mysql Inoodb 内核
MySQL从5.5版本开始将InnoDB作为默认存储引擎,该存储引擎是第一个完整支持事务ACID特性的存储引擎,且支持数据行锁,多版本并发控制(MVCC),外键,以及一致性非锁定读。
作为默认存储引擎,也就意味着默认创建的表都会使用此存储引擎,除非
使用ENGINE=参数指定创建其他存储引擎的表。
InnoDB的关键属性包括:
- ACID事务特性支持,包括commit, rollback以及crash恢复的能力
- 行级别锁以及多版本并发控制MVCC
- 利用主键的聚簇索引(clustered index)在底层存储数据,以提升对主键查询的IO性能
- 支持外键功能,管理数据的完整性
ACID模型是关系型数据库普遍支持的事务模型,用来保证数据的一致性,其中
的ACID分别代表:
A: atomicity原子性: 事务是一个不可再分割的工作单位,事务中的操作要么都发生,要么都不发生
C: consistency一致性: 事务开始之前和事务结束以后,数据库的完整性约束没有被破坏。这是说数据库事务不能破坏关系数据的完整性以及业务逻辑上的一致性
I: isolation独立性: 多个事务并发访问时,事务之间是隔离的,一个事务不应该影响其它事务运行效果
D: durability持续性: 在事务完成以后,该事务所对数据库所作的更改便持久的保存在数据库之中,并不会被回滚
举例来说,
比如银行的汇款1000元的操作,简单可以拆分成A账户的余额-1000, B账户的余额+1000,还要分别在A和B的账户流水上记录余额变更日志,这四个操作必须放在一个事务中完成,否则丢失其中的任何一条记录对整个系统来说都是不完整的。
对上述例子来说, 原子性体现在要么四条操作每个都成功,意味着汇款成功,要么其中某一个操作失败,则整个事务中的四条操作都回滚,汇款失败; 一致性表示当汇款结束时, A账户和B账户里的余额变化和操作日志记录是可以对应起来的; 独立性表示当汇款操作过程中如果有C账户也在往B账户里汇款的话,两个事务相互不影响即A->B有四个独立操作, C->B有四个独立操作; 持久性表示当汇款成功时, A和B的余额就变更了,不管是数据库重启还是什么原因,该数据已经写入到磁盘中作为永久存储,不会再变化,除非有新的事务 其中事务的隔离性是通过MySQL锁机制实现 原子性,一致性,持久性则通过MySQL的redo和undo日志记录来完成
InnoDB 多版本控制
为保证并发操作和回滚操作, InnoDB会将修改前的数据存放在回滚段(undo log)中。
InnoDB会在数据库的每一行上额外增加三个字段以实现多版本控制,
第一个字段是DB_TRX_ID用来存放针对该行最后一次执行insert、 update操作的事务ID,而delete操作也会被认为是update,只是会有额外的一位来代表事务为删除操作;
第二个字段是DB_ROLL_PTR指针指向回滚段里对应的undo日志记录;
第三个字段是DB_ROW_ID代表每一行的行ID。
回滚段中的undo日志记录只有在事务commit提交之后才会被丢弃,为避免回滚段越来越大,要注意及时执行commit命令
初始数据行的情况,六个字段的值分别是1,2,3,4,5,6
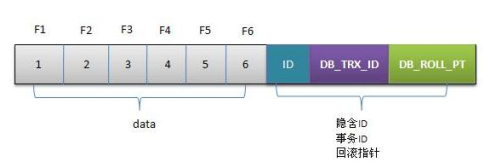
数据在数据库存储,不只是只有数据存储还有其他辅助信息存储例如(隐含id,事务id,回滚指针)等等信息
事务1修改该数据行,将六个字段的值分别*10,并生成回滚日志记录
事务2读取该数据行
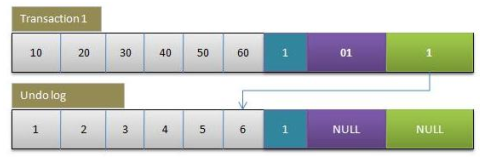
undo log 会保存修改前数据的哪一行的状态 ,执行roallback 会找到回滚指针 进行回到以前的数据
事务2按照自己的事务ID和行数据中的事务ID做对比,并按照事务隔离级别选取事务1修改前的回滚段中的数据返回
模拟多版本控制
在两个数据库链接下实验多版本控制
链接1: mysql> start transaction;
链接2: mysql> start transaction;
链接1 : mysql> update score set score=88 where sid=1;
链接2: mysql> select * from score where sid=1; ###链接1锁数据未释放,链接2也能访问相同数据
+------+-----------+-------+
| sid | course_id | score |
+------+-----------+-------+
| 1 | 1 | 90 |
| 1 | 2 | 90 |
| 1 | 3 | 90 |
| 1 | 4 | 90 |
链接1: mysql>commit;
链接2: mysql> select * from score where sid=1; ###链接1锁释放,但链接2访问到的数据依然是之前的数据
+------+-----------+-------+
| sid | course_id | score |
+------+-----------+-------+
| 1 | 1 | 90 |
| 1 | 2 | 90 |
| 1 | 3 | 90 |
| 1 | 4 | 90 |
链接2: mysql> commit;
链接2: mysql> select * from score where sid=1; ###链接2提交之后,再访问到的数据是修改后的数据
+------+-----------+-------+
| sid | course_id | score |
+------+-----------+-------+
| 1 | 1 | 88 |
| 1 | 2 | 88 |
| 1 | 3 | 88 |
| 1 | 4 | 88 |
InnoDB 体系结构
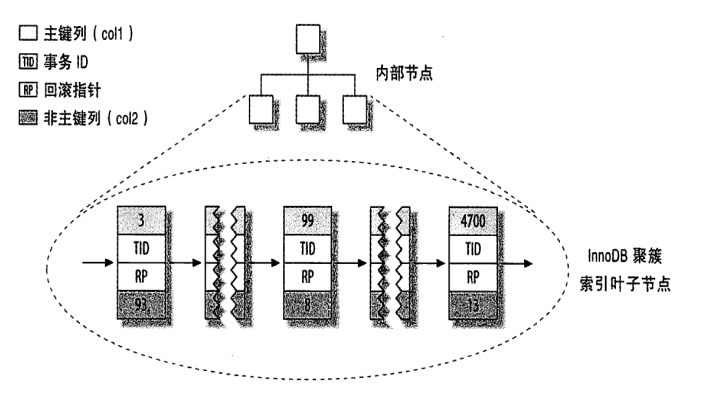
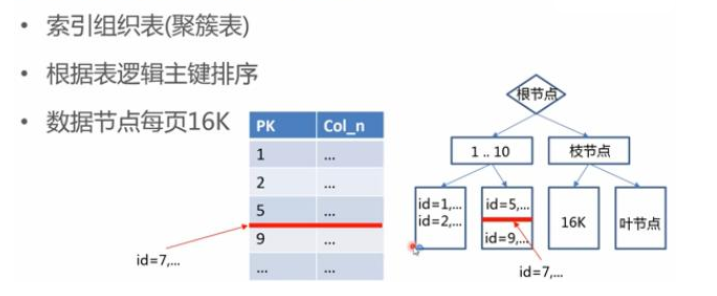
特点:
根据主键寻址速度很快
主键值递增的insert插入效率较好
主键值随机insert插入操作效率差
InnoDB 存储引擎体系架构
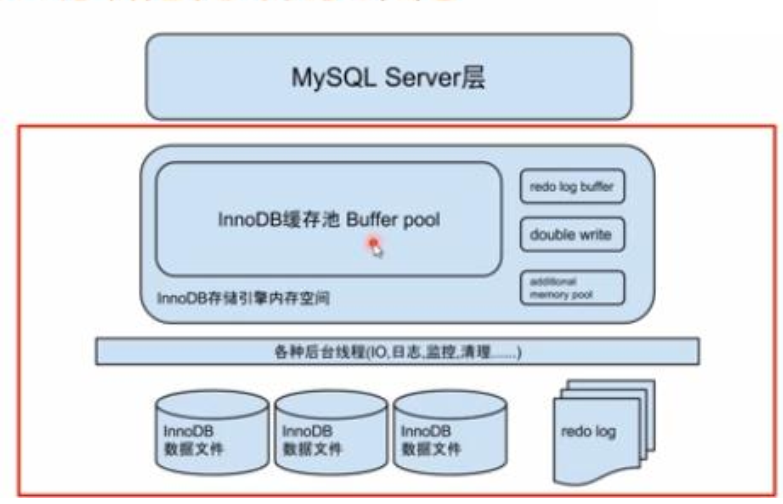
缓存池:
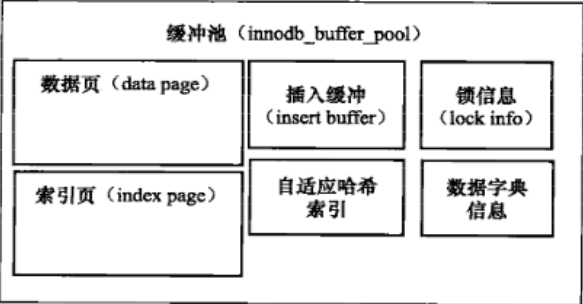
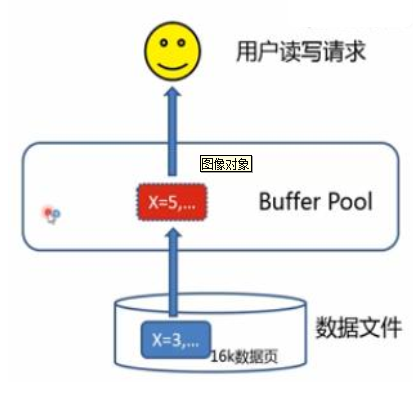
buffer pool缓存池是InnoDB在内存中开辟的用来缓存表数据和索引数据的区域, 一般可以设置为50%~80%的物理内存大小, 通过对经常访问的数据放置到内存当中来加快访问速度。
Buffer pool以page页的格式组成,页之间组成list列表,并通过LRU算法(最近最少使用算法) 对长久不使用的页进行置换。
数据的读写需要经过缓存(缓存在buffer pool 即在内存中)数据以整页(16K)位单位读取到缓存中缓存中的数据以LRU策略换出(最少使用策略)IO效率高,性能好
Adaptive Hash Index(自适应哈希索引):
Adaptive Hash index属性使得InnoDB更像是内存数据库。该属性通过innodb_adapitve_hash_index开启,也可以通过—skip-innodb_adaptive_hash_index参数关闭
InnoDB存储引擎会监控对表上索引的查找,如果观察到建立哈希索引可以带来速度的提升,则建立哈希索引,所以称之为自适应(adaptive) 的。自适应哈希索引通过缓冲池的B+树构造而来,因此建立的速度很快。而且不需要将整个表都建哈希索引,InnoDB存储引擎会自动根据访问的频率和模式 来为某些页建立哈希索引。
