FP-tree推荐算法
推荐算法大致分为:
- 基于物品和用户本身
- 基于关联规则
- 基于模型的推荐
基于物品和用户本身
基于物品和用户本身的,这种推荐引擎将每个用户和每个物品都当作独立的实体,预测每个用户对于每个物品的喜好程度,这些信息往往是用一个二维矩阵描述的。由于用户感兴趣的物品远远小于总物品的数目,这样的模型导致大量的数据空置,即我们得到的二维矩阵往往是一个很大的稀疏矩阵。同时为了减小计算量,我们可以对物品和用户进行聚类, 然后记录和计算一类用户对一类物品的喜好程度,但这样的模型又会在推荐的准确性上有损失。
基于关联规则
基于关联规则的推荐(Rule-based Recommendation):关联规则的挖掘已经是数据挖掘中的一个经典的问题,主要是挖掘一些数据的依赖关系,典型的场景就是“购物篮问题”,通过关联规则的挖掘,我们可以找到哪些物品经常被同时购买,或者用户购买了一些物品后通常会购买哪些其他的物品,当我们挖掘出这些关联规则之后,我们可以基于这些规则给用户进行推荐。
基于模型的推荐
基于模型的推荐(Model-based Recommendation):这是一个典型的机器学习的问题,可以将已有的用户喜好信息作为训练样本,训练出一个预测用户喜好的模型,这样以后用户在进入系统,可以基于此模型计算推荐。这种方法的问题在于如何将用户实时或者近期的喜好信息反馈给训练好的模型,从而提高推荐的准确度。
其实在现在的推荐系统中,很少有只使用了一个推荐策略的推荐引擎,一般都是在不同的场景下使用不同的推荐策略从而达到最好的推荐效果,例如 Amazon 的推荐,它将基于用户本身历史购买数据的推荐,和基于用户当前浏览的物品的推荐,以及基于大众喜好的当下比较流行的物品都在不同的区域推荐给用户,让用户可以从全方位的推荐中找到自己真正感兴趣的物品。探索推荐引擎内部的秘密,第 1 部分: 推荐引擎初探
FP-tree推荐算法 是属于上面第二条基于关联规则推荐的算法,他一共只要 遍历2次 原始数据就行了,比 apriori推荐算法复杂度会相对低一点,本文着重讲解该算法的计算。
按照网上最简单的例子来进行分析,假设有事务数据如下:
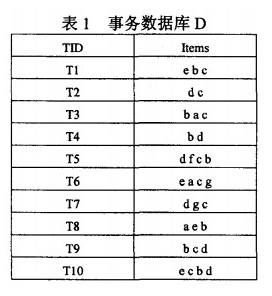
写入原始数据:
info = [["E", "B", "C"], ["D", "C"], ["B", "A", "C"], ["B", "D"], ["D", "F", "C", "B"], ["E", "A", "C", "G"],["D", "G", "C"],["A", "E", "B"], ["B", "C", "D"], ["E", "C", "B", "D"]]
第一次遍历原始数据,对原始数据进行计数,得到:
{'G': 2, 'B': 7, 'D': 6, 'A': 3, 'E': 4, 'C': 8, 'F': 1}
python代码为:
# 遍历数据,进行计数
def countitem(array):
temp = []
for item in array:
for value in item:
temp.append(value)
# 写入字典
dict = {}
for key in Counter(temp).keys():
dict[key] = Counter(temp)[key]
return dict
假设最小支持度为 support = 3 ,剔除掉不满足的数据,得到:
{'A': 3, 'B': 7, 'E': 4, 'D': 6, 'C': 8}
剔除掉的数据为:
['F', 'G']
python代码为:
# 删除支持度不够的key
def deletekey(dict, support):
temp = dict.copy()
detele = []
for key in dict.keys():
if dict[key] < support:
temp.pop(key)
detele.append(key)
return temp, detele
第二次遍历原始数据,构造FP-tree:

挖掘FP-tree,采用自底向上迭代方法,查找以A为后缀的频繁项集,然后是E,D,B,C。例如A的节点路径为:
('C', 8), ('B', 7), ('A', 1)
('C', 8), ('E', 4), ('A', 1)
('B', 7), ('E', 4), ('A', 1)
python代码为:
# info里面元素的种类
def getkinds(array):
temp = []
for item in array:
for value in item:
if value in temp:
pass
else:
temp.append(value)
# ['C', 'B', 'E', 'D', 'A']
# ['A', 'B', 'C', 'D', 'E']
return sorted(temp)
# 得到每一个种类的所有路径
def getrootpath(kinds, newinfo, dict):
allinfo = {}
for kind in kinds:
kindarr = []
for item in newinfo:
# 如果这一条路径包含某个种类
itemarr = []
if kind in item:
for value in item:
if kind == value:
break
else:
itemarr.append(value)
if itemarr:
kindarr.append(itemarr)
