spark-shell启动spark报错
前言
离线安装好CDH、Coudera Manager之后,通过Coudera Manager安装所有自带的应用,包括hdfs、hive、yarn、spark、hbase等应用,过程很是波折,此处就不抱怨了,直接进入主题。
描述
在安装有spark的节点上,通过spark-shell启动spark,满怀期待的启动spark,but,来了个晴天霹雳,报错了,报错了!错误信息如下:
18/06/11 17:40:27 ERROR spark.SparkContext: Error initializing SparkContext.
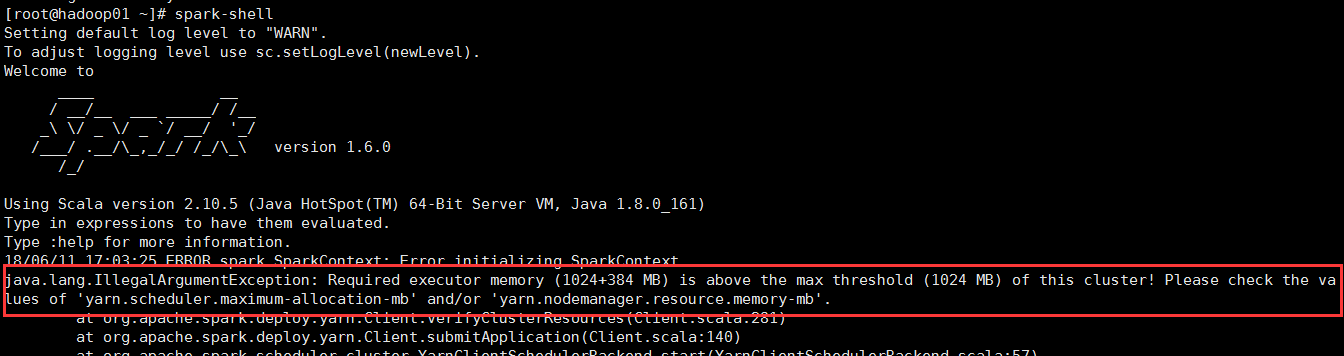
java.lang.IllegalArgumentException: Required executor memory (1024+384 MB) is above the max threshold (1024 MB) of this cluster! Please check the values of 'yarn.scheduler.maximum-allocation-mb' and/or 'yarn.nodemanager.resource.memory-mb'.
at org.apache.spark.deploy.yarn.Client.verifyClusterResources(Client.scala:281)
at org.apache.spark.deploy.yarn.Client.submitApplication(Client.scala:140)
at org.apache.spark.scheduler.cluster.YarnClientSchedulerBackend.start(YarnClientSchedulerBackend.scala:57)
at org.apache.spark.scheduler.TaskSchedulerImpl.start(TaskSchedulerImpl.scala:158)
at org.apache.spark.SparkContext.<init>(SparkContext.scala:538)
at org.apache.spark.repl.SparkILoop.createSparkContext(SparkILoop.scala:1022)
at $line3.$read$$iwC$$iwC.<init>(<console>:15)
at $line3.$read$$iwC.<init>(<console>:25)
at $line3.$read.<init>(<console>:27)
at $line3.$read$.<init>(<console>:31)
at $line3.$read$.<clinit>(<console>)
at $line3.$eval$.<init>(<console>:7)
at $line3.$eval$.<clinit>(<console>)