哈希(hash)是一种非常快的等值查找方法,在一般情况下这种查找的时间复杂度为O(1),即一般仅需要一次查找就能定位数据。
而B+树的查找次数,取决于B+树的高度,在生产环境中,B+树的高度一般3-4层,故需要3-4次的查询。
innodb会监控对表上个索引页的查询。如果观察到建立哈希索引可以带来速度提升,则自动建立哈希索引,称之为自适应哈希索引(Adaptive Hash Index,AHI)。
AHI有一个要求,就是对这个页的连续访问模式必须是一样的。
例如对于(a,b)访问模式情况:
where a = xxx
where a = xxx and b = xxx
AHI启动后,读写速度提高了2倍,辅助索引的连接操作性能可以提高5倍。
AHI,是数据库自动优化的,尽量使用符合AHI条件的查询,以提高效率。
Redo log buffer
Redo log buffer是一块用来存放写入redo log文件内容的内存区域,内存的大小由innodb_log_buffer_size参数确定。该buffer的内容会定期刷新到磁盘的redo log文件中。 参数innodb_flush_log_at_trx_commit决定了刷新到文件的方式,参数innodb_flush_log_at_timeout参数决定了刷新的频率。
系统表空间
InnoDB的系统表空间用来存放表和索引数据,同时也是doublewriter缓存,change缓存和回滚日志的存储空间,系统表空间是被多个表共享的表空间。
默认情况下,系统表空间只有一个系统数据文件,名为ibdata1。系统数据文件的位置和个数由参数innodb_data_file_path参数决定。

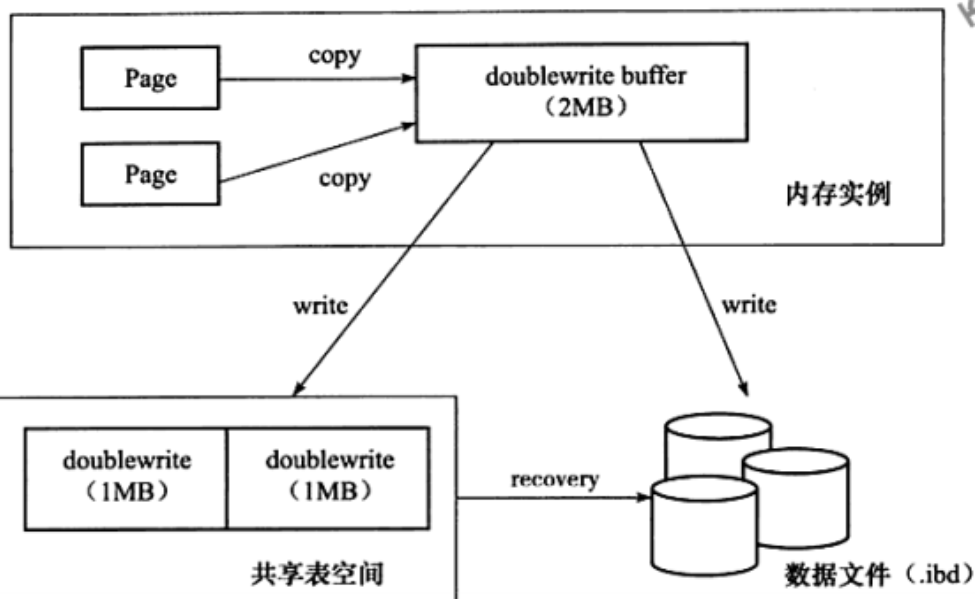
Doublewrite缓存
Doublewrite缓存是位于系统表空间的存储区域,用来缓存InnoDB的数据页从innodb buffer pool中flush之后并写入到数据文件之前,所以当操作系统或者数据库进程在数据页写磁盘的过程中崩溃,Innodb可以在doublewrite缓存中找到数据页的备份而用来执行crash恢复。
数据页写入到doublewrite缓存的动作所需要的IO消耗要小于写入到数据文件的消耗,因为此写入操作会以一次大的连续块的方式写入。
在应用(apply)重做日志前,用户需要一个页的副本,当写入失效发生时,先通过页的副本来还原该页,再进行重做,这就是double write
doublewrite组成: 内存中的doublewrite buffer,大小2M, 物理磁盘上共享表空间中连续的128个页,即2个区(extend),大小同样为2M。
对缓冲池的脏页进行刷新时,不是直接写磁盘,而是会通过memcpy()函数将脏页先复制到内存中的doublewrite buffer,之后通过doublewrite 再分两次,每次1M顺序地写入共享表空间的物理磁盘上,在这个过程中,因为doublewrite页是连续的,因此这个过程是顺序写的,开销并不是很大。在完成doublewrite页的写入后,再将doublewrite buffer 中的页写入各个 表空间文件中,此时的写入则是离散的。如果操作系统在将页写入磁盘的过程中发生了崩溃,在恢复过程中,innodb可以从共享表空间中的doublewrite中找到该页的一个副本,将其复制到表空间文件,再应用重做日志。
Undo 日志
Undo日志是由一系列事务的undo日志记录组成,每一条undo日志记录包含了事务数据回滚的相关原始信息,所以当其它的事务需要查看修改前的原始数据,则会从此undo日志记录中获取。Undo日志存放在回滚段中的undo日志段中。默认情况下回滚段是作为系统表空间的一部分,但也可以有自己独立的undo表空间,通过设置
innodb_undo_tablespaces和innodb_undo_directory两个参数。
Innodb支持最大128个回滚段,其中的32个用来服务临时表的相关事务操作,剩下的96个服务非临时表,每个回滚段可以同时支持1023个数据修改事务,也就是总共96K个数据修改事务。
Innodb_undo_logs参数用来设置回滚段的个数。
Undo Log的原理很简单,为了满足事务的原子性,在操作任何数据之前,首先将数据备份到一个地方
(这个存储数据备份的地方称为Undo Log)。然后进行数据的修改。如果出现了错误或者用户执行了
ROLLBACK语句,系统可以利用Undo Log中的备份将数据恢复到事务开始之前的状态
File-per-table表空间
File-per-table表空间意味着innodb的数据表不是共享一个系统表空间,而是每个表一个独立的表空间。可以通过设置innodb_file_per_table开启此属性。开启之后每个表数据和索引数据都会默认单独存放在数据文件夹下的.ibd数据文件中。
mysql> show variables like '%per_table%';
+-----------------------+-------+
| Variable_name | Value |
+-----------------------+-------+
| innodb_file_per_table | ON |
+-----------------------+-------+
temporary表空间 temporary临时表空间用来存放临时表,默认情况下是在数据文件夹下的ibtmp1数据文件,此数据文件被设置为每次自动增长12MB大小,当然也可以设置innodb_temp_data_file_path来指定临时表空间文件的存放位置。 临时表空间文件在正常的shutdown之后会自动清除,但在crash发生时不会清除,这就需要手动去删除表空间文件或重启服务器。
mysql> show variables like '%innodb_temp%';
+----------------------------+-----------------------+
| Variable_name | Value |
+----------------------------+-----------------------+
| innodb_temp_data_file_path | ibtmp1:12M:autoextend |
如果发现临时表空间数据文件比较大,可以考虑重启MySQL来释放空间大小。
redo log
redo日志是存在于磁盘上的文件,包括ib_logfile0和ib_logfile1两个文件,常用于在crash恢复发生时将还没来得及写入到数据文件中但已经完成提交的事务在数据库初始化时重新执行一遍
InnoDB对redo log buffer写入到redo log文件的方式提供了组提交(group commit)的方式,意味着针对一次写磁盘操作可以包含多个事务数据,用此方法提高性能。 为了IO效率,数据库修改的文件都在内存缓存中完成的;那么我们知道一旦断电,内存中的数据将消失, 而数据库是如何保证数据的完整性? 那就是数据持久化与事务日志
如果宕机了则:应用已经持久化好了的日志文件,读取日志文件中没有被持久化到数据文件里面的记录;将这些记录重新持久化到我们的数据文件中
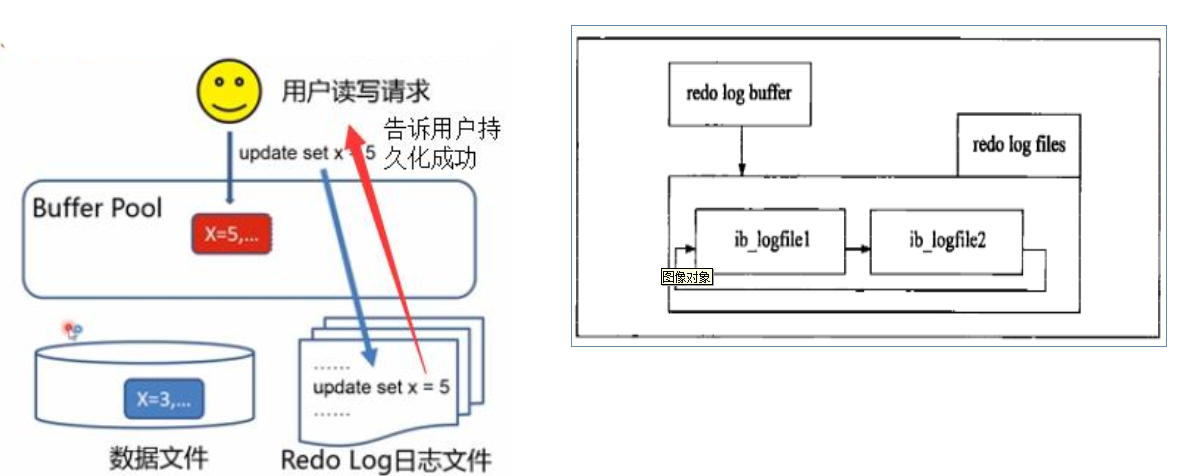
innodb日志持久化相关参数:
innodb_flush_log_at_trx_commit
0:每秒写入并持久化一次(不安全,性能高,无论mysql或服务器宕机,都会丢数据最多1秒的数据)
1:每次commit都持久化(安全,性能低, IO负担重)
2:每次commit都写入内存的内存缓存,每秒再刷新到磁盘(安全,性能折中, mysql宕机数据不会丢失,服务器宕机数据会丢失最多1秒的数据)
innodb_flush_log_at_timeout参数决定最多丢失多少秒的数据,默认是1秒
