python——有一种线程池叫做自己写的线程池
python的线程一直被称为鸡肋,所以它也没有亲生的线程池,但是竟然被我发现了野生的线程池,简直不能更幸运~~~于是,我开始啃源码,实在是虐心,在啃源码的过程中,我简略的了解了python线程的相关知识,感觉还是很有趣的,于是写博客困难症患者一夜之间化身写作小能手,完成了一系列线程相关的博客,然后恍然发现,python的多线程是一个鸡肋哎。。。这里换来了同事们的白眼若干→_→。嘻嘻,但是鸡肋归鸡肋,看懂了一篇源码给我带来的收获和成就感还是不能小视,所以还是分享下~~~
别人的线程池
首先介绍别人写的线程池模块,野生threadpool,直接到pypi上去搜,或者pip安装,都可以get到。这里还是先贴上来:
# -*- coding: UTF-8 -*-
"""Easy to use object-oriented thread pool framework. A thread pool is an object that maintains a pool of worker threads to perform
time consuming operations in parallel. It assigns jobs to the threads
by putting them in a work request queue, where they are picked up by the
next available thread. This then performs the requested operation in the
background and puts the results in another queue. The thread pool object can then collect the results from all threads from
this queue as soon as they become available or after all threads have
finished their work. It's also possible, to define callbacks to handle
each result as it comes in. The basic concept and some code was taken from the book "Python in a Nutshell,
2nd edition" by Alex Martelli, O'Reilly 2006, ISBN 0-596-10046-9, from section
14.5 "Threaded Program Architecture". I wrapped the main program logic in the
ThreadPool class, added the WorkRequest class and the callback system and
tweaked the code here and there. Kudos also to Florent Aide for the exception
handling mechanism. Basic usage:: >>> pool = ThreadPool(poolsize)
>>> requests = makeRequests(some_callable, list_of_args, callback)
>>> [pool.putRequest(req) for req in requests]
>>> pool.wait() See the end of the module code for a brief, annotated usage example. Website : http://chrisarndt.de/projects/threadpool/ """
__docformat__ = "restructuredtext en" __all__ = [
'makeRequests',
'NoResultsPending',
'NoWorkersAvailable',
'ThreadPool',
'WorkRequest',
'WorkerThread'
] __author__ = "Christopher Arndt"
__version__ = '1.3.2'
__license__ = "MIT license" # standard library modules
import sys
import threading
import traceback try:
import Queue # Python 2
except ImportError:
import queue as Queue # Python 3 # exceptions
class NoResultsPending(Exception):
"""All work requests have been processed."""
pass class NoWorkersAvailable(Exception):
"""No worker threads available to process remaining requests."""
pass # internal module helper functions
def _handle_thread_exception(request, exc_info):
"""Default exception handler callback function. This just prints the exception info via ``traceback.print_exception``. """
traceback.print_exception(*exc_info) # utility functions
def makeRequests(callable_, args_list, callback=None,
exc_callback=_handle_thread_exception):
"""Create several work requests for same callable with different arguments. Convenience function for creating several work requests for the same
callable where each invocation of the callable receives different values
for its arguments. ``args_list`` contains the parameters for each invocation of callable.
Each item in ``args_list`` should be either a 2-item tuple of the list of
positional arguments and a dictionary of keyword arguments or a single,
non-tuple argument. See docstring for ``WorkRequest`` for info on ``callback`` and
``exc_callback``. """
requests = []
for item in args_list:
if isinstance(item, tuple):
requests.append(
WorkRequest(callable_, item[0], item[1], callback=callback,
exc_callback=exc_callback)
)
else:
requests.append(
WorkRequest(callable_, [item], None, callback=callback,
exc_callback=exc_callback)
)
return requests # classes
class WorkerThread(threading.Thread):
"""Background thread connected to the requests/results queues. A worker thread sits in the background and picks up work requests from
one queue and puts the results in another until it is dismissed. """ def __init__(self, requests_queue, results_queue, poll_timeout=5, **kwds):
"""Set up thread in daemonic mode and start it immediatedly. ``requests_queue`` and ``results_queue`` are instances of
``Queue.Queue`` passed by the ``ThreadPool`` class when it creates a
new worker thread. """
threading.Thread.__init__(self, **kwds)
self.setDaemon(1)
self._requests_queue = requests_queue
self._results_queue = results_queue
self._poll_timeout = poll_timeout
self._dismissed = threading.Event()
self.start() def run(self):
"""Repeatedly process the job queue until told to exit."""
