Java内存模型解惑--观深入理解Java内存模型系列文章有感(二)
1、volatile关键字修饰的域的特性
当我们声明共享变量为volatile后,对这个变量的读/写将会很特别。理解volatile特性的一个好方法是:把对volatile变量的单个读/写,看成是使用同一个锁对这些单个读/写操作做了同步。下面我们通过具体的示例来说明,请看下面的示例代码:
class VolatileFeaturesExample {
//使用volatile声明64位的long型变量
volatile long vl = 0L;
public void set(long l) {
vl = l; //单个volatile变量的写
}
public void getAndIncrement () {
vl++; //复合(多个)volatile变量的读/写
}
public long get() {
return vl; //单个volatile变量的读
}
}
假设有多个线程分别调用上面程序的三个方法,这个程序在语义上和下面程序等价:
class VolatileFeaturesExample {
long vl = 0L; // 64位的long型普通变量
//对单个的普通 变量的写用同一个锁同步
public synchronized void set(long l) {
vl = l;
}
public void getAndIncrement () { //普通方法调用
long temp = get(); //调用已同步的读方法
temp += 1L; //普通写操作
set(temp); //调用已同步的写方法
}
public synchronized long get() {
//对单个的普通变量的读用同一个锁同步
return vl;
}
}
如上面示例程序所示,对一个volatile变量的单个读/写操作,与对一个普通变量的读/写操作使用同一个锁来同步,它们之间的执行效果相同。(这个synchronize可以保证同一时间只会有一个线程进行读或者写的操作)
锁的happens-before规则保证释放锁和获取锁的两个线程之间的内存可见性,这意味着对一个volatile变量的读,总是能看到(任意线程)对这个volatile变量最后的写入。
锁的语义决定了临界区代码的执行具有原子性。这意味着即使是64位的long型和double型变量,只要它是volatile变量,对该变量的读写就将具有原子性。如果是多个volatile操作或类似于volatile++这种复合操作,这些操作整体上不具有原子性。
简而言之,volatile变量自身具有下列特性:
- 可见性。对一个volatile变量的读,总是能看到(任意线程)对这个volatile变量最后的写入。
- 原子性:对任意单个volatile变量的读/写具有原子性,但类似于volatile++这种复合操作不具有原子性。
对于可见性,JMM是这样实现的:对于任意一个变量,一旦修改,立即把本地内存更新回主内存。对于任意一个变量,一旦读取,理解把本地内存中置为无效,从主内存中获取该值并更新到本地内存。
对于原子性,最常见的是long和double型变量的值,本来是分成两步来读写的,这两步有可能被不同的线程拆开,volatile保证这样的操作不会被拆开。
同时对于一个引用类型的变量,在进行new操作时也保证了他的原子性,先举例子:
====假设线程一执行到instance = new Singleton()这句,这里看起来是一句话,但实际上它并不是一个原子操作(原子操作的意思就是这条语句要么就被执行完,要么就没有被执行过,不能出现执行了一半这种情形)。事实上高级语言里面非原子操作有很多,我们只要看看这句话被编译后在JVM执行的对应汇编代码就发现,这句话被编译成8条汇编指令,大致做了3件事情:
1.给Singleton的实例分配内存。
2.初始化Singleton的构造器
3.将instance对象指向分配的内存空间(注意到这步instance就非null了)。
但是,由于Java编译器允许处理器乱序执行(out-of-order),以及JDK1.5之前JMM(Java Memory Medel)中Cache、寄存器到主内存回写顺序的规定,上面的第二点和第三点的顺序是无法保证的,也就是说,执行顺序可能是1-2-3也可能是1-3-2,如果是后者,并且在3执行完毕、2未执行之前,被切换到线程二上,这时候instance因为已经在线程一内执行过了第三点,instance已经是非空了,所以线程二直接拿走instance,然后使用,然后顺理成章地报错,而且这种难以跟踪难以重现的错误估计调试上一星期都未必能找得出来。 ====
在上面这种情况下,volatile保证了instance变量的原子性,禁止把3重排序到前面,即禁止volatile变量赋值之前的重排序。(也可以理解为在给instance设置的set方法上加入了synchronized,并且new的过程是在set中发生的,但是这样好像有点不合理,就禁止重排序是最好的理解)
