将CDH中的hive和hbase相互整合使用
一、.hbase与hive的兼容版本:
hive0.90与hbase0.92是兼容的,早期的hive版本与hbase0.89/0.90兼容,不需要自己编译。
hive1.x与hbase0.98.x或则更低版本是兼容的,不需要自己编译。
hive2.x与hbase1.x及比hbase1.x更高版本兼容,不需要自己编译。
hive 1.x 与 hbase 1.x整合时,需要自己编译
二、.hbase与hive的整合过程:
1.修改 hive 的conf目录下 hive-site.xml文件
<property>
<name>hive.zookeeper.quorum</name>
<value>node1,node2,node3</value>
</property>
<property>
<name>hive.server2.enable.doAs</name>
<value>false</value>
</property>
1.可通过Hive -> 操作 -> 下载客户端配置 的方式查看hive-site.xml文件内容,可得知 hive.zookeeper.quorum 配置的内容,默认配置即为 node1,node2,node3 即可。
2.可得知 hive.server2.enable.doAs 默认为 true,推荐修改为false,否则在使用官方推荐的hiveserver2/beeline的方式操作时,在利用HQL语句创建HBase时可能会出现异常。
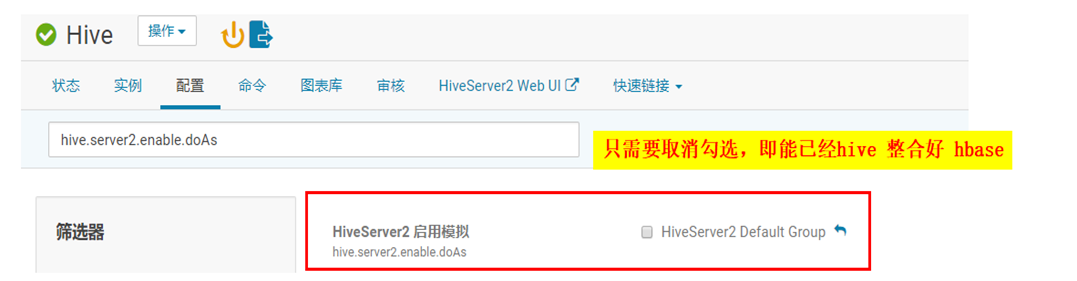
3.可通过Hive -> 配置 -> 搜索栏中搜索 hive.server2.enable.doAs ,默认为勾选,取消勾选即可,即能修改配置为 false。
再当我们通过Hive -> 操作 -> 下载客户端配置 的方式查看hive-site.xml文件内容,即可查看到hive.server2.enable.doAs已为false
2.重启 hive、hbase
3.使用命令 beeline -u jdbc:hive2://node1:10000 -n root 进行连接
4.HIVE执行创建表语句:hbase表 映射 hive表,写入的数据存储在 hbase表中,"hbase.mapred.output.outputtable"可指定数据写入到hbase表中
1.create database rimengshe;
2.use rimengshe;
3.创建hive表的同时也会创建出hbase表
# Hive中的表名test_tb;key字段映射hbase表中的rowkey;value字段映射cf1列簇下的val字段
CREATE TABLE ushio(key int, value string)
# 指定存储处理器
STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
# 声明列簇,列名
WITH SERDEPROPERTIES ("hbase.columns.mapping" = ":key,cf1:val")
# hbase.table.name声明HBase表名,为可选属性默认与Hive的表名相同
# hbase.mapred.output.outputtable指定插入数据时写入的表,如果以后需要往该表插入数据就需要指定该值
TBLPROPERTIES ("hbase.table.name" = "ushio", "hbase.mapred.output.outputtable" = "ushio");
3.hbase表中添加数据:put '表名','rowkey值','列簇名:列名','列值'
put 'ushio','98','cf1:val','val_98'
put 'ushio','99','cf1:val','val_99'
put 'ushio','100','cf1:val','val_100'
4.hive表中添加数据:(会运行yarn)INSERT INTO table_name (field1, field2,...fieldN ) VALUES (value1, value2,...valueN );
insert into ushio values(2,'ushio');
5.hbase表 查询表中的所有数据:scan '表名'
scan 'ushio'
6.hive表 查询表中的所有数据:
select * from ushio;
将CDH中的hive和hbase相互整合使用的更多相关文章
- hive与hbase的整合
Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供完整的sql查询功能,可以将sql语句转换为MapReduce任务进行运行.其优点学习成本低,可以通过类S ...