InooDB 存储引擎配置
启动配置
InnoDB合理的规划方法是在创建数据库实例之前就定义好数据文件,日志文件和数据页大小等相关属性
指定配置文件位置
MySQL实例启动需要依赖my.cnf配置文件, 而配置文件可以存在于多个操作系统目录下my.cnf文件的默认查找路径,从上到下找到的文件先读,但优先级逐级提升

系统表空间数据文件配置
可以通过innodb_data_file_path和innodb_data_home_dir来配置系统表空间数据文件
Innodb_data_file_path可以包含一个或多个数据文件,中间用;号分开
innodb_data_file_path=datafile_spec1[;datafile_spec2]…
datafile_spec1 = file_name:file_size[:autoextend[:max:max_file_size]]
其中autoextend和max选项只能用作最后的这个数据文件。 Autoextend默认情况下是一次增
加64MB,如果要修改此值可通过innodb_autoextend_increment参数。 Max用来指定可扩展数据文件的最大容量用来避免数据文件大小超过可用磁盘空间大小。
mysql> show variables like '%innodb_data%';
+-----------------------+------------------------+
| Variable_name | Value |
+-----------------------+------------------------+
| innodb_data_file_path | ibdata1:12M:autoextend |
| innodb_data_home_dir | |
+-----------------------+------------------------+
默认是12M
举例如下:
[mysqld]
innodb_data_file_path=ibdata1:50M;ibdata2:50M:autoextend
表示指定ibdata1和ibdata2两个数据文件,其中ibdata1文件为固定的50M大小,而ibdata2文件初始化为50M并可自动扩展容量
[mysqld]
innodb_data_file_path=ibdata1:12M:autoextend:max:500M innodb_data_home_dir参数用来显示指定数据文件的存储目录,默认是MySQL安装后的数据文件目录,举例如下:
[mysqld]
innodb_data_home_dir = /path/to/myibdata/
innodb_data_file_path=ibdata1:50M;ibdata2:50M:autoextend
当然也可以在innodb_data_file_path中指定绝对路径的数据文件
[mysqld]
innodb_data_home_dir =
innodb_data_file_path=/path/to/myibdata/ibdata1:50M;/path/to/myibdata/ibdata2:50M:autoextend
使用老版本mysql 一定要注意ibdata1 的大小,当ibdata1几十G或者几百G,要对这个ibdata1压缩的时候该怎么办了,先把所有的数据给mysqldump出来,从新在弄一份数据库把数据库导进去
5.7和5.6 是每张表都有一个表空间 表名.ibd,因为5.6有个参数开启了独立表空间
5.7和5.6 是每张表都有一个表空间 表名.ibd
日志文件配置
默认情况下InnoDB会在数据文件夹下创建两个48M的日志文件,分别是ib_logfile0和ib_logfile1。
Innodb_log_group_home_dir参数用来定义redo日志的文件位置
mysql> show variables like '%innodb_log_file%';
+---------------------------+----------+
| Variable_name | Value |
+---------------------------+----------+
| innodb_log_file_size | 50331648 |
| innodb_log_files_in_group | 2 |
+---------------------------+----------+ innodb_log_file_size 定义的ib_logfile的大小
innodb_log_files_in_group 定义的几个日志文件默认是两个ib_logfile0和ib_logfile1
my.cnf
[mysqld]
innodb_log_group_home_dir = /dr3/iblogs
innodb_log_files_in_group参数用来定义日志文件的个数,默认和推荐值都是2
innodb_log_file_size参数定义了每个日志文件的大小
日志文件越大意味着buffer pool进行文件间切换的操作越少,从而减少IO,一般至少要保证在高峰期的1小时内的所有日志都能存放在一个日志文件里而不发生切换,如果一小时发生了切换这时候就要改变日志文件大小,当然文件大小也有最大限制,就是所有日志文件的总大小不能超过512G
时间间隔很大说明能支持数据库繁忙程度很小
Undo表空间配置
默认情况下, undo日志是存放在系统表空间里,但也可以选择在独立的一个或多个undo表空间中存放undo日志
Innodb_undo_directory参数决定了独立的undo表空间存放目录
Innodb_undo_logs参数决定了回滚段的个数,该变量可以动态调整
Innodb_undo_tablespaces参数决定了独立undo表空间的个数,比如设置为16时则会在undo表空间存放目录下创建16个undo文件,默
认为10M
mysql> show variables like '%innodb_undo%';
+--------------------------+-------+
| Variable_name | Value |
+--------------------------+-------+
| innodb_undo_directory | ./ |
| innodb_undo_log_truncate | OFF |
| innodb_undo_logs | 128 |
| innodb_undo_tablespaces | 0 |
临时表空间配置
默认情况下, innodb会创建一个自增长的ibtmp1文件在数据文件夹下作为临时表空间数据文件。
Innodb_temp_data_file_path参数可以指定文件路径,文件名和文件大小
mysql> show variables like '%innodb_temp%';
+----------------------------+-----------------------+
| Variable_name | Value |
+----------------------------+-----------------------+
| innodb_temp_data_file_path | ibtmp1:12M:autoextend |
+----------------------------+-----------------------+
数据页配置
Innodb_page_size参数用来指定所有innodb表空间的数据页大小。 默认是16K大小,也可以设置为64K、 32K、 8K和4K。一般设置为存储磁盘的block size接近的大小.