最后说的volatile++操作无效是因为这个操作是复合的,包含了渎与写的操作,但是在读写的中间过程是没有进行同步的,有可能被其他线程插入,这就是在前二篇文章中提到的最后不为1000的原因。
1.1、volatile的写-读建立的happens before关系
上面讲的是volatile变量自身的特性,对程序员来说,volatile对线程的内存可见性的影响比volatile自身的特性更为重要,也更需要我们去关注。
从JSR-133开始,volatile变量的写-读可以实现线程之间的通信。
从内存语义的角度来说,volatile与锁有相同的效果:volatile写和锁的释放有相同的内存语义;volatile读与锁的获取有相同的内存语义。
class VolatileExample {
int a = 0;
volatile boolean flag = false;
public void writer() {
a = 1; //
flag = true; //
}
public void reader() {
if (flag) { //
int i = a; //
……
}
}
}
假设线程A执行writer()方法之后,线程B执行reader()方法。根据happens before规则,这个过程建立的happens before 关系可以分为两类:
- 根据程序次序规则,1 happens before 2; 3 happens before 4。
- 根据volatile规则,2 happens before 3。
- 根据happens before 的传递性规则,1 happens before 4。
上述happens before 关系的图形化表现形式如下:
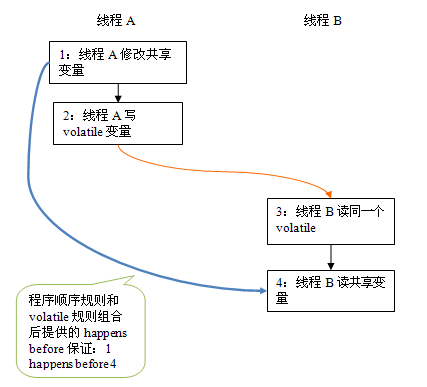
在上图中,每一个箭头链接的两个节点,代表了一个happens before 关系。黑色箭头表示程序顺序规则;橙色箭头表示volatile规则;蓝色箭头表示组合这些规则后提供的happens before保证。
这里A线程写一个volatile变量后,B线程读同一个volatile变量。A线程在写volatile变量之前所有可见的共享变量,在B线程读同一个volatile变量后,将立即变得对B线程可见。
2、volatile写-读的内存语义
volatile写的内存语义如下:
当写一个volatile变量时,JMM会把该线程对应的本地内存中的共享变量刷新到主内存。
以上面示例程序VolatileExample为例,假设线程A首先执行writer()方法,随后线程B执行reader()方法,初始时两个线程的本地内存中的flag和a都是初始状态。下图是线程A执行volatile写后,共享变量的状态示意图: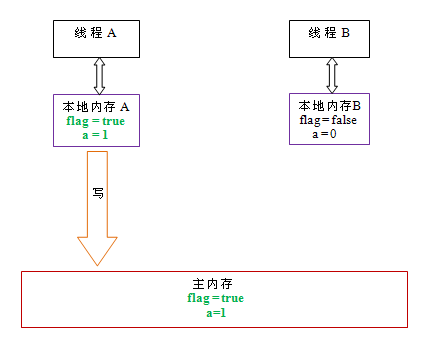
如上图所示,线程A在写flag变量后,本地内存A中被线程A更新过的两个共享变量的值被刷新到主内存中。此时,本地内存A和主内存中的共享变量的值是一致的。
volatile读的内存语义如下:
当读一个volatile变量时,JMM会把该线程对应的本地内存置为无效。线程接下来将从主内存中读取共享变量。
下面是线程B读同一个volatile变量后,共享变量的状态示意图: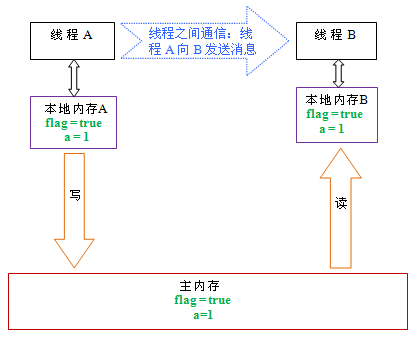
如上图所示,在读flag变量后,本地内存B已经被置为无效。此时,线程B必须从主内存中读取共享变量。线程B的读取操作将导致本地内存B与主内存中的共享变量的值也变成一致的了。
如果我们把volatile写和volatile读这两个步骤综合起来看的话,在读线程B读一个volatile变量后,写线程A在写这个volatile变量之前所有可见的共享变量的值都将立即变得对读线程B可见。
下面对volatile写和volatile读的内存语义做个总结:
- 线程A写一个volatile变量,实质上是线程A向接下来将要读这个volatile变量的某个线程发出了(其对共享变量所在修改的)消息。
- 线程B读一个volatile变量,实质上是线程B接收了之前某个线程发出的(在写这个volatile变量之前对共享变量所做修改的)消息。
- 线程A写一个volatile变量,随后线程B读这个volatile变量,这个过程实质上是线程A通过主内存向线程B发送消息。
3、volatile内存语义的实现(不仅实时同步主内存,而且要限制重排序已达成内存语义)
下面,让我们来看看JMM如何实现volatile写/读的内存语义。
前文我们提到过重排序分为编译器重排序和处理器重排序。为了实现volatile内存语义,JMM会分别限制这两种类型的重排序类型。下面是JMM针对编译器制定的volatile重排序规则表:
| 是否能重排序 | 第二个操作 | ||
| 第一个操作 | 普通读/写 | volatile读 | volatile写 |
| 普通读/写 | NO | ||
| volatile读 | NO | NO | NO |
| volatile写 | NO | NO | |
这里的第一个操作是普通读/写,第二个操作是volatile写是禁止重排序的,这就是上面保证引用类型的原子性里的禁止情况。
举例来说,第三行最后一个单元格的意思是:在程序顺序中,当第一个操作为普通变量的读或写时,如果第二个操作为volatile写,则编译器不能重排序这两个操作。
从上表我们可以看出:
- 当第二个操作是volatile写时,不管第一个操作是什么,都不能重排序。这个规则确保volatile写之前的操作不会被编译器重排序到volatile写之后。
- 当第一个操作是volatile读时,不管第二个操作是什么,都不能重排序。这个规则确保volatile读之后的操作不会被编译器重排序到volatile读之前。
- 当第一个操作是volatile写,第二个操作是volatile读时,不能重排序。
为了实现volatile的内存语义,编译器在生成字节码时,会在指令序列中插入内存屏障来禁止特定类型的处理器重排序。对于编译器来说,发现一个最优布置来最小化插入屏障的总数几乎不可能,为此,JMM采取保守策略。下面是基于保守策略的JMM内存屏障插入策略:
- 在每个volatile写操作的前面插入一个StoreStore屏障。
- 在每个volatile写操作的后面插入一个StoreLoad屏障。
- 在每个volatile读操作的后面插入一个LoadLoad屏障。
- 在每个volatile读操作的后面插入一个LoadStore屏障。
上述内存屏障插入策略非常保守,但它可以保证在任意处理器平台,任意的程序中都能得到正确的volatile内存语义。
下面是保守策略下,volatile写插入内存屏障后生成的指令序列示意图: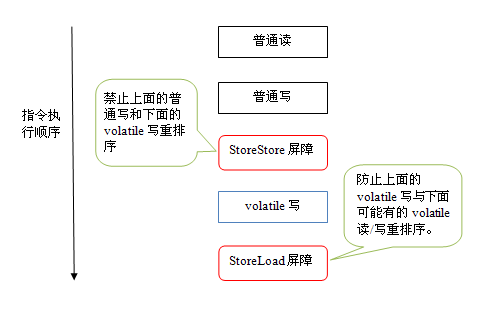
上图中的StoreStore屏障可以保证在volatile写之前,其前面的所有普通写操作已经对任意处理器可见了。这是因为StoreStore屏障将保障上面所有的普通写在volatile写之前刷新到主内存。
这里比较有意思的是volatile写后面的StoreLoad屏障。这个屏障的作用是避免volatile写与后面可能有的volatile读/写操作重排序。因为编译器常常无法准确判断在一个volatile写的后面,是否需要插入一个StoreLoad屏障(比如,一个volatile写之后方法立即return)。为了保证能正确实现volatile的内存语义,JMM在这里采取了保守策略:在每个volatile写的后面或在每个volatile读的前面插入一个StoreLoad屏障。从整体执行效率的角度考虑,JMM选择了在每个volatile写的后面插入一个StoreLoad屏障。因为volatile写-读内存语义的常见使用模式是:一个写线程写volatile变量,多个读线程读同一个volatile变量。当读线程的数量大大超过写线程时,选择在volatile写之后插入StoreLoad屏障将带来可观的执行效率的提升。从这里我们可以看到JMM在实现上的一个特点:首先确保正确性,然后再去追求执行效率。
下面是在保守策略下,volatile读插入内存屏障后生成的指令序列示意图:
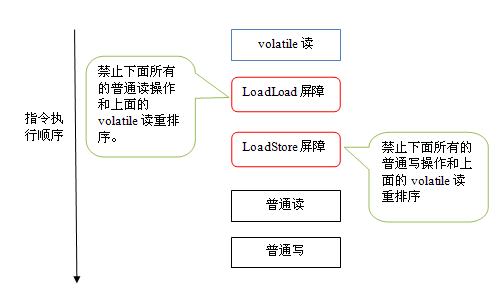
上图中的LoadLoad屏障用来禁止处理器把上面的volatile读与下面的普通读重排序。LoadStore屏障用来禁止处理器把上面的volatile读与下面的普通写重排序。
上述volatile写和volatile读的内存屏障插入策略非常保守。在实际执行时,只要不改变volatile写-读的内存语义,编译器可以根据具体情况省略不必要的屏障。下面我们通过具体的示例代码来说明:
class VolatileBarrierExample {
int a;
volatile int v1 = 1;
volatile int v2 = 2;
void readAndWrite() {
int i = v1; //第一个volatile读
int j = v2; // 第二个volatile读
a = i + j; //普通写
v1 = i + 1; // 第一个volatile写
v2 = j * 2; //第二个 volatile写
}
… //其他方法
}
针对readAndWrite()方法,编译器在生成字节码时可以做如下的优化:
注意,最后的StoreLoad屏障不能省略。因为第二个volatile写之后,方法立即return。此时编译器可能无法准确断定后面是否会有volatile读或写,为了安全起见,编译器常常会在这里插入一个StoreLoad屏障。
