long this_load; //当前调度组的负载
unsigned long this_load_per_task; //当前调度组的平均负载
unsigned long this_nr_running; //当前调度组内运行队列中进程的总数
unsigned long this_has_capacity;
unsigned int this_idle_cpus;
/* Statistics of the busiest group */
unsigned int busiest_idle_cpus;
unsigned long max_load; //最忙的组的负载量
unsigned long busiest_load_per_task; //最忙的组中平均每个任务的负载量
unsigned long busiest_nr_running; //最忙的组中所有运行队列中进程的个数
unsigned long busiest_group_capacity;
unsigned long busiest_has_capacity;
unsigned int busiest_group_weight;
|
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
do
{
local_group = cpumask_test_cpu(this_cpu, sched_group_cpus(sg));
if (local_group) {
//如果是当前CPU上的group,则进行赋值
sds->this_load = sgs.avg_load;
sds->this = sg;
sds->this_nr_running = sgs.sum_nr_running;
sds->this_load_per_task = sgs.sum_weighted_load;
sds->this_has_capacity = sgs.group_has_capacity;
sds->this_idle_cpus = sgs.idle_cpus;
} else if (update_sd_pick_busiest(sd, sds, sg, &sgs, this_cpu)) {
//在update_sd_pick_busiest判断当前sgs的是否超过了之前的最大值,如果是
//则将sgs值赋给sds
sds->max_load = sgs.avg_load;
sds->busiest = sg;
sds->busiest_nr_running = sgs.sum_nr_running;
sds->busiest_idle_cpus = sgs.idle_cpus;
sds->busiest_group_capacity = sgs.group_capacity;
sds->busiest_load_per_task = sgs.sum_weighted_load;
sds->busiest_has_capacity = sgs.group_has_capacity;
sds->busiest_group_weight = sgs.group_weight;
sds->group_imb = sgs.group_imb;
}
sg = sg->next;
} while (sg != sd->groups);
|
决定选择调度域中最忙的组的参照标准是该组内所有 CPU上负载(load) 的和, 找到组中找到忙的运行队列的参照标准是该CPU运行队列的长度, 即负载,并且 load 值越大就表示越忙。在平衡的过程中,通过比较当前队列与以前记录的busiest 的负载情况,及时更新这些变量,让 busiest 始终指向域内最忙的一组,以便于查找。
调度域的平均负载计算
|
1
2
3
|
sds.avg_load = (SCHED_POWER_SCALE * sds.total_load) / sds.total_pwr;
if (sds.this_load >= sds.avg_load)
goto out_balanced;
|
在比较负载大小的过程中, 当发现当前运行的CPU所在的组中busiest为空时,或者当前正在运行的 CPU队列就是最忙的时, 或者当前 CPU队列的负载不小于本组内的平均负载时,或者不平衡的额度不大时,都会返回 NULL 值,即组组之间不需要进行平衡;当最忙的组的负载小于该调度域的平均负载时,只需要进行小范围的负载平衡;当要转移的任务量小于每个进程的平均负载时,如此便拿到了最忙的调度组。
然后find_busiest_queue中找到最忙的调度队列,遍历该组中的所有 CPU 队列,经过依次比较各个队列的负载,找到最忙的那个队列。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
|
for_each_cpu(i, sched_group_cpus(group)) {
/*rq->cpu_power表示所在处理器的计算能力,在函式sched_init初始化时,会把这值设定为SCHED_LOAD_SCALE (=Nice 0的Load Weight=1024).并可透过函式update_cpu_power (in kernel/sched_fair.c)更新这个值.*/
unsigned long power = power_of(i);
unsigned long capacity = DIV_ROUND_CLOSEST(power,SCHED_POWER_SCALE);
unsigned long wl;
if (!cpumask_test_cpu(i, cpus))
continue;
rq = cpu_rq(i);
/*获取队列负载cpu_rq(cpu)->load.weight;*/
wl = weighted_cpuload(i);
/*
* When comparing with imbalance, use weighted_cpuload()
* which is not scaled with the cpu power.
*/
if (capacity && rq->nr_running == 1 && wl > imbalance)
continue;
/*
* For the load comparisons with the other cpu's, consider
* the weighted_cpuload() scaled with the cpu power, so that
* the load can be moved away from the cpu that is potentially
* running at a lower capacity.