内存相关配置
Innodb_buffer_pool_size参数确定了缓存表数据和索引数据的内存区域大小,默认为128M,推荐设置为系统内存的50%~80%。
在服务器有大量内存的情况下,也可以设置多个缓存以提高系统并发度。
Innodb_buffer_pool_instances参数就是用来做这个设置。
Innodb_log_buffer_size参数确定了redo log缓存的大小,默认值是16M, 其大小取决于是否有某些大的事务会大量修改数据而导致在事务执行过程中就要写日志文件。
InnoDB 只读设置
InnoDB可以通过—innodb-read-only参数设置数据表只能读取 ,默认是0
[mysqld]
innodb-read-only=1 #表示开启innodb_read_only
mysql> show variables like '%read_only%';
+-----------------------+-------+
| Variable_name | Value |
+-----------------------+-------+
| innodb_read_only | OFF |
| read_only | OFF |
| super_read_only | OFF |
| transaction_read_only | OFF |
| tx_read_only | OFF |
+-----------------------+-------+
innodb_read_only 开启 对所有的innodb的表都是只读权限 。
read_only 开启 只对普通用户的innodb的表 是只读权限 对管理员无效 如果要使其普通用户生效,加上super权限。
mysql> show grants for yj@localhost;
+----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Grants for yj@localhost |
+----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| GRANT SUPER ON *.* TO 'yj'@'localhost' |
| GRANT SELECT, INSERT, DELETE, CREATE, REFERENCES, INDEX, ALTER, CREATE TEMPORARY TABLES, LOCK TABLES, EXECUTE, CREATE VIEW, SHOW VIEW, CREATE ROUTINE, ALTER ROUTINE, EVENT, TRIGGER ON `book`.* TO 'yj'@'localhost' |
+----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
InnoDB buffer pool 配置
InnoDB buffer pool设置
Buffer pool是内存中用来缓存数据和索引的存储区域,其是MySQL性能调优的重要一环。
理想情况下,设置的size越大,则缓存到内存的数据越多, InnoDB就越像是内存数据库。
Buffer pool的底层是一个列表,通过LRU算法进行数据页的换进换出操作。当空间原因导致新页的加入需要换出一页时, InnoDB取出最近最少使用的页并将这个新的数据页加入到列表的中央。从方向上看,列表的头部是最常使用的数据页,而在尾部则是最少使用的数据页。
Buffer pool中3/8的部分是保存最少使用的数据页,而中央部分其实是经常使用和最少使用的结合点。当在最少使用中保存的数据页被访问时,则数据页就会被移动到列表的头部变成最常使用的。
配置大小
InnoDB buffer pool的大小可以在启动时配置,也可以在启动之后配置。
增加和减少buffer pool的大小都是以大块的方式,块的大小由参数innodb_buffer_pool_chunk_size决定,默认为128M。
Innodb_buffer_pool_size的大小可以自行设定,但必须是
innodb_buffer_pool_chunk_size*innodb_buffer_pool_instances的整数倍,如果不是,则buffer pool会被调整成大于设定值且最接近的一个值
如下列
mysql> show variables like '%innodb_buffer_pool%'
-> ;
+-------------------------------------+----------------+
| Variable_name | Value |
+-------------------------------------+----------------+
| innodb_buffer_pool_chunk_size | 134217728 |
| innodb_buffer_pool_dump_at_shutdown | ON |
| innodb_buffer_pool_dump_now | OFF |
| innodb_buffer_pool_dump_pct | 25 |
| innodb_buffer_pool_filename | ib_buffer_pool |
| innodb_buffer_pool_instances | 1 |
| innodb_buffer_pool_load_abort | OFF |
| innodb_buffer_pool_load_at_startup | ON |
| innodb_buffer_pool_load_now | OFF |
| innodb_buffer_pool_size | 134217728 |
+-------------------------------------+----------------+ mysql> select 134217728/1024/1024
-> ;
+---------------------+
| 134217728/1024/1024 |
+---------------------+
| 128.00000000 |
+---------------------+
1 row in set (0.00 sec) #动态修改一下InnoDB_buffer_size 给加大一个1 Bytes 看看是增加为134217729还是 134217728的整数倍 mysql> set global innodb_buffer_pool_size=134217729;
Query OK, 0 rows affected, 1 warning (0.00 sec) #是变成了整数陪
mysql> show variables like '%innodb_buffer_pool%'
-> ;
+-------------------------------------+----------------+
| Variable_name | Value |
+-------------------------------------+----------------+
| innodb_buffer_pool_chunk_size | 134217728 |
| innodb_buffer_pool_dump_at_shutdown | ON |
| innodb_buffer_pool_dump_now | OFF |
| innodb_buffer_pool_dump_pct | 25 |
| innodb_buffer_pool_filename | ib_buffer_pool |
| innodb_buffer_pool_instances | 1 |
| innodb_buffer_pool_load_abort | OFF |
| innodb_buffer_pool_load_at_startup | ON |
| innodb_buffer_pool_load_now | OFF |
| innodb_buffer_pool_size | 268435456 |
+-------------------------------------+----------------+
10 rows in set (0.00 sec) mysql> select 268435456/1024/1024
-> ;
+---------------------+
| 268435456/1024/1024 |
+---------------------+
| 256.00000000 |
+---------------------+
1 row in set (0.00 sec)
Innodb_buffer_pool_chunk_size可以自行设定,且增加和减少都要以M为单位,并只能在启动前修改,修改后的值*innodb_buffer_pool_instances不能大于buffer pool的大小,否则修改无效。
[mysqld]
innodb_buffer_pool_chunk_size=134217728
buffer pool的大小可以动态修改,用set语句直接修改,当语句发起时,会一直等到当前所有的事务结束后才执行,而一旦执行则执行过程中的其他事务如果要访问buffer pool就会等待语句执行完毕。
#动态修改
mysql> SET GLOBAL innodb_buffer_pool_size=402653184;
当执行online的调整大小时,可以通过error log或者innodb_buffer_pool_resize_status查看进度
mysql> SHOW STATUS WHERE Variable_name='InnoDB_buffer_pool_resize_status';
+----------------------------------+----------------------------------+
| Variable_name | Value |
+----------------------------------+----------------------------------+
| Innodb_buffer_pool_resize_status | Resizing also other hash tables. |
+----------------------------------+----------------------------------+
配置多个buffer pool实例
当buffer pool的大小是GB级别时,将一个buffer poo分割成几个独立的实例能降低多个线程同时读写缓存页的竞争性而提高并发性。
通过innodb_buffer_pool_instances参数可以调整实例个数。 如果有多个实例,则缓存的数据页会随机放置到任意的实例中,且每个实例都有独立的buffer pool所有的特性。
Innodb_buffer_pool_instances的默认值是1,最大可以调整成64。
mysql> SYSTEM cat /etc/my.cnf
[mysqld]
basedir=/usr/local/mysql
datadir=/usr/local/mysql/data
port=3306
character-set-server=utf8
collation-server=utf8_unicode_ci
secure-file-priv=/tmp/
innodb_buffer_pool_instances=5
innodb_buffer_pool_size=1024M #这里我设置了实例为了 buffer_pool 为1024M mysql> show variables like '%innodb_buffer_pool%'
-> ;
+-------------------------------------+----------------+
| Variable_name | Value |
+-------------------------------------+----------------+
| innodb_buffer_pool_chunk_size | 134217728 |
| innodb_buffer_pool_dump_at_shutdown | ON |
| innodb_buffer_pool_dump_now | OFF |
| innodb_buffer_pool_dump_pct | 25 |
| innodb_buffer_pool_filename | ib_buffer_pool |
| innodb_buffer_pool_instances | 5 |
| innodb_buffer_pool_load_abort | OFF |
| innodb_buffer_pool_load_at_startup | ON |
| innodb_buffer_pool_load_now | OFF |
| innodb_buffer_pool_size | 1342177280 |
+-------------------------------------+----------------+
实际大小是buffer_pool的1280M 实例为5 可以 show engine innodb status\G; 看看几个buffer 实例 会从1280平均分给buffer pool 实例
Making the Buffer Pool Scan Resistant
新读取的数据页被插入到buffer pool的LRU列表的中间位置,默认位置是从尾部开始算起的3/8的位置。当被放入buffer pool的页被第一次访问时就开始往列表的前方移动,而这样列表的后部就是不经常访问的页甚至是从不访问的页。
通过参数innodb_old_blocks_pct可以控制列表中”old” 数据页所占的百分比,默认是37%,等同于3/8,取值范围是5~95。
Innodb_old_blocks_time参数默认是1000毫秒,指定了页面读取到buffer pool后但没有移动到经常被访问列表位置的时间窗口。
InnoDB buffer pool预存取(read-ahead)
Read ahead是异步地预先获取多个数据页到buffer pool的IO操作,这些数据页都是假定会随后被用到的。 InnoDB通过两种read-ahead算法提高IO性能:
线性read ahead:预测哪些页会被顺序访问。通过innodb_read_ahead_threshold参数调整顺序数据页的数量。当从一个区中顺序读取的页数量大于等于
innodb_read_ahead_threshold时, innodb会触发异步read ahead操作将真个区都读到buffer pool中。该参数的默认值是56,取值范围是0~64。 随机read ahead:通过已经在buffer pool中的数据页来预测哪些页会被随后访问到。如果13个连续的处于相同区的页存在于buffer pool中,则InnoDB会把同一个区的其它页都读取进来。通过设置innodb_random_read_ahead=ON来开启此方式。
通过执行show engine innodb status命令显示的三个参数判断read-ahead算法的有效性:
Innodb_buffer_pool_read_ahead
Innodb_buffer_pool_read_ahead_evicted
Innodb_buffer_pool_read_ahead_rnd
InnoDB buffer pool flushing配置
Innodb会在后台将buffer pool中的脏页(已经修改但没有写到数据文件)flush掉。当buffer pool中的脏页所占百分比达到innodb_max_dirty_pages_pct_lvm会触发flush,当所占比例达到innodb_max_dirty_pages_pct时,则innodb会“强烈” 的flush。
针对数据修改操作频繁的系统, flush可能会严重滞后导致有大量的buffer pool内存占用,有一些参数专门针对修改繁忙的系统可以调整:
Innodb_adaptive_flushing_lwm:为防止redo log被填满,此参数设置一个阈值,如果redo log的容量超过此阈值,则执行adaptive flush操作。
Innodb_max_drity_pages_pct_lwm
Innodb_io_capacity_max
Innodb_flushing_avg_loops
重置buffer pool状态
InnoDB可以通过配置innodb_buffer_pool_dump_at_shutdown参数来确保在mysql正常重启时部分经常使用的数据页能直接加载到buffer pool中,通过批量加载的方式, 以节省重启mysql导致的warmup时间(原先在buffer pool中的数据页要从磁盘再次加载到内存中)。
Buffer pool的状态可以在任意时刻被保存,而重置状态也可以恢复任意保存的副本。
在数据库运行期间动态配置buffer pool数据页保留占比的方式是:
SET GLOBAL innodb_buffer_pool_dump_pct=40; 而在配置文件中的配置方法为:
[mysqld]
innodb_buffer_pool_dump_pct=40
配置当服务器关闭时保存buffer pool的当前状态的方法是:
SET GLOBAL innodb_buffer_pool_dump_at_shutdown=ON; mysqld --innodb_buffer_pool_load_at_startup=ON;
默认情况下innodb_buffer_pool_dump_at_shutdown和innodb_buffer_pool_load_at_startup两个配置
是开启状态
在关闭MySQL时,会把内存中的热数据保存在磁盘里ib_buffer_pool文件中,位于数据目录下。
数据库运行期间保存和重新加载buffer pool的方法是:
SET GLOBAL innodb_buffer_pool_dump_now=ON;
SET GLOBAL innodb_buffer_pool_load_now=ON;
查看buffer pool保存和重新加载的进度的方法是:
mysql> SHOW STATUS LIKE 'Innodb_buffer_pool_dump_status';
+--------------------------------+--------------------------------------------------+
| Variable_name | Value |
+--------------------------------+--------------------------------------------------+
| Innodb_buffer_pool_dump_status | Buffer pool(s) dump completed at 170519 0:16:28 |
+--------------------------------+--------------------------------------------------+
1 row in set (0.00 sec) mysql> SHOW STATUS LIKE 'Innodb_buffer_pool_load_status';
+--------------------------------+--------------------------------------------------+
| Variable_name | Value |
+--------------------------------+--------------------------------------------------+
| Innodb_buffer_pool_load_status | Buffer pool(s) load completed at 170519 0:14:05 |
+--------------------------------+--------------------------------------------------+
1 row in set (0.00 sec)
监控buffer pool的状态情况
通过show engine innodb status\G;命令可以查看buffer pool的运行情况
mysql> show engine innodb status\G;
*************************** 1. row ***************************
Type: InnoDB
Name:
Status:
=====================================
2018-08-15 22:55:43 0x7f5b69b4e700 INNODB MONITOR OUTPUT
=====================================
Per second averages calculated from the last 39 seconds
-----------------
BACKGROUND THREAD
-----------------
srv_master_thread loops: 4 srv_active, 0 srv_shutdown, 18800 srv_idle
srv_master_thread log flush and writes: 18804
----------
SEMAPHORES
----------
OS WAIT ARRAY INFO: reservation count 2
OS WAIT ARRAY INFO: signal count 2
RW-shared spins 0, rounds 4, OS waits 2
RW-excl spins 0, rounds 0, OS waits 0
RW-sx spins 0, rounds 0, OS waits 0
Spin rounds per wait: 4.00 RW-shared, 0.00 RW-excl, 0.00 RW-sx
------------
TRANSACTIONS
------------
Trx id counter 35363587
Purge done for trx's n:o < 0 undo n:o < 0 state: running but idle
History list length 0
LIST OF TRANSACTIONS FOR EACH SESSION:
---TRANSACTION 421507019233104, not started
0 lock struct(s), heap size 1136, 0 row lock(s)
--------
FILE I/O
--------
I/O thread 0 state: waiting for completed aio requests (insert buffer thread)
I/O thread 1 state: waiting for completed aio requests (log thread)
I/O thread 2 state: waiting for completed aio requests (read thread)
I/O thread 3 state: waiting for completed aio requests (read thread)
I/O thread 4 state: waiting for completed aio requests (read thread)
I/O thread 5 state: waiting for completed aio requests (read thread)
I/O thread 6 state: waiting for completed aio requests (write thread)
I/O thread 7 state: waiting for completed aio requests (write thread)
I/O thread 8 state: waiting for completed aio requests (write thread)
I/O thread 9 state: waiting for completed aio requests (write thread)
Pending normal aio reads: [0, 0, 0, 0] , aio writes: [0, 0, 0, 0] ,
ibuf aio reads:, log i/o's:, sync i/o's:
Pending flushes (fsync) log: 0; buffer pool: 0
480 OS file reads, 131 OS file writes, 7 OS fsyncs
0.00 reads/s, 0 avg bytes/read, 0.00 writes/s, 0.00 fsyncs/s
-------------------------------------
INSERT BUFFER AND ADAPTIVE HASH INDEX
-------------------------------------
Ibuf: size 1, free list len 0, seg size 2, 0 merges
merged operations:
insert 0, delete mark 0, delete 0
discarded operations:
insert 0, delete mark 0, delete 0
Hash table size 332099, node heap has 2 buffer(s)
Hash table size 332099, node heap has 0 buffer(s)
Hash table size 332099, node heap has 0 buffer(s)
Hash table size 332099, node heap has 0 buffer(s)
Hash table size 332099, node heap has 0 buffer(s)
Hash table size 332099, node heap has 0 buffer(s)
Hash table size 332099, node heap has 0 buffer(s)
Hash table size 332099, node heap has 2 buffer(s)
0.00 hash searches/s, 0.00 non-hash searches/s
---
LOG
---
Log sequence number 3964869295
Log flushed up to 3964869295
Pages flushed up to 3964869295
Last checkpoint at 3964869286
0 pending log flushes, 0 pending chkp writes
10 log i/o's done, 0.00 log i/o's/second
----------------------
BUFFER POOL AND MEMORY
----------------------
Total large memory allocated 1374289920
Dictionary memory allocated 102398
Buffer pool size 81910
Free buffers 81395
Database pages 511
Old database pages 0
Modified db pages 0
Pending reads 0
Pending writes: LRU 0, flush list 0, single page 0
Pages made young 0, not young 0
0.00 youngs/s, 0.00 non-youngs/s
Pages read 453, created 58, written 114
0.00 reads/s, 0.00 creates/s, 0.00 writes/s
No buffer pool page gets since the last printout
Pages read ahead 0.00/s, evicted without access 0.00/s, Random read ahead 0.00/s
LRU len: 511, unzip_LRU len: 0
I/O sum[0]:cur[0], unzip sum[0]:cur[0]
----------------------
INDIVIDUAL BUFFER POOL INFO
----------------------
---BUFFER POOL 0
Buffer pool size 16382
Free buffers 16226
Database pages 155
Old database pages 0
Modified db pages 0
Pending reads 0
Pending writes: LRU 0, flush list 0, single page 0
Pages made young 0, not young 0
0.00 youngs/s, 0.00 non-youngs/s
Pages read 155, created 0, written 2
0.00 reads/s, 0.00 creates/s, 0.00 writes/s
No buffer pool page gets since the last printout
Pages read ahead 0.00/s, evicted without access 0.00/s, Random read ahead 0.00/s
LRU len: 155, unzip_LRU len: 0
I/O sum[0]:cur[0], unzip sum[0]:cur[0]
.....
InnoDB 其他配置
InnoDB change buffer设置
change buffering是MySQL5.5加入的新特性, change buffering是insert buffer的加强, insert buffer只针对insert有效, change buffering对insert、 delete、 update(delete+insert)、 purge都有效。当修改一个索引块(secondary index)时的数据时,索引块在buffter pool中不存在,修改信息就会被cache在change buffer中,当通过索引扫描把需要的索引块读取到buffer pool时,会和change buffer中修改信息合并,再择机写回disk。
目的还是为了减少随机IO带来性能损耗
Change buffer是作为buffer pool中的一部分存在。
Innodb_change_buffering参数缓存所对应的操作: (update会被认为是delete+insert)
all: 默认值,缓存insert, delete, purges操作
none: 不缓存
inserts: 缓存insert操作
deletes: 缓存delete操作
changes: 缓存insert和delete操作
purges: 缓存后台执行的物理删除操作
innodb_change_buffer_max_size参数配置change buffer在buffer pool中所占的最大百分比,默认是25%,最大可以设置为50%。 当MySQL实例中有大量的修改操作时,要考虑增大innodb_change_buffer_max_size。
InnoDB线程并发度配置
InnoDB利用操作系统的线程技术达到多线程实现。
Innodb_thread_concurrency参数限制同时执行的线程数。默认值是0代表没有限制。
Innodb_thread_sleep_delay参数确定
InnoDB后台IO线程配置
通过配置innodb_read_io_threads和innodb_write_io_threads参数来指定后台读和写数据页的线程的个数,默认值是4,容许的取值范围是1-64。
mysql> show engine innodb status\G
FILE I/O
--------
I/O thread 0 state: waiting for completed aio requests (insert buffer thread)
I/O thread 1 state: waiting for completed aio requests (log thread)
I/O thread 2 state: waiting for completed aio requests (read thread)
I/O thread 3 state: waiting for completed aio requests (read thread)
I/O thread 4 state: waiting for completed aio requests (read thread)
I/O thread 5 state: waiting for completed aio requests (read thread)
I/O thread 6 state: waiting for completed aio requests (write thread)
I/O thread 7 state: waiting for completed aio requests (write thread)
I/O thread 8 state: waiting for completed aio requests (write thread)
I/O thread 9 state: waiting for completed aio requests (write thread)
....