上面的优化是针对任意处理器平台,由于不同的处理器有不同“松紧度”的处理器内存模型,内存屏障的插入还可以根据具体的处理器内存模型继续优化。以x86处理器为例,上图中除最后的StoreLoad屏障外,其它的屏障都会被省略。
前面保守策略下的volatile读和写,在 x86处理器平台可以优化成: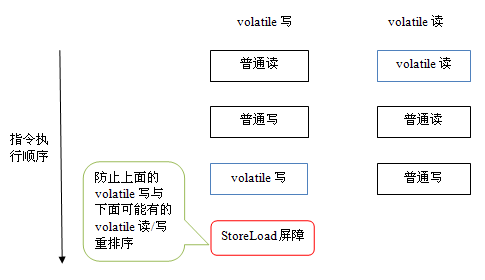
前文提到过,x86处理器仅会对写-读操作做重排序。X86不会对读-读,读-写和写-写操作做重排序,因此在x86处理器中会省略掉这三种操作类型对应的内存屏障。在x86中,JMM仅需在volatile写后面插入一个StoreLoad屏障即可正确实现volatile写-读的内存语义。这意味着在x86处理器中,volatile写的开销比volatile读的开销会大很多(因为执行StoreLoad屏障开销会比较大)。
3.1、JSR-133为什么要增强volatile的内存语义
在JSR-133之前的旧Java内存模型中,虽然不允许volatile变量之间重排序,但旧的Java内存模型允许volatile变量与普通变量之间重排序。在旧的内存模型中,VolatileExample示例程序可能被重排序成下列时序来执行: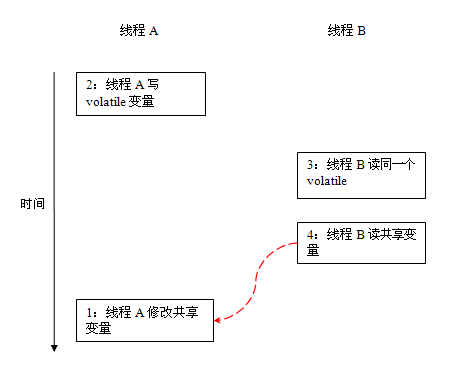
在旧的内存模型中,当1和2之间没有数据依赖关系时,1和2之间就可能被重排序(3和4类似)。其结果就是:读线程B执行4时,不一定能看到写线程A在执行1时对共享变量的修改。
因此在旧的内存模型中 ,volatile的写-读没有锁的释放-获所具有的内存语义。为了提供一种比锁更轻量级的线程之间通信的机制,JSR-133专家组决定增强volatile的内存语义:严格限制编译器和处理器对volatile变量与普通变量的重排序,确保volatile的写-读和锁的释放-获取一样,具有相同的内存语义。从编译器重排序规则和处理器内存屏障插入策略来看,只要volatile变量与普通变量之间的重排序可能会破坏volatile的内存语意,这种重排序就会被编译器重排序规则和处理器内存屏障插入策略禁止。
由于volatile仅仅保证对单个volatile变量的读/写具有原子性,而锁的互斥执行的特性可以确保对整个临界区代码的执行具有原子性。在功能上,锁比volatile更强大;在可伸缩性和执行性能上,volatile更有优势。如果读者想在程序中用volatile代替监视器锁,请一定谨慎.(http://www.ibm.com/developerworks/cn/java/j-jtp06197.html)
PS:在java1.6之后,jvm优化了synchronize的性能,所以能使用synchronize的情况下,尽量少使用volatile。(http://ifeve.com/java-synchronized/)
1.6之后,volatile变量与普通变量的界限也变得模糊了,如下:
public class VolatileExample extends Thread{
//设置类静态变量,各线程访问这同一共享变量
private static boolean flag = false;
//无限循环,等待flag变为true时才跳出循环
public void run() {while (!flag){};}
public static void main(String[] args) throws Exception {
new VolatileExample().start();
//sleep的目的是等待线程启动完毕,也就是说进入run的无限循环体了
Thread.sleep(100);
flag = true;
}
}
这种情况下,这个程序是不会终止的,如果把flag声明为volatile,则可以终止。但是如果保持没有volatile声明,在while里面加上一个println(1),则发现又可以终止了。这是怎么回事呢??
原来只有在对变量读取频率很高的情况下,虚拟机才不会及时回写主内存,而当频率没有达到虚拟机认为的高频率时,普通变量和volatile是同样的处理逻辑。如在每个循环中执行System.out.println(1)加大了读取变量的时间间隔,使虚拟机认为读取频率并不那么高,所以实现了和volatile的效果(本文开头的例子只在HotSpot24上测试过,没有在JRockit之类其余版本JDK上测过)。volatile的效果在jdk1.2及之前很容易重现,但随着虚拟机的不断优化,如今的普通变量的可见性已经不是那么严重的问题了,这也是volatile如今确实不太有使用场景的原因吧。
4、synchronize锁的释放-获取建立的happens before 关系