while True:
if self._dismissed.isSet():
# we are dismissed, break out of loop
break
# get next work request. If we don't get a new request from the
# queue after self._poll_timout seconds, we jump to the start of
# the while loop again, to give the thread a chance to exit.
try:
request = self._requests_queue.get(True, self._poll_timeout)
except Queue.Empty:
continue
else:
if self._dismissed.isSet(): # we are dismissed, put back request in queue and exit loop
self._requests_queue.put(request)
break
try:
result = request.callable(*request.args, **request.kwds)
self._results_queue.put((request, result))
except:
request.exception = True
self._results_queue.put((request, sys.exc_info())) def dismiss(self):
print '**********dismiss***********'
"""Sets a flag to tell the thread to exit when done with current job.
"""
self._dismissed.set() class WorkRequest:
"""A request to execute a callable for putting in the request queue later. See the module function ``makeRequests`` for the common case
where you want to build several ``WorkRequest`` objects for the same
callable but with different arguments for each call. """ def __init__(self, callable_, args=None, kwds=None, requestID=None,
callback=None, exc_callback=_handle_thread_exception):
"""Create a work request for a callable and attach callbacks. A work request consists of the a callable to be executed by a
worker thread, a list of positional arguments, a dictionary
of keyword arguments. A ``callback`` function can be specified, that is called when the
results of the request are picked up from the result queue. It must
accept two anonymous arguments, the ``WorkRequest`` object and the
results of the callable, in that order. If you want to pass additional
information to the callback, just stick it on the request object. You can also give custom callback for when an exception occurs with
the ``exc_callback`` keyword parameter. It should also accept two
anonymous arguments, the ``WorkRequest`` and a tuple with the exception
details as returned by ``sys.exc_info()``. The default implementation
of this callback just prints the exception info via
``traceback.print_exception``. If you want no exception handler
callback, just pass in ``None``. ``requestID``, if given, must be hashable since it is used by
``ThreadPool`` object to store the results of that work request in a
dictionary. It defaults to the return value of ``id(self)``. """
#__init__( callable_, args=None, kwds=None, callback=None, exc_callback=_handle_thread_exception)
#WorkRequest(callable_, item[0], item[1], callback=callback,exc_callback=exc_callback)
if requestID is None:
self.requestID = id(self)
else:
try:
self.requestID = hash(requestID)
except TypeError:
raise TypeError("requestID must be hashable.")
self.exception = False
self.callback = callback
self.exc_callback = exc_callback
self.callable = callable_
self.args = args or []
self.kwds = kwds or {} def __str__(self):
return "<WorkRequest id=%s args=%r kwargs=%r exception=%s>" % \
(self.requestID, self.args, self.kwds, self.exception) class ThreadPool:
"""A thread pool, distributing work requests and collecting results. See the module docstring for more information. """ def __init__(self, num_workers, q_size=0, resq_size=0, poll_timeout=5):
"""Set up the thread pool and start num_workers worker threads. ``num_workers`` is the number of worker threads to start initially. If ``q_size > 0`` the size of the work *request queue* is limited and
the thread pool blocks when the queue is full and it tries to put
more work requests in it (see ``putRequest`` method), unless you also
use a positive ``timeout`` value for ``putRequest``. If ``resq_size > 0`` the size of the *results queue* is limited and the
worker threads will block when the queue is full and they try to put
new results in it. .. warning:
If you set both ``q_size`` and ``resq_size`` to ``!= 0`` there is
the possibilty of a deadlock, when the results queue is not pulled
regularly and too many jobs are put in the work requests queue.