使用Linux异步IO
InnoDB在Linux平台使用异步IO子系统完成数据文件页的读写请求,可以通过innodb_user_native_aio参数控制,默认是开启状态,并且需要libaio系统库支持
InnoDB主线程配置
InnoDB的主线程在后台承担了诸多的任务,绝大多数是和IO操作相关的,比如将buffer pool中的修改后的数据刷新的磁盘文件中。
Innodb_io_capacity参数设置了InnoDB的整体IO能力。该参数应该被设置为等同于操作系统每秒的IO操作数量。该参数可以设置为100及以上的任意数值,默认值是200。其中设置为100相当于7200RPM的磁盘性能。
InnoDB purge配置
InnoDB的purge操作是一类垃圾回收操作,是由一个或多个独立线程自动执行。通过
innodb_purge_threads参数设置purge线程的数量,如果DML操作比较复杂且涉及到多个表时,则可以考虑增加此值,最大可以设置为32.
事务被提交后,其所使用的undolog可能不再需要因此需要PurgeThread来回收已经使用并分配的undo页
InnoDB 优化器统计信息配置
Innodb表的优化器统计信息分为永久和非永久两种。
永久的优化器统计信息即使是服务器重启的情况下也会存在,其用来选出更优的执行计划以便提供更好的查询性能.
通过配置innodb_stats_auto_recalc参数来控制统计信息是否在表发生巨大变化(超过10%的行)之后是否自动更新,但由于自动更新统计信息本身是异步的,所以有时未必能马上更新,这是可以执行analyze table语句来同步更新统计信息。
Create table和alter table语句中的Stats_persistent, stats_auto_recalc, stats_sample_pages子句可用来配置单个表的优化器统计信息规则
Stats_persistent用来指定是否对此表开启永久统计资料, 1代表开启, 0代表不开启。当开启之后,
可以执行analyze table命令来收集统计资料。
Stats_auto_recalc表示是否自动对表的永久统计资料进行重新计算,默认值和全局参数innodb_stats_auto_recalc一致。1代表当表中数据10%以上更新时重新计算, 0代表不自动更新,而是通过analyze table命令重新计算
Stats_sample_pages表示当计算索引列的统计资料是需要的索引页的样本数量
优化器永久统计资料数据在系统表mysql.innodb_table_stats和mysql.innodb_index_stats表中存储,这两个表中有个字段last_update可以用来判断统计信息最后更改时间。这两个表的数据也可以被手工更改。当手工更改完数据之后,要执行flush table 表名命令来重新load此表的统计资料。innodb_table_stats表中每个目标表一行记录,而innodb_index_stats表中每个索引会有多条记录
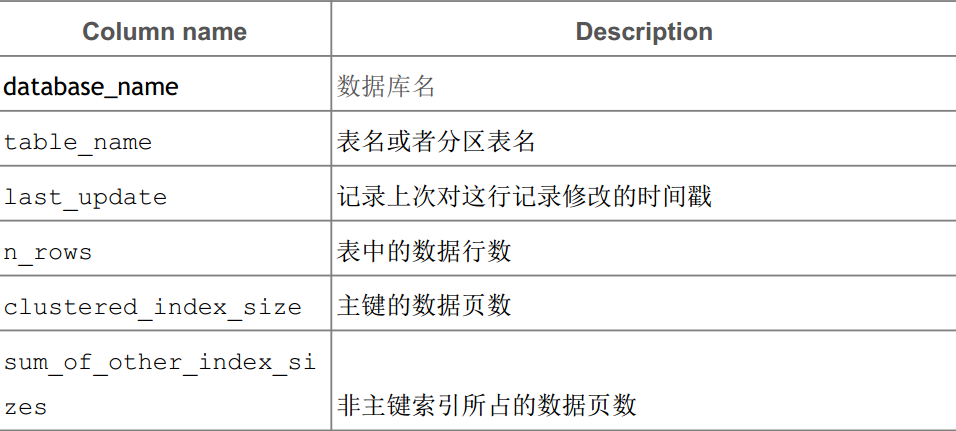
Innodb_table_stats表结构
Innodb_index_stats表结构:
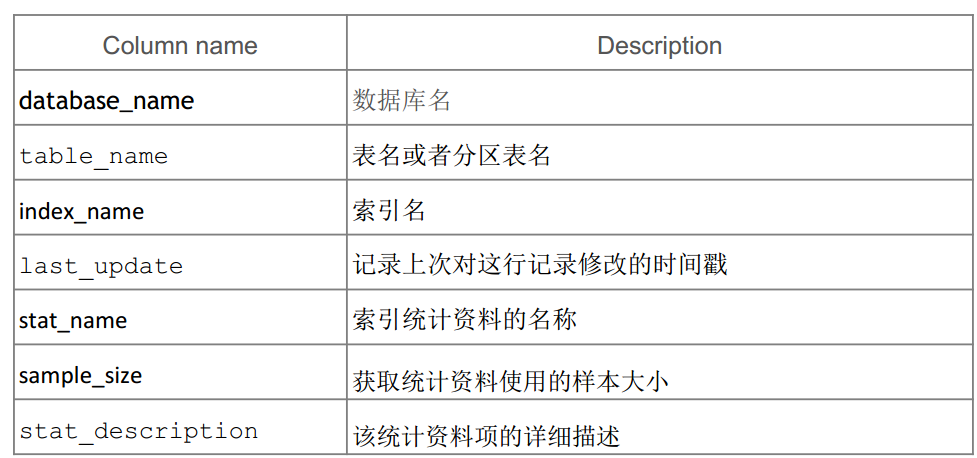
Stat_name=n_diff_pfxNN参数:当是n_diff_pfx01时stat_value列表示索引第一列上的区别值有几个,当是n_diff_pfx02时stat_value列表示索引第一、二列上的区别值有几个,以此类推。而stat_description列显示了对应的逗号可开的索引列值。
默认情况下永久优化器统计信息的属性是开启的, innodb_stats_persistent=ON
非永久优化器统计信息会在每次服务器重启或者其他一些操作时被清理。 优化器统计信息会被存储在磁盘上,通过设置innodb_stats_persistent=ON参数(默认)。
MySQL的查询优化器会基于评估好的统计资料选择合适的索引参与到执行计划中,而类似analyze table的语句会从索引中随机选取数据页参与到每个索引的基数评估中。而参数innodb_stats_persistent_sample_pages决定了参与评估的数据页的数量, 默认值是20。当语句执行的执行计划不是最优选择时,则考虑增加此参数,以便获得正确的统计资料。
当设置innodb_stats_persistent=OFF参数或者对单个表设置stats_persistent=0时,对应的统计资料就仅存在于内存中而非磁盘上,当服务器重启之后统计资料丢失。当然此类统计资料也可以周期性的更新。
比如执行analyze table语句手动刷新统计资料,或者在innodb_stats_on_metadata选项打开之后执行show table status/show index或查询information_schema.tables/statistics表时非永久统计资料会自动更新,当InnoDB检测到1/16的表数据被修改时也会更新。
索引页之间合并阈值
通过配置merge_threshold来确保当索引页的数据由于删除操作或者修改操作低于阈值, InnoDB会将此索引页和邻近的索引页合并。默认值是50,取值范围是1到50。
Merge_threshold参数可以定义在表上,也可以定义在一个独立的索引上。
CREATE TABLE t1 (
id INT,
KEY id_index (id)
) COMMENT='MERGE_THRESHOLD=45';
CREATE TABLE t1 (
id INT,
KEY id_index (id)
); ALTER TABLE t1 COMMENT='MERGE_THRESHOLD=40';
CREATE TABLE t1 (
id INT,
KEY id_index (id) COMMENT 'MERGE_THRESHOLD=40'
); CREATE TABLE t1 (id INT);
CREATE INDEX id_index ON t1 (id) COMMENT 'MERGE_THRESHOLD=40';
评估merge_threshold参数合理的方法是查看innodb_metrics表里的相关参数, 确保发生了较少的索引页合并且合并请求和成功合并的数量相当
mysql> SELECT NAME, COMMENT FROM INFORMATION_SCHEMA.INNODB_METRICS
WHERE NAME like '%index_page_merge%';
+-----------------------------+----------------------------------------+
| NAME | COMMENT |
+-----------------------------+----------------------------------------+
| index_page_merge_attempts | Number of index page merge attempts |
| index_page_merge_successful | Number of successful index page merges |
+-----------------------------+----------------------------------------+
重置InnoDB系统表空间
最简单的增加系统表空间的办法就是在初始化阶段配置数据文件的自增长,
通过配置最后一个文件的autoextend属性,当数据文件空间不足时默认自动增长64M大小。
也可以通过修改innodb_autoextend_increment参数修改自动增长的大小。
也可以通过增加另一个数据文件方法扩展表空间,步骤如下:
关闭MySQL
检查配置的最后一个数据文件是否是autoextend,如果是则根据当前数据文件的大小去掉自动扩展属性, 改成当前大小
mysql> SHOW VARIABLEs LIKE '%innodb_data_file%';
+-----------------------+------------------------+
| Variable_name | Value |
+-----------------------+------------------------+
| innodb_data_file_path | ibdata1:12M:autoextend |
+-----------------------+------------------------+
1 row in set (0.01 sec) 在my.cnf配置文件的innodb_data_file_path参数里增加一个新的数据文件,选择是否自动扩展启动MySQL innodb_data_home_dir =
innodb_data_file_path=/ibdata/ibdata1:10M:autoextend ####如果有设置改成,没有设置就添加
innodb_data_home_dir =
innodb_data_file_path = /ibdata/ibdata1:988M;/disk2/ibdata2:50M:autoextend
减小系统表空间大小的方法如下:
Mysqldump出所有的InnoDB表,包括mysql系统数据库下的五个表
mysql> select table_name from information_schema.tables where table_schema='mysql' and
engine='InnoDB';
+----------------------+
| table_name |
+----------------------+
| innodb_index_stats |
| innodb_table_stats |
| slave_master_info |
| slave_relay_log_info |
| slave_worker_info |
+----------------------+ 关闭MySQL