# print(kind, kindarr)
# A [[('C', 8), ('B', 7)], [('C', 8), ('E', 4)], [('B', 7), ('E', 4)]]
# B [[('C', 8)], [('C', 8)], [('C', 8)], [('C', 8)], [('C', 8)]]
# C []
# D [[('C', 8)], [('B', 7)], [('C', 8), ('B', 7)], [('C', 8)], [('C', 8), ('B', 7)], [('C', 8), ('B', 7)]]
# E [[('C', 8), ('B', 7)], [('C', 8)], [('B', 7)], [('C', 8), ('B', 7), ('D', 6)]]
allinfo[kind] = kindarr
return allinfo
将节点路径的count全部和A一致:
('C', 1), ('B', 1), ('A', 1)
('C', 1), ('E', 1), ('A', 1)
('B', 1), ('E', 1), ('A', 1)
统计所有字母种类,也就是:
{'E': 2, 'B': 2, 'CB': 1, 'C': 2, 'BE': 1, 'CE': 1}
没有满足 support >= 3 ,所以A没有强关联的元素。
统计所有字幕种类的python代码为:
# 得到所有组合的字典
def getrange(rootpath):
alldict = {}
for key in rootpath.keys():
root = rootpath[key]
# 一个元素的路径
onearr = []
dict = {}
# 实现一个元素路径
for item in root:
for value in item:
onearr.append(value)
dict[value] = onearr.count(value)
alldict[key] = dict
# {'B': {'C': 5}, 'C': {}, 'E': {'C': 3, 'B': 3, 'D': 1}, 'A': {'E': 2, 'C': 2, 'B': 2}, 'D': {'C': 5, 'B': 4}}
# 实现多个元素路径
for item1 in root:
tempdict = {}
for item2 in root:
if item1 == item2:
if len(item1) > 1:
x = "".join(item1)
if x in tempdict.keys():
tempdict[x] += 1
else:
tempdict[x] = 1
# print(tempdict)
if tempdict:
for x in tempdict:
alldict[key][x] = tempdict[x]
# print(alldict)
# {'D': {'CB': 3, 'C': 5, 'B': 4}, 'A': {'E': 2, 'B': 2, 'CB': 1, 'C': 2, 'BE': 1, 'CE': 1}, 'E': {'D': 1, 'C': 3, 'CB': 1, 'B': 3, 'CBD': 1}, 'B': {'C': 5}, 'C': {}}
return alldict
最后得到置信度:
{'E': {'B': '3/7', 'C': '3/8'}, 'B': {'C': '5/8'}, 'D': {'B': '4/7', 'C': '5/8', 'CB': '3/5'}}
代表的意思是:
买了C人,有3/8概率买E,有5/8概率买B,有5/8概率买D,且买了C又买了B的人有3/5的概率买D
置信度的计算可以参考上一篇博文:
置信度的python代码为:
# 得到每个种类的置信度
def confidence(alldict, support, newinfo):
newdict = {}
for kind in alldict:
copydict = alldict[kind].copy()
for key in alldict[kind]:
if alldict[kind][key] < support:
copydict.pop(key)
if copydict:
newdict[kind] = copydict
# print(newdict)
# {'E': {'C': 3, 'B': 3}, 'B': {'C': 5}, 'D': {'C': 5, 'CB': 3, 'B': 4}}
# 计算置信度
for kind in newdict:
for key in newdict[kind].keys():
tempnum = newdict[kind][key]
denominator = 0
for item in newinfo:
if len(key) == 1:
if key in item:
denominator += 1
elif len(key) == 2:
if key[0] in item and key[1] in item:
denominator += 1
elif len(key) == 3:
if key[0] in item and key[1] in item and key[2] in item:
denominator += 1
newdict[kind][key] = str(tempnum) + "/" + str(denominator)
return newdict
所有源码都在:
FP-tree推荐算法的更多相关文章
- FP Tree算法原理总结
在Apriori算法原理总结中,我们对Apriori算法的原理做了总结.作为一个挖掘频繁项集的算法,Apriori算法需要多次扫描数据,I/O是很大的瓶颈.为了解决这个问题,FP Tree算法(也称F ...
- 用Spark学习FP Tree算法和PrefixSpan算法
在FP Tree算法原理总结和PrefixSpan算法原理总结中,我们对FP Tree和PrefixSpan这两种关联算法的原理做了总结,这里就从实践的角度介绍如何使用这两个算法.由于scikit-l ...