at $line3.$eval.$print(<console>)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.spark.repl.SparkIMain$ReadEvalPrint.call(SparkIMain.scala:1045)
at org.apache.spark.repl.SparkIMain$Request.loadAndRun(SparkIMain.scala:1326)
at org.apache.spark.repl.SparkIMain.loadAndRunReq$1(SparkIMain.scala:821)
at org.apache.spark.repl.SparkIMain.interpret(SparkIMain.scala:852)
at org.apache.spark.repl.SparkIMain.interpret(SparkIMain.scala:800)
at org.apache.spark.repl.SparkILoop.reallyInterpret$1(SparkILoop.scala:857)
....................后面还有很多错误信息
spark启动错误提示1
仔细查看错误信息之后发现,原来是yarn配置的内存不够,spark启动需要1024+384 MB的内存,但是我的yarn配置仅有1024 MB,不够满足spark启动要求,所以抛出异常,关键错误信息如下图所示:
解决方法
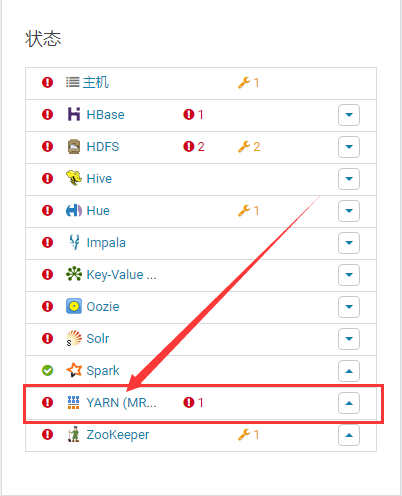
登录Cloudera Manager,找到YARN (MR2 Included),点击进如(不要在意我的集群有那么多警告和报错,解决spark问题是关键),如下图所示:
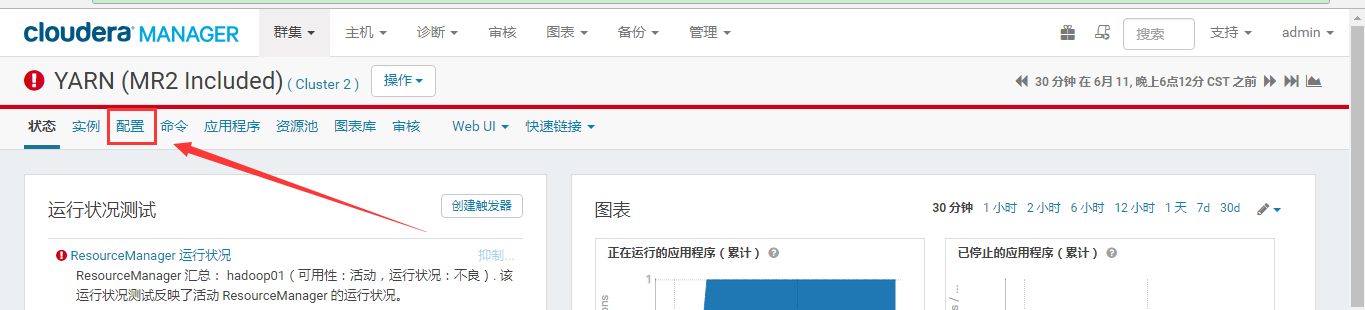
在导航栏找到 配置 选项,如下图所示:
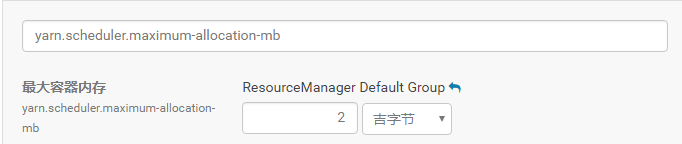
点击进入 配置 页面,在搜索栏中输入yarn.scheduler.maximum-allocation-mb,如下图所示:

可以看到,该配置参数的值正如spark启动时抛出的异常所示,为1GB,将其修改为2GB即可,点击保存更改,如下图所示:
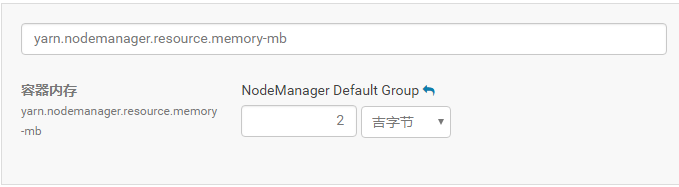
 按照上述的步骤,继续修改yarn.nodemanager.resource.memory-mb 参数的值为2GB,如下图所示,点击保存更改,重启yarn使设置生效。
按照上述的步骤,继续修改yarn.nodemanager.resource.memory-mb 参数的值为2GB,如下图所示,点击保存更改,重启yarn使设置生效。
返回到spark节点命令行里面执行spark-shell命令,奇怪,仍然报错,但错误为其他,不再是上面的错误,错误信息为
18/06/11 17:46:46 ERROR spark.SparkContext: Error initializing SparkContext.
