sklearn常见分类器的效果比较
sklearn 是 python 下的机器学习库。
scikit-learn的目的是作为一个“黑盒”来工作,即使用户不了解实现也能产生很好的结果。
其功能非常强大,当然也有很多不足的地方,就比如说神经网络就只有一个RBM(不是人民币哈)。但是,不管怎样,首荐!!
这个例子比较了几种分类器的效果,并直观的显示之
- import numpy as np
- import matplotlib.pyplot as plt
- from matplotlib.colors import ListedColormap
- #from sklearn.model_selection import train_test_split #废弃!!
- from sklearn.cross_validation import train_test_split
- from sklearn.preprocessing import StandardScaler
- from sklearn.datasets import make_moons, make_circles, make_classification
- from sklearn.neural_network import BernoulliRBM
- from sklearn.neighbors import KNeighborsClassifier
- from sklearn.svm import SVC
- from sklearn.gaussian_process import GaussianProcess
- from sklearn.tree import DecisionTreeClassifier
- from sklearn.ensemble import RandomForestClassifier, AdaBoostClassifier
- from sklearn.naive_bayes import GaussianNB
- from sklearn.discriminant_analysis import QuadraticDiscriminantAnalysis
- h = .02 # step size in the mesh
- names = ["Nearest Neighbors", "Linear SVM", "RBF SVM",
- "Decision Tree", "Random Forest", "AdaBoost",
- "Naive Bayes", "QDA", "Gaussian Process","Neural Net", ]
- classifiers = [
- KNeighborsClassifier(3),
- SVC(kernel="linear", C=0.025),
- SVC(gamma=2, C=1),
- DecisionTreeClassifier(max_depth=5),
- RandomForestClassifier(max_depth=5, n_estimators=10, max_features=1),
- AdaBoostClassifier(),
- GaussianNB(),
- QuadraticDiscriminantAnalysis(),
- #GaussianProcess(),
- #BernoulliRBM(),
- ]
- X, y = make_classification(n_features=2, n_redundant=0, n_informative=2,
- random_state=1, n_clusters_per_class=1)
- rng = np.random.RandomState(2)
- X += 2 * rng.uniform(size=X.shape)
- linearly_separable = (X, y)
- datasets = [make_moons(noise=0.3, random_state=0),
- make_circles(noise=0.2, factor=0.5, random_state=1),
- linearly_separable
- ]
- figure = plt.figure(figsize=(27, 9))
- i = 1
- # iterate over datasets
- for ds_cnt, ds in enumerate(datasets):
- # preprocess dataset, split into training and test part
- X, y = ds
- X = StandardScaler().fit_transform(X)
- X_train, X_test, y_train, y_test = \
- train_test_split(X, y, test_size=.4, random_state=42)
- x_min, x_max = X[:, 0].min() - .5, X[:, 0].max() + .5
- y_min, y_max = X[:, 1].min() - .5, X[:, 1].max() + .5
- xx, yy = np.meshgrid(np.arange(x_min, x_max, h),
- np.arange(y_min, y_max, h))
- # just plot the dataset first
- cm = plt.cm.RdBu
- cm_bright = ListedColormap(['#FF0000', '#0000FF'])
- ax = plt.subplot(len(datasets), len(classifiers) + 1, i)
- if ds_cnt == 0:
- ax.set_title("Input data")
- # Plot the training points
- ax.scatter(X_train[:, 0], X_train[:, 1], c=y_train, cmap=cm_bright)
- # and testing points
- ax.scatter(X_test[:, 0], X_test[:, 1], c=y_test, cmap=cm_bright, alpha=0.6)
- ax.set_xlim(xx.min(), xx.max())
- ax.set_ylim(yy.min(), yy.max())
- ax.set_xticks(())
- ax.set_yticks(())
- i += 1
- # iterate over classifiers
- for name, clf in zip(names, classifiers):
- ax = plt.subplot(len(datasets), len(classifiers) + 1, i)
- clf.fit(X_train, y_train)
- score = clf.score(X_test, y_test)
- # Plot the decision boundary. For that, we will assign a color to each
- # point in the mesh [x_min, m_max]x[y_min, y_max].