- Hive与Hbase关系整合
近期工作用到了Hive与Hbase的关系整合,虽然从网上参考了很多的资料,但是大多数讲的都不是很细,于是决定将这块知识点好好总结一下供大家分享,共同掌握! 本篇文章在具体介绍Hive与Hbase整合之 ...
- Hadoop Hive与Hbase关系 整合
用hbase做数据库,但因为hbase没有类sql查询方式,所以操作和计算数据很不方便,于是整合hive,让hive支撑在hbase数据库层面 的 hql查询.hive也即 做数据仓库 1. 基于Ha ...
- Hadoop Hive与Hbase整合+thrift
Hadoop Hive与Hbase整合+thrift 1. 简介 Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供完整的sql查询功能,可以将sql语句 ...
- 数据导入(一):Hive On HBase
Hive集成HBase可以有效利用HBase数据库的存储特性,如行更新和列索引等.在集成的过程中注意维持HBase jar包的一致性.Hive与HBase的整合功能的实现是利用两者本身对外的API接口 ...
- 集成Hive和HBase
1. MapReduce 用MapReduce将数据从本地文件系统导入到HBase的表中, 比如从HBase中读取一些原始数据后使用MapReduce做数据分析. 结合计算型框架进行计算统计查看HBa ...
- hive和hbase整合的原因和原理
为什么要进行hive和hbase的整合? hive是高延迟.结构化和面向分析的: hbase是低延迟.非结构化和面向编程的. Hive集成Hbase就是为了使用hbase的一些特性.或者说是中和它们的 ...
- 大数据工具篇之Hive与HBase整合完整教程
大数据工具篇之Hive与HBase整合完整教程 一.引言 最近的一次培训,用户特意提到Hadoop环境下HDFS中存储的文件如何才能导入到HBase,关于这部分基于HBase Java API的写入方 ...
- 十、Hadoop学习笔记————Hive与Hbase以及RDBMS(关系型数据库)的关系
Hive目的是为了简化MapReduce编程 实际应用中,Hive与Hbase不经常链接
随机推荐
- SPI 机制-插件化扩展功能
SPI(Service Provider Interfaces),中文直译服务提供者接口,一种服务发现机制.可能很多人都不太熟悉这个机制,但是平常或多或少都用到了这个机制,比如我们使用 JDBC 连接 ...
- Fire Balls 04——砖塔的创建,动态上升以及旋转
版权申明: 本文原创首发于以下网站: 博客园『优梦创客』的空间:https://www.cnblogs.com/raymondking123 优梦创客的官方博客:https://91make.top ...
- Java集合框架之ArrayList浅析
Java集合框架之ArrayList浅析 一.ArrayList综述: 位于java.util包下的ArrayList是java集合框架的重要成员,它就是传说中的动态数组,用MSDN中的说法,就是Ar ...
- 分布式任务调度框架 Azkaban —— Flow 1.0 的使用
一.简介 Azkaban 主要通过界面上传配置文件来进行任务的调度.它有两个重要的概念: Job: 你需要执行的调度任务: Flow:一个获取多个 Job 及它们之间的依赖关系所组成的图表叫做 Flo ...
- 12 redis搭建主从服务(ubuntu)
什么是主从服务 一个master可以拥有多个slave,一个slave可以拥有多个slave,如此下去,形成了多级服务器集群架构 master用来写数据, slave用来读数据, 经统计:网站的读写比 ...
- iOS仿写下厨房
把之前简书的博客搬到博客园了,还是放在一个地方看着舒服. 先看一下做的效果,是不是还不错?(可以看一下早餐那块的轮播,上面盖着一个都是点点的图片,但是它不是和轮播一起滚动的,是盖在轮播上面的,需要在那 ...
- JavaScript img标签自带的onload和onerror函数
onload 加载完成时调用触发 原生: <img src="" alt="Park" onload=“handleImageLoaded()”/> ...
- x86—EFLAGS寄存器详解(转载)
鉴于EFLAGS寄存器的重要性,所以将这一部分内容从处理器体系结构及寻址模式一文中单独抽出另成一文,这部分内容主要来自Intel Developer Mannual,在后续的内核系列中遇到的许多和EF ...
- TK图形界面
import tkinter 1.使用tkinter模块前 一般先要建立一个tkinter的对象 例: window = tkinter.TK() 2.建立完对象设置好窗口属性以及所有功能 ...
- 【selenium】- selenium IDE的安装以及使用
本文由小编根据慕课网视频亲自整理,转载请注明出处和作者. 1. 自动化测试工程师的任务 一个合格的自动化测试工程师,需要把框架搭建起来.让不是自动化测试的人,一个普通功能化测试的人,可以完成自动化测试 ...