org.apache.hadoop.security.AccessControlException: Permission denied: user=root, access=WRITE, inode="/user":hdfs:supergroup:drwxr-xr-x
at org.apache.hadoop.hdfs.server.namenode.DefaultAuthorizationProvider.checkFsPermission(DefaultAuthorizationProvider.java:279)
at org.apache.hadoop.hdfs.server.namenode.DefaultAuthorizationProvider.check(DefaultAuthorizationProvider.java:260)
at org.apache.hadoop.hdfs.server.namenode.DefaultAuthorizationProvider.check(DefaultAuthorizationProvider.java:240)
at org.apache.hadoop.hdfs.server.namenode.DefaultAuthorizationProvider.checkPermission(DefaultAuthorizationProvider.java:162)
at org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.checkPermission(FSPermissionChecker.java:152)
at org.apache.hadoop.hdfs.server.namenode.FSDirectory.checkPermission(FSDirectory.java:3530)
at org.apache.hadoop.hdfs.server.namenode.FSDirectory.checkPermission(FSDirectory.java:3513)
at org.apache.hadoop.hdfs.server.namenode.FSDirectory.checkAncestorAccess(FSDirectory.java:3495)
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.checkAncestorAccess(FSNamesystem.java:6649)
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.mkdirsInternal(FSNamesystem.java:4420)
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.mkdirsInt(FSNamesystem.java:4390)
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.mkdirs(FSNamesystem.java:4363)
...........................后面还有很多不重要的
spark启动报错2
关键错误信息如下图所示:
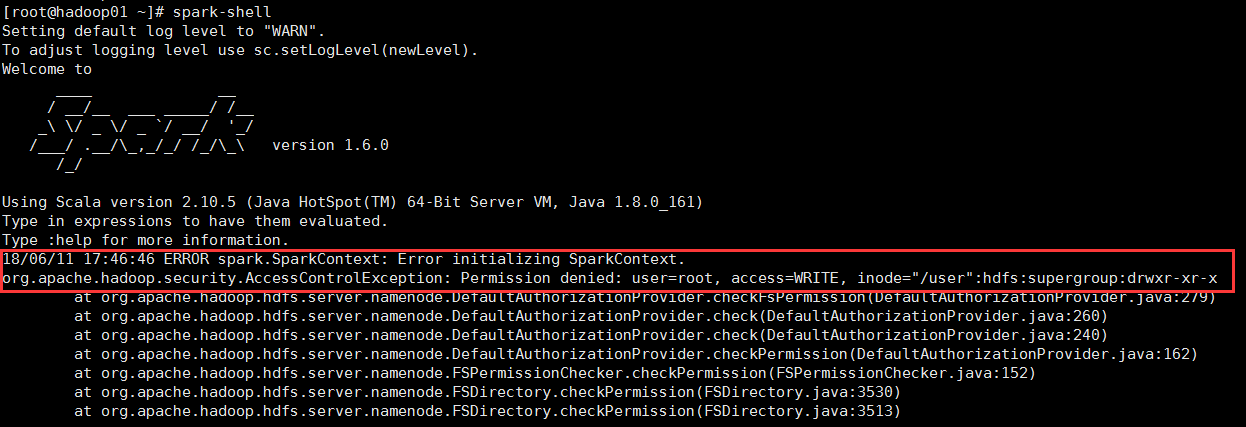
原因是启动spark的用户权限不够,我是使用root命令启动spark,需要hdfs用户启动spark(注:hdfs是hadoop的超级用户),所以报错,切换到hdfs用户下,再次启动是spark,成功。

补充
yarn.scheduler.maximum-allocation-mb 参数的作用:该参数在yarn-site.xml配置文件中配置,设置yarn容器的最大分配内存,以MB为单位,如果yarn资源管理器(RM/ResourceManager)中的容器请求的资源大于此处设置的值,就会抛出无效资源请求异常(InvalidResourceRequestException)。
yarn.nodemanager.resource.memory-mb参数的作用:该参数在yarn-site.xml配置文件中配置,设置yarn节点上可用的物理内存,默认大小为8192(MB),该内存可用于分配给yarn容器。
spark-shell启动spark报错的更多相关文章
- 学习中的错误——ubuntu 14.04 LTS 启动eclipse报错
在ubuntu中启动eclipse报错:(Eclipse:15978): GLib-GIO-CRITICAL **: g_dbus_connection_get_unique_name: assert ...
- maven 项目启动tomcat报错 java.lang.ClassNotFoundException: org.springframework.web.context.ContextLoaderListener
maven项目启动tomcat报错: java.lang.ClassNotFoundException: org.springframework.web.context.ContextLoaderLi ...
- 【转】Eclipse下启动tomcat报错:/bin/bootstrap.jar which is referenced by the classpath, does not exist.
转载地址:http://blog.csdn.net/jnqqls/article/details/8946964 1.错误: 在Eclipse下启动tomcat的时候,报错为:Eclipse下启动to ...