- FP Tree算法原理总结(转载)
FP Tree算法原理总结 在Apriori算法原理总结中,我们对Apriori算法的原理做了总结.作为一个挖掘频繁项集的算法,Apriori算法需要多次扫描数据,I/O是很大的瓶颈.为了解决这个问题 ...
- Mahout推荐算法API详解
转载自:http://blog.fens.me/mahout-recommendation-api/ Hadoop家族系列文章,主要介绍Hadoop家族产品,常用的项目包括Hadoop, Hive, ...
- 转】Mahout推荐算法API详解
原博文出自于: http://blog.fens.me/mahout-recommendation-api/ 感谢! Posted: Oct 21, 2013 Tags: itemCFknnMahou ...
- 基于FP-Tree的关联规则FP-Growth推荐算法Java实现
基于FP-Tree的关联规则FP-Growth推荐算法Java实现 package edu.test.ch8; import java.util.ArrayList; import java.util ...
- [转]Mahout推荐算法API详解
Mahout推荐算法API详解 Hadoop家族系列文章,主要介绍Hadoop家族产品,常用的项目包括Hadoop, Hive, Pig, HBase, Sqoop, Mahout, Zookeepe ...
- Mahout推荐算法API具体解释【一起学Mahout】
阅读导读: 1.mahout单机内存算法实现和分布式算法实现分别存在哪些问题? 2.算法评判标准有哪些? 3.什么会影响算法的评分? 1. Mahout推荐算法介绍 Mahout推荐算法,从数据处理能 ...
- 机器学习-FP Tree
接着是上一篇的apriori算法: FP Tree数据结构 为了减少I/O次数,FP Tree算法引入了一些数据结构来临时存储数据.这个数据结构包括三部分,如下图所示 第一部分是一个项头表.里面记录了 ...
- 【笔记3】用pandas实现矩阵数据格式的推荐算法 (基于用户的协同)
原书作者使用字典dict实现推荐算法,并且惊叹于18行代码实现了向量的余弦夹角公式. 我用pandas实现相同的公式只要3行. 特别说明:本篇笔记是针对矩阵数据,下篇笔记是针对条目数据. ''' 基于 ...
随机推荐
- RecyclerView因版本问题无法加载
前几天在学习RecyclerView时候,一直失败,各种加载不上.下面是错误信息 D/AndroidRuntime: Shutting down VM E/AndroidRuntime: FATAL ...
- input标签name与value区别
id是唯一标识符,不允许有重复值(类似数据表的主键)可以通过它的值来获得对应的html标签对象.(如果在同一页面代码中,出现重复的id,会导致不可预料的错误) name:单独地在一个网页里面,一个控件 ...
- android SDK 离线下载更新
http://blog.csdn.net/harvic880925/article/details/37913801 前言:在公司配置eclipse做android开发,真是烦死了,不知公司做了哪门子 ...
- PKU 3983
很久前写了一个24点的算法,刚好POJ上也有个24点,顺便给解了,POJ上的相对于我原始来写的较为简单许多,因为,限制了数字的位置固定,实际上24点的话是不可能限制这个固定的,所以我之前会对数据进行一 ...
- 初识 Burp Suite
Burp Suite 是用于攻击web 应用程序的集成平台.它包含了许多工具,并为这些工具设计了许多接口,以促进加快攻击应用程序的过程. 所有的工具都共享一个能处理并显示HTTP 消息, ...
- strip_tags() 函数
定义和用法 strip_tags() 函数剥去 HTML.XML 以及 PHP 的标签. 语法 strip_tags(string,allow) 参数 描述 string 必需.规定要检查的字符串. ...
- C# 处理应用程序减少内存占用
SetProcessWorkingSetSize减少内存占用 系统启动起来以后,内存占用越来越大,使用析构函数.GC.Collect什么的也不见效果,后来查了好久,找到了个办法,就是使用 SetPro ...
- Hql 中 dao 层 以及daoimpl 层的代码,让mvc 模式更直观简洁
1.BaseDao接口: //使用BaseDao<T> 泛型 ,在service中注入的时候,只需要将T换为对应的bean即可 public interface BaseDao<T& ...
- 十分钟了解分布式计算:Spark
Spark是一个通用的分布式内存计算框架,本文主要研讨Spark的核心数据结构RDD的设计思路,及其在内存上的容错.内容基于论文 Zaharia, Matei, et al. "Resili ...
- Apache2 同源策略解决方案 - 配置 CORS
什么是同源策略 现在的浏览器大多配有同源策略(Same-Origin Policy),具体表现如下: 浏览某一网站,例如 http://www.decembercafe.org/.这个网页中的 Aja ...