删除所有InnoDB的数据文件和日志文件,包括*.ibd和ib_log文件,还有在MySQL库文件夹下的*.ibd文件 删除所有.frm的InnoDB表文件 在配置文件里配置新的表空间文件 启动MySQL
导入备份出的dump文件
重置InnoDB redo log文件大小
关闭MySQL
通过innodb_log_file_size更改文件大小,通过innodb_log_files_in_group更改文件数量
my.cnf
innodb_log_file_size=30M
innodb_log_files_in_group=3 启动MySQL,看看iblogfile的数量和大小
配置单表数据文件表空间
InnoDB的单表数据文件表空间代表每个InnoDB表的数据和索引数据都存放在单独的.ibd数据文件中,每个.ibd数据文件代表独立的表空间。
此属性通过innodb_file_per_table配置。
此配置的主要优势: 当删除表或者truncate表的时候,意味着对磁盘空间可以回收。而共享表空间时删除一个表时空间不会释放而只是文件里有空闲空间
Truncate table命令要比共享表空间快
通过定义create table …data directory=绝对路径,可以将特定的表放在特定的磁盘或者存储空间
可以将单独的表物理拷贝到另外的MySQL实例中
此配置的劣势:
每个表都有未使用的空间,意味着磁盘空间有些浪费
启动单独表空间的方式如下:
[mysqld]
innodb_file_per_table=1
当设置innodb_file_per_table=0,所有创建的新表都会放置到共享表空间ibdata1里,除非在create table命令里显示的使用tablespace选项。
将已经存在于共享表空间的表修改为独立表空间的方法:
SET GLOBAL innodb_file_per_table=1;
ALTER TABLE table_name ENGINE=InnoDB;
通过命令create table … data directory=绝对路径可以将单表数据文件创建在另外的目录里。 在指定的绝对路径下,会创建数据库名相同的文件夹,里面含有此表的.ibd文件,同时在MySQL的默认数据文件下的数据库名文件夹下会创建table_name.isl文件包含了此表的路径,相当于link文件。
mysql> CREATE TABLE t1 (c1 INT PRIMARY KEY) DATA DIRECTORY = '/alternative/directory';
Query OK, 0 rows affected (0.03 sec)
# MySQL creates a .ibd file for the new table in a subdirectory that corresponding
# to the database name db_user@ubuntu:~/alternative/directory/test# ls
t1.ibd # MySQL creates a .isl file containing the path name for the table in a directory
# beneath the MySQL data directory
db_user@ubuntu:~/mysql/data/test$ ls
db.opt t1.frm t1.isl
单表迁移
不管是出于备份复制还是什么原因要将单表复制到另外的数据库实例下,可以使用传输表空间的方法
当数据库文件特别大100G的时候,导入导出特别慢,可以用单表的方式实现迁移
在原实例下创建表
mysql> use test;
mysql> CREATE TABLE t(c1 INT)engine=InnoDB; 在目标实例下创建表
mysql> use test;
mysql> CREATE TABLE t(c1 INT)engine=InnoDB; 在目标实例下将表的表空间属性去除
mysql> ALTER TABLE t DISCARD TABLESPACE; 此命令对有外键的表不支持,必须首先执行foreign_key_checks=0 在原实例下表加锁仅允许读操作,并生成.cfg元文件,防止写入数据
mysql> use test;
mysql> FLUSH TABLES t FOR EXPORT; 将.ibd和.cfg文件拷贝到目标实例的指定目录下
shell> scp /path/to/datadir/test/t.{ibd,cfg} destinationserver:/path/to/datadir/test 原实例下释放锁
mysql> use test;
mysql> UNLOCK TABLES; 目标实例下执行导入表空间操作
mysql> use test;
mysql> ALTER TABLE t IMPORT TABLESPACE;
设置Undo log独立表空间
默认情况下undo log是存储在系统表空间ibdata1里,我们也可以将其存放在一个或多个独立表空间下。
Innodb_undo_tablespaces参数定义了有多少个undo表空间,此参数只能在建立MySQL实例时被配置
innodb_undo_directory参数定义了undo表空间的存放路径
innodb_undo_logs参数定义了回滚段的数量
mysql> show variables like '%innodb_undo%';
+--------------------------+-------+
| Variable_name | Value |
+--------------------------+-------+
| innodb_undo_directory | ./ |
| innodb_undo_log_truncate | OFF |
| innodb_undo_logs | 128 |
| innodb_undo_tablespaces | 0 |
Innodb_undo_log_truncate参数决定是否开启undo表空间清空
mysql> SET GLOBAL innodb_undo_log_truncate=ON;
当设置了此参数为ON后,则代表undo文件大小超过innodb_max_undo_log_size(默认值是128M)的都标记为清空
mysql> SELECT @@innodb_max_undo_log_size;
+----------------------------+
| @@innodb_max_undo_log_size |
+----------------------------+
| 1073741824 |
mysql> SET GLOBAL innodb_max_undo_log_size=2147483648;
Query OK, 0 rows affected (0.00 sec)
当标记为清空后,回滚段标记为非激活状态表示不接收新的事务,而已存在的事务会等到完成;然后通过purge操作将回滚段空间释放;当undo表空间的所有回滚段都释放后,表空间就会清空成初始10M大小;然后回滚段重新变成激活状态以接收新的事务
InnoDB普通表空间
什么情况下需要普通表空间
一般是当你有一些表访问比较频繁,而且你的物理磁盘性能不太一样,快的磁盘空间比较小的时候,可以考虑把这几个表通过表空间放到快的盘上。
通过create tablespace命令可以创建一个共享InnoDB表空间,和系统表空间一样,多个表可以在此表空间上存储数据, 此表空间的数据文件可以放置在任意的文件夹下。
CREATE TABLESPACE tablespace_name
ADD DATAFILE 'file_name'
[FILE_BLOCK_SIZE = value]
[ENGINE [=] engine_name] mysql> CREATE TABLESPACE `ts1` ADD DATAFILE 'ts1.ibd' Engine=InnoDB; ##创建在
MySQL数据目录下 mysql> CREATE TABLESPACE `ts1` ADD DATAFILE '/my/tablespace/directory/ts1.ibd'
Engine=InnoDB; 当创建完表空间之后,就可以通过create table …tablespace或者alter table …
tablespace命令将表增加到此表空间上 mysql> CREATE TABLE t1 (c1 INT PRIMARY KEY) TABLESPACE ts1 ROW_FORMAT=COMPACT;
mysql> ALTER TABLE t2 TABLESPACE ts1;
通过alter table命令可以将InnoDB表在系统表空间、独立表空间和普通表空间之间转化:
ALTER TABLE tbl_name TABLESPACE [=] tablespace_name ##从系统表空间或者独立表空
间上转移到普通表空间
ALTER TABLE tbl_name ... TABLESPACE [=] innodb_system ##从普通表空间或者独立表空间上转移到系统表空间
ALTER TABLE tbl_name ... TABLESPACE [=] innodb_file_per_table ##从系统表空间或者普通表空间转移到独立表空间
Alter table … tablespace语句的执行都会导致此表会重建,即使表空间的属性和之前是
一样的。
mysql> create tablespace ts1 add datafile
'/usr/local/mysql/data/ts1.ibd';
Query OK, 0 rows affected (0.02 sec)
mysql> use course; #创建了一个普通表空间
mysql> create table students4(id int,name varchar(10)) tablespace ts1;
Query OK, 0 rows affected (0.00 sec) #更改为独立表空间
mysql> alter table students4 tablespace=innodb_file_per_table; root@localhost:/usr/local/mysql/data/course# ls students4.*