To prevent this, always set ``timeout > 0`` when calling
``ThreadPool.putRequest()`` and catch ``Queue.Full`` exceptions. """
self._requests_queue = Queue.Queue(q_size)
self._results_queue = Queue.Queue(resq_size)
self.workers = []
self.dismissedWorkers = []
self.workRequests = {}
self.createWorkers(num_workers, poll_timeout) def createWorkers(self, num_workers, poll_timeout=5):
"""Add num_workers worker threads to the pool. ``poll_timout`` sets the interval in seconds (int or float) for how
ofte threads should check whether they are dismissed, while waiting for
requests. """
for i in range(num_workers):
self.workers.append(WorkerThread(self._requests_queue,
self._results_queue, poll_timeout=poll_timeout)) def dismissWorkers(self, num_workers, do_join=False):
"""Tell num_workers worker threads to quit after their current task."""
dismiss_list = []
for i in range(min(num_workers, len(self.workers))):
worker = self.workers.pop()
worker.dismiss()
dismiss_list.append(worker) if do_join:
for worker in dismiss_list:
worker.join()
else:
self.dismissedWorkers.extend(dismiss_list) def joinAllDismissedWorkers(self):
"""Perform Thread.join() on all worker threads that have been dismissed.
"""
for worker in self.dismissedWorkers:
worker.join()
self.dismissedWorkers = [] def putRequest(self, request, block=True, timeout=None):
"""Put work request into work queue and save its id for later."""
assert isinstance(request, WorkRequest)
# don't reuse old work requests
assert not getattr(request, 'exception', None)
import time
self._requests_queue.put(request, block, timeout)
self.workRequests[request.requestID] = request def poll(self, block=False):
"""Process any new results in the queue."""
while True:
# still results pending?
if not self.workRequests:
raise NoResultsPending
# are there still workers to process remaining requests?
elif block and not self.workers:
raise NoWorkersAvailable
try:
# get back next results request, result = self._results_queue.get(block=block) # has an exception occured?
if request.exception and request.exc_callback: request.exc_callback(request, result) # hand results to callback, if any
if request.callback and not \
(request.exception and request.exc_callback):
request.callback(request, result)
del self.workRequests[request.requestID]
except Queue.Empty:
break def wait(self):
"""Wait for results, blocking until all have arrived."""
while 1:
try:
self.poll(True)
except NoResultsPending:
break ################
# USAGE EXAMPLE
################ if __name__ == '__main__':
import random
import time # the work the threads will have to do (rather trivial in our example)
def do_something(data):
time.sleep(random.randint(1,5))
result = round(random.random() * data, 5)
# just to show off, we throw an exception once in a while
if result > 5:
raise RuntimeError("Something extraordinary happened!")
return result # this will be called each time a result is available
def print_result(request, result):
print("**** Result from request #%s: %r" % (request.requestID, result)) # this will be called when an exception occurs within a thread
# this example exception handler does little more than the default handler
def handle_exception(request, exc_info):
if not isinstance(exc_info, tuple):
# Something is seriously wrong...
print(request)
print(exc_info)
raise SystemExit
print("**** Exception occured in request #%s: %s" % \
(request.requestID, exc_info)) # assemble the arguments for each job to a list...
data = [random.randint(1,10) for i in range(20)]
# ... and build a WorkRequest object for each item in data
requests = makeRequests(do_something, data, print_result, handle_exception)
# to use the default exception handler, uncomment next line and comment out
# the preceding one.
#requests = makeRequests(do_something, data, print_result) # or the other form of args_lists accepted by makeRequests: ((,), {})
data = [((random.randint(1,10),), {}) for i in range(20)]
requests.extend(
makeRequests(do_something, data, print_result, handle_exception)
#makeRequests(do_something, data, print_result)
# to use the default exception handler, uncomment next line and comment
# out the preceding one.
) # we create a pool of 3 worker threads
print("Creating thread pool with 3 worker threads.")
main = ThreadPool(3) # then we put the work requests in the queue...
