论文《Network in Network》笔记
论文:Lin M, Chen Q, Yan S. Network In Network[J]. Computer Science, 2013.
1. 1×1 convolutions
作用:1×1卷积核可以起到一个跨通道聚合的作用,所以进一步可以起到降维(或者升维)的作用,起到减少参数的目的。 比如当前层为 x*x*m即图像大小为x*x,特征层数为m,然后如果将其通过1×1的卷积核,特征层数为n,那么只要n<m这样就能起到降维的目的,减少之后步骤的运算量(当然这里不太严谨,需要考虑1×1卷积核本身的参数个数为m×n个)。换句话说,如果使用1x1的卷积核,这个操作实现的就是多个feature map的线性组合,可以实现feature map在通道个数上的变化。 而因为卷积操作本身就可以做到各个通道的重新聚合的作用,所以1×1的卷积核也能达到这个效果。
2. MLP卷积层
一般来说,如果我们要提取的一些潜在的特征是线性可分的话,那么对于线性的卷积运算来说这是足够了。然而一般来说我们所要提取的特征一般是高度非线性的。在传统的CNN中,也许我们可以用超完备的滤波器,来提取各种潜在的特征。比如我们要提取某个特征,于是就用了一大堆的滤波器,把所有可能的提取出来,这样就可以把想要提取的特征也覆盖到,然而这样存在一个缺点,那就是网络太恐怖了,参数太多了。
CNN高层特征其实是低层特征通过某种运算的组合。于是作者就根据这个想法,提出在每个局部感受野中进行更加复杂的运算,提出了对卷积层的改进算法:MLP卷积层。MLP层可以看成是每个卷积的局部感受野中还包含了一个微型的多层网络
3. Maxout层
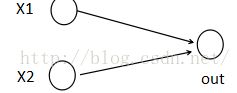
原先为:
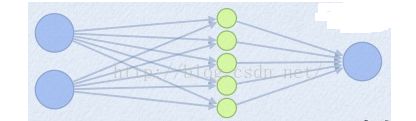
现在为:
3. 全局均值池化
传统的卷积神经网络卷积运算一般是出现在低层网络。对于分类问题,最后一个卷积层的特征图通过量化然后与全连接层连接,最后在接一个softmax逻辑回归分类层。这种网络结构,使得卷积层和传统的神经网络层连接在一起。我们可以把卷积层看做是特征提取器,然后得到的特征再用传统的神经网络进行分类。
然而,全连接层因为参数个数太多,往往容易出现过拟合的现象,导致网络的泛化能力不尽人意。于是Hinton采用了Dropout的方法,来提高网络的泛化能力。
本文提出采用全局均值池化的方法,替代传统CNN中的全连接层。与传统的全连接层不同,我们对每个特征图一整张图片进行全局均值池化,这样每张特征图都可以得到一个输出。这样采用均值池化,连参数都省了,可以大大减小网络,避免过拟合,另一方面它有一个特点,每张特征图相当于一个输出特征,然后这个特征就表示了我们输出类的特征。这样如果我们在做1000个分类任务的时候,我们网络在设计的时候,最后一层的特征图个数就要选择1000。
论文《Network in Network》笔记的更多相关文章
- 《Vision Permutator: A Permutable MLP-Like ArchItecture For Visual Recognition》论文笔记
论文题目:<Vision Permutator: A Permutable MLP-Like ArchItecture For Visual Recognition> 论文作者:Qibin ...
- [place recognition]NetVLAD: CNN architecture for weakly supervised place recognition 论文翻译及解析(转)
https://blog.csdn.net/qq_32417287/article/details/80102466 abstract introduction method overview Dee ...
- 论文笔记系列-Auto-DeepLab:Hierarchical Neural Architecture Search for Semantic Image Segmentation
Pytorch实现代码:https://github.com/MenghaoGuo/AutoDeeplab 创新点 cell-level and network-level search 以往的NAS ...