*/
wl = (wl * SCHED_POWER_SCALE) / power;
if (wl > max_load) {
max_load = wl;
busiest = rq;
}
|
通过上面的计算,便拿到了最忙队列。
当busiest->nr_running运行数大于1的时候,进行pull操作,pull前对move_tasks,先进行double_rq_lock加锁处理。
|
1
2
3
4
|
double_rq_lock(this_rq, busiest);
ld_moved = move_tasks(this_rq, this_cpu, busiest,
imbalance, sd, idle, &all_pinned);
double_rq_unlock(this_rq, busiest);
|
move_tasks进程pull task是允许失败的,即move_tasks->balance_tasks,在此处,有sysctl_sched_nr_migrate开关控制进程迁移个数,对应proc的是/proc/sys/kernel/sched_nr_migrate。
下面有can_migrate_task函数检查选定的进程是否可以进行迁移,迁移失败的原因有3个,1.迁移的进程处于运行状态;2.进程被绑核了,不能迁移到目标CPU上;3.进程的cache仍然是hot,此处也是为了保证cache命中率。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
/*关于cache cold的情况下,如果迁移失败的个数太多,仍然进行迁移
* Aggressive migration if:
* 1) task is cache cold, or
* 2) too many balance attempts have failed.
*/
tsk_cache_hot = task_hot(p, rq->clock_task, sd);
if (!tsk_cache_hot ||
sd->nr_balance_failed > sd->cache_nice_tries) {
#ifdef CONFIG_SCHEDSTATS
if (tsk_cache_hot) {
schedstat_inc(sd, lb_hot_gained[idle]);
schedstat_inc(p, se.statistics.nr_forced_migrations);
}
#endif
return 1;
}
|
判断进程cache是否有效,判断条件,进程的运行的时间大于proc控制开关sysctl_sched_migration_cost,对应目录/proc/sys/kernel/sched_migration_cost_ns
|
1
2
3
4
5
6
7
|
static int
task_hot(struct task_struct *p, u64 now, struct sched_domain *sd)
{
s64 delta;
delta = now - p->se.exec_start;
return delta < (s64)sysctl_sched_migration_cost;
}
|
在load_balance中,move_tasks返回失败也就是ld_moved==0,其中sd->nr_balance_failed++对应can_migrate_task中的"too many balance attempts have failed",然后busiest->active_balance = 1设置,active_balance = 1。
|
1
2
3
4
5
|
if (active_balance)
//如果pull失败了,开始触发push操作
stop_one_cpu_nowait(cpu_of(busiest),
active_load_balance_cpu_stop, busiest,
&busiest->active_balance_work);
|
push整个触发操作代码机制比较绕,stop_one_cpu_nowait把active_load_balance_cpu_stop添加到cpu_stopper每CPU变量的任务队列里面,如下:
|
1
2
3
4
5
6
|
void stop_one_cpu_nowait(unsigned int cpu, cpu_stop_fn_t fn, void *arg,
struct cpu_stop_work *work_buf)
{
*work_buf = (struct cpu_stop_work){ .fn = fn, .arg = arg, };
cpu_stop_queue_work(&per_cpu(cpu_stopper, cpu), work_buf);
}
|
而cpu_stopper则是cpu_stop_init函数通过cpu_stop_cpu_callback创建的migration内核线程,触发任务队列调度。因为migration内核线程是绑定每个核心上的,进程迁移失败的1和3问题就可以通过push解决。active_load_balance_cpu_stop则调用move_one_task函数迁移指定的进程。
上面描述的则是整个pull和push的过程,需要补充的pull触发除了schedule后触发,还有scheduler_tick通过触发中断,调用run_rebalance_domains再调用rebalance_domains触发,不再细数。
|
1
2
3
4
|
void __init sched_init(void)
{
open_softirq(SCHED_SOFTIRQ, run_rebalance_domains);
}
|
链接为:http://oenhan.com/cpu-load-balance
LINUX内核CPU负载均衡机制【转】的更多相关文章
- octavia的实现与分析(一)·openstack负载均衡的现状与发展以及lvs,Nginx,Haproxy三种负载均衡机制的基本架构和对比
[负载均衡] 大量用户发起请求的情况下,服务器负载过高,导致部分请求无法被响应或者及时响应. 负载均衡根据一定的算法将请求分发到不同的后端,保证所有的请求都可以被正常的下发并返回. [主流实现-LVS ...
- openstack octavia的实现与分析(一)openstack负载均衡的现状与发展以及lvs,Nginx,Haproxy三种负载均衡机制的基本架构和对比
[负载均衡] 大量用户发起请求的情况下,服务器负载过高,导致部分请求无法被响应或者及时响应. 负载均衡根据一定的算法将请求分发到不同的后端,保证所有的请求都可以被正常的下发并返回. [主流实现-LVS ...