for req in requests:
main.putRequest(req)
print("Work request #%s added." % req.requestID)
# or shorter:
# [main.putRequest(req) for req in requests] # ...and wait for the results to arrive in the result queue
# by using ThreadPool.wait(). This would block until results for
# all work requests have arrived:
# main.wait() # instead we can poll for results while doing something else:
i = 0
while True:
try:
time.sleep(0.5)
main.poll()
print("Main thread working...")
print("(active worker threads: %i)" % (threading.activeCount()-1, ))
if i == 10: main.createWorkers(3)
if i == 20: main.dismissWorkers(2)
i += 1
except KeyboardInterrupt:
print("**** Interrupted!")
break
except NoResultsPending:
print("**** No pending results.")
break
if main.dismissedWorkers:
print("Joining all dismissed worker threads...")
main.joinAllDismissedWorkers()
threadpool Code
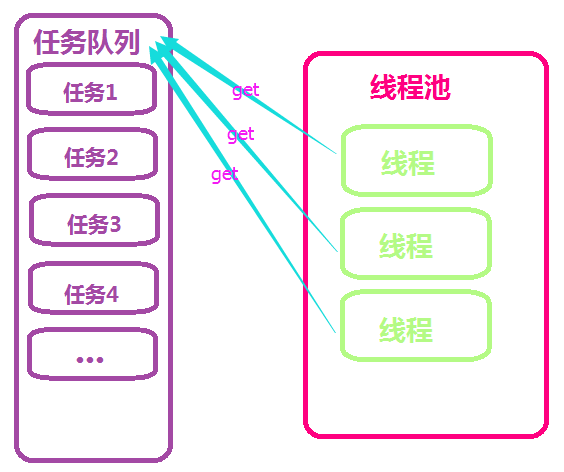
首先我们来看这个线程池的大致原理。在初始化中,它会根据我们的需求,启动相应数量的线程,这些线程是初始化好的,一直到程序结束,不会停止,它们从任务队列中获取任务,在没有任务的时候就阻塞,他们当我们有任务的时候,对任务进行初始化,放入任务队列,拿到任务的线程结束了自己的阻塞人生,欢欢喜喜的拿回去执行,并在执行完毕之后,将结果放入结果队列,继续到任务队列中取任务,如果没有任务就进入阻塞状态。看了一整天的源码竟让我三两句话解释清楚了,我到底是表达能力强还是理解能力差!!!我想静静~~~附上类图如下: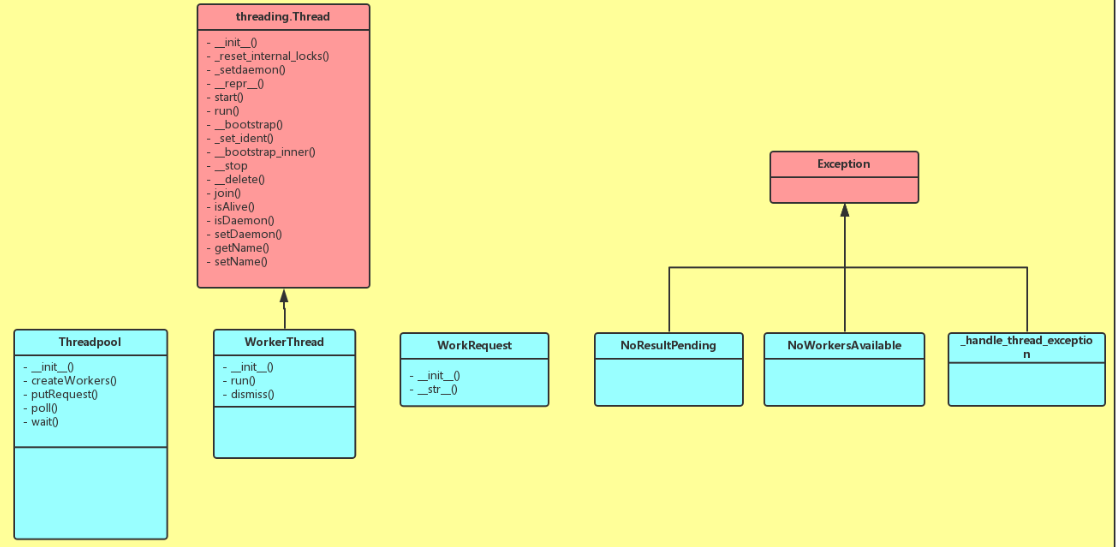
我的线程池
下面就来介绍我写的线程池了,上面的线程池有一个问题,那就是一开始创建了多少个线程,这些线程就一直存在内存中,即使没有工作,也不会销毁。于是我有了一个想法,就像其他语言中的线程池一样,写一个拥有最大线程数和最小线程数限制的线程池。
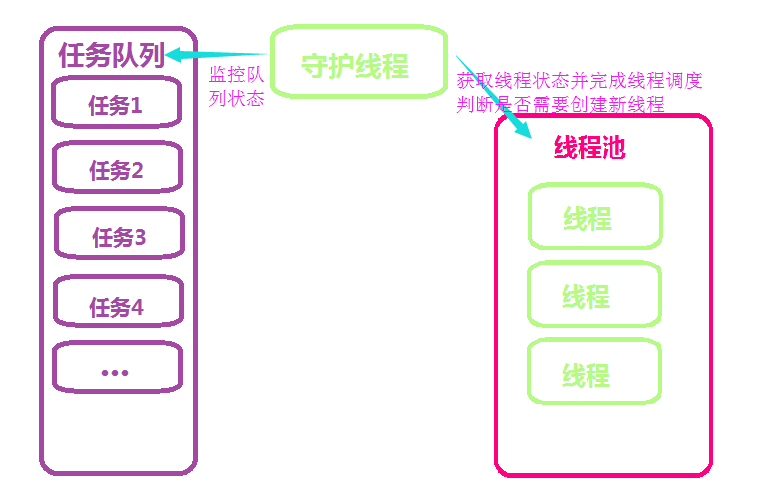
程序启动之初只将最小线程数的线程放在池中,并将线程设置为阻塞状态,用守护线程来查看任务队列,当任务队列中有任务时,则停止线程的阻塞状态,让它们到队列中去获取任务,执行,如果需要返回结果,则将结果返回结果队列。当任务很多,线程池中没有闲置的线程且当前线程数小于线程池最大线程数时,将创建新的线程(这里使用了yield)来接收新的任务,线程执行完毕后,则回到阻塞状态,长期闲置的线程会自动销毁,但池中线程永远不小于在最小线程数。当最小线程数和最大线程数相等的时候,内部就基本和野生线程相同啦~~~
在参考了野生threadpool模块之后,我也学着继承原生的threading.Thread类,并重写了run方法,了解了给一个线程注入新方法的过程。并用到了Event方法和yield。如果不要返回值的话,我想效率还是很高的。尽管我在返回值方面还做了优化,哎~~~
银角大王的线程池:
from Queue import Queue
import contextlib
import threading WorkerStop = object() class ThreadPool: workers = 0 threadFactory = threading.Thread