students4.frm students4.ibd
当删除一个普通表空间时,首先需要保证此表空间上的所有表都被删除,否则会报错。删除表空间是用drop tablespace语句来执行。Drop database的动作会删除所有的表,但创建的tablespace不会被自动删除,必须通过drop tablespace显示执行。
普通表空间不支持临时表,而且也不支持alter table … discard tablespace和alter table …import tablespace命令。
mysql> drop tablespace ts1;
ERROR 1529 (HY000): Failed to drop TABLESPACE ts1
mysql> drop table temp123;
Query OK, 0 rows affected (0.00 sec)
mysql> drop tablespace ts1;
Query OK, 0 rows affected (0.01 sec)
创建InnoDB表
通过create table语句创建InnoDB表,因为默认存储引擎就是InnoDB,所以不需要在创建表的语句最后指定engine=innodb。
InnoDB的表数据和索引数据默认是存储在系统表空间中,但可以通过开启innodb_file_per_table选项将表数据和索引数据存放在独立表空间中。当表创建完之后,会在表所在的数据库文件夹里创建.frm文件用来存储表的结构,系统表空间对应的.ibdata文件存储数据文件,而当开启独立表空间时,则会在表所在的数据库文件夹里创建.ibd用来存储表数据和索引数据。
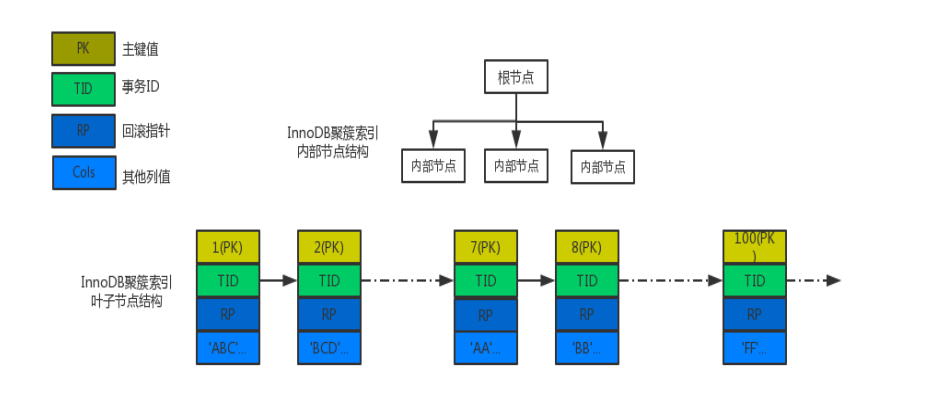
通过show table status语句可以查看InnoDB的表属性
mysql> show table status like 'user_stock'\G;
*************************** 1. row ***************************
Name: user_stock
Engine: InnoDB
Version: 10
Row_format: Dynamic
Rows: 0
Avg_row_length: 0
Data_length: 16384
Max_data_length: 0
Index_length: 0
Data_free: 0
Auto_increment: 1
Create_time: 2018-08-15 23:58:20
Update_time: NULL
Check_time: NULL
Collation: utf8_general_ci
Checksum: NULL
...
修改表的存储引擎
通过alter table语句修改已有表的存储引擎
ALTER TABLE table_name ENGINE=InnoDB;
自增长字段设置
当对InnoDB表设置了自增长字段之后,表会在内存中保存一个自增长计数器。
默认情况下自增长字段的初始值是1,但也可以通过配置auto_increment_offset参数将所有的自增长字段初始值设置为另外的值,而当表中插入数值时, InnoDB会求出当前表中的该列的最大值,然后在此基础上加1作为插入的数据。默认是以+1为增长的进度,但也可以通过auto_increment_increment配置所有自增长字段的自定义增长进度。
InnoDB表主要的限制
InnoDB表目前只支持最多1017个列
InnoDB表目前支持最大64个二级索引
多列索引目前支持最大16个列
如果表中不存在text或者blob类型字段时, 行数据整体的最大长度是65535个字节
mysql> CREATE TABLE t (a VARCHAR(8000), b VARCHAR(10000), c VARCHAR(10000), d
VARCHAR(10000), e VARCHAR(10000),f VARCHAR(10000), g VARCHAR(10000))
ENGINE=InnoDB;
ERROR 1118 (42000): Row size too large. The maximum row size for theused table type, not counting BLOBs, is 65535. You have to change some columns to TEXT or BLOBs
mysql Inoodb 内核的更多相关文章
- mysql 需要内核级线程的支持,而不只是用户级线程,这样才能够有效的使用多个cpu
mysql 需要内核级线程的支持,而不只是用户级线程,这样才能够有效的使用多个cpu
- mysql 阿里内核人员
丁奇 http://dinglin.javaeye.com/ 鸣嵩 @曹伟-鸣嵩 (新浪微博) 彭立勋 http://www.penglixun.com/ 皓庭 http://wqtn22.iteye ...
- MySQL内核:InnoDB存储引擎 卷1
MySQL内核:InnoDB存储引擎卷1(MySQL领域Oracle ACE专家力作,众多MySQL Oracle ACE力捧,深入MySQL数据库内核源码分析,InnoDB内核开发与优化必备宝典) ...
- 腾讯云数据库团队:浅谈如何对MySQL内核进行深度优化
作者介绍:简怀兵,腾讯云数据库团队高级工程师,负责腾讯云CDB内核及基础设施建设:先后供职于Thomson Reuters和YY等公司,PTimeDB作者,曾获一项发明专利:从事MySQL内核开发工作 ...
- 举个栗子看如何做MySQL 内核深度优化
本文由云+社区发表 作者介绍:简怀兵,腾讯云数据库高级工程师,负责腾讯云CDB内核及基础设施建设:先后供职于Thomson Reuters和YY等公司,PTimeDB作者,曾获一项发明专利:从事MyS ...
- 如何深度优化MySQL内核
MYSQL数据库适用场景广泛,相较于Oracle.DB2性价比更高,Web网站.日志系统.数据仓库等场景都有MYSQL用武之地,但是也存在对于事务性支持不太好(MySQL 5.5版本开始默认引擎才是I ...
- mysql中binlog与存储引擎的2PC
mysql内部的2PC mysql开启binlog后实际上可以认为其数据有两份,binlog中一份,引擎中一份(这里先把存储引擎中数据看成整体的单独一份,另外也可以把binlog看成是一个引擎).既然 ...
- MySQL复制异常大扫盲:快速溯源与排查错误全解
MySQL复制异常大扫盲:快速溯源与排查错误全解https://mp.weixin.qq.com/s/0Ic8BnUokyOj7m1YOrk1tA 作者介绍王松磊,现任职于UCloud,从事MySQL ...
- 初看mysql源代码之mysql.cc
在mysql的源代码目录中,sql目录是mysql源代码中经常变化的目录之一,也是MySQL服务器内核最为核心和重要的目录. sql目录除了包含mysqld.cc这一MySQL main函数所在文件外 ...
随机推荐
- SDK | 声波传输
SDK | 声波传输 - 音频流生成 https://github.com/CloudSide/WaveTransSdk/tree/master/c/freq_util Objective-C: ht ...
- (连通图 Tarjan)Caocao's Bridges --HDU --4738
链接: http://acm.hdu.edu.cn/showproblem.php?pid=4738 题目大意:曹操有很多岛屿,然后呢需要建造一些桥梁将所有的岛屿链接起来,周瑜要做的是就是不让曹操将所 ...
- Android操作HTTP实现与服务器通信
(转自http://www.cnblogs.com/hanyonglu/archive/2012/02/19/2357842.html) 本示例以Servlet为例,演示Android与Servlet ...
- wc.java
GitHub代码链接 1.项目相关要求 •基本功能列表: -c 统计文件中字符的个数 -w 统计文件中的词数 -l 统计文件中的行数 •拓展功能: -a 统计文件中代码行数.注释行数.空行 2 ...
- Oracle sql 优化の常用方式
1.不要用 '*' 代替所有列名,特别是字段比较多的情况下 使用select * 可以列出某个表的所有列名,但是这样的写法对于Oracle来说会存在动态解析问题.Oracle系统通过查询数据字典将 ' ...
- 单元测试工具Numega BoundsChecker
1 前言 我在本文中详细介绍了测试工具NuMega Devpartner(以下简称NuMega)的使用方法. NuMega是一个动态测试工具,主要应用于白盒测试.该工具的特点是学习简单.使用方便.功能 ...
- 两种方式创建支持SSH服务的docker镜像
方法一:基于commit命令创建 1.首先,从docker的源中查看我们需要的镜像,本案例中使用Ubuntu作为基础镜像. # federico @ linux in ~ [16:57:38] $ s ...
- [ucgui] 仪表盘函数
/* 仪表盘 */ void DrawArcScale(void) { ; ; int i; ]; GUI_SetBkColor(GUI_WHITE); GUI_Clear(); GUI_SetPen ...
- vs2017新建.netcore相关项目提示"未检测到任何.NET Core SDK"或打开.net core 相关项目Web层总是未能正常加载
近来vs2017出现一个非常怪的现象,之前新建.net core相关项目好好的,现在出现问题,如下: 解决办法,是更新vs2017,界面如下:
- django项目中使用项目环境制作脚本 通过终端命令运行脚本文件
在实际的django项目开发中,有时候需要制作一些脚本文件对项目数据进行处理,然后通过终端命令运行脚本. 完整的实现流程如下: 1.在一个应用目录下(app, 必须是在应用目录下,可以专门创建一个应用 ...