- if hasattr(clf, "decision_function"):
- Z = clf.decision_function(np.c_[xx.ravel(), yy.ravel()])
- else:
- Z = clf.predict_proba(np.c_[xx.ravel(), yy.ravel()])[:, 1]
- # Put the result into a color plot
- Z = Z.reshape(xx.shape)
- ax.contourf(xx, yy, Z, cmap=cm, alpha=.8)
- # Plot also the training points
- ax.scatter(X_train[:, 0], X_train[:, 1], c=y_train, cmap=cm_bright)
- # and testing points
- ax.scatter(X_test[:, 0], X_test[:, 1], c=y_test, cmap=cm_bright,
- alpha=0.6)
- ax.set_xlim(xx.min(), xx.max())
- ax.set_ylim(yy.min(), yy.max())
- ax.set_xticks(())
- ax.set_yticks(())
- if ds_cnt == 0:
- ax.set_title(name)
- ax.text(xx.max() - .3, yy.min() + .3, ('%.2f' % score).lstrip(''),
- size=15, horizontalalignment='right')
- i += 1
- plt.tight_layout()
- plt.show()
效果图:
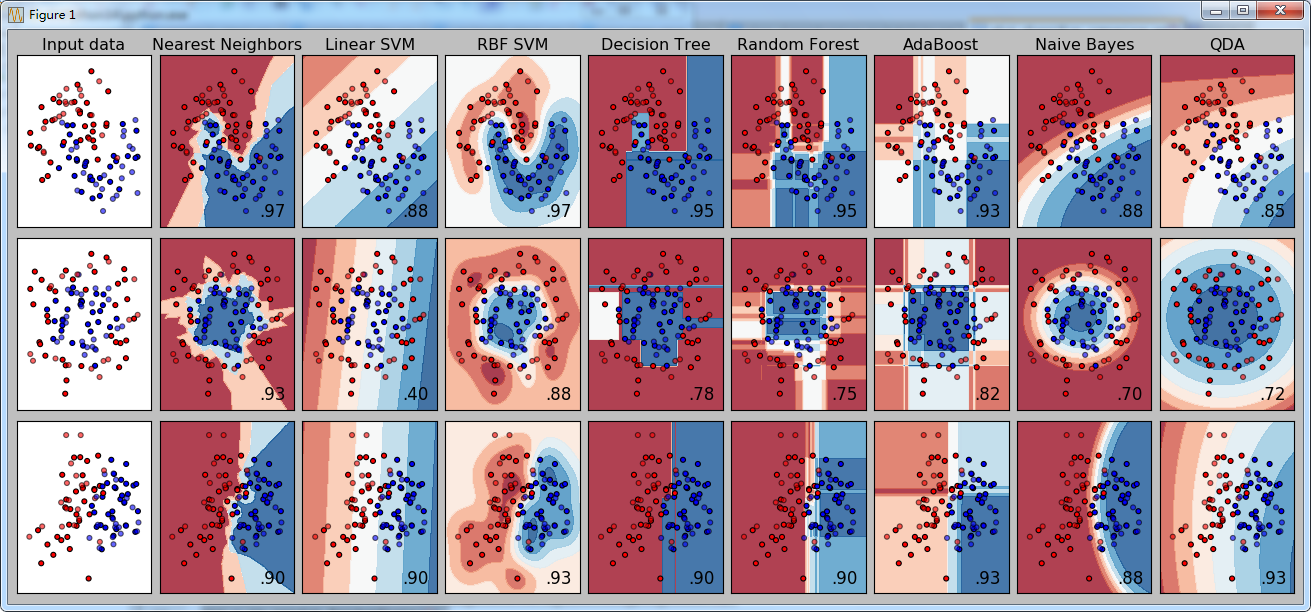
说明:

1.原始数据(三组)
2.分类器名称(八个)
3.对应的成绩 (score)
sklearn常见分类器的效果比较的更多相关文章
- sklearn常见分类器(二分类模板)
# -*- coding: utf-8 -*- import pandas as pd import matplotlib matplotlib.rcParams['font.sans-serif'] ...
- 基于sklearn的分类器实战
已迁移到我新博客,阅读体验更佳基于sklearn的分类器实战 完整代码实现见github:click me 一.实验说明 1.1 任务描述 1.2 数据说明 一共有十个数据集,数据集中的数据属性有全部 ...