currentThread = staticmethod(threading.currentThread) def __init__(self, maxthreads=20, name=None): self.q = Queue(0)
self.max = maxthreads
self.name = name
self.waiters = []
self.working = [] def start(self):
needsiZe = self.q.qsize()
while self.workers < min(self.max, needSize):
self.startAWorker() def startAWorker(self):
self.workers += 1
name = "PoolThread-%s-%s" % (self.name or id(self), self.workers)
newThread = self.threadFactory(target=self._worker, name=name)
newThread.start() def callInThread(self, func, *args, **kw):
self.callInThreadWithCallback(None, func, *args, **kw) def callInThreadWithCallback(self, onResult, func, *args, **kw):
o = (func, args, kw, onResult)
self.q.put(o) @contextlib.contextmanager
def _workerState(self, stateList, workerThread):
stateList.append(workerThread)
try:
yield
finally:
stateList.remove(workerThread) def _worker(self):
ct = self.currentThread()
o = self.q.get()
while o is not WorkerStop:
with self._workerState(self.working, ct):
function, args, kwargs, onResult = o
del o
try:
result = function(*args, **kwargs)
success = True
except:
success = False
if onResult is None:
pass else:
pass del function, args, kwargs if onResult is not None:
try:
onResult(success, result)
except:
#context.call(ctx, log.err)
pass del onResult, result with self._workerState(self.waiters, ct):
o = self.q.get() def stop(self):
while self.workers:
self.q.put(WorkerStop)
self.workers -= 1
threadpool Code
def show(arg):
import time
time.sleep(1)
print arg pool = ThreadPool(20) for i in range(500):
pool.callInThread(show, i) pool.start()
pool.stop()
use example Code
这里安利下我男神,哈哈哈~武sir的方法和上面的例子中不同的是,自定义了线程的start方法,当启动线程的时候才初始化线程池,并根据线程池定义的数量和任务数量取min,而不是先开启定义的线程数等待命令,在一定程度上避免了空线程对内存的消耗。
with知识点
这里要介绍一个知识点。我们在做上下文管理的时候,用到过with。
我们如何自定义一个with方法呢?