- LVS : Linux Virtual Server 负载均衡,集群,高并发,robust
1 LVS : Linux Virtual Server http://www.linuxvirtualserver.org/ http://www.linuxvirtualserver.org/zh ...
- LVS (Linux Virtual Server) 负载均衡
[大型网站技术实践]初级篇:借助LVS+Keepalived实现负载均衡 一.负载均衡:必不可少的基础手段 1.1 找更多的牛来拉车吧 当前大多数的互联网系统都使用了服务器集群技术,集群即将相同服 ...
- Azure的负载均衡机制
负载均衡一直是一个比较重要的议题,几乎所有的Azure案例或者场景都不可避免,鉴于经常有客户会问,所以笔者觉得有必要总结一下. Azure提供的负载均衡机制,按照功能,可以分为三种:Azure Loa ...
- nginx 健康检查和负载均衡机制分析
nginx 是优秀的反向代理服务器,这里主要讲它的健康检查和负载均衡机制,以及这种机制带来的问题.所谓健康检查,就是当后端出现问题(具体什么叫出现问题,依赖 于具体实现,各个实现定义不一样),不再往这 ...
- linux+nginx+tomcat负载均衡,实现session同步
linux+nginx+tomcat负载均衡,实现session同步 花了一个上午的时间研究nginx+tomcat的负载均衡测试,集群环境搭建比较顺利,但是session同步的问题折腾了几个小时才搞 ...
- 分析NGINX 健康检查和负载均衡机制
nginx 是优秀的反向代理服务器,这里主要讲它的健康检查和负载均衡机制,以及这种机制带来的问题.所谓健康检查,就是当后端出现问题(具体什么叫出现问题,依赖于具体实现,各个实现定义不一样),不再往这个 ...
- Ribbon 负载均衡机制
Ribbon 提供了几个负载均衡的组件,其目的就是让请求转给合适的服务器处理,因此,如何选择合适的服务器变成了负载均衡机制的核心,Ribbon 提供了如下负载均衡规则: RoundRobinRule: ...
随机推荐
- Python 修饰符@用法
def funA(desA): print("It's funA") def funB(desB): print(desB( )) print("It's funB&qu ...
- [C1W4] Neural Networks and Deep Learning - Deep Neural Networks
第四周:深层神经网络(Deep Neural Networks) 深层神经网络(Deep L-layer neural network) 目前为止我们学习了只有一个单独隐藏层的神经网络的正向传播和反向 ...
- zz阿里妈妈深度树检索技术(TDM)及应用框架的探索实践
分享嘉宾:何杰 阿里妈妈 高级算法专家 编辑整理:孙锴 内容来源:DataFun AI Talk 出品社区:DataFun 注:欢迎转载,转载请注明出处 导读:阿里妈妈是阿里巴巴集团旗下数字营销的大中 ...
- git--github使用
什么是github GitHub是一个面向开源及私有软件项目的托管平台,因为只支持git 作为唯一的版本库格式进行托管,故名GitHub. GitHub于2008年4月10日正式上线,除了Git代码仓 ...
- Paper | Making a "Completely Blind" Image Quality Analyzer
目录 1. 技术细节 1.1 NSS特征 1.2 选择锐利块来计算NSS 1.3 一张图像得到36个特征 1.4 用MVG建模这36个特征 1.5 NIQE指标 2. 实验 质量评估大佬AC Bovi ...
- vue 路由跳转到本页面,ts 监听路由变化
@Watch('$route') routechange(to: any, from: any) { //参数不相等 if (to.query.name!=from.query.name) { //t ...
- 手把手教你使用gogs搭建git私有仓库
本来想在 Github 上建一个私仓,但是发现只能设置 3 个贡献者. 国内的码云也只能设置 5 个. 无意间看到了使用 gogs 可以搭建私服,正好手头有空闲的服务器,于是开干! https://g ...
- html-加水印--watermark--代码测试
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- Kafka随笔
1.选举Leader Leader 是 Partition 级别的,当一个 Broker 挂掉后,所有 Leader 在该 Broker 上的 Partition 都会被重新选举,选出一个新 Lea ...
- 在Visual Studio 中使用 <AutoGenerateBindingRedirects> 来解决引用的程序集版本冲突问题
问题: https://stackoverflow.com/questions/42836248/using-autogeneratebindingredirects-in-visual-studio ...