- 论文笔记——Rethinking the Inception Architecture for Computer Vision
1. 论文思想 factorized convolutions and aggressive regularization. 本文给出了一些网络设计的技巧. 2. 结果 用5G的计算量和25M的参数. ...
- 论文笔记:Fast Neural Architecture Search of Compact Semantic Segmentation Models via Auxiliary Cells
Fast Neural Architecture Search of Compact Semantic Segmentation Models via Auxiliary Cells 2019-04- ...
- 论文笔记:ProxylessNAS: Direct Neural Architecture Search on Target Task and Hardware
ProxylessNAS: Direct Neural Architecture Search on Target Task and Hardware 2019-03-19 16:13:18 Pape ...
- 论文笔记:DARTS: Differentiable Architecture Search
DARTS: Differentiable Architecture Search 2019-03-19 10:04:26accepted by ICLR 2019 Paper:https://arx ...
- 论文笔记:Progressive Neural Architecture Search
Progressive Neural Architecture Search 2019-03-18 20:28:13 Paper:http://openaccess.thecvf.com/conten ...
- 论文笔记:Auto-DeepLab: Hierarchical Neural Architecture Search for Semantic Image Segmentation
Auto-DeepLab: Hierarchical Neural Architecture Search for Semantic Image Segmentation2019-03-18 14:4 ...
- 论文笔记系列-DARTS: Differentiable Architecture Search
Summary 我的理解就是原本节点和节点之间操作是离散的,因为就是从若干个操作中选择某一个,而作者试图使用softmax和relaxation(松弛化)将操作连续化,所以模型结构搜索的任务就转变成了 ...
随机推荐
- ACM1001:Sum Problem
Problem Description In this problem, your task is to calculate SUM(n) = 1 + 2 + 3 + ... + n. Input ...
- kettle安装部署及远程执行
一.windows环境 1.安装jdk 随意选择目录 只需把默认安装目录 \java 之前的目录修改即可 2.安装jre→更改→ \java 之前目录和安装 jdk 目录相同即可 注:若无安装目录要求 ...
- 数据结构与算法之链表(LinkedList)——简单实现
这一定要mark一下.虽然链表的实现很简单,且本次只实现了一个方法.但关键的是例子:单向链表的反转.这是当年我去H公司面试时,面试官出的的题目,而当时竟然卡壳了.现在回想起来,还是自己的基本功不扎实, ...
- WPF开发学习笔记
1.命名规范: 插件名称统一以:CI.Client.Plugins.SYS.+TableName eg:CI.Client.Plugins.SYS.EnterPrise 2.插件文件目录: 3.D ...
- 使用uliweb创建一个简单的blog
1.创建数据库 uliweb的数据库都在models.py文件里面,因此先创建该文件 vim apps/blog/models.py 添加如下两行: #coding=utf-8 from uliweb ...
- 获取当前页面的所有链接的四种方法对比(python 爬虫)
''' 得到当前页面所有连接 ''' import requests import re from bs4 import BeautifulSoup from lxml import etree fr ...
- HBase数据模型的一些概念
首先来先理解一个概念:HBase是一种列式存储的分布式数据库. 表 在HBase中数据以表的形式存储.使用表的主要原因是把某些列组织起来一起访问,同一个表中的数据通常是相关的 ...
- 21-[jQuery]-介绍,引入方式,与js的区别
1.jQuery介绍 jQury官网:https://jquery.com/ 2.jQuery文件的引入 <!DOCTYPE html> <html lang="en&qu ...
- GPUImage每个类的作用
28 #import "GPUImageBrightnessFilter.h" //亮度 29 #import "GPUImageExpos ...
- bzoj 3232: 圈地游戏
bzoj 3232: 圈地游戏 01分数规划,就是你要最大化\(\frac{\sum A}{\sum B}\),就二分这个值,\(\frac{\sum A}{\sum B} \geq mid\) \( ...