- sklearn 组合分类器
组合分类器: 组合分类器有4种方法: (1)通过处理训练数据集.如baging boosting (2)通过处理输入特征.如 Random forest (3)通过处理类标号.error_corre ...
- 纯CSS3实现常见多种相册效果
本文包含 1.CSS3中2D转换和3D转换的介绍. 2.在相册中的应用实例. CSS3中的转换效果和动画效果十分强大好用,可以实现一些常见的动态效果. 如此一来,CSS3便可以代替许多jQuery的功 ...
- js---电商中常见的放大镜效果
js中的放大镜效果 在电商中,放大镜效果是很常见的,如下图所示: 当鼠标悬浮时,遮罩所在区域在右侧进行放大. 在动手写之前,我们要先理清思路,分析需求,所需知识点,再将每一块进行组装,最后进行功能的完 ...
- sklearn各种分类器简单使用
sklearn中有很多经典分类器,使用非常简单:1.导入数据 2.导入模型 3.fit--->predict 下面的示例为在iris数据集上用各种分类器进行分类: #用各种方式在iris数据集上 ...
- 常见的页面效果,相关的js代码
1.焦点图 $(document).ready(function(){ var i=0; var autoChange= setInterval(function(){ if(i<$(" ...
- 【Android进阶】使用Andbase快速开发框架实现常见侧滑栏和滑动标签页组合效果
最近闲来无事,在网上寻找源代码看,突然发现了一个国内技术牛人开发的快速开发框架Andbase,花了一天时间研究了下源码和怎么使用,现将开发常见的侧滑栏和滑动标签页组合效果的使用介绍个大家,希望可以减少 ...
- cs231n笔记 (一) 线性分类器
Liner classifier 线性分类器用作图像分类主要有两部分组成:一个是假设函数, 它是原始图像数据到类别的映射.另一个是损失函数,该方法可转化为一个最优化问题,在最优化过程中,将通过更新假设 ...
随机推荐
- hadoop伪分布模式安装
软件环境 操作系统 : OracleLinux-R6-U6 主机名: hadoop java: jdk1.7.0_75 hadoop: hadoop-2.4.1 环境搭建 1.软件安装 由于所需的软 ...
- 《SQL Server 2008从入门到精通》--20180710
目录 1.使用Transact-SQL语言编程 1.1.数据定义语言DDL 1.2.数据操纵语言DML 1.3.数据控制语言DCL 1.4.Transact-SQL语言基础 2.运算符 2.1.算数运 ...
- jetty8 中的异常 There is an error in invoking javac. A full JDK (not just JRE) is required...
在jetty文件夹下的start.ini文件里有这么一行"-Dorg.apache.jasper.compiler.disablejsr199=true"注释,把这个注释去掉,再启 ...
- Lambda表达式学习记录
Lambda表达式可以简化C#编程的某些方面,用法非常灵活.因此也不容易掌握. 下边是我学Lambda表达式的一点记录. 1.Lambda表达式是与委托紧密联系的.只要有委托参数类型的地方,就可以使用 ...
- Linux fsck命令详解
fsck(file system check)用来检查和维护不一致的文件系统.若系统掉电或磁盘发生问题,可利用fsck命令对文件系统进行检查. fsck常见命令参数 -a:自动修复文件系统,不询问任何 ...
- java.lang.verifyerror:bad type on orerand stack
问题: junit测试的时候报这个错:java.lang.verifyerror:bad type on orerand stack 原因:(多种,自行逐个排查) 1.class not find 引 ...
- 作业一 制作PC配置 吴昊
- 统计过程控制与评价 Cpk、SPC、PPM
Cpk(Process capability index)--工序能力指数 SPC(Statisical Process Control)--工艺过程统计受控状态分析 PPM(Parts Per Mi ...
- mysql的表和约束操作
在创建表是默认为加上数据引擎和字符集,如创建一个student表,代码如下: create table students(id int unsigned zerofill auto_increment ...
- 你的ABAP程序给佛祖开过光么?来试试Jerry这个小技巧
最近Jerry在忙一个项目,技术栈换成了nodejs平台,语言换成了JavaScript,因为赶项目进度,一直没时间更新公众号.感谢大家的支持,关注人数还是慢慢地增长到了3000. 今天我们来聊聊一个 ...