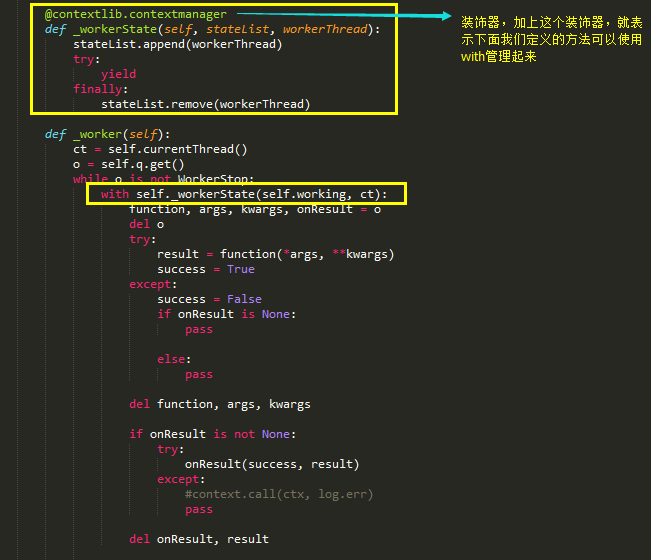
如此一来,我们便可以实现对线程状态的监控和管理了。将正在运行中的线程,加入到一个列表中,并使用yield返回,当线程执行完之后,再从这个列表中移除,就可以知道哪些线程是正在运行的啦。
python——有一种线程池叫做自己写的线程池的更多相关文章
- Java并发——ThreadPoolExecutor线程池解析及Executor创建线程常见四种方式
前言: 在刚学Java并发的时候基本上第一个demo都会写new Thread来创建线程.但是随着学的深入之后发现基本上都是使用线程池来直接获取线程.那么为什么会有这样的情况发生呢? new Thre ...
- 你创建线程池最好分为两种线程池,io密集型线程池,或者cpu密集型线程池
你创建线程池最好分为两种线程池,io密集型线程池,或者cpu密集型线程池. 否则,如果只用一个线程池的话,不管是iO密集的线程,或者cpu消耗大的都放在同一个线程池的话,会发生线程池被撑满的情况
- 多个线程分别顺序交替打印一种不同字符abcdefg(已实现随便多少个线程打印多少个字符,利用线程池实现多线程)
下面实现多线程顺序打印字符"abcdefg": 实现Runnable接口: /** * @author: rhyme * @date: 2019-08-17 14:39 * @to ...
- Python之线程 3 - 信号量、事件、线程队列与concurrent.futures模块
一 信号量 二 事件 三 条件Condition 四 定时器(了解) 五 线程队列 六 标准模块-concurrent.futures 基本方法 ThreadPoolExecutor的简单使用 Pro ...