锁是java并发编程中最重要的同步机制。锁除了让临界区(synchronize的区域)互斥执行外,还可以让释放锁的线程向获取同一个锁的线程发送消息。下面是锁释放-获取的示例代码:(方法上的锁是锁的this对象)
class MonitorExample {
int a = 0;
public synchronized void writer() { //
a++; //
} //
public synchronized void reader() { //
int i = a; //
……
} //
}
假设线程A执行writer()方法,随后线程B执行reader()方法。根据happens before规则,这个过程包含的happens before 关系可以分为两类:
- 根据程序次序规则,1 happens before 2, 2 happens before 3; 4 happens before 5, 5 happens before 6。
- 根据监视器锁规则,3 happens before 4。
- 根据happens before 的传递性,2 happens before 5。
上述happens before 关系的图形化表现形式如下: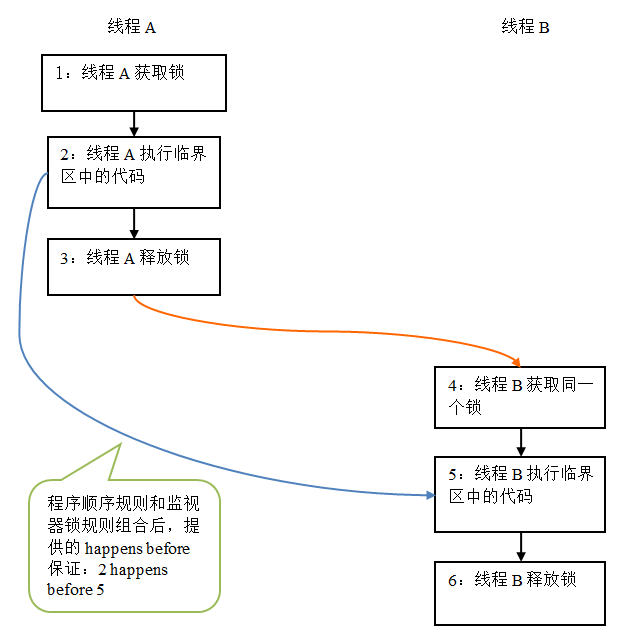
在上图中,每一个箭头链接的两个节点,代表了一个happens before 关系。黑色箭头表示程序顺序规则;橙色箭头表示监视器锁规则;蓝色箭头表示组合这些规则后提供的happens before保证。
上图表示在线程A释放了锁之后,随后线程B获取同一个锁。在上图中,2 happens before 5。因此,线程A在释放锁之前所有可见的共享变量,在线程B获取同一个锁之后,将立刻变得对B线程可见。
5、锁释放和获取的内存语义
当线程释放锁时,JMM会把该线程对应的本地内存中的共享变量刷新到主内存中。以上面的MonitorExample程序为例,A线程释放锁后,共享数据的状态示意图如下: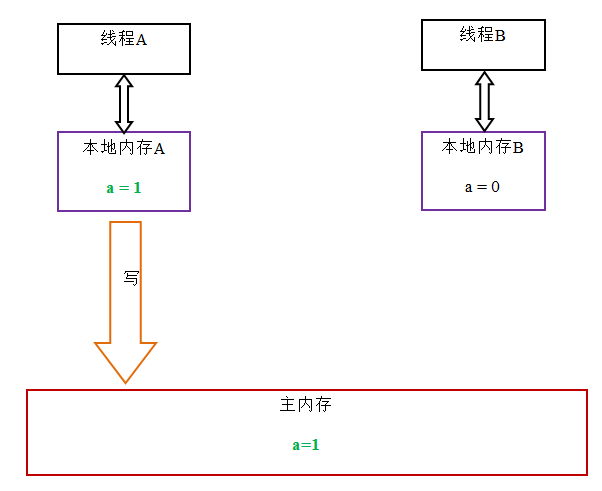
当线程获取锁时,JMM会把该线程对应的本地内存置为无效。从而使得被监视器保护的临界区代码必须要从主内存中去读取共享变量。下面是锁获取的状态示意图:
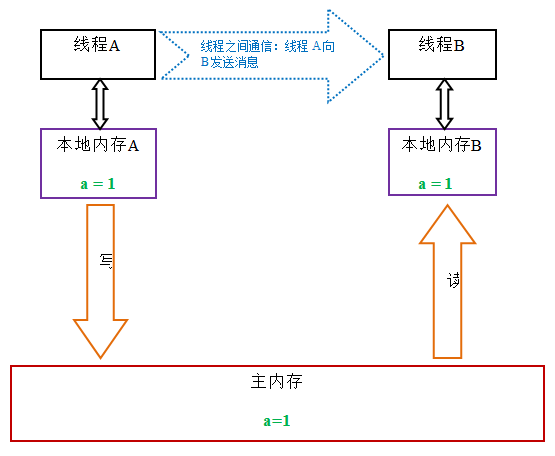
对比锁释放-获取的内存语义与volatile写-读的内存语义,可以看出:锁释放与volatile写有相同的内存语义;锁获取与volatile读有相同的内存语义。
下面对锁释放和锁获取的内存语义做个总结:
- 线程A释放一个锁,实质上是线程A向接下来将要获取这个锁的某个线程发出了(线程A对共享变量所做修改的)消息。
- 线程B获取一个锁,实质上是线程B接收了之前某个线程发出的(在释放这个锁之前对共享变量所做修改的)消息。
- 线程A释放锁,随后线程B获取这个锁,这个过程实质上是线程A通过主内存向线程B发送消息。
6、锁内存语义的实现
本文将借助ReentrantLock的源代码,来分析锁内存语义的具体实现机制。
太复杂了,不抄过来了。。。http://www.infoq.com/cn/articles/java-memory-model-5
其中涉及到CAS(compareAndSwapInt())
7、final域的特殊性
与前面介绍的锁和volatile相比较,对final域的读和写更像是普通的变量访问。对于final域,编译器和处理器要遵守两个重排序规则:
- 在构造函数内对一个final域的写入,与随后把这个被构造对象的引用赋值给一个引用变量,这两个操作之间不能重排序。
- 初次读一个包含final域的对象的引用,与随后初次读这个final域,这两个操作之间不能重排序。
public class FinalExample {
int i; //普通变量
final int j; //final变量
static FinalExample obj;
public void FinalExample () { //构造函数
i = 1; //写普通域
j = 2; //写final域
}
public static void writer () { //写线程A执行
obj = new FinalExample ();
}
public static void reader () { //读线程B执行
FinalExample object = obj; //读对象引用
int a = object.i; //读普通域
int b = object.j; //读final域
}
}
这里假设一个线程A执行writer ()方法,随后另一个线程B执行reader ()方法。下面我们通过这两个线程的交互来说明这两个规则。
7.1、写final域的重排序规则
写final域的重排序规则禁止把final域的写重排序到构造函数之外。这个规则的实现包含下面2个方面:
- JMM禁止编译器把final域的写重排序到构造函数之外。
- 编译器会在final域的写之后,构造函数return之前,插入一个StoreStore屏障。这个屏障禁止处理器把final域的写重排序到构造函数之外。
现在让我们分析writer ()方法。writer ()方法只包含一行代码:finalExample = new FinalExample ()。这行代码包含两个步骤:
- 构造一个FinalExample类型的对象;
- 把这个对象的引用赋值给引用变量obj。
假设线程B读对象引用与读对象的成员域之间没有重排序(马上会说明为什么需要这个假设),下图是一种可能的执行时序: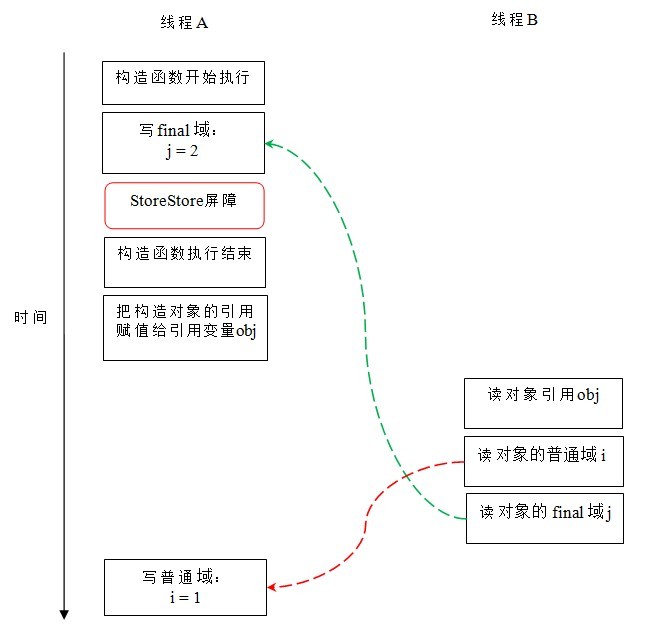
在上图中,写普通域的操作被编译器重排序到了构造函数之外,读线程B错误的读取了普通变量i初始化之前的值。而写final域的操作,被写final域的重排序规则“限定”在了构造函数之内,读线程B正确的读取了final变量初始化之后的值。
写final域的重排序规则可以确保:在对象引用为任意线程可见之前,对象的final域已经被正确初始化过了,而普通域不具有这个保障。以上图为例,在读线程B“看到”对象引用obj时,很可能obj对象还没有构造完成(对普通域i的写操作被重排序到构造函数外,此时初始值2还没有写入普通域i)。
7.2、读final域的重排序规则
读final域的重排序规则如下:
在一个线程中,初次读对象引用与初次读该对象包含的final域,JMM禁止处理器重排序这两个操作(注意,这个规则仅仅针对处理器)。编译器会在读final域操作的前面插入一个LoadLoad屏障。
初次读对象引用与初次读该对象包含的final域,这两个操作之间存在间接依赖关系。由于编译器遵守间接依赖关系,因此编译器不会重排序这两个操作。大多数处理器也会遵守间接依赖,大多数处理器也不会重排序这两个操作。但有少数处理器允许对存在间接依赖关系的操作做重排序(比如alpha处理器),这个规则就是专门用来针对这种处理器。
reader()方法包含三个操作:
- 初次读引用变量obj;
- 初次读引用变量obj指向对象的普通域j。
- 初次读引用变量obj指向对象的final域i。
现在我们假设写线程A没有发生任何重排序,同时程序在不遵守间接依赖的处理器上执行,下面是一种可能的执行时序:
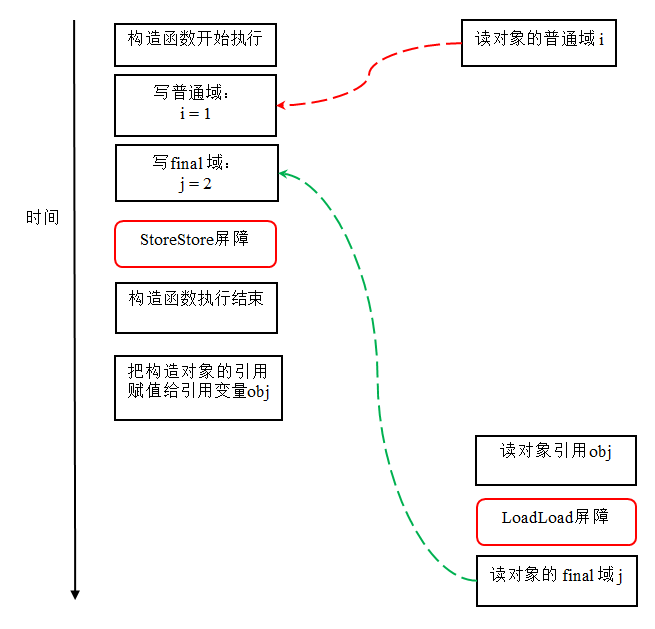
在上图中,读对象的普通域的操作被处理器重排序到读对象引用之前。读普通域时,该域还没有被写线程A写入,这是一个错误的读取操作。而读final域的重排序规则会把读对象final域的操作“限定”在读对象引用之后,此时该final域已经被A线程初始化过了,这是一个正确的读取操作。
读final域的重排序规则可以确保:在读一个对象的final域之前,一定会先读包含这个final域的对象的引用。在这个示例程序中,如果该引用不为null,那么引用对象的final域一定已经被A线程初始化过了。
7.3、如果final域是引用类型
上面我们看到的final域是基础数据类型,下面让我们看看如果final域是引用类型,将会有什么效果?
请看下列示例代码:
public class FinalReferenceExample {
final int[] intArray; //final是引用类型
static FinalReferenceExample obj;
public FinalReferenceExample () { //构造函数
intArray = new int[1]; //
intArray[0] = 1; //
}
public static void writerOne () { //写线程A执行
obj = new FinalReferenceExample (); //
}
public static void writerTwo () { //写线程B执行
obj.intArray[0] = 2; //
}
public static void reader () { //读线程C执行
if (obj != null) { //
int temp1 = obj.intArray[0]; //
}
}
}
这里final域为一个引用类型,它引用一个int型的数组对象。对于引用类型,写final域的重排序规则对编译器和处理器增加了如下约束:
在构造函数内对一个final引用的对象的成员域的写入,与随后在构造函数外把这个被构造对象的引用赋值给一个引用变量,这两个操作之间不能重排序。
对上面的示例程序,我们假设首先线程A执行writerOne()方法,执行完后线程B执行writerTwo()方法,执行完后线程C执行reader ()方法。下面是一种可能的线程执行时序:
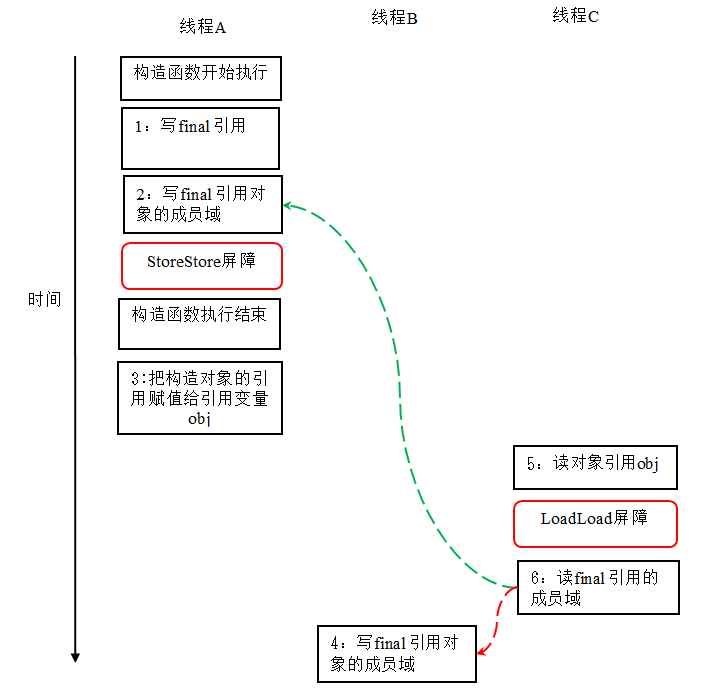