- tomcat7 启动项目报错 java.lang.NoSuchMethodError: javax.servlet.ServletContext.getSessionCookieConfig()
JDK版本:jdk1.8.0_77 Tomcat 版本:apache-tomcat-7.0.47 异常重现步骤: 1.完成项目部署 2.启动Tomcat 异常头部信息:java.lang.NoSuch ...
- Eclipse中启动tomcat报错:A child container failed during start
我真的很崩溃,先是workspace崩了,费了好久重建的workspace,然后建立了一个小demo项目,tomcat中启动却报错,挑选其中比较重要的2条信息如下: A child container ...
- Ubuntu下安装了java但启动eclipse报错说没装java
参考资料:http://blog.csdn.net/happyteafriends/article/details/8290950 一.问题 在Ubuntu下安装了java并在~/.bashrc配置了 ...
- 终端ssh登录mac用shell打包ipa报错:replacing existing signature
终端ssh登录mac用shell打包ipa报错:replacing existing signature 报错原因:login.keychain被锁定,ssh登录的没有访问权限 解决方法:终端敲入 s ...
- VirtualBox启动虚拟机报错0x80004005
Unable to load R3 module C:\Program Files\Oracle\VirtualBox/VBoxDD.DLL (VBoxDD): GetLastError=1790 ( ...
- Eclipse启动Tomcat报错,系统缺少本地apr库
Eclipse启动Tomcat报错,系统缺少本地apr库. Tomcat中service.xml中的设置情况. 默认情况是HTTP协议的值:protocol="HTTP/1.1" ...
- 启动php-fpm报错:please specify user and group other than root
安装好PHP之后启动报错: 启动php-fpm报错:please specify user and group other than root, pool 'default 修改 php-fpm.co ...
随机推荐
- 分类Category的概念和使用流程
一.了解 1.分类的概念: category:类别.类目.分类 2.分类的作用: 将1个类中不同方法分到多个不同的文件中存储 可以在不修改原来类的基础上,为这个类扩充一些方法 注意: 分类中只能增加方 ...
- Week2-作业一——《构建之法》三章精读之想
Week2-作业一——精读<构建之法> 前言 其实我本人是不经常看书的,电子书倒是看了不少,实体书真的不经常看,但是为了这次作业的需求,我还是选择静下心来阅读一下这本<构建之法> ...
- week4b:个人博客作业
下面是week4做程序的过程. 1.在做之前先做客户需求,要求使用的使用mul图. 自己第一次听到这个名字,网上查UML为, http://www.cnblogs.com/wangkangluo1/a ...
- sql中Union和union all的使用
该文转载自:http://www.cnblogs.com/chaobaojun/archive/2009/12/24/1631508.html 在MS-SQL如果将两个或更多查询的结果组合为单个结果集 ...
- grunt入门讲解3:实例讲解使用 Gruntfile 配置任务
这个Gruntfile 实例使用到了5个 Grunt 插件: grunt-contrib-uglify grunt-contrib-qunitgrunt-contrib-concatgrun ...
- selenium 关键字驱动部分设计思路
1 说明: 1.以下的代码亲测直接可用, 2.设计思路来自博客园的 张飞_ :http://www.cnblogs.com/zhangfei/p/5330994.html / http://w ...
- Jvm dump介绍与使用(内存与线程)
很多情况下,都会出现dump这个字眼,java虚拟机jvm中也不例外,其中主要包括内存dump.线程dump. 当发现应用内存溢出或长时间使用内存很高的情况下,通过内存dump进行分析可找到原因. 当 ...
- UVA 12633 Super Rooks on Chessboard(FFT)
题意: 给你一个R*C的棋盘,棋盘上的棋子会攻击,一个棋子会覆盖它所在的行,它所在的列,和它所在的从左上到右下的对角线,那么问这个棋盘上没有被覆盖的棋盘格子数.数据范围R,C,N<=50000 ...
- BZOJ5254 FJWC2018红绿灯(线段树)
注意到一旦在某个路口被红灯逼停,剩下要走的时间是固定的.容易想到预处理出在每个路口被逼停后到达终点的最短时间,这样对于每个询问求出其最早在哪个路口停下就可以了.对于预处理,从下一个要停的路口倒推即可. ...
- [BZOJ4044]Virus synthesis 回文自动机的DP
4044: [Cerc2014] Virus synthesis Time Limit: 20 Sec Memory Limit: 128 MB Description Viruses are us ...