- {Python之线程} 一 背景知识 二 线程与进程的关系 三 线程的特点 四 线程的实际应用场景 五 内存中的线程 六 用户级线程和内核级线程(了解) 七 python与线程 八 Threading模块 九 锁 十 信号量 十一 事件Event 十二 条件Condition(了解) 十三 定时器
Python之线程 线程 本节目录 一 背景知识 二 线程与进程的关系 三 线程的特点 四 线程的实际应用场景 五 内存中的线程 六 用户级线程和内核级线程(了解) 七 python与线程 八 Thr ...
- Python之路【第十一篇】: 进程与线程
阅读目录 一. cpython并发编程之多进程1.1 multiprocessing模块介绍1.2 Process类的介绍1.3 Process类的使用1.4 进程间通信(IPC)方式一:队列1.5 ...
- python开发【第4篇】【进程、线程、协程】
一.进程与线程概述: 进程,是并发执行的程序在执行过程中分配和管理资源的基本单位,每一个进程都有一个自己的地址空 间. 线程,是进程的一部分,一个没有线程的进程可以被看作是单线程的.线程有时又被称为轻 ...
- Python学习笔记整理总结【网络编程】【线程/进程/协程/IO多路模型/select/poll/epoll/selector】
一.socket(单链接) 1.socket:应用层与TCP/IP协议族通信的中间软件抽象层,它是一组接口.在设计模式中,Socket其实就是一个门面模式,它把复杂的TCP/IP协议族隐藏在Socke ...
- 并发编程-线程-死锁现象-GIL全局锁-线程池
一堆锁 死锁现象 (重点) 死锁指的是某个资源被占用后,一直得不到释放,导致其他需要这个资源的线程进入阻塞状态. 产生死锁的情况 对同一把互斥锁加了多次 一个共享资源,要访问必须同时具备多把锁,但是这 ...
随机推荐
- 异步记载数据时page是怎么计算的
最近一直在完善基于Busybox做的ARM Linux的根文件系统,由于busybox是一个精简的指令集组成的简单文件系统,其优点就是极精简,满足了Linux基本的启动需求,由于它几乎没有什么后台服务 ...
- [T-SQL]INSERT INTO SELECT 与 SELECT INTO FROM
1.INSERT INTO SELECT 语法:INSERT INTO Table2(field1,field2,...) select value1,value2,... from Table1 要 ...
- GirdView 追忆学生时代的百思不得解
临近年关,越多越多的园友开始了对工作.生活的总结,以及对来年目标的确立.这很励志,人是一根能思想的苇草,想来想去,我实在没什么惊天地.泣鬼神的英勇事迹,16年毕业季,按部就班的在时间的马车上颠簸,阅读 ...
- maven国内镜像(maven下载慢的解决方法)
Maven是当前流行的项目管理工具,但官方的库在国外经常连不上,连上也下载速度很慢.国内oschina的maven服务器很早之前就关了.今天发现阿里云的一个中央仓库,亲测可用. <mirror& ...
- jquery常用插件及用法总结
http://www.jb51.net/Special/200.htm
- [转]CocoaPods安装和使用教程
转载地址:http://code4app.com/article/cocoapods-install-usage 目录 CocoaPods是什么? 如何下载和安装CocoaPods? 如何使用Coco ...
- css新笔记
这里的黑科技其实就是一些CSS中不怎么为人所知但在解决某些问题的时候很溜的属性. border-radius 很多开发者估计都没有正确认识这个border-radius,因为基本上很多人都是这么用的: ...
- 传感器之超声波测距HC-SR04
一.前言 HC-SR04超声波测距模块可提供2cm-400cm的非接触式距离感测功能,测距精度可达高到3mm:模块包括超声波发射器.接收器与控制电路.像智能小车的测距以及转向,或是一些项目中,常常会用 ...
- AndroidManifest.xml详解(下)
本文编辑整理自:http://blog.163.com/hero_213/blog/static/39891214201242835410742/ 八.第三层<activity-alias> ...
- Oracle(DML)
数据操作语言: insert update delete 事务控制语言: commit rollback savepoint 1.insert语句 两种格式: 直接插入 子查询插入 1. 直接插入基本 ...