在上图中,1是对final域的写入,2是对这个final域引用的对象的成员域的写入,3是把被构造的对象的引用赋值给某个引用变量。这里除了前面提到的1不能和3重排序外,2和3也不能重排序。
JMM可以确保读线程C至少能看到写线程A在构造函数中对final引用对象的成员域的写入。即C至少能看到数组下标0的值为1。而写线程B对数组元素的写入,读线程C可能看的到,也可能看不到。JMM不保证线程B的写入对读线程C可见,因为写线程B和读线程C之间存在数据竞争,此时的执行结果不可预知。
如果想要确保读线程C看到写线程B对数组元素的写入,写线程B和读线程C之间需要使用同步原语(lock或volatile)来确保内存可见性。
7.4、为什么final引用不能从构造函数内“逸出”
前面我们提到过,写final域的重排序规则可以确保:在引用变量为任意线程可见之前,该引用变量指向的对象的final域已经在构造函数中被正确初始化过了。其实要得到这个效果,还需要一个保证:在构造函数内部,不能让这个被构造对象的引用为其他线程可见,也就是对象引用不能在构造函数中“逸出”。为了说明问题,让我们来看下面示例代码:
public class FinalReferenceEscapeExample {
final int i;
static FinalReferenceEscapeExample obj;
public FinalReferenceEscapeExample () {
i = 1; //1写final域
obj = this; //2 this引用在此“逸出”
}
public static void writer() {
new FinalReferenceEscapeExample ();
}
public static void reader {
if (obj != null) { //
int temp = obj.i; //
}
}
}
假设一个线程A执行writer()方法,另一个线程B执行reader()方法。这里的操作2使得对象还未完成构造前就为线程B可见。即使这里的操作2是构造函数的最后一步,且即使在程序中操作2排在操作1后面,执行read()方法的线程仍然可能无法看到final域被初始化后的值,因为这里的操作1和操作2之间可能被重排序。实际的执行时序可能如下图所示: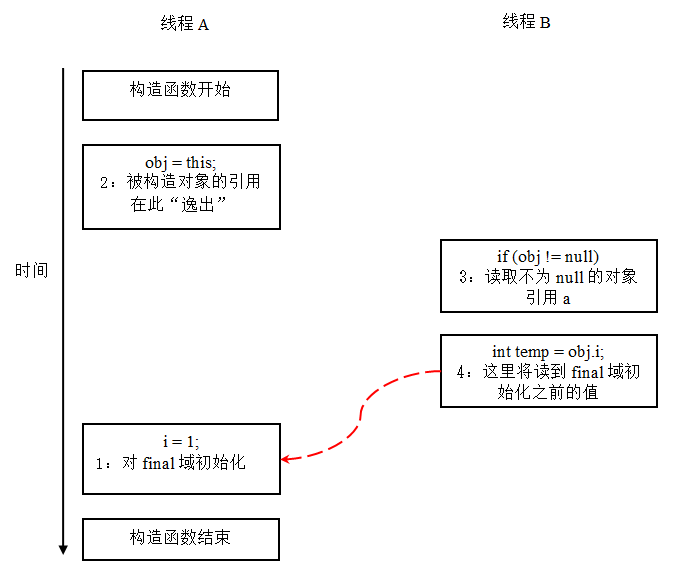
从上图我们可以看出:在构造函数返回前,被构造对象的引用不能为其他线程可见,因为此时的final域可能还没有被初始化。在构造函数返回后,任意线程都将保证能看到final域正确初始化之后的值。
7.5、final语义在处理器中的实现
现在我们以x86处理器为例,说明final语义在处理器中的具体实现。
上面我们提到,写final域的重排序规则会要求译编器在final域的写之后,构造函数return之前,插入一个StoreStore障屏。读final域的重排序规则要求编译器在读final域的操作前面插入一个LoadLoad屏障。
由于x86处理器不会对写-写操作做重排序,所以在x86处理器中,写final域需要的StoreStore障屏会被省略掉。同样,由于x86处理器不会对存在间接依赖关系的操作做重排序,所以在x86处理器中,读final域需要的LoadLoad屏障也会被省略掉。也就是说在x86处理器中,final域的读/写不会插入任何内存屏障!
7.6、JSR-133为什么要增强final的语义
在旧的Java内存模型中 ,最严重的一个缺陷就是线程可能看到final域的值会改变。比如,一个线程当前看到一个整形final域的值为0(还未初始化之前的默认值),过一段时间之后这个线程再去读这个final域的值时,却发现值变为了1(被某个线程初始化之后的值)。最常见的例子就是在旧的Java内存模型中,String的值可能会改变(参考文献2中有一个具体的例子,感兴趣的读者可以自行参考,这里就不赘述了)。
为了修补这个漏洞,JSR-133专家组增强了final的语义。通过为final域增加写和读重排序规则,可以为java程序员提供初始化安全保证:只要对象是正确构造的(被构造对象的引用在构造函数中没有“逸出”),那么不需要使用同步(指lock和volatile的使用),就可以保证任意线程都能看到这个final域在构造函数中被初始化之后的值。
补充内容:不得不提的volatile及指令重排序(happen-before)
Java内存模型解惑--观深入理解Java内存模型系列文章有感(二)的更多相关文章
- Java虚拟机内存溢出异常--《深入理解Java虚拟机》学习笔记及个人理解(三)
Java虚拟机内存溢出异常--<深入理解Java虚拟机>学习笔记及个人理解(三) 书上P39 1. 堆内存溢出 不断地创建对象, 而且保证创建的这些对象不会被回收即可(让GC Root可达 ...
- Java四种引用--《深入理解Java虚拟机》学习笔记及个人理解(四)
Java四种引用--<深入理解Java虚拟机>学习笔记及个人理解(四) 书上P65. StrongReference(强引用) 类似Object obj = new Object() 这类 ...
- Java进阶(三十六)深入理解Java的接口和抽象类
Java进阶(三十六)深入理解Java的接口和抽象类 前言 对于面向对象编程来说,抽象是它的一大特征之一.在Java中,可以通过两种形式来体现OOP的抽象:接口和抽象类.这两者有太多相似的地方,又有太 ...
- Java并发指南2:深入理解Java内存模型JMM
本文转载自互联网,侵删 一:JMM基础与happens-before 并发编程模型的分类 在并发编程中,我们需要处理两个关键问题:线程之间如何通信及线程之间如何同步(这里的线程是指并发执行的活动实 ...
- java提高篇(三)-----理解java的三大特性之多态
面向对象编程有三大特性:封装.继承.多态. 封装隐藏了类的内部实现机制,可以在不影响使用的情况下改变类的内部结构,同时也保护了数据.对外界而已它的内部细节是隐藏的,暴露给外界的只是它的访问方法. 继承 ...
- 【NLP】揭秘马尔可夫模型神秘面纱系列文章(二)
马尔可夫模型与隐马尔可夫模型 作者:白宁超 2016年7月11日15:31:11 摘要:最早接触马尔可夫模型的定义源于吴军先生<数学之美>一书,起初觉得深奥难懂且无什么用场.直到学习自然语 ...
- 垃圾收集器与内存分配策略(深入理解Java虚拟机)
3.1 概述 垃圾收集器要解决哪些问题? 哪些内存需要回收 什么时候回收 如何回收 引用计数算法:当有一个地方引用,+1,引用失效,-1. 缺点:对象之间相互循环引用的问题. 可达性分析算法: ...
- Java对象已死吗 深入理解Java虚拟机笔记
1.引用计数器法 给每个对象设置一个计数器,每当有一个引用就给计数器的值+1,引用时小时就减一,当计数器值为0是就可以回收掉了. 主流虚拟机都没有使用这种算法,循环依赖问题 2.可达性分析: 思路是通 ...
- 《深入理解 Java 虚拟机》笔记整理
正文 一.Java 内存区域与内存溢出异常 1.运行时数据区域 程序计数器:当前线程所执行的字节码的行号指示器.线程私有. Java 虚拟机栈:Java 方法执行的内存模型.线程私有. 本地方法栈:N ...
随机推荐
- Concurrency and Race Conditions
1.当多个线程访问共享硬件或软件资源的任何时候,由于线程之间可能产生对资源的不一致观察,所以必须显式管理对资源的访问. 2.内核中的并发管理设施: (1). 信号量: P操作将信号量的值减 1 ,判断 ...
- linux安装本地blast
1)wget ftp://ftp.ncbi.nlm.nih.gov/blast/executables/blast+/2.8.0alpha/ncbi-blast-2.8.0-alpha+-x64-li ...
- PIE结对项目编程
一.题目描述 构造程序并测试,分别是: 1.不能触发Fault. 2.触发Fault,但是不能触发Error. 3.触发Error,但是不能产生Failure. 二.结对对象 ...
- np.random.random()系列函数
1.np.random.random()函数参数 np.random.random((1000, 20)) 上面这个就代表生成1000行 20列的浮点数,浮点数都是从0-1中随机. 2.numpy.r ...
- OOP的几个不常用的方法
from OOP_多态 import cat c = cat("cat") print(c.__doc__) print(cat.__doc__) # # 打印类的描述信息,也就是 ...
- volatile是否就是原子性/线程同步的
在java线程并发处理中,有一个关键字volatile的使用目前存在很大的混淆,以为使用这个关键字,在进行多线程并发处理的时候就可以万事大吉. Java语言是支持多线程的,为了解决线程并发的问题,在语 ...
- IaaS、PaaS、SaaS、CaaS、MaaS五者的区别
云计算构架图 很明显,这五者之间主要的区别在于第一个单词,而aaS都是as-a-service(即服务)的意思,这五个模式都是近年来兴起的,且这五者都是云计算的落地产品,所以我们先来 ...
- 面向对象设计模式纵横谈:Adapter 适配器模式(笔记记录)
适配(转换)的概念无处不在 适配,即在不改变原有实现的基础上,将原先不兼容的接口转换为兼容的接口.生活中适配转换的例子太多了,也是设计模式里面比较容易理解的一个模式. 动机(Motivation) 在 ...
- centos 挂载u盘
1.创建一个目录来挂载U盘 mkdir /mnt/usb #创建usb目录挂载U盘 2.插上U盘,查看移动设备状态 fdisk -l #(注意:参数是小写字母 l 不是数字 1) 会看到类似这一行:/ ...
- C语言dos程序源代码分享(进制转换器)
今天给大家分享一个dos程序的源代码 这个程序是本人在学习中的经验分享 如果有问题或者建议,欢迎大家一起交流 源代码: /*本程序为一个进制转换器 本程序不作为商业用途,完全为技术交流 喜欢C语言的同 ...